OBCP第八章 OB运维、监控与异常处理-常见异常处理
问题排查概述:数据库连接问题排查
在遇到连接问题时,需要清楚整个系统的架构,对整个连接链路进行排查。通常情况下应用连接到数据库的完整链路是从应用服务器到 OBProxy 再到 OB 集群,此外还可能涉及负载均衡、DNS 解析、网络等。一般连接问题如连接失败、连接断开、连接报错异常等问题排查,从以下两个方向入手:
OBProxy和应用之间的连接异常
OBProxy和OBServer之间连接异常
排查方式:
首先可以通过尝试连接,缩小问题链路的范围:
通过OBProxy连接数据库
直连OceanBase数据库
查看报错信息,常见报错类型有:
数据库事务状态异常,OB主动断开连接
应用端连接报错。如果报错信息涉及Get connection timeout及连接数,应查看应用是否有流量突增或DB连接数设置;如果报错信息涉及Communications link failure,连接可能被异常中断
问题排查概述:OBServer进程异常退出
当正在运行的OBServer异常退出时,通过操作系统(ps -ef命令)查询不到 OBServer进程的存在,此时,如果不是硬件损坏或者操作系统的问题,可尝试拉起observer进程作为应急手段;OBServer 在退出时会生成core dump文件,可以此为依据进行 OBServer 的异常退出根因分析(版本不同,core dump排查的方法不同)

Lbt后的地址信息可以填入 addr2line -pCfe $observer $symbol_addr 命令中的$symbol_addr以获得CRAS原始信息和线程栈信息。( addr2line 可用于V2.2.76 版本之后)
问题排查概述:合并问题排查
进行合并问题排查时,首先要确定当前集群中的合并配置项,确定当前的合并状态,然后根据查询得到的情况,对不同的合并问题类型进行分析后再寻找根因
确认合并配置项:
需确定enable_manual_merge,zone_merge_concurrency,zone_merge_order,
enable_merge_by_turn,major_freeze_duty_time,enable_auto_leader_switch等配置项
确定合并状态:
SELECT * FROM __all_zone WHERE name = "frozen_version" or name = "last_merged_version";
SELECT * FROM __all_zone WHERE name = "merge_status";
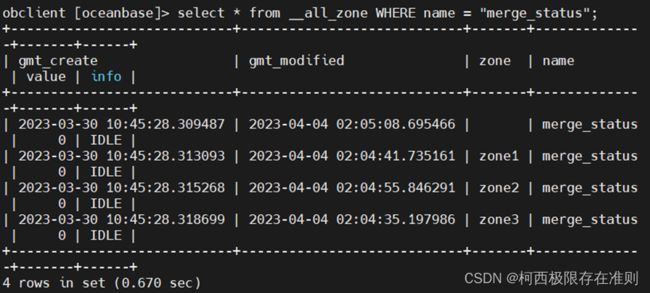
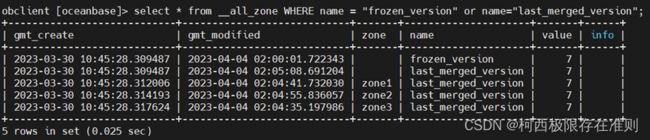
根据上面查询到的信息,可以将问题归于未合并问题、合并超时问题、合并慢问题,并做具体的分析
问题排查概述:合并问题排查
| 合并问题细分 |
判断步骤 |
| 未合并问题 |
ZONE未合并:SELECT * FROM __all_zone WHERE name = "global_broadcast_version" or name = "broadcast_version"; 如果broadcast_version 等于 last_merged_version,且 last_merged_version 落后于 global_broadcast_version,说明 RootService 没有发起相关 Zone 的合并 副本未合并:SELECT * FROM __all_virtual_meta_table WHERE data_version != 25 LIMIT 10; 查询哪个主机上的 副本为合并(假设当前要合并的目标版本是25) |
| 合并超时问题 |
定位未合并到指定版本的 partition 判断该 partition 的合并任务是否在执行中:SELECT * FROM __all_virtual_sys_task_status; 如果该 partition 没有调度合并任务,判断该 partition 的最新的转储 sstable 的 snapshot_version 有没有推过freeze_info 点,如果没有推过 freeze_info 点,说明转储有问题 |
| 合并慢问题 |
通过SELECT /*+ query_timeout(10000000)*/* FROM __all_virtual_partition_sstable_merge_info WHERE merge_type = “major merge” and version = “ limit 5; 语句找到合并耗时最多的几个 partition 来具体分析 通过表 __all_virtual_partition_sstable_merge_info 查看宏块重用情况 查看合并开始时间是否合理 |
问题排查概述:事务问题排查
在运行 OceanBase 的过程中,OceanBase 会执行数据库事务,在执行后将执行返回的结果返回给发出请求的客户端;如果事务执行失败或者异常,会产生事务报错,常见的事务报错大体分为两大类:
事务执行过程中对客户端展示的错误
通过日志或内存表查询发现的环境异常
排查方式:
通过__all_virtual_trans_stat表可以查询到当前还未结束的事务上下文状态
进一步根据 trans_id搜索对应时间段内的 observer.log 日志,找到相应事务报错信息:

可以根据错误标识位(4038)判断问题是否属于事务回滚类、执行超时类、等待锁超时类等类型
问题排查概述:事务问题排查

问题排查概述:副本迁移问题排查
在进行副本迁移问题排查时,首先确定副本迁移是否不符合预期情况,然后再根据具体的迁移情况进行处理
确定副本迁移是否存在问题步骤:
确定问题partition:
SELECT * FROM __all_unit WHERE migrate_from_svr_ip != "" or
migrate_from_svr_port !="";
查看RootService调动副本迁移任务的状态是否符合预期:
在 RootService 所在机器 grep “root_balancer” rootservice.log 获取线程号 LWP_ID,获取线程号后去grep “LWP_ID” rootservice.log 看 RS 的负载均衡线程正在执行的任务
检查系统虚拟表: __all_virtual_sys_task_status
检查存储层调度的状态:
SELECT * FROM __all_virtual_sys_task_status;问题排查概述:副本迁移问题排查
| 副本迁移问题细分 | 步骤 |
| 迁入目标端磁盘满 | 排查有迁移异常的 server: SELECT * FROM __all_server WHERE block_migrate_in_time > 0 \G临时设置block_migrate_in_time解除block状态: ALTER system SET migration_disable_time = "600s"; 查询磁盘使用空间 |
| 迁移过慢问题 | 查看迁移相关配置项: server_data_copy_out_concurrency ,该项为单个节点迁出数据的最大并发数 server_data_copy_in_concurrency ,该项为单个节点迁入数据的最大并发数 sys_bkgd_io_low_percentage 该项表示 sys_io_percent 的下限,如果下限太低则可能导 致合并的 I/O 很慢,可以通过适当调大这个值来调大 I/O (检查 I/O 是否达到磁盘瓶颈) sys_bkgd_net_percentage 该项表示后端网络带宽占用(检查网络配置) |
| 迁移失败问题 | 确认常见错误码。 检查是否存在硬件问题。 检查内核问题。 |