计算机组成原理-流水线技术学习笔记1
目录
一,处理器性能公式
二,RSIC中的五级流水线
三,流水线中指令间的相互作用
结构危害structural hazard
数据危害data hazard
控制危害control hazard
四,CPI计算
五,应对结构性危害Structural Hazards
六,数据危害Data Hazards 的类型
RAW hazard,Read-after-Write
WAR hazard,Write-after-Read
WAW hazard,Write-after-Write
七,解决数据危害的三种策略
互锁 Interlock
绕过 Bypass
预测 Speculate
八,针对RAW hazard的值预测
九,控制危害 Control Hazards
十, 分支跳转延迟间隙Branch Delay Slots
十一,在五级流水线中,为什么不能给每个周期都分配指令,从而导致CPI>1?
十二,陷阱和中断 Traps and Interrupts
异常 Exception
中断 Interrupt
陷阱Trap
十三,异步中断
十四,陷阱traps
陷阱处理 Trap Handler
同步陷阱Synchronous Trap
精确陷阱Precise traps
十五,Latency 和 bandwidth
一,处理器性能公式

程序运行的时间 = 程序中的指令数 × 一条指令需要的周期数 × 每个周期所需的时间
其中:
- 一段程序所含的指令数,取决于该程序的源码source code,编译器技术compiler technology以及指令集架构ISA。
- 每条指令所需的周期数(Cycles per instructions, CPI),取决于ISA和处理器架构µarchitecture
- 每个周期所需的时间,取决于处理器架构以及基础工艺base technology
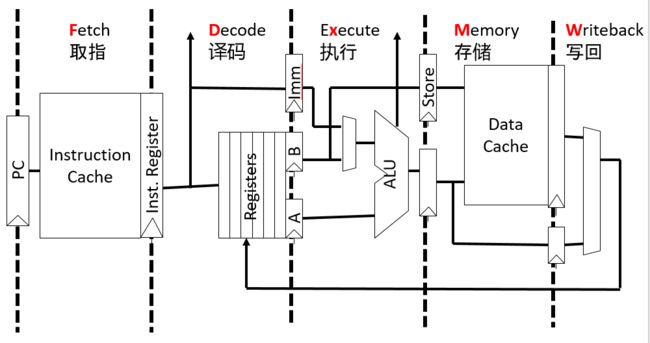
二,RSIC中的五级流水线
三,流水线中指令间的相互作用
结构危害structural hazard
流水线中一条指令需要另外一条指令正在使用的资源
数据危害data hazard
当前指令的执行依赖于先前指令所产生的数据值。
控制危害control hazard
当前指令的执行依赖于先前指令所产生的下一条指令的地址,可能是用于分支跳转或者异常处理。
处理这些危害会让流水线中产生气泡bubbles,并且是的CPI>1.
四,CPI计算
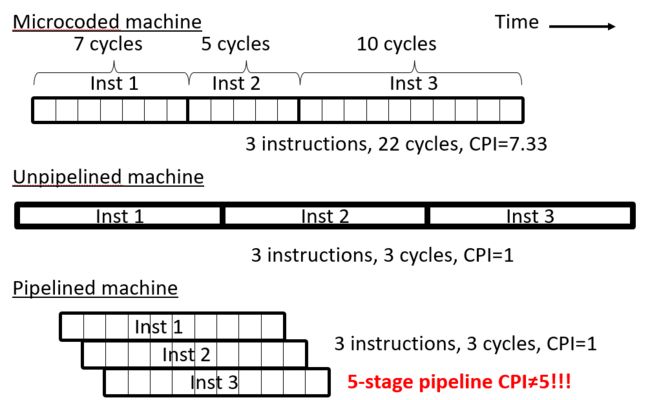
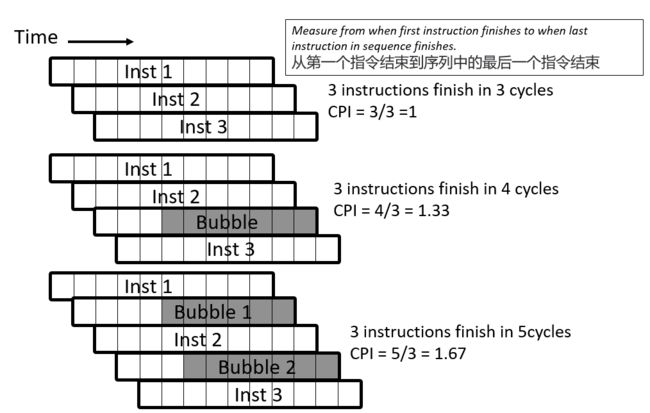
五,应对结构性危害Structural Hazards
Structural hazard 通常发生在两条指令同时需要同一个硬件资源对的时候,在硬件上,可以通过暂停新的(newer)指令对该资源的访问,直到先前(older)的指令访问完成。
结构性危害总是可以通过增加更多的硬件设计来避免,比如两条指令在同一时间,需要同一个端口port来访问内存,硬件上可以通过多设计一个访问内存的port来避免这种情况。
典型的RISC五级流水线在设计上没有结构性危害,但是许多RISC实现在多周期单元(如乘法器、除法器、浮点单元等)上存在结构性危害,并且可能存在寄存器回写端口。
六,数据危害Data Hazards 的类型
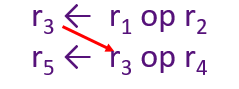
假设有如下伪指令:
![]()
其中r表示不同的寄存器,上面伪指令的含义为:Ri 与 Rj进行操作,并将结果保存至Rk中。
以上述伪指令为基础,可以有三种数据危害:
RAW hazard,Read-after-Write
指令1和指令2存在数据依赖关系Data-dependence,写完R3之后再读,需要先求出寄存器R3的值,然后第二条指令才能顺利执行:
WAR hazard,Write-after-Read
指令1和2存在反向依赖关系Anti-dependence,需要先读R1,然后再写,如果不等指令1执行完毕,就执行指令2,可能会导致指令1执行错误,因为R1的值可能先会被指令2更新:
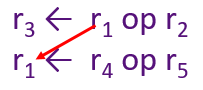
WAW hazard,Write-after-Write
指令1和指令2存在输出依赖Output-dependence, 指令1和指令2都是同时往同一个寄存器R3中写入数据,按照程序的语义,R3的值最后应该是被指令2更新:

七,解决数据危害的三种策略
互锁 Interlock
在流水线的某个阶段将受依赖影响的指令暂停,等待危害消除后,再开始。
绕过 Bypass
尽可能早地绕过依赖的数据值
预测 Speculate
对依赖的数据进行预测,如果猜错了就纠正。
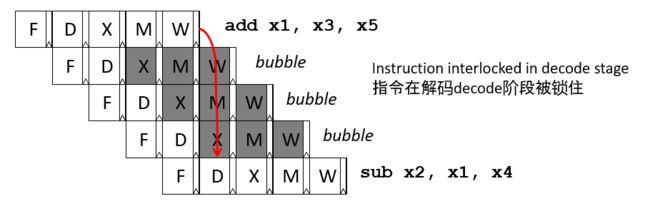
下面以如下两条指令为例:

指令2依赖于指令1所产生的结果值X1,如果是采用interlock的方式,指令2在decode阶段就会被锁住,它要等到指令1执行完后, 才能拿到X1的值,因此会产生三个流水线气泡。
如果采用绕过bypass的方法,它会然后指令1流水线中的ALU,直接把指令1的计算结果传递到指令2的Execute阶段,这样将无气泡产生:

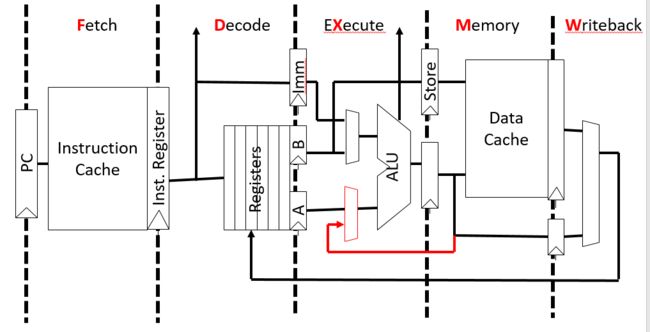 如上图红线所示,为增加的硬件结构,
如上图红线所示,为增加的硬件结构,
此外,还有一种完全绕过(Fully Bypassed Data Path)的硬件设计:

八,针对RAW hazard的值预测
与其等待一个数据值,也可以尝试去预测,当然只在某些限制的场景下有效:
- 分支预测,Branch prediction
- 栈指针更新,Stack pointer updates
- 内存地址歧义,Memory address disambiguation
九,控制危害 Control Hazards
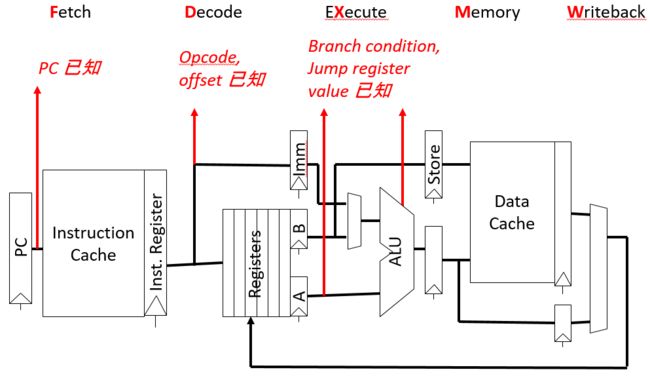
PC(Program Counter)寄存器里保存着处理器即将执行的下一条指令的地址。计算下一个PC的值,需要以下元素:
- 对于无条件的跳转,需要操作码Opcode, 当前的PC,以及偏移量 offset。
- 对于跳转寄存器Jump Register,需要操作码Opcode, 寄存器的值以及偏移量offset。
- 对于条件分支Conditional Branches,需要操作码Opcode, 保存条件的寄存器, PC和offset。
- 对于所有其他的指令,需要操作码和PC。
在流水线的各个阶段,可以获取到的控制流信息:
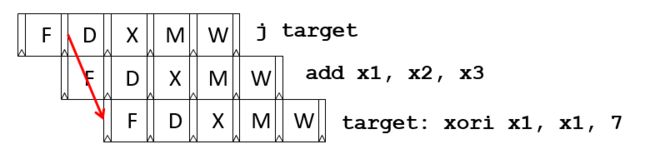
十, 分支跳转延迟间隙Branch Delay Slots
早期的RISC采用流水线microcode engines的思想,改变了ISA语义,总是在控制流发生变化之前执行分支/跳转后的指令,如下示例:

按照正常的语义,上述指令的执行顺序为:0x100 -> 0x205 -> 0x104,但是0x104会在target之前执行。
在指令跳转的延迟间隙,软件必须用一些有用的工作来填充,或者用显式的 NOP (No OPeration)指令来填充。
十一,在五级流水线中,为什么不能给每个周期都分配指令,从而导致CPI>1?
- 完全绕过的硬件结构实现起来太过昂贵:
- 通常会提供一些经常使用的路径
- 一些不经常使用的旁路结构会增加周期时间,从而抵消了减小CPI带来的好处。
- 加载指令有两个周期(two-cycle)的延迟
- 指令加载完后不能马上被使用。
- MIPS-I ISA定义了加载延迟间隙(load delay slots),一种对软件可见的流水线hazard,编译器可以分配独立的指令或者插入NOP指令去避免hazard。在MIPS-II中被移除,MIPS-II在硬件上使用interlock。
- MIPS:“Microprocessor without Interlocked Pipeline Stages”
- 跳转或者条件分支可能会造成流水线气泡(bubbles)
- 如果没有延迟间隙,将会终止后续指令的执行。
对软件可见的延迟间隙(delay slot)机器而言,编译器会插入大量的NOP指令,在此期间执行,以减小CPI,但是也增加了程序的总指令数。
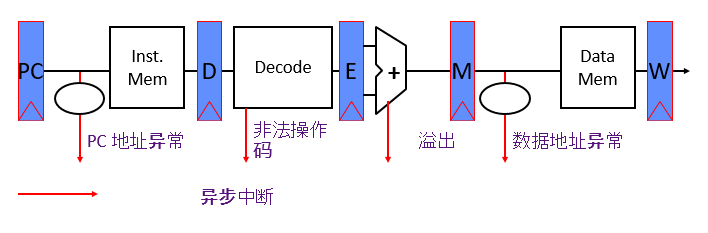
十二,陷阱和中断 Traps and Interrupts
异常 Exception
An unusual internal event caused by program during execution
程序在执行过程中引起的异常内部事件。比如页错误page fault, 算术溢出arithmetic underflow
中断 Interrupt
An external event outside of running program。
在正在运行的程序之外的事件。
陷阱Trap
Forced transfer of control to supervisor caused by exception or interrupt,Not all exceptions cause traps,由于异常和中断,强制将控制权转移给supervisor,并不是所有的异常都会导致traps。
十三,异步中断
一个IO设备通过断言一个优先中断请求行,来获取注意。当处理器打算处理这个中断时:
- 它会先在指令i处停止当前的程序,完成指令i之前所有的指令,也就是到i-1为止(精确中断,precise interrupt )。
- 它会将指向指令i处的PC保存到一个特殊的寄存器(EPC)中。
- 它会禁用中断,并将控制权转移到运行在supervisor模式下的指定中断处理程序
十四,陷阱traps
改变正常的控制流:
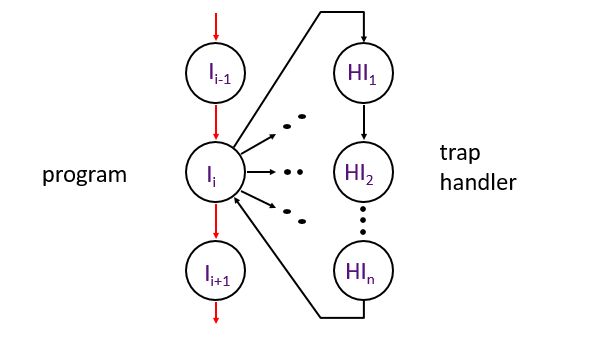
一个来自程序外部或者内部的事件,需要被其他系统或程序处理,这种事件从软件的角度来讲较为稀有或者异常。
陷阱处理 Trap Handler
1,在使能中断去允许嵌套中断之前,需要先保存EPC寄存器。
- 需要一个指令将EPC的值移动到通用寄存器GPRs中
- 需要在EPC被保存前屏蔽其他中断。
2,需要读取能够反映当前trap产生原因的状态寄存器。
3,使用一个特殊的直接跳转指令ERET (return-from-environment) :
- 使能中断
- 将处理器恢复至user模式
- 恢复硬件状态信息,和控制状态
同步陷阱Synchronous Trap
同步陷阱是由特定指令的异常引起的。
通常,该指令无法完成,需要在异常处理后重新启动,同时,需要撤销一个或多个已经执行完毕的指令所带来的影响。
在系统调用陷阱的情况下,该指令被认为已经完成。需要一种涉及特权模式privileged mode的的特殊跳转指令。
在五级流水线中,异常的处理:
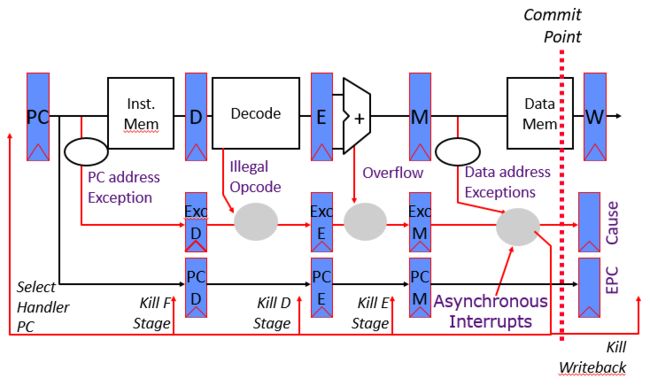
精确陷阱Precise traps
干净地停在一条指令后,先前的指令都已完成,没有后续的指令会改变架构的状态。
十五,Latency 和 bandwidth
- Latency延迟:用时间(秒,seconds)或者周期数cycles来表示,是一个操作从开始到结束所需要的时间,
- Bandwidth带宽:用每秒或者每个周期所执行的操作数来表示,是操作所执行的速率。
- Occupancy占有率:用时间(秒,seconds)或者周期数cycles来表示,是某个单元在执行中被阻塞的时间(structural hazard)