Airflow ETL任务调度工具 介绍

Airflow 是 Apache 基金会的一套用于创建、管理和监控工作流程的开源平台,是一套非常优秀的任务调度工具。截至2022年7月,在GitHub上已经拥有近27k的star。
本文主要介绍一下Airflow 2.3.2版本,各个功能模块,以及如何使用。只浅浅提了一下Airflow的功能点,具体内容还是链接到了官方文档。
前言
官网简介
Airflow是一个ETL中的任务调度工具。
ETL Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
Airflow 是一个可编程、调度和监控的工作流平台。
Airflow 用户可以定义一组有依赖的任务,即有向无环图(DAG),按照依赖依次执行。
Airflow 提供了丰富的命令行和强大的Web UI,方便的管控调度任务,可以实时监控运行状态。
Linux crontab 不足
- 在多任务调度执行的情况下,难以理清任务之间的依赖关系
- 不便于查看当前执行到哪一个任务
- 任务执行失败时没有自动的重试和报警机制
- 不便于查看执行日志,即不方便定位报错的任务和错误原因
- 不便于查看调度流下每个任务执行的起止消耗时间,这对于优化task作业是非常重要的
- 没有记录历史调度任务的执行情况,而这对于优化作业和错误排查是很重要的
ETL 的常见痛点
- 日益增加的数据量
- 快速排查任务失败的原因
- 每个新工具都要重新学习新的配置规范
- 重试,监控,报警
- 敏捷高效的开发以满足业务需求
- 不均衡的数据峰值
使用场景
- 监控自动化工作的情况(通过web UI和各个worker上记录的执行历史)
- 自动处理并传输数据
- 为机器学习或推荐系统提供一个数据管道和使用框架
- 做代码部署调度
安装
单机版本地安装
本地安装Airflow非常简单,只需要按照官网的 Running Airflow locally 教程复制相应命令即可。
容器化安装
官网文档Running Airflow in Docker,需要提前将Docker和docker-compose装好。
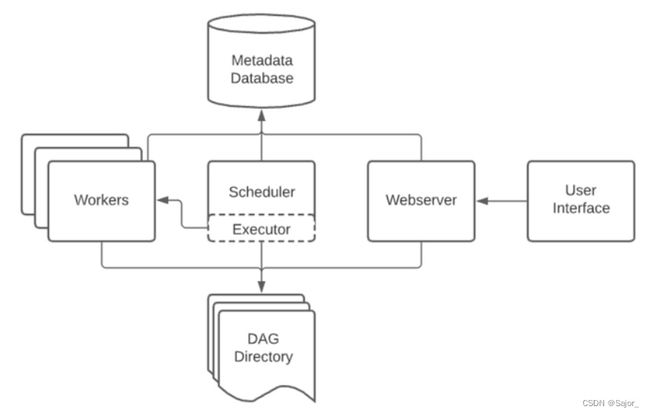
系统流程图
单机版

基本概念
DAG: 即一个工作流,一个DAG由一系列的TASK组成。
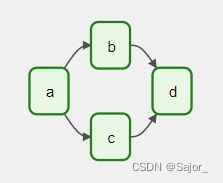 

DAG RUN: 即一次DAG工作流的执行。一个DAG在不同时间触发会生成一次 DAG RUN。
TASK: 任务,Airflow中最小的执行单位,一群TASK组成一个DAG,TASK之间有相互依赖的关系。
这里有三种基本的TASK类型
- Operator:任务模板
- Sensor:传感器
- TaskFlow:其他Python代码
具体模块
Scheduler/调度器
调度器通常作为服务运行,是一种使用DAG定义结合元数据中的任务状态来决定哪些任务需要被执行以及任务执行优先级的过程。
调度器监控所有的DAG文件,加载文件中的变化,默认每分钟一次。
WebServer/web服务器 + User Interface/UI页面
提供图形页面,可以监控DAG运行状态,也可以对DAG操作。使用的是Gunicorn框架启动。
Metadata Database/元数据库
存储所有的DAG,任务定义,运行的历史,用户,权限等。
默认使用SQLite,可以支持MySQL、PostgreSQL。
Executor/执行器
Airflow中有多种执行器可选择,例如:
- SequentialExecutor: 单进程顺序执行任务,默认执行器,通常用于测试
- LocalExecutor: 多进程本地执行任务
- CeleryExecutor: 分布式调度,生产常用
- DaskExecutor: 动态任务调度,主要用于数据分析
- ...
Ariflow + Celery 图
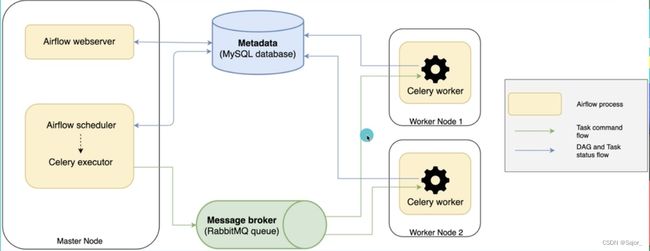 

Worker/执行者
用来执行Executor接收的任务,这些是实际执行任务逻辑的进程,由正在使用的执行器确定。
Operator/操作员
一个TASK中的具体操作模板,例如
- BashOperator-(airflow.operators.bash.BashOperator) 用来执行Bash脚本
- PythonOperator-(airflow.operators.python.PythonOperator) 调用Python函数
- EmailOperator-(airflow.operators.email_operator.EmailOperator) 发送邮件
- MySqlOperator-(airflow.providers.mysql.operators.mysql.MySqlOperator) 在MySQL中执行SQL脚本
- ...
Sensor/传感器
TASK的一种特殊Operator类型,由时间或事件触发。
例如我们在等待上游服务商处理后,读取服务商生成的文件,再执行后续任务。通常会定时使用Operator去检查上游服务商是否处理完毕,生成对应文件,未处理完毕则停止。
针对此场景,可以使用Sensor监听上游服务商。
UI介绍
GitHub上有UI 页面的介绍。
DAGs: 该页面展示所有的DAG任务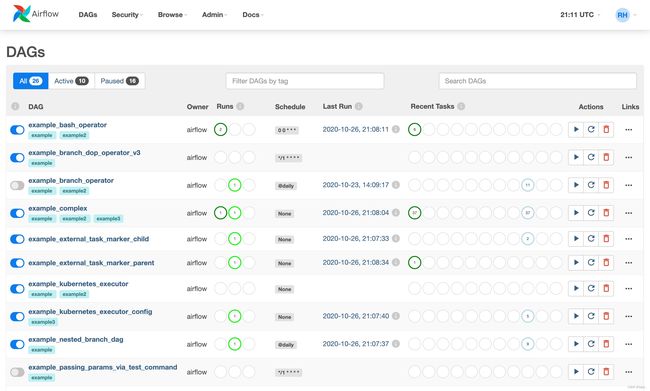 

Grid: 网格表示DAG中TASK的执行情况,每一列即是一个DAG RUN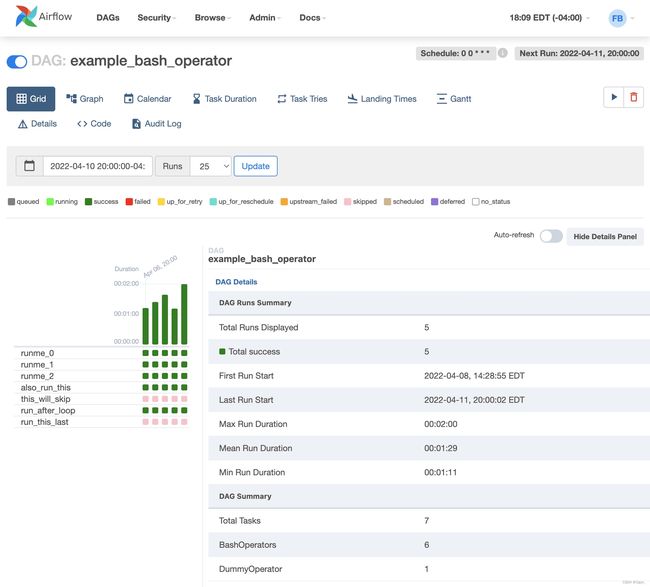 

Graph: 每个TASK的依赖关系可视化,以及在一次DAG RUN中的运行状态
 

Task Duration : 随着时间的推移,在不同任务上花费的总时间。 

Gantt: 甘特图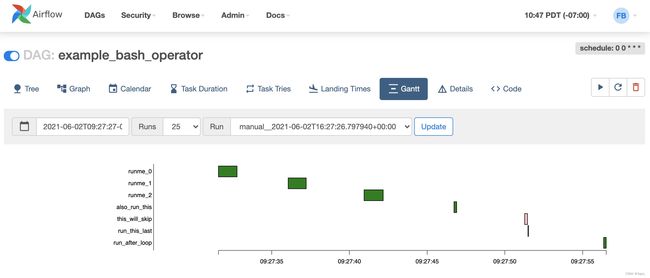 

Code: 源码页面
 

创建DAG
首先需要声明一个DAG,这里有三种方式
通过上下文管理with隐式调用
with DAG(
"my_dag_name", start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
schedule_interval="@daily", catchup=False
) as dag:
op = EmptyOperator(task_id="task")
标准构造方式
my_dag = DAG("my_dag_name", start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
schedule_interval="@daily", catchup=False)
op = EmptyOperator(task_id="task", dag=my_dag)
装饰器方式
@dag(start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
schedule_interval="@daily", catchup=False)
def generate_dag():
op = EmptyOperator(task_id="task")
dag = generate_dag()
参数
- dag_id 唯一标识
- default_args 默认参数
- description 描述
- schedule_interval 调度时间
- max_active_runs 最大并行执行个数
默认参数default_args
默认配置,通常在DAG中具体的Operator具有同样的配置,它下面有许多配置比如重试次数,邮件等。该参数支持将里面的参数和具体的TASK绑定。
default_args={
'depends_on_past': False,
'email': ['[email protected]'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
},
depends_on_past
设置为True时,表示只有当上一个TASK成功时,当前TASK才能启动。
可以配置一个邮件列表,触发邮件发送时将往列表中的邮箱发送对应邮件。
email_on_failure
TASK失败时是否触发邮件发送
email_on_retry
TASK重试时是否触发邮件发送
retries
失败重试总次数
retry_delay
失败重试时,之间的时间间隔
重启相关
catchup
DAG执行通常带有时间范围,假如三天该任务都没有启动成功,第四天运行时会将前三天的数据补上,无需启动三次依次补数据,这时该参数配置为False。
max_active_runs
要求并发执行的任务数,例如在数据库操作时,多个任务同时执行可能会引发死锁。
连接
在使用TASK之前,先提一下连接,在使用Airflow时,会经常连接数据库、邮箱、文件服务器等,将连接的账号密码写到代码中不是一个好的习惯。
Airflow提供了统一管理连接凭据的功能。在 Menu -> Admin -> Connections 中可以管理。
然后在代码中可以使用Hook的方式获取
from airflow.hooks.base_hook import BaseHook
conn = BaseHook.get_connection('connection_id')
也可以通过模板变量获取
echo {{ conn..host }}
创建TASK
一个TASK可以使用某个具体的Operator模板,例如上文提到的 BashOperator、PythonOperator,也可以使用自己实现的Operator。
BashOperator
from airflow.operators.bash import BashOperator
bash_task = BashOperator(
task_id='print_date',
# 这里也可以写脚本文件路径
bash_command='date',
)
PythonOperator
from airflow.operators.python import PythonOperator
python_task = PythonOperator(
task_id="python_task",
# fun为函数名
python_callable = fun
)
EmailOperator
from airflow.operators.email_operator import EmailOperator
email_task = EmailOperator(
task_id = "email_task",
to = "[email protected]",
subject = "Email Test",
html_content = """ Email Test
""",
dag=dag
)
MySqlOperator
首先需要安装拓展包apache-airflow-providers-mysql
# ubuntu
apt install libmysqlclient-dev
# centos
yum install mysql-devel
# pypi提到必须使用20.2.4版本的pip安装
python -m pip install pip==20.2.4
# 最后使用pip安装airflow依赖
pip install apache-airflow-providers-mysql
之后
from airflow.providers.mysql.operators.mysql import MySqlOperator
mysql_task = MySqlOperator(
task_id = "mysql_task",
# 提前配好连接
mysql_conn_id = "connection_id",
# 这里也可以写sql文件路径
sql = "select * from tb_anchor limit 100",
dag = dag
)
PostgresOperator
想使用这个模板之前,需要先安装一些库 libpq-dev、gcc、python-dev 见官网 和 Python的psycopg2包。
之后需要安装拓展包apache-airflow-providers-postgres
# ubuntu
apt install libpq-dev
pip install psycopg2
# 最后使用pip安装airflow依赖
pip install apache-airflow-providers-postgres
下图描绘了一个TASK由none开始可能经历的状态
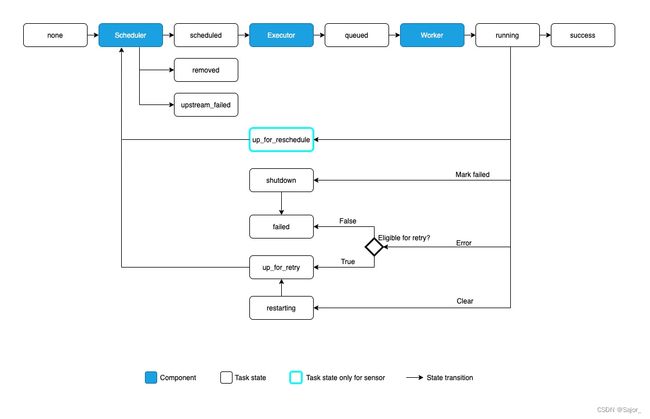 

TASK依赖关系
有两种常用方式声明任务依赖
使用 >> 和 <<
bash_task >> python_task >> [mysql_task, email_task]
使用 set_upstream 和 set_downstream方法
bash_task.set_downstream(python_task)
mysql_task.set_upstream(python_task)
还有更简洁的复杂关系
from airflow.models.baseoperator import cross_downstream
# Replaces
# [op1, op2] >> op3
# [op1, op2] >> op4
cross_downstream([op1, op2], [op3, op4])
还有链式
from airflow.models.baseoperator import chain
# Replaces op1 >> op2 >> op3 >> op4
chain(op1, op2, op3, op4)
# You can also do it dynamically
chain(*[EmptyOperator(task_id='op' + i) for i in range(1, 6)])
# Replaces
# op1 >> op2 >> op4 >> op6
# op1 >> op3 >> op5 >> op6
chain(op1, [op2, op3], [op4, op5], op6)
任务传参XComs
任务之间是互相隔离的,甚至可能在不同的机器上执行。
在PythonOperator中,默认函数的返回值,自动加入至XComs中,在其他任务中,可以直接通过Task id 获取返回值。
# Pulls the return_value XCOM from "pushing_task"
value = task_instance.xcom_pull(task_ids='pushing_task')
模板变量
Airflow 集成了Jinja。变量,宏和过滤器可以在模板中使用。
DAG 依赖
这里有两种方法支持一个DAG触发另一个DAG
- triggering 主动触发 TriggerDagRunOperator
- waiting 传感器触发 ExternalTaskSensor
trigger_next_dag = TriggerDagRunOperator(
# 触发的DAG ID
trigger_dag_id = "Sajor_Dag",
# 任务ID
task_id = "trigger sajor",
# 执行时间
execution_date = "{{ds}}",
# 是否等待触发的DAG完成
wait_for_completion = False
)
可以在 Menu -> Browse -> DAG Dependencies 中看到 DAG 之间的依赖关系。
动态DAG
因为使用Python,所以DAG不一定是由声明式创建,也可以使用循环来创建一堆DAG。
有时一个DAG中的业务应该分为多个DAG,但是代码又高度相似。
命令行工具
可以输入 airflow -h 查看命令行支持情况
开放API
Airflow提供了开放的API接口,并提供了Swagger文档。
该功能特性可以支持其他项目,使用网络请求的方式调用Airflow中的功能。
Pools池
可以在 Menu -> Admin -> Pools 定义Pool,来约定在这个Pool中的资源大小,将多个DAG指定使用该Pool时,所有DAG整体资源消耗不会超过该Pool中的设置。
这可以用于生产环境中,限制整体DAG的资源消耗,防止影响生产中正常业务的执行。
*最佳实践
官网提供了一些,DAG编写指南,应当到官网仔细阅读。
尽量使用分布式架构和容器
将Airflow各个组件分开,尤其是Scheduler和Worker要分开。
在内存不足时,Scheduler和Worker抢占资源,有可能会发生两者失联的情况,导致任务被多次重启。
容器化可以使用容器监控工具,监控各个模块的资源占用情况。
任务的幂等性
在设计每一个任务时,尽量做到可以重复多次运行,即使在运行过程中被打断了,下次运行依然不会出现问题。
多实现自己的Operator
在各种不同系统中下载数据时,最好实现自己的Operator,至少是Hook,相当于封装了外来的API。
定期清理元数据库
数据库中有些表会保存每一次任务的信息,日积月累,这些表就变得越来越大,搜索时就会变得很慢,所以定期去数据库清理这些表,可以提升系统的效率。
在确认不需要Xcom功能时,可以禁用掉,因为在PythonOperator中,函数的返回值默认会启动Xcom功能,每一次执行都会新增一条Xcom记录至数据库中,不管是否使用。
注意资源管理
- 链接数据库可以使用Connection,方便管理和查看。
- Variable在官方文档中提到不要滥用,因为Variable是存在元数据库中的,会耗用数据库连接。
- 在DAG定义文件中,不要调用昂贵的资源,例如调用三方API。因为调度器会频繁扫描DAG文件,在定义DAG外层,均会触发执行,会给服务器带来很大压力。包引用也应尽量放至最内层,如TASK层。
代码DEMO
from datetime import datetime, timedelta
from textwrap import dedent
# The DAG object; we'll need this to instantiate a DAG
from airflow import DAG
# Operators; we need this to operate
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from airflow.operators.email_operator import EmailOperator
from airflow.providers.mysql.operators.mysql import MySqlOperator
from airflow.models.xcom import XCom
with DAG(
'sajor',
# [START default_args]
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args={
'depends_on_past': False,
'email': ['[email protected]'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function,
# 'on_success_callback': some_other_function,
# 'on_retry_callback': another_function,
# 'sla_miss_callback': yet_another_function,
# 'trigger_rule': 'all_success'
},
# [END default_args]
description='Sajor\' Dags',
schedule_interval=timedelta(minutes=10),
start_date=datetime(2021, 1, 1),
catchup=False,
tags=['sajor'],
) as dag:
# [END instantiate_dag]
def get_variable():
from airflow.models import Variable
key = Variable.get("juaner")
print("Hello %s" % key)
def get_args(arg):
s = "Hello %s" % arg
print(s)
return s
# python中 * 关键字参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。
# python中 ** 关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
def get_kwargs(*arg, **kwargs):
print(arg)
print(kwargs)
print('-----------------')
# 使用公共参数 variable
python_task = PythonOperator(
task_id="python_task",
python_callable = get_variable,
)
# 函数传参
python_get_args = PythonOperator(
task_id="python_get_args",
python_callable = get_args,
op_kwargs={"arg": "Sajor"}
)
# 函数传参
python_get_kwargs = PythonOperator(
task_id="python_get_kwargs",
python_callable = get_kwargs,
op_kwargs={"id":"1","name":"zs","age":18},
op_args=[1,2,3,"hello","world"],
)
mysql_task = MySqlOperator(
task_id = "mysql_task",
mysql_conn_id = "zmt_185",
sql = "select * from test limit 100",
dag = dag
)
email_task = EmailOperator(
task_id = "email_task",
to = "[email protected]",
subject = "Email Test",
# Jinja 变量
html_content = """
Email Test
{{ ds_nodash }}
{{ dag }}
{{ conf }}
{{ next_ds }}
{{ yesterday_ds }}
{{ tomorrow_ds }}
{{ execution_date }}
""",
dag=dag
)
bash_task = BashOperator(
task_id='bash_task',
do_xcom_push=True,
# 这里可以写Jinja,获取其他TASK中的xcom数据。return_value这个变量名是固定的
# 也可以写脚本文件路径
bash_command='echo "I get: {{ ti.xcom_pull(task_ids="python_get_args", key="return_value") }}"',
)
python_task >> python_get_args >> python_get_kwargs >> bash_task
其他
PXL (Pocket Excel File) files 相较于 CSV (Comma Separated Values File) 是压缩过的,导入数仓时间更短,成本更低。csv无法处理二进制数据,无法表示Null值。
DBT 工具
官方视频资料: airflow summit