K近邻算法【OpenCV&Python】
K近邻算法—入门
- 0、 引言
- 1、理论基础
- 3、计算
-
- 3.1 归一化
- 3.2 距离计算
- 4、手写数字识别的原理
-
- 4.1 数据初始化
- 4.2 读取特征图像
- 4.3 提取特征图像的特征值
- 4.4 计算待识别图像的特征值
- 4.5 计算待识别图像与特征图像之间的距离
- 4.6 获取k个最短距离及索引
- 4.7 识别
- 4.8 完整程序
- 5、K近邻模块的基本使用
- 6、K近邻手写数字识别
0、 引言
参考书籍 《OpenCV轻松入门——面向Python》李立宗著,电子工业出版社出版
机器学习算法是从数据中产生模型,也就是进行学习的算法。我们把经验提供算法,它能够根据经验数据产生模型。在面对新的情况时,模型就会为我们提供判断结果。
从数据中学得模型的过程称为学习(Learning)或者训练(Training),在训练过程中所使用的数据称为训练数据,其中的每个样本称为训练样本,训练样本所组成的合集称为训练集。
当然,如果希望获得一个模型,除了有数据还需要给样本贴上标签(Label),本章从理论基础、手写数字识别算法、手写数字识别实例等角度介绍K-近邻算法。
1、理论基础
K近邻算法的本质是将指定对象根据已知特征值分类。为了确定分类,需要定义特征。
例1:为一段运动视频分类,判断视频是乒乓球比赛还是足球比赛。
步骤:
这里定义两个特征,一个是“挥手”特征,一个是“踢脚”特征;
将数据绘制散点图;
从图中可以看出,数据点呈现聚集特征。
此时,有一个Test视频,统计其“挥手”、“踢脚”的次数,发现视频Test最近的邻居是乒乓球比赛视频,因此判断Test是乒乓球比赛视频。
Tips:例1是一个相对极端的例子,非黑即白,而实际分类数据中的参数比较多,判断起来相对复杂。因此,为了提高算法的可靠性,在实施时会取k个邻近点这k个邻近点中属于哪一类的较多,然后将当前待识别点划分为哪一类。为了方便判断,k值通常取奇数。
下面用一个例子解释K近邻算法的基本思想。
例2:已知某知名双胞胎艺人A和B长得很像,判断一张图片T上的人物到底是A还是B,则采用K近邻算法的具体步骤如下。
(1)收集艺人A和B的照片各100张;
(2)确定几个用来识别人物的重要特征,并使用这些特征来标注艺人A和B的照片。例如,根据某四个特征,可以将每张照片表示为[156,34,890,457]这样的形式(即一个样本点)。简而言之,就是使用数值来表示照片,得到艺人A的数据集FA、艺人B的数据集FB。
(3)计算待识别图像T的特征,并使用特征值表示图像T。
(4)计算图像T的特征值TF与FA、FB中各特征值之间的距离。
(5)找出产生其中k个最短距离的样本点(找出离T最近的k个邻居),统计k个样本点钟属于FA和FB的样本点个数,属于哪个数据集的样本点多,就将T确定为哪个艺人的图像。
3、计算
K近邻算法在获取各个样本的特征值后,计算待识别样本的特征值与已知分类的样本特征值之间的距离,然后找出k个最邻近的样本,根据k个最邻近样本中占比最高的样本所属的分类,来确定待识别样本的分类。
3.1 归一化
对于简单的情况,直接计算与特征值的距离(差距)即可。
当有多个参数时,一般将这些参数构成**列表(数组)**进行综合判断。
由于实际情况中,参数具有不同的量纲,需要对参数进行处理。一般情况下,对参数进行**归一化处理**=即可。
3.2 距离计算
(1)差距
先将特征值中对应的元素相减,然后再求和;
(2)曼哈顿距离(避免正负相抵消的情况)
先取绝对值,再求和;
(3)平方和
计算距离的平方和;
(4)欧氏距离(广泛使用)
计算平方和的平方根。
4、手写数字识别的原理
4.1 数据初始化
本例中,特征图像存储在当前路径的“image”下;用于判断分类的特征值有100个;特征图像的行数和列数可以通过程序来获取,也可以在图像上单击鼠标右键后通过查找属性值来获取。
数据初始化程序如下:
##### 数据初始化
# 涉及的数据主要有路径信息、图像大小、特征值数量、用来存储所有特征值的数据等。
s = 'image\\' # 图像所在的路径
num = 100 # 共有特征值的数量
row = 240 # 特征图像的行数
col = 240 # 特征图像的列数
a = np.zeros((num,row,col)) # a用来存储所有特征的值
print (a.shape)
4.2 读取特征图像
##### 读取特征图像
# 本步骤将所有的特征图像读入到 a中,共有10个数字,每个数字有10个特征图像,采用嵌套循环语句来读取。
n = 0 # n用来存储当前图像
for i in range(0,10):
for j in range(1,11):
a[n,:,:] = cv2.imread(s+str(i)+'\\'+str(i)+'-'+str(j)+'.bmp',0)
n = n+1
4.3 提取特征图像的特征值
##### 提取特征图像的特征值
# 在提取特征值时,可以计算每个子块内黑色像素点的个数,也可以计算每个子块内白色像素点的个数
feature = np.zeros((num,round(row/5),round(col/5))) # feature存储所有样本的特征值
print(feature.shape) # 在必要时查看feature的形状是什么样子
print(row) # 在必要时查看row的值,有多少个特征值(100个)
for ni in range(0,num):
for nr in range(0,row):
for nc in range(0,col):
if a[ni,nr,nc] == 255:
feature[ni,int(nr/5),int(nc/5)] += 1
#如果原图像内位于(row,col)位置的像素点是白色,则要把对应特征值内位于(row/5,col/5处的值加1)
f = feature # 简化变量名称
4.4 计算待识别图像的特征值
##### 计算待识别图像的特征值
# 读取待识别图像的特征值,然后计算该图像的特征值
o = cv2.imread('image\\test\\9.bmp',0)
# 读取图像的值
of = np.zeros((round(row/5),round(col/5))) # 用来存储待识别图像的特征值
for nr in range(0,row):
for nc in range(0,col):
if o[nr,nc] == 255:
of[int(nr/5),int(nc/5)] += 1
4.5 计算待识别图像与特征图像之间的距离
##### 计算待识别图像与特征图像之间的距离
# 依次计算待识别图像与特征图像之间的距离
d = np.zeros(100)
for i in range(0,100):
d[i] = np.sum((of-f[i,:,:])*(of-f[i,:,:])) # 欧氏距离
# 数据集f中依次存储的是数字0~9的共计100个图像的特征值,所以数组d中的索引号对应着各特征图像的编号。
# d[mn]表示待识别图像与数字“m”的第n个特征图像的距离。
# 如果将索引号整除10,得到的值正好是其对应的特征图像上的数字。
# 确定了索引与特征图像的关系,下一步可以通过计算索引达到数字识别的目的。
4.6 获取k个最短距离及索引
##### 获取k个最短距离及索引
# 具体实现方式:每次找出最短距离(最小值)及其索引(下标),然后将该最小值替换为最大值;
# 重复上述过程k次,得到k个最短距离的索引
d = d.tolist
temp = []
Inf = max(d)
print (Inf) # 必要时查看最大值
k = 7
for i in range(k):
temp.append(d.index(min(d)))
d[d.index(min(d))] = Inf
4.7 识别
已知将索引整除10,就能得到对应特征图像上的数字。
(66,60,65,68,69,67,78,89,96,32)=(6,6,6,6,6,6,7,8,9,3)
为了叙述上的方便,将上述整除结果标记为dr,在dr中出现次数最多的数字,就是识别结果。
##### 识别
# 根据计算出来的索引值
temp = [i/10 for i in temp]
# 数组r用来存储结果,r[0]表示K近邻中“0”的个数,r[n]表示K近邻中n的个数
r = np.zeros(10) # 建立一个数组r,使其初始值均为0
for i in temp:
r[int(i)] += 1 # 依次从dr中取数字n,将数组r索引位置为n的值加1
print ("当前可能的数字结果为:‘+str(np.argmax(r))")
4.8 完整程序
# K邻近算法识别手写数字
import cv2
import numpy as np
import matplotlib.pyplot as plt
##### 数据初始化
# 涉及的数据主要有路径信息、图像大小、特征值数量、用来存储所有特征值的数据等。
s = 'image\\' # 图像所在的路径
num = 100 # 共有特征值的数量
row = 240 # 特征图像的行数
col = 240 # 特征图像的列数
a = np.zeros((num,row,col)) # a用来存储所有特征的值
print (a.shape)
##### 读取特征图像
# 本步骤将所有的特征图像读入到 a中,共有10个数字,每个数字有10个特征图像,采用嵌套循环语句来读取。
n = 0 # n用来存储当前图像
for i in range(0,10):
for j in range(1,11):
a[n,:,:] = cv2.imread(s+str(i)+'\\'+str(i)+'-'+str(j)+'.bmp',0)
n = n+1
##### 提取特征图像的特征值
# 在提取特征值时,可以计算每个子块内黑色像素点的个数,也可以计算每个子块内白色像素点的个数
feature = np.zeros((num,round(row/5),round(col/5))) # feature存储所有样本的特征值
print(feature.shape) # 在必要时查看feature的形状是什么样子
print(row) # 在必要时查看row的值,有多少个特征值(100个)
for ni in range(0,num):
for nr in range(0,row):
for nc in range(0,col):
if a[ni,nr,nc] == 255:
feature[ni,int(nr/5),int(nc/5)] += 1
#如果原图像内位于(row,col)位置的像素点是白色,则要把对应特征值内位于(row/5,col/5处的值加1)
f = feature # 简化变量名称
##### 计算待识别图像的特征值
# 读取待识别图像的特征值,然后计算该图像的特征值
o = cv2.imread('image\\test\\9.bmp',0)
# 读取图像的值
of = np.zeros((round(row/5),round(col/5))) # 用来存储待识别图像的特征值
for nr in range(0,row):
for nc in range(0,col):
if o[nr,nc] == 255:
of[int(nr/5),int(nc/5)] += 1
##### 计算待识别图像与特征图像之间的距离
# 依次计算待识别图像与特征图像之间的距离
d = np.zeros(100)
for i in range(0,100):
d[i] = np.sum((of-f[i,:,:])*(of-f[i,:,:])) # 欧氏距离
# 数据集f中依次存储的是数字0~9的共计100个图像的特征值,所以数组d中的索引号对应着各特征图像的编号。
# d[mn]表示待识别图像与数字“m”的第n个特征图像的距离。
# 如果将索引号整除10,得到的值正好是其对应的特征图像上的数字。
# 确定了索引与特征图像的关系,下一步可以通过计算索引达到数字识别的目的。
##### 获取k个最短距离及索引
# 具体实现方式:每次找出最短距离(最小值)及其索引(下标),然后将该最小值替换为最大值;
# 重复上述过程k次,得到k个最短距离的索引
d = d.tolist
temp = []
Inf = max(d)
print (Inf) # 必要时查看最大值
k = 7
for i in range(k):
temp.append(d.index(min(d)))
d[d.index(min(d))] = Inf
##### 识别
# 根据计算出来的索引值
temp = [i/10 for i in temp]
# 数组r用来存储结果,r[0]表示K近邻中“0”的个数,r[n]表示K近邻中n的个数
r = np.zeros(10)
for i in temp:
r[int(i)] += 1
print ("当前可能的数字结果为:‘+str(np.argmax(r))")
5、K近邻模块的基本使用
在OpenCV中,不需要自己编写复杂的函数实现K近邻算法,直接调用其自带的模块函数即可。
import cv2
import numpy as np
import matplotlib.pyplot as plt
##### 创建两组数据,每组数据包含20对随机数:
# rand1数据位于(0,30)
rand1 = np.random.randint(0,30,(20,2)).astype(np.float32)
# rand2数据位于(70,100)
rand2 = np.random.randint(70,100,(20,2)).astype(np.float32)
##### 将rand1和rand2拼接为训练数据
trainData = np.vstack((rand1,rand2))
##### 数据标签,共两类:0和1
# r1对应着rand1的标签,为类型0
r1Label = np.zeros((20,1)).astype(np.float32)
# r2对应着rand2的标签,为类型1
r2Label = np.ones((20,1)).astype(np.float32)
tdLabel = np.vstack((r1Label,r2Label))
# 使用绿色标注类型0
g = trainData[tdLabel.ravel() == 0]
plt.scatter(g[:,0],g[:,1],80,'g','o')
# 使用蓝色标注类型1
b = trainData[tdLabel.ravel() == 1]
plt.scatter(b[:,0],b[:,1],80,'b','s')
# plt.show()
##### test为用于测试的随机数,该数在0到100之间
test = np.random.randint(0,100,(1,2)).astype(np.float32)
plt.scatter(test[:,0],test[:,1],80,'r','*')
##### 调用OpenCV内的K近邻模块,并进行训练
knn = cv2.ml.KNearest_create()
knn.train(trainData,cv2.ml.ROW_SAMPLE,tdLabel)
##### 使用K近邻算法分类
ret,results,neighbours,dist = knn.findNearest(test,5)
##### 显示处理结果
print("当前随机数可以判定为类型:",results)
print("距离当前点最近的5个邻居是:",neighbours)
print("5个最近邻居的距离:",dist)ous
# 观察运行结果,对比上述输出
plt.show()
运行结果1:

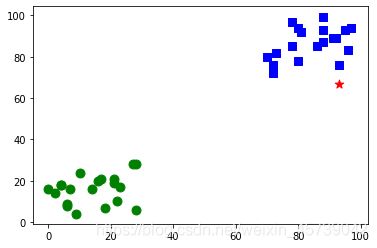
运行结果2:

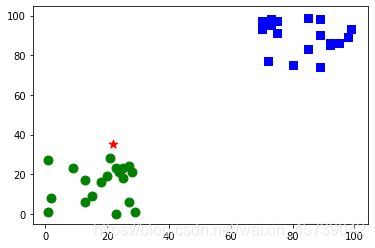
注 :由于test是0到100的随机数,因此每次运行的结果不一定完全相同。
6、K近邻手写数字识别
使用OpenCV自带的K近邻算法识别手写程序。
############ K邻近算法识别手写数字
import cv2
import numpy as np
import matplotlib.pyplot as plt
##### 数据初始化
# 涉及的数据主要有路径信息、图像大小、特征值数量、用来存储所有特征值的数据等。
s = 'image\\' # 图像所在的路径
num = 100 # 共有特征值的数量
row = 240 # 特征图像的行数
col = 240 # 特征图像的列数
a = np.zeros((num,row,col)) # a用来存储所有特征的值
# print (a.shape)
##### 读取特征图像
# 本步骤将所有的特征图像读入到 a中,共有10个数字,每个数字有10个特征图像,采用嵌套循环语句来读取。
n = 0 # n用来存储当前图像
for i in range(0,10):
for j in range(1,11):
a[n,:,:] = cv2.imread(s+str(i)+'\\'+str(i)+'-'+str(j)+'.bmp',0)
n = n+1
##### 提取特征图像的特征值
# 在提取特征值时,可以计算每个子块内黑色像素点的个数,也可以计算每个子块内白色像素点的个数
feature = np.zeros((num,round(row/5),round(col/5))) # feature存储所有样本的特征值
# print(feature.shape) # 在必要时查看feature的形状是什么样子
# print(row) # 在必要时查看row的值,有多少个特征值(100个)
for ni in range(0,num):
for nr in range(0,row):
for nc in range(0,col):
if a[ni,nr,nc] == 255:
feature[ni,int(nr/5),int(nc/5)] += 1
#如果原图像内位于(row,col)位置的像素点是白色,则要把对应特征值内位于(row/5,col/5处的值加1)
f = feature # 简化变量名称
##### 将feature处理为单行形式
train = feature[:,:].reshape(-1,round(row/5)*round(col/5)).astype(np.float32)
# print (train.shape)
##### 贴标签,要注意,是range(0,100),而不是range(0,101)
trainLabels = [int(i/10)]
for i in range (0,100):
trainLabels = np.asarray(trainLabels)
# print(*trainLabels) #打印测试看看标签值
###### 读取图像值
o = cv2.imread('image\\test\\5.bmp',0) # 读取待识别图像
of = np.zeros(round(row/5),round(col/5))) # 用来存储待识别图像的特征值
for nr in range(0,row):
for nc in range(0,col):
if o[nr,nc] == 255:
of[int(nr/5),int(nc/5)] += 1
test = of.shape(-1,round(5/row),round(5/col)).astype(np.float32)
##### 调用OpenCV内的K近邻模块,并进行训练
knn = cv2.ml.KNearest_create()
knn.train(train,cv2.ml.ROW_SAMPLE,traindLabels)
##### 使用K近邻算法分类
ret,results,neighbours,dist = knn.findNearest(test,k=5)
##### 显示处理结果
print("当前随机数可以判定为类型:",results)
print("距离当前点最近的5个邻居是:",neighbours)
print("5个最近邻居的距离:",dist)