深入理解搜索引擎-排序算法
众所周知,在搜索引擎领域,无论你是用户还是内容生产者,搜索引擎的结果排序对你来说都是至关重要的。对于用户而言,一个好的排序会给你一个非常好的搜索体感,你无需查看更多结果就能找到你的答案。对于内容生产者而言,无论是大搜还是垂搜,排序结果的好坏直接影响你内容的流量和点击。调查显示,搜索引擎结果的点击主要集中在top10的结果中, 可以参考下图:
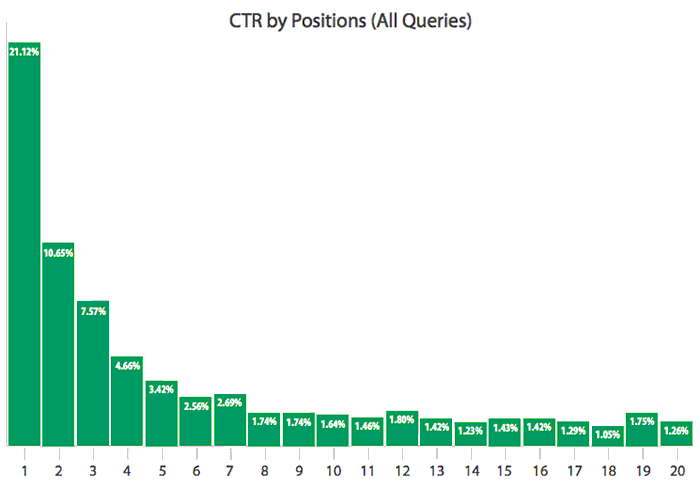
从上图可看到,第一页top10的总点击率是57%,也就是说43%的用户要么往后面翻页,要么什么也没点击。这也是为什么企业争相做SEO的原因,这也是为什么会衍生出搜索引擎的竞价排名机制的原因,如下图。那么今天我们就来讲讲搜索排序是如何实现。
搜索结果排序是搜索引擎最核心的部分,之前我们说过召回决定了搜索引擎质量的上限,而排序算法则是最大限度的拟合这个上限。
评估用户输入的query与引擎中的内容doc的相关性大小,这依赖于搜索引擎所采用的的检索模型。检索排序从信息检索学科建立之初就一直是研究重点,发展至今,已经有了很多较为成熟的模型。按照搜索排序的流程分为,召回粗排,精排层和重排序,重排序阶段主要考虑到相关业务诉求和多样性要求,偏业务端,所以本文只介绍召回粗排和精排模型。
召回粗排模型
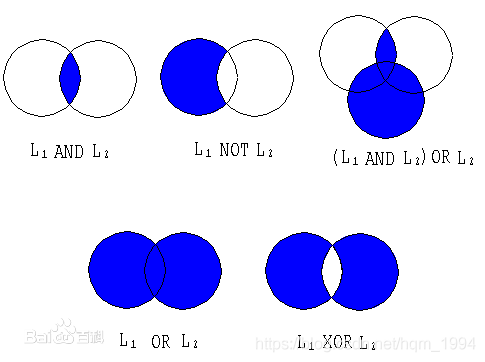
【布尔模型】
检索模型中最简单的一种,其数学基础是集合论。在布尔模型中,query和文档doc的相关性通过布尔代数运算来判定。布尔代数运算也就是所谓的"与/或/非",“and/or/not”,通过这些逻辑连接词将用户的查询词串联作为用户需求的表达。
【向量空间模型】
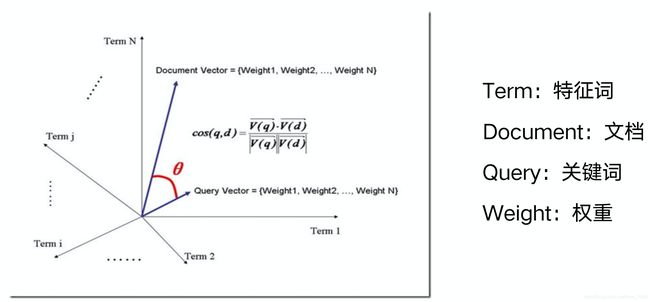
向量空间模型最初由信息检索领域奠基人Salton教授提出,经过信息检索学科多年的探索,目前已经是非常基础并且成熟的检索模型了。向量空间模型把用户的query和每一个文档doc都表示成t维特征组成的向量,特征权重计算可使用TF-IDF(在《索引技术》中有详细讲过)。
在实际查询过程中,将query的向量与文档doc的向量进行余弦相似度计算,它认为,值越大,夹角越小就代表query和doc越相似,故而可以用此相似度计算结果作为排序因素。向量空间模型发展至今,不仅仅在搜索领域,在NLP及文本挖掘等诸多领域也是普遍采用的有效工具。
【概率模型】
概率检索模型是从概率排序原理推导出来的,其基本思想是:用户输入一个query,搜索引擎能够在搜索结果排序时按照文档doc集合和用户输入的query的相关性由高到低排序,那么这个搜索系统的准确性是最优的,而在文档doc集合的基础上尽可能准确地对这种相关性进行评估则是其核心。
按照如下思路进行思考:首先,我们可以对查询后得到的文档进行分类:相关文档和非相关文档。这个可以按照朴素贝叶斯的生成学习模型进行考虑。如果这个文档属于相关性的概率大于非相关性的,那么它就是相关性文档,反之属于非相关性文档。最经典的就是BM25排序模型,而这也是开源搜索引擎ElasticSearch的默认相关性排序算法。

机器学习精排模型
【LR-逻辑回归】
LR模型是广义线性模型,从其函数形式来看,LR模型可以看做是一个没有隐层的神经网络模型(感知机模型)。公式如下:

LR模型一直是CTR预估问题的benchmark模型,而CTR预估问题本身就是排序问题的结果,排序做得越好,CTR则会越高。LR可以处理大规模的离散化特征、易于并行化、可解释性强。同时LR有很多变种,可以支持在线实时模型训练(FTRL)。然而由于线性模型本身的局限,不能处理特征和目标之间的非线性关系,因此模型效果严重依赖于算法工程师的特征工程经验。
【GBDT+LR】
既然特征工程很难,那能否自动完成呢?模型级联提供了一种思路,典型的例子就是Facebook 2014年的论文中介绍的通过GBDT(Gradient Boost Decision Tree)模型解决LR模型的特征组合问题,结构如下:
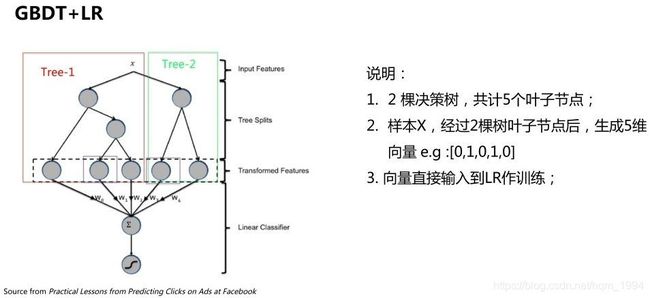
此方案可以看成利用GBDT替代人工实现连续值特征的离散化,而且同时在一定程度组合了特征,可以改善人工离散化中可能出现的边界问题,也减少了人工的工作量。GBDT本质是对历史的记忆,而GBDT+LR则强化了GBDT细粒度的记忆能力!
【FM/FFM】
FM(Factorization Machine)是由Konstanz大学Steffen Rendle(现任职于Google)于2010年最早提出的,旨在解决稀疏数据下的特征组合问题。
与传统的简单线性模型不同的是,因子分解机考虑了特征间的交叉,对所有嵌套变量交互进行建模(类似于SVM中的核函数),因此在搜索推荐和计算广告领域关注的点击率CTR(click-through rate)和转化率CVR(conversion rate)两项指标上有着良好的表现,故而可以很好的作用于结果排序。此外,FM的模型还具有可以用线性时间来计算,以及能够与许多先进的协同过滤方法(如Bias MF、svd++等)相融合等优点。
公式如下:
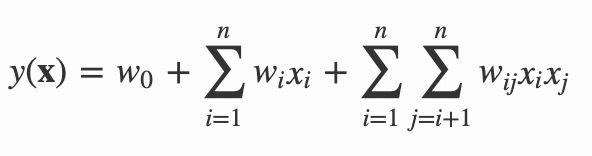
其中,n 代表样本的特征数量,xi 是第 i 个特征的值,w0、wi、wij 是模型参数。
FFM(Field Factorization Machine)是在FM的基础上引入了“场(Field)”的概念而形成的新模型。不详细赘述,后面会详细讲每一个算法和实践。
【深度学习DNN】
此前我们讲过使用DNN来做召回,DNN的能力不止如此,也可以用于排序场景。在前面的精排模型中,绝大多数的特征都是大规模离散化的特征,而且交叉类的特征十分重要,尽管GBDT,FM等具有一定交叉特征能力型,但交叉的能力十分有限,仍然脱离不了特征工程。而dnn类的模型拥有很强的模型表达能力,而且其结构也是“看上去”天然具有特征交叉的能力。利用基于dnn的模型做排序主要有两个优势:
- 模型表达能力强,能够学习出高阶非线性特征。
- 容易扩充其他类别的特征,比如在特征拥有图片,文字类特征的时候。
不过现在也有很多场景结合DNN+GBDT+FM融合模型实现排序,总体结构是:
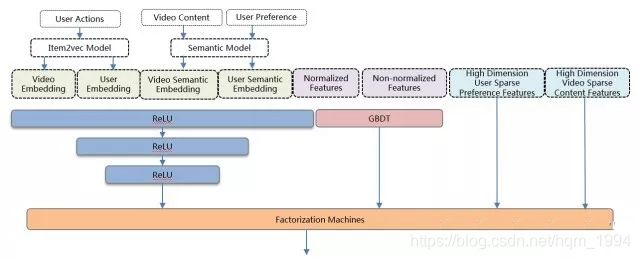
- DNN模型:使用全连接网络,共三个隐藏层。DNN能从具有良好数学分布的特征中抽取深层信息,比如embedding特征,归一化后统计特征等等
- GBDT模型:单独进行训练,输入包含归一化和未归一化的稠密特征。能处理未归一化的连续和离散特征。能根据熵增益自动对输入特征进行离散和组合。
- FM融合层:FM模型与DNN模型作为同一个网络同时训练。将DNN特征,GBDT输出和稀疏特征进行融合并交叉。
【深度模型之DeepFM模型】
DeepFM是哈工大与华为诺亚实验室联合提出的一种深度学习方法,它基于Google的经典论文Wide&Deep基础上,通过将原论文的wide部分(LR部分)替换成FM,从而改进了原模型依然需要人工特征工程的缺点,得到一个end-to-end 的深度学习模型。结构如下:
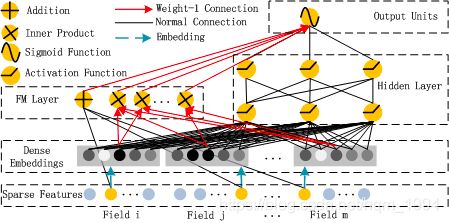
【深度模型之Bert模型】
BERT预训练模型既可用于召回也可用于排序,其最主要的优势在于其语义特征的表达,在排序任务中,将BERT和Learning To Rank的思想进行结合,将原始模型使用Pointwise Approach的模式改为Pairwise Approach模式,Pairwise Approach相当于BERT只考虑用户输入的query和两个候选文档之间的相关程度,而不考虑用户输入query与单个候选文档的相关度,所以改为PairWise模式,优化的目标任意两个候选文档的排序位次,这样更适合排序场景。
-
训练样本形式:Pointwise模式下样本是按照

-
损失函数:Pointwise模式下模型使用的Cross Entropy Loss作为损失函数,优化目标是提升分类效果,而Pairwise模式下模型使用Hing Loss作为损失函数,优化目标是加大正例和负例在语义空间的区分度。

后续会针对每种算法进行详解,排序模型还有很多,如果想了解其他模型算法,记得留言,下回分享。

最后欢迎关注微信公众号:药老算法(yaolaosuanfa),带你领略搜索、推荐等数据挖掘算法魅力。