大数据高级开发工程师——工作流调度器Azkaban(1)
文章目录
- 工作流调度器Azkaban
-
- Azkaban介绍
-
- 为什么需要工作流调度系统
- 工作流调度实现方式
- Azkaban简介
- Azkaban架构
-
- Azkaban基本架构
- Azkaban架构的三种运行模式
-
- 1. solo server mode(单机模式)
- 2. two server mode
- 3. multiple executor mode
- Azkaban安装部署
-
- 编译 azkaban
-
- 1. 下载源码包
- 2. 修改build.gradle
- 3. 开始编译
- 4. 获得安装包
- multiple executor模式安装
-
- 1. 数据库准备
- 3. 解压软件安装包
- 4. 安装SSL安全认证
- 4. 安装azkaban web server
- 5. 安装azkaban executor server
- 6. 启动服务
- 7. 修改linux的时区问题
工作流调度器Azkaban
Azkaban介绍
- azkaban官网:https://azkaban.readthedocs.io/en/latest/

为什么需要工作流调度系统
- 一个完整的数据分析系统通常都是由大量任务单元组成
- shell脚本程序、java程序、mapreduce程序、hive脚本等;
- 各任务单元之间存在时间先后及前后依赖关系;
- 为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行。
- 例如,我们可能有这样一个需求,某个业务系统每天产生20G原始数据,我们每天都要对其进行处理,处理步骤如下所示:
- 通过Hadoop先将原始数据同步到HDFS上;
- 借助MapReduce计算框架对原始数据进行转换,生成的数据以分区表的形式存储到多张Hive表中;
- 需要对Hive中多个表的数据进行JOIN处理,得到一个明细数据Hive宽表;
- 将明细数据进行各种统计分析,得到结果报表信息;
- 需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
工作流调度实现方式
- 简单的任务调度:直接使用linux的crontab来定义;
- 复杂的任务调度:开发调度平台,或使用现成的开源调度系统,比如:ooize、azkaban、airflow、dophinscheduler等
Azkaban简介
- Azkaban 是由 Linkedin 开源的一个批量工作流任务调度器,用于在一个工作流(work flow)内以一个特定的顺序运行一组工作和流程。
- Azkaban 定义了一种 KV 格式文件(properties)来建立任务之间的依赖关系,并提供一个易于使用的 web 用户界面维护和跟踪你的工作流。
- 它有如下功能特点:
- 提供功能清晰、简单易用的web UI界面
- 方便上传工作流
- 调度工作流
- 能够杀死并重新启动工作流
- 工作流和任务的日志记录和审计
- 提供job配置文件快速建立任务和任务之间的关系
- 提供模块化的可插拔机制,原生支持command、java、hive、hadoop
- 安全性高:认证/授权(权限的工作)
- 提供分布式的多个执行服务器executor
- 提供conditional workflow工作流
- 提供功能清晰、简单易用的web UI界面
Azkaban架构
Azkaban基本架构

Azkaban 由三部分构成:
- Azkaban Web Server:提供了Web UI,是 azkaban 的主要管理者,包括 project 的管理、认证、调度、对工作流执行过程的监控等。
- Azkaban Executor Server:负责具体的工作流和任务的调度提交
- MySQL:用于保存项目、日志或者执行计划之类的信息
Azkaban架构的三种运行模式
1. solo server mode(单机模式)
- solo server mode 是 azkaban 的一个独立的实例
- 易于安装:不需要安装mysql,它内置了H2数据库,作为它的底层持久化存储
- 易于开始使用:管理服务器 web server 和执行服务器 execute server 都在一个进程中运行,任务量不大项目可以采用此模式
- 包含azkaban所有的功能
- 有兴趣的可以参考官网文档
2. two server mode
- web server 和 executor server运行在不同的进程
- 数据库为mysql,管理服务器和执行服务器在不同进程
- 这种模式下,管理服务器和执行服务器互不影响
3. multiple executor mode
- web server 和 executor server运行在不同的进程,executor server 有多个
- 该模式下,执行服务器和管理服务器在不同主机上,且执行服务器可以有多个
Azkaban安装部署
编译 azkaban
1. 下载源码包
- 这里选用azkaban4.0.0这个版本的源码进行重新编译,编译完成之后得到我们需要的安装包,然后进行安装
注意:1、使用
Gradle编译azkaban源码;2、需要使用jdk1.8或更高的版本来进行编译
- 访问地址
https://github.com/azkaban/azkaban/releases/tag/4.0.0,下载 azkaban 源码包
- 或者使用命令下载
wget https://github.com/azkaban/azkaban/archive/refs/tags/4.0.0.tar.gz
# 解压缩
tar -zxvf azkaban-4.0.0.tar.gz -C /Volumes/F/MyGitHub/azkaban
2. 修改build.gradle
- 使用gradle进行编译源码,此过程中需要去maven的仓库中下载各种jar包等文件,为了提高下载的速度,可以配置成从国内的maven仓库下载文件,方法如下:
cd azkaban-4.0.0
vim build.gradle
# 添加maven仓库url
maven{ url 'http://maven.aliyun.com/nexus/content/groups/public/'}
maven{ url 'http://maven.oschina.net/content/groups/public/'}

3. 开始编译
./gradlew build installDist -x test
# 开始下载,控制台会打印如下类似的日志
Downloading https://services.gradle.org/distributions/gradle-4.6-all.zip
..........
4. 获得安装包
编译成功后获得安装包和文件:
| 安装包 | 说明 |
|---|---|
| azkaban-web-server-0.1.0-SNAPSHOT.tar.gz | Azkaban Web服务安装包 |
| azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz | Azkaban 执行服务安装包 |
| azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz | Azkaban 单机安装包 |
| create-all-sql-0.1.0-SNAPSHOT.sql | 编译之后的sql脚本 |
| execute-as-user.c | C程序文件脚本 |
multiple executor模式安装
前提:某节点已经安装mysql,这里我们以node03已经安装mysql为例。若没有特殊说明,所有操作都是使用
hadoop普通用户操作。
1. 数据库准备
mysql -uroot -p123456
-- 设置密码的验证强度等级
set global validate_password_policy=LOW;
set global validate_password_length=6;
-- 创建数据库azkaban,用于存储使用azkaban框架过程中产生的数据
CREATE DATABASE azkaban;
CREATE USER 'azkaban'@'%' IDENTIFIED BY 'azkaban';
GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' identified by 'azkaban' WITH GRANT OPTION;
flush privileges;
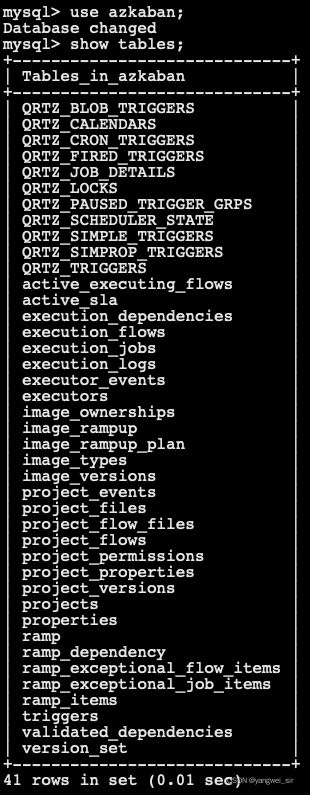
use azkaban;
source /bigdata/soft/create-all-sql-0.1.0-SNAPSHOT.sql;
exit;
- 更改 MySQL 包大小:防止 Azkaban 连接 MySQL 阻塞
sudo vim /etc/my.cnf
# 在文件末尾增加如下内容,然后保存、退出
max_allowed_packet=1024M
- 重启 mysql 服务
sudo /sbin/service mysqld restart
# 输出如下日志
Redirecting to /bin/systemctl restart mysqld.service
3. 解压软件安装包
mkdir -p /bigdata/install/azkaban-4.0.0
# 解压缩
tar -zxvf azkaban-web-server-0.1.0-SNAPSHOT.tar.gz -C /bigdata/install/azkaban-4.0.0/
tar -zxvf azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz -C /bigdata/install/azkaban-4.0.0/
cd /bigdata/install/azkaban-4.0.0/
# 重命名
mv azkaban-web-server-0.1.0-SNAPSHOT/ azkaban-web-server-4.0.0
mv azkaban-exec-server-0.1.0-SNAPSHOT/ azkaban-exec-server-4.0.0
4. 安装SSL安全认证
- 安装ssl安全认证,允许我们使用https的方式访问我们的azkaban的web服务,密码一定要一个个的字母输入,或者粘贴也行。
cd azkaban-web-server-4.0.0/
keytool -keystore keystore -alias jetty -genkeypair -keyalg RSA
- 具体输入如下:
- 密码都是azkaban
- 显示[Unknown]:直接敲回车
- 显示[no]:输入yes,回车
- jetty密码:azkaban

- 如果是英文环境,上图中的“是”用“yes”代替。此时,发现目录中多出一个秘钥文件
keystore
# keytool中有很多的cmd及option;查看keytool用法
[hadoop@node03 azkaban-web-server-4.0.0]$ man keytool
# 提示:搜索关键字,如-genkeypair
OPTION DEFAULTS
The following examples show the defaults for various option values.
-alias "mykey"
-keystore <the file named .keystore in the user's home directory>
-genkeypair 生成一个秘钥对(公钥、私钥)
-keyalg RSA 指定使用某算法生成秘钥对
4. 安装azkaban web server
- 第一步:
cd /bigdata/install/azkaban-4.0.0/azkaban-web-server-4.0.0修改 azkaban-web-server 的配置文件,vim conf/azkaban.properties,修改内容如下
# Azkaban Personalization Settings
azkaban.name=Azkaban
azkaban.label=My Azkaban
...
default.timezone.id=Asia/Shanghai
# Azkaban UserManager class
# azkaban内置的UserManager用户管理器,当启动web server时,`XmlUserManager`会读取配置文件`azkaban.properties`,然后解析`azkaban-users.xml`
user.manager.class=azkaban.user.XmlUserManager
# 此xml文件中用来配置azkaban的用户、组、角色
user.manager.xml.file=conf/azkaban-users.xml
...
# Azkaban Jetty server properties.
jetty.use.ssl=true
...
# 新增内容
jetty.ssl.port=8443
jetty.keystore=/bigdata/install/azkaban-4.0.0/azkaban-web-server-4.0.0/keystore
jetty.password=azkaban
jetty.keypassword=azkaban
jetty.truststore=/bigdata/install/azkaban-4.0.0/azkaban-web-server-4.0.0/keystore
jetty.trustpassword=azkaban
...
mysql.host=node03
...
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
- 说明:
- StaticRemainingFlowSize:正在排队的任务数;
- CpuStatus: CPU 占用情况
- MinimumFreeMemory:内存占用情况。 测试环境, 必须将 MinimumFreeMemory 删除掉,否则它会认为集群资源不够,不执行。
- 第二步:设置 azkaban 用户,
vim conf/azkaban-users.xml,修改如下
<user password="abc123" roles="myread" username="abcread"/>
<user password="abc123" roles="mywrite" username="abcwrite"/>
<user password="abc123" roles="admin" username="abcadmin"/>
<user password="abc123" roles="myread, mywrite" username="abcrwe" groups="groupx"/>
<group name="groupx" roles="myexe"/>
<role name="myread" permissions="READ"/>
<role name="mywrite" permissions="WRITE"/>
<role name="myexe" permissions="EXECUTE"/>

-
此文件格式解析,可以参考官网文档
-
user 格式
| Attributes | Values | Required? |
|---|---|---|
| username | 登录用户名 The login username. | 必须有 |
| password | 密码 The login password. | 必须有 |
| roles | role角色,如果是多个角色的话,中间逗号分隔 Comma delimited list of roles that this user has. |
非必须 |
| groups | 用户所属组,如果是多个组,中间逗号分隔 Comma delimited list of groups that the users belongs to. |
非必须 |
| proxy | 代理 Comma delimited list of proxy users that this users can give to a project | 非必须 |
- group 格式
| Attributes | Values | Required? |
|---|---|---|
| name | 组名 The group name | 必须有 |
| roles | role角色,如果是多个角色的话,中间逗号分隔 Comma delimited list of roles that this user has. |
非必须 |
- role 格式
| Attributes | Values | Required? |
|---|---|---|
| name | role角色名称 The role name | 必须有 |
| permissions | 权限,如果是多个权限的话,中间逗号分隔 Comma delimited list global permissions for the role |
必须有 |
- 可选的权限有
| Permissions | Values |
|---|---|
| ADMIN | 管理员权限,拥有azkaban中所有的权限 Grants all access to everything in Azkaban. |
| READ | 对每个project有只读权限 Gives users read only access to every project and their logs |
| WRITE | 允许用户上传文件、修改job的properties、删除project Allows users to upload files, change job properties or remove any project |
| EXECUTE | 允许用户执行任何flow Allows users to trigger the execution of any flow |
| SCHEDULE | 允许用户给任意flow添加或移除指定的调度 Users can add or remove schedules for any flows |
| CREATEPROJECTS | 如果创建project功能被锁死,有此权限的用户拥有创建project的权限 Allows users to create new projects if project creation is locked down |
- 官网配置
5. 安装azkaban executor server
- 第一步:
cd /bigdata/install/azkaban-4.0.0/azkaban-exec-server-4.0.0修改azkaban-exec-server的配置文件,vim conf/azkaban.properties,修改内容如下
# Azkaban Personalization Settings
azkaban.name=Azkaban
azkaban.label=My Azkaban
...
default.timezone.id=Asia/Shanghai
...
jetty.use.ssl=true
......
# 新增内容 添加如下5行内容
jetty.keystore=/bigdata/install/azkaban-4.0.0/azkaban-web-server-4.0.0/keystore
jetty.password=azkaban
jetty.keypassword=azkaban
jetty.truststore=/bigdata/install/azkaban-4.0.0/azkaban-web-server-4.0.0/keystore
jetty.trustpassword=azkaban
...
# Where the Azkaban web server is located
azkaban.webserver.url=https://node03:8443
...
mysql.host=node03
...
- 第二步:添加插件,将我们编译后的 C 文件
execute-as-user.c拷贝到/bigdata/install/azkaban-4.0.0/azkaban-exec-server-4.0.0/plugins/jobtypes
cp /bigdata/soft/execute-as-user.c /bigdata/install/azkaban-4.0.0/azkaban-exec-server-4.0.0/plugins/jobtypes
- 然后执行以下命令生成 execute-as-user
cd /bigdata/install/azkaban-4.0.0/azkaban-exec-server-4.0.0/plugins/jobtypes
sudo yum -y install gcc-c++
gcc execute-as-user.c -o execute-as-user
sudo chown root execute-as-user
sudo chmod 6050 execute-as-user

- 第三步:修改配置文件
vim commonprivate.properties,增加或修改如下内容
# true: 表示azkaban的登录用户,同时作为linux服务器系统的用户
execute.as.user=true
azkaban.native.lib=/bigdata/install/azkaban-4.0.0/azkaban-exec-server-4.0.0/plugins/jobtypes
# 表示,这些azkaban用户(linux系统用户)都属于`myazkaban`用户组
azkaban.group.name=myazkaban
memCheck.enabled=false
- 将exec拷贝到另外两个节点,并修改所属用户
cd /bigdata/install/azkaban-4.0.0
scp -r azkaban-exec-server-4.0.0/ hadoop@node01:$PWD
scp -r azkaban-exec-server-4.0.0/ hadoop@node02:$PWD
# node01、node02上分别执行
cd /bigdata/install/azkaban-4.0.0/azkaban-exec-server-4.0.0/plugins/jobtypes
sudo chown root execute-as-user
sudo chmod 6050 execute-as-user
- 第四步:添加用户、用户组
- 需要在 3 个 exec 服务器中,创建用户
abcrwe、用户组myazkaban,并且用户abcrwe属于用户组myazkaban - 为了解决权限问题,同时将用户
abcrwe添加附属组hadoop中 - 此处以
abcrwe用户为例(如果使用其他用户,按照此方式创建即可)具体命令如下
- 需要在 3 个 exec 服务器中,创建用户
# node01、node02、node03都执行如下命令
sudo groupadd myazkaban
[sudo] hadoop 的密码:
sudo useradd -g myazkaban abcrwe
sudo passwd abcrwe
新的 密码:123456
重新输入新的密码:
# 将 abcrwe 添加附加用户组
sudo usermod -a -G hadoop abcrwe
# 查看用户 abcrwe
sudo id abcrwe
uid=1002(abcrwe) gid=1002(myazkaban) 组=1002(myazkaban),1001(hadoop)
- exec 服务器在执行 flow 时,会在
/bigdata/install/azkaban-4.0.0/azkaban-exec-server-4.0.0目录创建目录executions,为了解决权限问题,3台节点都需要做如下操作
cd /bigdata/install/azkaban-4.0.0/azkaban-exec-server-4.0.0
mkdir executions
sudo chown :myazkaban executions/
6. 启动服务
- 第一步:启动azkaban exec server
# node01
cd /bigdata/install/azkaban-4.0.0/azkaban-exec-server-4.0.0
bin/start-exec.sh
# 关闭exec server: `bin/shutdown-exec.sh`
jps
14014 AzkabanExecutorServer
- 第二步:激活exec-server,每次启动exec都需要激活
# node01
cd /bigdata/install/azkaban-4.0.0/azkaban-exec-server-4.0.0
curl -G "node01:$(<./executor.port)/executor?action=activate" && echo
# 输出
{"status":"success"}
- 分别在 node02、node03 上启动 exec server 并激活
# node02
bin/start-exec.sh
jps
curl -G "node02:$(<./executor.port)/executor?action=activate" && echo
# node03
bin/start-exec.sh
jps
curl -G "node03:$(<./executor.port)/executor?action=activate" && echo
- 三个节点的exec server都启动后,可以去mysql中确认下,node03执行命令
mysql> select * from executors;
+----+--------+-------+--------+
| id | host | port | active |
+----+--------+-------+--------+
| 1 | node01 | 44066 | 1 |
| 2 | node02 | 40791 | 1 |
| 3 | node03 | 41330 | 1 |
+----+--------+-------+--------+
3 rows in set (0.00 sec)
- 发现,确实有3个exec server,active=1,表示已激活
- 第三步:启动 azkaban-web-server
# node03
cd /bigdata/install/azkaban-4.0.0/azkaban-web-server-4.0.0
bin/start-web.sh
# 关闭web server命令:`bin/shutdown-web.sh`
jps
8142 AzkabanWebServer
- 宿主机浏览器访问地址:https://node03:8443

- 登录后,进入界面

7. 修改linux的时区问题
-
之前在安装虚拟机时,已经设置时区为“亚洲/上海”所以不用担心时区问题,不需要修改时区
注:先配置好服务器节点上的时区
-
但是如果你的时区不是“亚洲/上海”,那么需要修改成此时区
-
确认时区 :
CST +0800表示时区是东八区(“亚洲/上海”)
$ date +"%Z %z"
CST +0800
- 生成时区配置文件Asia/Shanghai,用交互式命令 tzselect 即可
# 拷贝该时区文件,覆盖系统本地时区配置
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime