使用sleuth实现微服务跟踪-微服务日志处理
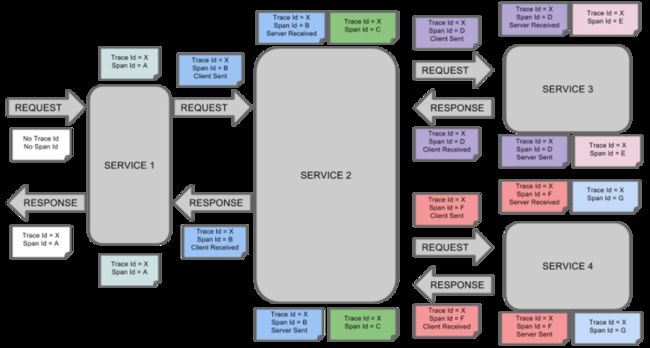
在微服务架构中,众多的微服务之间互相调用,如何清晰地记录服务的调用链路是一个需要解决的问题。同时,由于各种原因,跨进程的服务调用失败时,运维人员希望能够通过查看日志和查看服务之间的调用关系来定位问题,而Spring cloud sleuth组件正是为了解决微服务跟踪的组件。
sleuth的原理介绍可以参考这篇文章: [服务链路追踪(Spring Cloud Sleuth)](http://blog.csdn.net/forezp/article/details/70162074)
本文主要讲解sleuth的两方面用法
- sleuth+elk 结合,聚合微服务日志
- sleuth+ zipkin结合,显示文件调用链路
本文代码参考hello+world+helloworldh+helloworldfeign+track这5个项目
sleuth+elk聚合日志
sleuth配置
- 在微服务项目引入下列依赖
org.springframework.cloud
spring-cloud-starter-sleuth
配置文件application.yml增加
logging:
level:
root: INFO
org.springframework.web.servlet.DispatcherServlet: DEBUG
org.springframework.cloud.sleuth: DEBUG
依次启动hello项目和helloworld项目,在浏览器输入http://localhost:8020/message后两个项目的控制台输出如下日志
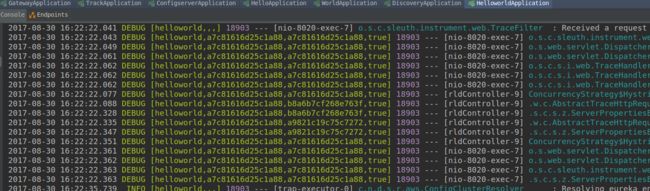
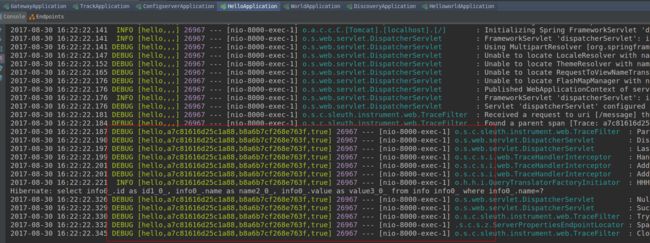
其中a7c81616d25c1a88是TraceId,后面跟着的是SpanId,依次调用有一个全局的TraceId,将调用链路串起来。
查看日志文件并不是一个很好的方法,当微服务越来越多日志文件也会越来越多,通过ELK可以将日志聚合,并进行可视化展示和全文检索。
sleuth配合elk使用
ELK是一款日志分析系统,它是Logstash+ElasticSearch+Kibana的技术组合,它可以通过logstash收集各个微服务日志,并通过Kibana进行可视化展示,而且还可以对大量日志信息通过ElasticSearch进行全文检索。

操作步骤:
- 安装ELK,我使用了docker安装了ELK,具体安装步骤可参考这篇文章:
[Docker ElK安装部署使用教程](http://www.cnblogs.com/soar1688/p/6849183.html)
区别是在启动logstash时,指定了日志来源路径
/opt/logstash/bin/logstash -e
'input { file { codec => json path => "/opt/build/*.json" } }
output { elasticsearch { hosts => ["localhost"] } }'项目添加依赖
net.logstash.logback
logstash-logback-encoder
4.9
在src/java/resources目录下新建logback-spring.xml,配置如下内容
DEBUG
${CONSOLE_LOG_PATTERN}
${LOG_FILE}
${LOG_FILE}.%d{yyyy-MM-dd}.gz
7
${CONSOLE_LOG_PATTERN}
10MB
${LOG_FILE}.json
${LOG_FILE}.json.%d{yyyy-MM-dd}.gz
7
UTC
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"parent": "%X{X-B3-ParentSpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
10MB
因为上面的日志文件用到spring.application.name,所以需要项目名称的配置挪到bootstrap.yml。
- 测试结果,在浏览器输入http://localhost:8020/message发起几次调用后,打开http://localhost:5601后看到上述的Kibana页面,说明可以正常使用ELK查询,分析跟踪日志。
sleuth 结合zipkin
通过查看日志分析微服务的调用链路并不是一个很直观的方案,结合zipkin可以很直观地显示微服务之间的调用关系。



通过zipkin可以将调用链路可视化显示。
下面讲解配置步骤:
服务端zipkin-server配置
新建项目track,并引入依赖
io.zipkin.java
zipkin-server
io.zipkin.java
zipkin-autoconfigure-ui
启动类添加@EnableDiscoveryClient和@EnableZipkinServer注解
配置文件application.yml
spring:
application:
name: sleuth-server
server:
port: 9411
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
instance:
instanceId: ${spring.application.name}:${spring.cloud.client.ipAddress}:${server.port}以上服务端就搭建好了
客户端整合zipkin步骤
客户端添加依赖
org.springframework.cloud
spring-cloud-starter-zipkin
配置文件添加
spring:
zipkin:
base-url: http://127.0.0.1:9411
sleuth:
sampler:
percentage: 1.0指定了zipkin server的地址,下面制定需采样的百分比,默认为0.1,即10%,这里配置1,是记录全部的sleuth信息,是为了收集到更多的数据(仅供测试用)。在分布式系统中,过于频繁的采样会影响系统性能,所以这里配置需要采用一个合适的值。
zipkin改进
在这里对zipkin进行改进,主要包含两方面
- 通过消息中间件收集sleuth数据
- 持久化sleuth数据
1、通过消息中间件收集sleuth数据
通过消息中间件可以将zipkin server和微服务解耦,微服务无需知道zipkin server地址,只需将sleuth数据传入消息中间件。同时,也可以解决zipkin server与微服务网络不通情况。
改造服务端
- 修改zipkin server(trace项目)配置
org.springframework.cloud
spring-cloud-sleuth-zipkin-stream
org.springframework.cloud
spring-cloud-starter-sleuth
org.springframework.cloud
spring-cloud-stream-binder-rabbit
io.zipkin.java
zipkin-autoconfigure-ui
配置文件application.yml增加
rabbitmq:
host: localhost
port: 5673
username: guest
password: guest这是sleuth数据来源
- 启动类@EnableZipkinServer改为@EnableZipkinStreamServe
以上服务端改造完毕,下面改造客户端(以helloworld-feign项目为例)
改造客户端
以helloworldfeign项目为例
- 修改依赖
org.springframework.cloud
spring-cloud-sleuth-stream
org.springframework.cloud
spring-cloud-starter-sleuth
org.springframework.cloud
spring-cloud-stream-binder-rabbit
配置文件增加
spring:
rabbitmq:
host: localhost
port: 5673
username: guest
password: guest并删除下面指向zipkin server的配置
spring:
zipkin:
base-url: http://127.0.0.1:9411这样就完成了客户端的配置,依次启动track和helloworldfeign项目,通过http://localhost:8030/message调用其他服务后,在zipkin server 成功获取了helloworldfeign的sleuth数据。
在以上的过程中,只要重启zipkin server,发现之前的数据丢失。这是因为zipkin server获取的数据是放在内存的,我们可以获取的服务追踪数据放入到ElasticSearch
2、持久化sleuth数据
- 修改依赖
org.springframework.cloud
spring-cloud-sleuth-zipkin-stream
io.zipkin.java
zipkin-autoconfigure-storage-elasticsearch-http
1.29.2
org.springframework.cloud
spring-cloud-stream-binder-rabbit
io.zipkin.java
zipkin-autoconfigure-ui
配置文件增加
zipkin:
storage:
type: elasticsearch
elasticsearch:
cluster: elasticsearch
hosts: http://localhost:9200
index: zipkin
index-shards: 5
index-replicas: 1再次启动track项目后,可以将数据持久化到elasticsearch。
---------------------
转自:https://blog.csdn.net/jrn1012/article/details/77837710
相关文章:
https://blog.csdn.net/forezp/article/details/76795269
https://blog.csdn.net/peterwanghao/article/details/79967634