Raft协议浅析
文章目录
- 1. 简单介绍
- 2.前置知识
-
- ①节点状态
- ②心跳与选举超时时间
- ③任期term count
- ④主要解决问题
- 3.原理
-
- 领袖选举 Leader Election
-
- ①发生时机
- ②原理
- 记录复写 Log Replication
-
- ①为什么是集群?
- ②流程
- ③特殊情况
- ④对于Append Entries Mssage理解
- raft保证的安全性 Safety
-
- 追随者死机
- 领袖死机
- 超时期限和可用性
1. 简单介绍
raft是paxos算法的一种实现。目标是提供更清晰的逻辑分工使用算法本身更好理解,同时有更高的安全性。Raft能为在计算机集群之间部署有限状态机提供一种通用方法,并确保集群内的任意节点在某种状态转换上保持一致(个人理解就是保证主从的一致性)。
在redis的哨兵模式中就用到了raft协议。
tip:
- 与paxos最主要的区别:paxos每次遇到一个新的请求会选举新的leader,所以这个leader是短期的。而raft协议选取的leader是永久性的,除非因为网络问题等因素才会进行leader重新选举
2.前置知识
①节点状态
在raft中每个节点都是有对应的状态的,共3种:
● leader 领袖:负责处理外部信息,并通过心跳机制同步给追随者。
● follower 追随者:转发请求给leader,接收来自leader的心跳
● candidate 候选人:当leader不存在时,进行选举
②心跳与选举超时时间
正常情况下,集群中存在leader和follower,leader会定期给follower发送心跳(heartbeat),以至于让其follower知道还在工作。每个follower会维护一个超时选举器(timeout:150ms或300ms),当在timeout后还未收到leader的心跳,则会成功candidate状态并进行选举;若成功收到了来自leader的心跳,则将timeout清零,重新计数。
③任期term count
当选举开始时,term会+1,表示一个新的任期开始,如果选举成功则正常进行工作;如果失败,则终止当前任期,开启新的任期并开启下一次任期(term+1)
④主要解决问题
Raft协议主要解决3个问题:
● 领袖选举
● 记录复写
● 安全性
3.原理
领袖选举 Leader Election
①发生时机
● 起始状态,没有leader
● leader宕机或网络问题
本质都是follower的计时器到期
②原理
-
当集群中有节点的timeout(可能是刚开始,也有可能是宕机了)超时后,则该节点从follower状态变为candidate状态,开始进行选举:追随者将自己的term加1,并为自己投递1票,并向集群中的其他集群发起投票请求。(此时其他节点可能处于follower状态或candidate状态)
-
当其他节点收到选票请求时,会对选票中的任期信息进行对比,如果选票的任期>自己节点的任期,则会自认落选,并将自己的任期set=选票的任期。如果选票的任期=<自己节点的任期,就意味着在自己已经先于该选票参加过选举了,自己则更应该成功leader
-
参与选举的节点在timeout时期内会收到来自其他集群的确认消息,如果超过半数都同一成为leader,则真正的成为leader,否则该节点结束当前任期,进入下一任期的选举,term+1;
-
Raft每个服务器的超时期限是随机的,这降低伺服务同时竞选的几率,也降低因两个竞选人得票都不过半而选举失败的几率。
视频推荐:raft
看一看这个视频,就懂了
个人对任期与选票的理解:
- 首先一个term只能投一次vote。
- candicate是term+1后,马上进行投递vote(投递给自己)
- follower接收到candicate的vote,判断后(假如成功),则为其投递确认选票,并将自己的term设定为选票的term(term增加变化)。
为什么每一个term只有一个vote: - 可以结合生活例子来看,就如总统选举,也是每个人每届只能投一个。如果每个人每届投两票,都投两个总统,那不是最终就会投出两个相同总统的吗?这就使得这次选举失去了意义。
为什么每个节点的timeout不一样是随机的150ms或100ms。
- 可以想象一个场景(split vote)【对应官网视频http://thesecretlivesofdata.com/raft/#election】,如果有两个节点同时发生timeout并进行选举,此时他们极有可能在相同时间内收到相同的选票,因为有"每个节点每个任期只能有一票的限制",当两个节点收到相同的选票数量时,他们一定没有收到半数以上的数量,当他们在规定时间内没收到选票,则会进行下一次任期,term+1,重新开始选举。因为timeout不同,所有两个节点下一次首次进行选举时时间就不一样了。
综上:其实只要一个节点的term确定了,那么就暗示着当前的选票就已经投递过了,想要投递新的选票,那么term就必须增加。
即选票的投递一定伴随着term的增加
记录复写 Log Replication
①为什么是集群?
leader提供写服务,follower提供读服务
在互联网整体来看,读远大于写
当写请求打到leader时,我们必须保证整个集群都能够根据这次写请求达到数据的一致性。
②流程
● 当leader收到客户端的请求后,先将修改操作写进自己的日志中,并将日志通过信息随心跳机制发送给其他的follower。自己进入第一阶段
● 其他follower也将此修改操作写到自己的日志中,并回复leader ack。
● 当leader收到半数以上的ack后,给客户端ack,自己本地提交事务,并跟随心跳机制向其他的follower发送提交命令,其他follower收到后,提交本地事务。
③特殊情况
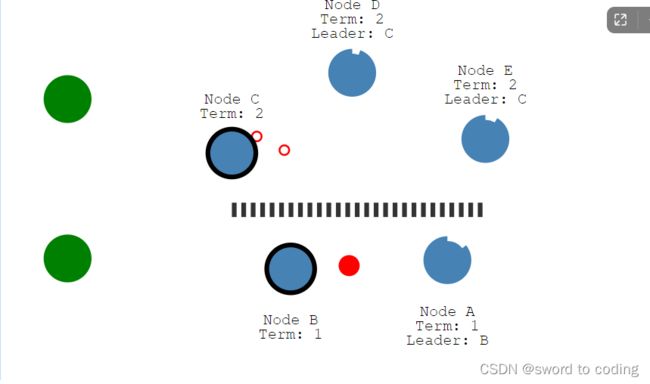
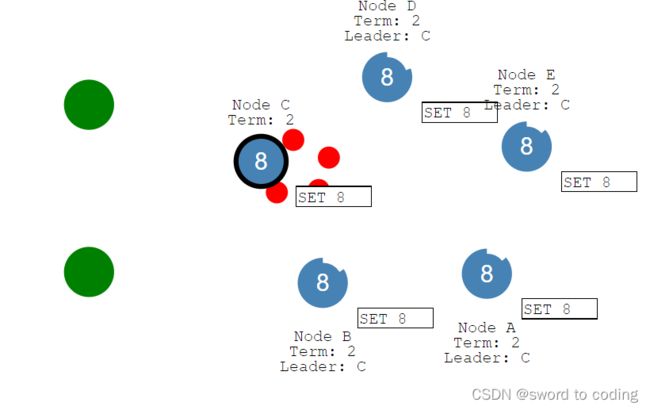
网络隔离
● 如图所示,A、B机器与CDE被隔离。leaderb因为无法收到半数以上的ack而重复给其他节点发送信息,CDE因无法收到leader心跳,而进行重新选举,并生成新leaderC。
● 如图,他们节点的任期已经不同了,term高的是最新的数据修改
● 当网络恢复,leaderB会发现新的leader,且其term比自己高,自己会退化为followerB,并回滚自身的日志(未提交部分),followerA也会回滚自己的日志(未提交)。同时BA的term任期变为leader的所属任期(为什么?可以类比人类现实:自己的国家选举了新一届的总统,那自己肯定也必须是新一届的人啊,自己所认识的任期也要与leader一致。另一点保证:下次进行leader选举时,表名自己已经获取到了最新的数据)
● 这样就保证了全局的一致性。
④对于Append Entries Mssage理解
后续………………
raft保证的安全性 Safety
● 选举安全性:每个任期最多只能选出一个领袖。
● 领袖附加性:领袖只会把新指令附加(英语:append)在记录尾端,不会改写或删除已有指令。
● 记录符合性:如果某个指令在两个记录中的任期和指令序号一样,则保证序号较小的指令也完全一样。
● 领袖完整性:如果某个指令在某个任期中存储成功,则保证存在于领袖该任期之后的记录中。
● 状态机安全性:如果某服务器在其状态机上执行了某个指令,其他服务器保证不会在同个状态上执行不同的指令。
前四项保证的原因详见上述算法,状态机安全性则借由下述选举流程的限制所达到。
追随者死机
当某台追随者死机时,所有给它的转发指令和拉票的消息都会因没有回应而失败,此时发送端会持续重送。当这台追随者引导重新加入集群,就会收到这些消息,追随者会重新回应,如果转发的指令已经写入,不会重复写入。
领袖死机
领袖死机或断线时,每个已存储指令必定已经写入到过半的服务器中,此时选举流程会让记录最完整的服务器胜选。其中一个因素是Raft候选人拉票时会揭露自己记录最新一笔的信息,如果服务器自己的记录比较新,就不会投票给候选人。(怎么对比最新信息?根据任期和日志?先比任期再比日志?)
超时期限和可用性
因为Raft启动选举是基于超时,使得超时期限的选择至为关键。若遵守算法的时限需求
广播时间 << 超时期限 << 平均故障间隔
就能达到稳定性。这三个时间定义如下:
● 广播时间 是单一服务器发送消息给集群中每台服务器并得到回应的平均时间,需要测量得到。
● 超时期限 是发动选举的超时期限,由部署Raft集群的人选定。
● 平均故障间隔 是服务器发生故障之间的平均时间,可以测量或估计得到。
广播时间典型是 0.5ms 到 20ms,平均故障间隔通常是用周或月来计算的,所以可以将超时期限设在 10ms 到 500ms。