char和wchar_t的关系以及wprintf的应用
算法 Linux linux
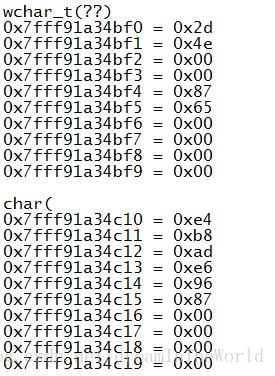
内存里的wchar_t和char
字符串存储是转换成对应的编码按16进制字节存储
可以通过查看内存中存储的字节了解字符串对应的编码
#include 
“中文”的编码 (Unicode : 2D 4E 87 65), (UTF-8 : E4 B8 AD E6 96 87 )
打印出内存中对于wchar_t和char的存储情况可以看到
wchar_t对应的是Unicode编码,而char对应的则是utf-8编码(因为CPP文件本身就是utf-8编码)
wchar_t数据类型一般为16位或32位,但不同的C或C++库有不同的规定,如GNU Libc规定wchar_t为32位
总之,wchar_t所能表示的字符数远超char型
win32 中wchar_t为16位 Linux中是32位
下面分别在64位系统和32位系统中运行结果
无论在64位系统还是32位中 wchar_t占用的字节数都是4字节(32位)

setlocale的作用
当向终端 控制台输出wchar_t类型的字符时,需要设置setlocale
因为通常终端、控制台环境自身是不支持UCS系列的字符集编码的,
使用流操作函数时(printf),在标准/RT库实现的内部会将UCS字符转换成合适的本地ANSI编码字符,
转换的依据就是setlocale设定的活动locale,最后将结果字符序列传递给终端
可以注释掉setlocale函数的调用,输出情况就是这样:
下面看看输出-N的情况
把输出的%S换成%s
把第12行换成 wprintf(L”\nwchar_t(%s)\n”, wstr);

这是因为ascii码表中(0x2D对应减号/破折号-), (0x4E对应大写字母N),刚好是在ascii系列编码的范围内(0-127)
不符合utf-8的编码规则 所以以ascii的标准输出字符串
那么就是说 %s 是按照char的格式输出字符串内容 刚好遇到后面的0x00结束字符串。
wchar_t和char的相互转换
UTF-8就是在互联网上使用最广的一种unicode的实现方式
他们之间的转换算法是固定的 所以Linux系统也提供了API(wcstombs和mbstowcs)供开发者直接调用转换
windows下面提供的API是MultiByteToWideChar和WideCharToMultiByte
转换规则可以查看 http://blog.csdn.net/dreamintheworld/article/details/77697914
#include "0x%02x ", (unsigned char)result[i]);
}
wprintf(L"\n\n");
return 0;
} 
#include "%p = 0x%02x\n", ch+i, (unsigned char)ch[i]);
}
wprintf(L"\n\n");
return 0;
} 
优质链接
http://club.topsage.com/thread-2227977-1-1.html