Spark:Streaming
目录
01:上篇回顾
02:今日目标
03:SparkStreaming基本原理
04:DStream的设计
05:DStream的函数
06:无状态计算模式场景
07:有状态计算模式场景
08:滑动窗口计算模式场景
09:集成Kafka:集成方式
10:集成Kafka:开发测试
11:集成Kafka:获取Offset
12:实时热点应用案例:需求
13:实时热点应用案例:开发环境构建
14:实时热点应用案例:需求一实现
15:实时热点应用案例:需求二实现
16:实时热点应用案例:需求三实现
17:Streaming中的Checkpoint机制
18:了解Streaming中Kafka Offset的管理
附录一:Streaming Maven依赖
附录二、Kafka集群操作
01:上篇回顾
https://blog.csdn.net/m0_57498038/article/details/119112951
-
SparkSQL中Sink数据源接口如何设计的?
-
语法
df/ds.write.mode .format .save/save(Path)/saveAsTable -
注意:写数据库,需要考虑插入更新的问题
-
-
SparkSQL如何集成Hive并如何实现开发?
-
设计:SparkSQL访问MetaStore
-
开发
-
DSL
-
step1:将Hive表的数据变成DataSet或者DataFrame:spark.read.table
-
step2:使用DSL进行处理
-
-
SQL:spark.sql直接使用SQL进行处理
-
-
应用场景
-
SparkSQL/Impala:分布式内存计算框架:SQL
-
|
-
代替Hive进行计算:Hive主要作用构建数据仓库
-
|
-
SQL
-
DDL:HiveSQL + MetaStore
-
DML:SparkSQL 、Impala
-
DQL:SparkSQL 、Impala
-
-
-
-
SparkSQL中如何定义UDF?
-
SQL:spark.register.udf(函数名,函数体)
-
DSL:val 函数名 = udf(函数体)
-
-
SparkSQL的开发方式有哪些?
-
Idea中开发,打成jar包,提交运行 / IDEA中直接运行
-
执行SQL脚本 / Beeline + Thirft Server
-
JDBC
-
-
SparkStreaming的功能、特点和应用场景是什么?
-
功能:使用微小时间的批处理基于SparkCore实现流式计算程序开发
-
特点
-
基本SparkCore:底层还是每个RDD数据处理
-
将动态数据基于时间切分为静态时间片数据
-
每个时间片的数据就是一个RDD的数据
-
-
高并发、高容错:RDD的特性
-
好使:所有逻辑的转换处理调用的都是RDD转换函数
-
-
区别
-
SparkCore:离线,程序会停止,Task运行是由触发函数触发运行
-
Streaming:准实时,程序不会停,按照时间批次运行
-
-
应用
-
适合于数据量并发比较小的实时计算场景
-
-
-
SparkStreaming中的驱动接口及数据抽象是什么?
//step1:驱动接口 val ssc = StreamingContext.getActiveOrCreate( //创建一个新的ssc () => { val conf = new SparkConf().appName.master.set(K,V) new StreamingContext(conf,Seconds(1)) } ) val ssc = StreamingContext.getActiveOrCreate( chk_path,//指定chk路径,用于判断是否已经有一个ssc //如果当前没有,调用函数构建一个新的 () => { val sparkConf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[3]") //设置Kafka每个分区消费的最大消息数 .set("spark.streaming.kafka.maxRatePerPartition", "10000") val context = new StreamingContext(sparkConf, Seconds(5)) //设置日志级别 context.sparkContext.setLogLevel("WARN") //设置checkpoint目录 context.checkpoint(chk_path) //调用处理逻辑 processData(context) context } ) //step2:实现处理 //将所有的数据读取放入一个时间集合中:DStream //DStream调用转换函数对数据进行处理 //将DStream的数据进行保存 //step3:启动并持久运行 ssc.start ssc.awaitTermination ssc.stop(true,true)
02:今日目标
-
SparkStreaming的基本原理
-
处理过程
-
DStream的设计
-
-
SparkStreaming的使用
-
==DStream的使用?==
-
DStream的Source数据源的使用:Kakfa
-
==作为Kafka的消费者:怎么保证消费的一次性语义?==
-
-
DStream的函数的使用
-
转换函数:基本与RDD是一致的
-
输出函数:Streaming没有触发函数,输出函数用于保存结果
-
print
-
-
-
DStream的Sink数据源的使用:Kafka、MySQL、Redis
-
-
基于不同业务模式处理
-
无状态模式
-
有状态模式
-
窗口计算模式
-
实时热点统计的分析案例
-
-
-
了解性内容
-
SparkStreaming程序如果故障怎么恢复之前的状态?
-
消费Kafka的数据怎么自己管理offset?
-
03:SparkStreaming基本原理
-
目标:了解SparkStreaming的基本原理
-
实施
-
以我们所写的WordCount程序为例,读取Socket的数据,进行词频统计
-
==step1:启动程序,启动Driver进程,Driver申请启动Executor进程==
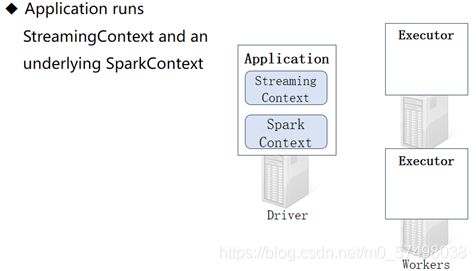
-
==step2:Driver会在某个Executor中启动一个子进程Receiver进程==
-
Received这个进程是一直持久运行的,负责接收读取到的数据,需要1coreCPU来维护运行
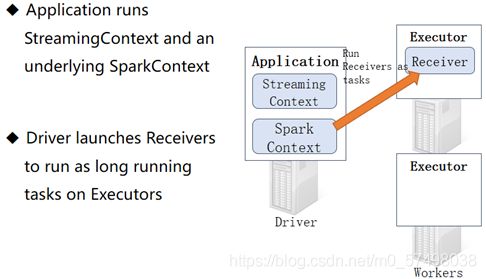
-
-
==step3:Received不断的接受数据,按照BlockInterval时间来划分数据==
-
什么是BlockInterval?
-
Batch Interval:每个批次的时间,每个批次的数据就是一个RDD的数据,计算时间
-
Batch Interval = 1s :每1s处理一次
-
DStream中每一秒产生1个RDD
-
-
Block Interval:数据划分时间,存储数据的分片的时间【每个分区的数据】,每到BlockInterval,就将这个时间产生的数据进行存储
-
属性:默认值为200ms
-
每200ms,就将这200ms产生的数据存储起来
-

-
-
-
数据怎么存储?
-
每个Block Interval所产生的数据存储在Executor的内存中
-
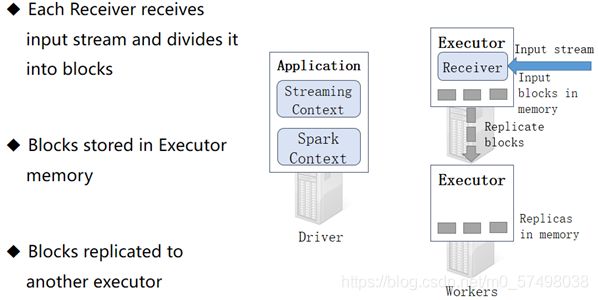
-
-
==step4:Receive不断缓存Block块 数据,并且将位置汇报给Driver==
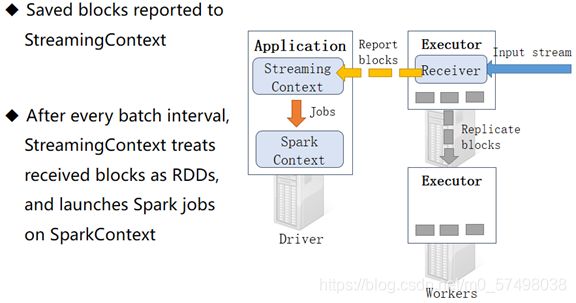
-
==step5:Driver判断是否达到BatchInterval,达到批次时间,就触发Task运行==
-
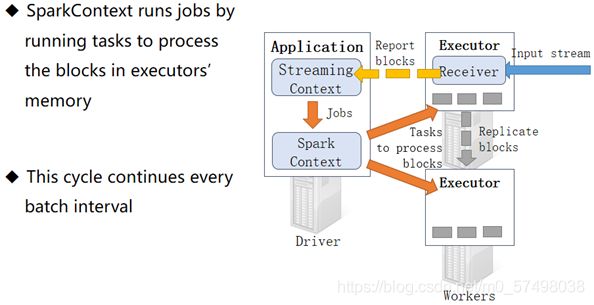
-
-
达到BatchInterval时间,将这个BatchInterval中所有的BlockInterval的数据从逻辑上构建为一个RDD
-
RDD分区数 = BatchInterval / BlockInterval
-
-
-
小结
-
了解SparkStreaming的基本原理
-
04:DStream的设计
-
目标:掌握DStream的设计
-
实施
-
SparkStreaming:基于SparkCore,基于无边界的数据流按照时间划分为多个有边界的数据
-
DStream:Seq[RDD],类似于一个无边界的数据集合,按照时间划分每个有边界的数据作为一个RDD
-
对无边界的数据处理,变成了对每个有边界的RDD的数据处理
-
SparkCore SparkStreaming SparkSQL StructStreaming RDD DStream DataSet DataSet 分布式集合【有限-静态】 分布式集合【无限-动态】 分布式表【有限-静态】 分布式表【无限-动态】 -
-
官方给定的描述
Discretized Stream or DStream is the basic abstraction provided by Spark Streaming. It represents a continuous stream of data, either the input data stream received from source, or the processed data stream generated by transforming the input stream. Internally, a DStream is represented by a continuous series of RDDs, which is Spark’s abstraction of an immutable, distributed dataset (see Spark Programming Guide for more details). Each RDD in a DStream contains data from a certain interval, as shown in the following figure.-
输入的数据流:会根据Batch Interval时间进行切分,每个Batch的数据会构建一个RDD
-
RDD的分区个数:Block Interval

-
数据流的转换:就是数据流中每个RDD的转换
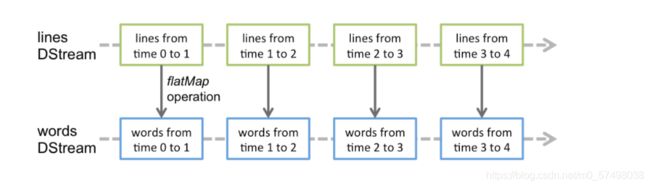
-
图例
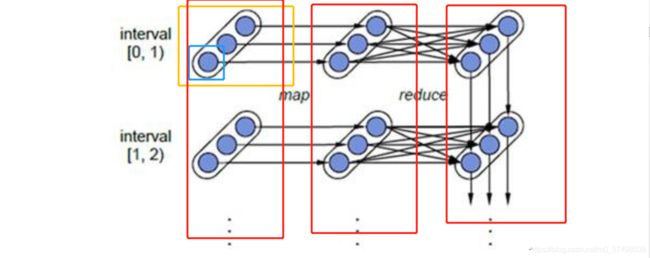
-
红色的线:每个红色的框线就是一个DStream,在时间方向上无限延伸
-
黄色的线:每个黄色的框线就是一个RDD,每个时间批次的数据就会构建一个RDD
-
蓝色的线:每个蓝色的框线就是一个分区,每个BlockInterval的数据就作为RDD的一个分区
-
-
-
-
小结
-
掌握DStream的设计
-
05:DStream的函数
-
目标:掌握SparkStreaming中DStream函数的使用
-
路径
-
step1:函数的应用
-
step2:特殊函数
-
-
实施
-
函数的应用
-
本质:所有DStream的转换就是RDD的转换,基本所有转换函数都是一致的
-
RDD:转换函数【返回一个新的RDD,Lazy模式】、触发【触发Task的运行】
-
DStream:转换【基本与RDD一致】、输出函数【没有触发函数,DStream是按照时间批次运行】
-
-
==转换:基本与RDD一致==
-
-
map
-
flatMap
-
filter
-
……
-
==输出==
-
print:打印数据到命令行
-
saveAsTextFile:将结果保存到文件系统
-
foreachRDD
-
……
-
-
特殊函数
-
tranform:基于DStream中的RDD进行编程,有返回值
-
类似于map函数
-
功能:取DStream中每个RDD进行处理,有返回值
-
定义
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U] //传递的参数为当前的rdd和rdd对应的时间 def transform[U: ClassTag](transformFunc: (RDD[T], Time) => RDD[U]) -
使用
val rsStream = inputStream //基于DStream的编程 // .filter(line => line.trim.length > 0) // .flatMap(line => line.trim.split("\\s+")) // .map(word => (word,1)) // .reduceByKey((temp,item) => temp + item) //基于RDD的编程 .transform( rdd => { //得到每个rdd rdd .filter(line => line.trim.length > 0) .flatMap(line => line.trim.split("\\s+")) .map(word => (word,1)) .reduceByKey((temp,item) => temp + item) })
-
-
foreachRDD:基于DStream中的RDD进行编程,没有返回值
-
类似于foreach函数
-
-
功能:取DStream中每个RDD进行处理,没有返回值
-
定义
def foreachRDD(foreachFunc: RDD[T] => Unit): Unit def foreachRDD(foreachFunc: (RDD[T], Time) => Unit-
使用
rsStream.foreachRDD((rdd,time) => { //如果没有数据,就不打印 if(!rdd.isEmpty()){ val dateTime = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss").format(time.milliseconds) //打印时间 println("===========================================") println(dateTime) println("===========================================") //打印数据 rdd.foreach(println) } })
-
-
-
-
小结
-
掌握SparkStreaming中DStream函数的使用
-
注意:工作中能使用RDD的转换和输出,就不要使用DStream的转换和输出,建议尽量使用transform和foreachRDD
-
06:无状态计算模式场景
-
目标:了解流式计算的无状态计算模式场景
-
实施
-
流式计算的三种模式
-
无状态模式:将每条数据中的IP地址解析得到国家省份城市
-
当前批次与前面的批次的计算没有关系
-
-
有状态模式:统计到目前为止的累计订单总金额
-
当前批次与前面的所有批次的计算有关系
-
-
窗口计算模式:每5s统计前10s的数据:指定处理的数据的范围
-
当前批次与前面的部分批次的计算有关系
-
10:00:00:开始运行
-
10:00:05:第一次处理:10:00:00 - 10:00:05
-
10:00:10:第二次处理:10:00:00 - 10:00:10
-
10:00:15:第三次处理:10:00:05 - 10:00:15
-
-
-
==无状态计算:每个批次的结果就是最后输出的结果,每个批次之间是没有关系的==
-
举个栗子:实现实时数据的ETL
-
Kafka:InputTopic
K V 1 001 laoda 20 ip1 2 002 laoda 20· ip2 3 003 laoda 20 ip3 4 004 laoda 20 ip4 -
SparkStreaming:ETL,解析每一条数据的国家省份城市,每一秒执行一次
-
第一个批次:2021-11-10 00:00:01
1 001 laoda 20 ip1 2 002 laoda 20· ip2 -
第二个批次:2021-11-10 00:00:02
3 003 laoda 20 ip3 4 004 laoda 20 ip4
-
-
Kafka:OutputTopic
K V 1 001 laoda 20 ip1 地区 2 002 laoda 20· ip2 地区 3 003 laoda 20 ip3 地区 4 004 laoda 20 ip4 地区
-
-
==应用场景:常见于ETL实现==,一对一,每个批次的计算就要得到这个批次的结果
-
-
-
小结
-
了解流式计算的无状态计算模式场景
-
07:有状态计算模式场景
-
目标:掌握有状态计算的场景
-
实施
-
例如:双十一,实时统计当前的订单总成交额
-
启动:2021-11-11 00:00:00
-
第一个批次:2021-11-11 00:00:01【00:00:00 - 00:00:01】
order01 100万 order02 100万 || 200万 -
第二个批次:2021-11-11 00:00:02 【00:00:01 - 00:00:02】
order03 200万 order04 100万 || 300万 || 最终显示的结果:当前批次 + 上个批次的结果 = 500万
-
-
==应用场景:需要做聚合计算的结果==
-
例如:统计到目前为止的每个单词的个数
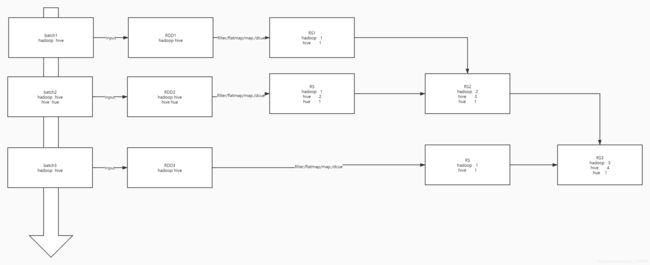
-
-
-
小结
-
掌握有状态计算的场景及实现
-
08:滑动窗口计算模式场景
-
目标:了解流式计算中滑动窗口计算的模式场景
-
实施
-
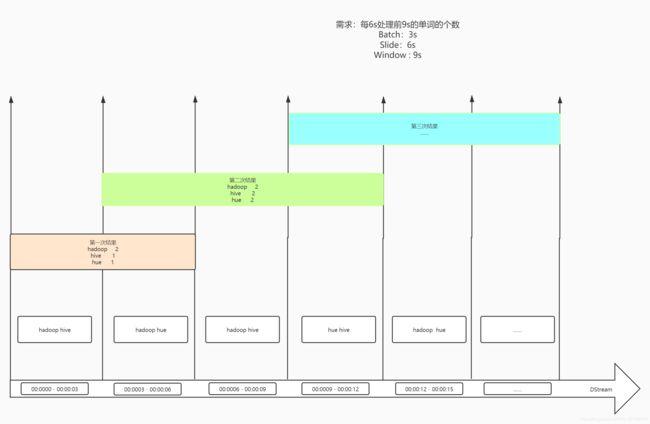
举个栗子:每3s构建一个批次,每6s显示前9s的数据
-
Batch Interval:每隔多长时间构建一个RDD,窗口计算中,达到Batch时间,只构架RDD,但并不计算
-
5s
-
-
Slide Interval:滑动时间,计算显示结果的周期,每隔多长时间滑动一次窗口
-
10s
-
-
Window Interval:计算的数据时间范围,也叫作窗口大小
-
1800s
-
-
-
应用场景:每10s刷新近半个小时的热搜
-
启动:10:00:00
-
第一次刷新:10:00:10
-
……
-
第N次刷新:10:30:00 【10:00:00 - 10:30:00】
-
第N+1次刷新:10:30:10 【10:00:10 - 10:30:10】
-
……
-
第M次刷新:11:00:10 【10:30:10 - 11:00:10】
-
-
需求:每6s计算前9s的单词的个数
-
Batch = 3s
-
Slide = 6s
-
Window = 9s
-
-
==注意:滑动时间和窗口大小必须为Batch批次时间的整数倍==
-
-
小结
-
了解流式计算中滑动窗口计算的模式场景
-
09:集成Kafka:集成方式
-
目标:了解SparkStreaming与Kafka 0.8.x集成的方式
-
路径
-
step1:场景
-
step2:版本
-
step3:0.8.x集成方式
-
step4:0.10.x+集成方式
-
-
实施
-
场景:只要是流式计算,数据源肯定来自于Kafka
-
版本
-
0.8.x集成方式
-
方式一:Approach 1: Receiver-based Approach:基于Receive的方式,推送数据的方式
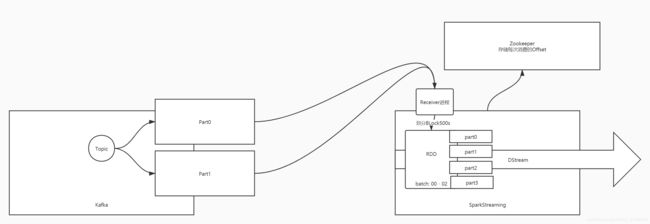
This approach uses a Receiver to receive the data. The Receiver is implemented using the Kafka high-level consumer API. As with all receivers, the data received from Kafka through a Receiver is stored in Spark executors, and then jobs launched by Spark Streaming processes the data. However, under default configuration, this approach can lose data under failures (see receiver reliability. To ensure zero-data loss, you have to additionally enable Write-Ahead Logs in Spark Streaming (introduced in Spark 1.2). This synchronously saves all the received Kafka data into write-ahead logs on a distributed file system (e.g HDFS), so that all the data can be recovered on failure. See Deploying section in the streaming programming guide for more details on Write-Ahead Logs.-
==启动receiver进程来接受数据==,receiver使用Kafka高级API来实现的,将offset存储在zk中,自动提交存储
-
将接受到的数据划分Block,将数据存储在Executor的内存中,等待达到Batchinterval时间,触发运行
-
为了保证程序故障,==数据不丢失,需要将数据写入WAL==,但是会出现性能较差的问题
-
问题
-
很难保证数据一次性语义
-
写WAL降低了性能
-
将Topic数据读取到以后,必须重新根据时间分到多个分区中
-
每隔RDD的分区个数 = Batch / Block
-
-
-
-
==方式二:Approach 2: Direct Approach (No Receivers),自己拉取数据的方式==
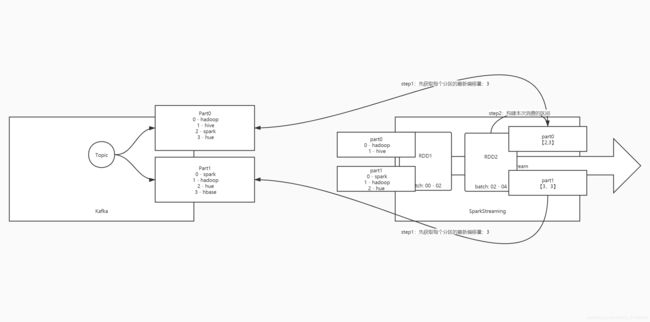
This new receiver-less “direct” approach has been introduced in Spark 1.3 to ensure stronger end-to-end guarantees. Instead of using receivers to receive data, this approach periodically queries Kafka for the latest offsets in each topic+partition, and accordingly defines the offset ranges to process in each batch. When the jobs to process the data are launched, Kafka’s simple consumer API is used to read the defined ranges of offsets from Kafka (similar to read files from a file system). Note that this feature was introduced in Spark 1.3 for the Scala and Java API, in Spark 1.4 for the Python API. - step1:SparkStreaming会周期性【每个Batch】向Kafka的Topic中的每个分区查询最新偏移量
-
step2:将上一次的消费位置与这次最新的offset构建消费的区间,根据区间向Kafka请求
-
第一次
-
-
先获取最新offset
-
part0:2
-
part1:3
-
构建每个分区的范围区间
-
part0:【0,2)
-
part1:【0,3)
-
-
向Kafka进行请求消费每个分区的范围:将所有消费到的数据构建一个RDD
-
RDD分区个数 = 消费Topic的分区个数
-
part0
-
part1
-
-
-
-
第二次
-
先获取最新offset
-
part0:4
-
part1:4
-
-
-
构建每个分区的范围区间
-
part0:【2,4)
-
part1:【3,4)
-
-
向Kafka进行请求消费每个分区的范围:将所有消费到的数据构建一个RDD
-
RDD分区个数 = 消费Topic的分区个数
-
part0
-
part1
-
-
-
-
-
==优点==
-
Simplified Parallelism:简单的并行化机制
-
实现了RDD的分区 = 消费的Kafka的分区数
-
-
Efficiency:不再依赖WAL,自己主动请求数据,如果数据丢失,重新请求即可
-
Exactly-once semantics:有且仅有一次一次性语义
-
-
-
0.10.x:一种方式,保留了0.8版本中的direct的方式来实现
-
-
小结
-
了解SparkStreaming与Kafka 集成的方式
-
10:集成Kafka:开发测试
-
目标:实现SparkStreaming集成Kafka0.10及以上版本的开发
-
实施
-
启动Kafka并创建Topic
-
参考附录二
-
-
API语法
-
KafkaUtils:消费Kafka数据的工具类
-
createDirectStream:使用Direct方式消费Kafka的方法
-
def createDirectStream[K, V]( ssc: StreamingContext, //StreamingContext对象 locationStrategy: LocationStrategy, //计算最优路径 consumerStrategy: ConsumerStrategy[K, V] //消费者配置对象 ): InputDStream[ConsumerRecord[K, V]] -
代码开发
-
-
package bigdata.itcast.streaming.kafka import org.apache.commons.lang.time.FastDateFormat import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.serialization.{StringDeserializer, StringSerializer} import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.dstream.{DStream, InputDStream, ReceiverInputDStream} import org.apache.spark.streaming.kafka010._ import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @ClassName StreamingAndKafka * @Description TODO 流式计算消费Kafka中的数据,实现WordCount */ object StreamingAndKafka { def main(args: Array[String]): Unit = { //todo:1-构建驱动接口对象:StreamingContext:包含SparkContext val ssc = { //如果存在,就获取,不存在就创建 StreamingContext.getActiveOrCreate(() => { //构建SparkConf val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[3]") //返回一个新的对象:配置对象,批处理间隔时间:Batch Interval,1s执行一次 new StreamingContext(conf,Seconds(1)) }) } //调整日志级别 ssc.sparkContext.setLogLevel("WARN") //todo:2-实现数据的处理逻辑 //step1:读取数据 //实现消费Kafka数据的最优计算路径 val locationStrategy = LocationStrategies.PreferConsistent //指定消费Kafka配置 val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "node1:9092,node2:9092,node3:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "sparkstream_test01", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean) ) //指定消费哪些topic val topics = Array("sparkStream01") val consumerStrategy = ConsumerStrategies.Subscribe[String,String]( topics, kafkaParams ) //获取Kafka的数据 val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream( ssc,//上下文对象 locationStrategy, consumerStrategy ) //step2:处理数据 val rsStream: DStream[(String, Int)] = kafkaStream //先获取value .map(record => record.value()) //过滤数据 .filter(line => line != null && line.trim.length > 0) //处理 .flatMap(line => line.trim.split("\\s+")) .map(word => (word,1)) .reduceByKey((tmp,item) => tmp + item) //step3:保存结果 // rsStream.print rsStream.foreachRDD((rdd,time) => { //判断是否为空 if(!rdd.isEmpty()){ //输出时间 val dtime = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss").format(time.milliseconds) println("----------------------------------") println(dtime) println("----------------------------------") //输出数据 rdd.foreach(println) } }) //todo:3-启动流式计算,如果遇到故障,释放资源 //启动流式计算 ssc.start() //保持运行,等待人为终止 ssc.awaitTermination() //遇到特殊故障,进行关闭释放资源 ssc.stop(true,true) } } -
查看结果
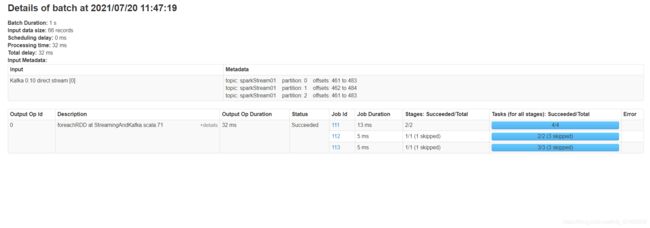
-
-
小结
-
实现SparkStreaming集成Kafka0.10及以上版本的开发
-
11:集成Kafka:获取Offset
-
目标:实现SparkStreaming消费Kafka数据并获取Offset
-
实施
-
获取Offset
-
//定义Offset对象 var offsetRanges: Array[OffsetRange] = null val rsStream: DStream[(String, Int)] = kafkaStream .transform(rdd => { //获取当前这个批次中RDD的每个分区的offset offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //处理这个批次的数据 rdd //先获取value .map(record => record.value()) //过滤数据 .filter(line => line != null && line.trim.length > 0) //处理 .flatMap(line => line.trim.split("\\s+")) .map(word => (word,1)) .reduceByKey((tmp,item) => tmp + item) }) -
输出Offset
-
//输出当前RDD每个分区对应消费的offset offsetRanges.foreach(offsetRange => { //获取每个分区的消费Kafka分区的范围 val topic = offsetRange.topic val part = offsetRange.partition val startOffset = offsetRange.fromOffset val endOffset = offsetRange.untilOffset println(topic+"\t"+part+"\t"+startOffset+"\t"+endOffset) }) -
结果

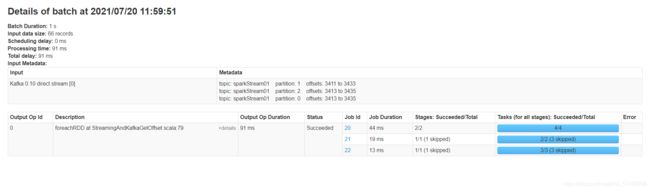
-
-
小结
-
实现SparkStreaming消费Kafka数据并获取Offset
-
12:实时热点应用案例:需求
-
目标:掌握实时热点分析案例的需求
-
实施
-
需求一:实时对日志数据进行ETL提取转换,基于IP地址解析得到每个IP对应省份和城市,结果存储到文件系统
-
==业务模式:无状态模式==
-
例如
-
原始数据
userid,ip,time,keyword9808dce0d08476fb,123.234.35.224,20210720120411593,一名北京赴浙人员新冠阳性 9808dce0d08476fb,123.234.35.224,20210720120411593,一名北京赴浙人员新冠阳性 986bfb9dec3ee35f,139.204.246.134,20210720120411726,元旦起上海超市禁止提供塑料袋 -
实时ETL,解析IP
userid,ip,time,keyword,province,city9808dce0d08476fb,123.234.35.224,20210720120411593,一名北京赴浙人员新冠阳性,上海,上海市 98c88f1538355597,123.233.13.64,20210720120411698,2020年日本最美最帅高中生,北京,北京市 986bfb9dec3ee35f,139.204.246.134,20210720120411726,元旦起上海超市禁止提供塑料袋,江苏,苏州市
-
-
-
需求二:百度热搜排行榜Top10,累加统计所有用户搜索词次数,获取Top10搜索词
-
==业务模式:有状态模式==
-
将每个批次每个搜索词的搜素次数进行累加并排序取前10
-
-
-
需求三:近期时间内热搜Top10,统计最近一段时间范围(比如,最近半个小时或最近2个小时)内用户搜索词次数,获取Top10搜索词及次数
-
==业务模式:窗口模式==
-
每隔3s统计前6s的热门搜索Top10
-
-
-
小结
-
掌握实时热点分析案例的需求
-
13:实时热点应用案例:开发环境构建
-
目标:实现实时热点分析案例的开发环境构建
-
实施
-
创建工程包结构

-
创建Topic
-
##创建Topic kafka-topics.sh --create --topic search-log-topic --partitions 3 --replication-factor 1 --zookeeper node1.itcast.cn:2181/kafka200 ##列举 kafka-topics.sh --list --zookeeper node1.itcast.cn:2181/kafka200 ##创建生产者 kafka-console-producer.sh --topic search-log-topic --broker-list node1.itcast.cn:9092 ##创建消费者 kafka-console-consumer.sh --topic search-log-topic --bootstrap-server node1.itcast.cn:9092 --from-beginning -
生成数据工具类:MockSearchLog
-
用于模拟用户搜索的日志数据生产到Kafka的Topic中 ,作为生产者
-
用户id,ip地址,搜索时间,搜索词
9808dce0d08476fb,123.234.35.224,20210720120411593,一名北京赴浙人员新冠阳性 98c88f1538355597,123.233.13.64,20210720120411698,2020年日本最美最帅高中生 986bfb9dec3ee35f,139.204.246.134,20210720120411726,元旦起上海超市禁止提供塑料袋
-
-
-
StreamingContext工具类:StreamingContextUtils
-
getStreamingContext:用于返回一个StreamingContext
-
参数:当前类的类名,批次时间
-
-
consumerKafka:用于返回消费Kafka的数据的DStream
-
参数:ssc,消费的Topic名称
-
-
-
IPAnalysisTest:测试IP解析的工具类
-
object IPAnalysisTest { def main(args: Array[String]): Unit = { //构建IP解析器 val searcher = new DbSearcher(new DbConfig(),"dataset/ip2region.db") //解析IP val arr = searcher.btreeSearch("123.232.207.135").getRegion.split("\\|") //输出地区等信息 arr.foreach(println } }
-
-
小结
-
实现实时热点分析案例的开发环境构建
-
14:实时热点应用案例:需求一实现
-
目标:实现实时热点案例的需求一
-
实施
-
IP解析测试
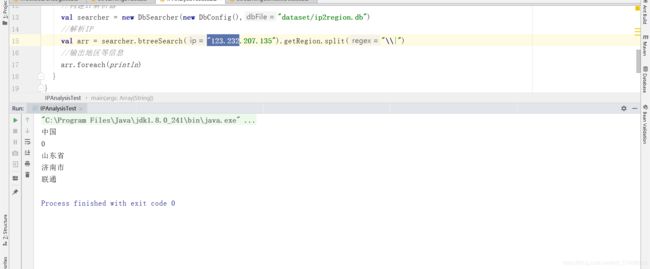
-
代码实现
-
package bigdata.spark.streaming.app.etl import bigdata.spark.streaming.app.StreamingContextUtils import org.apache.commons.lang.time.FastDateFormat import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} import org.lionsoul.ip2region.{DbConfig, DbSearcher} * @ClassName StreamingETL * @Description TODO 实时对日志数据进行ETL提取转换,基于IP地址解析得到每个 IP对应省份和城市,结果存储到文件系统 */ object StreamingETL { def main(args: Array[String]): Unit = { //todo:1-构建StreamingContext val ssc = StreamingContextUtils.getStreamingContext(this.getClass,1) ssc.sparkContext.setLogLevel("WARN") //todo:2-实现处理 //step1:读取数据 val kafkaStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc,"search-log-topic") //step2:处理数据 val etlStream = kafkaStream .map(record => record.value()) .filter(line => line != null && line.trim.split(",").length == 4) val rsStream: DStream[String] = etlStream .mapPartitions(part => { //构建解析器对象 val searcher = new DbSearcher(new DbConfig(),"dataset/ip2region.db") //对每个分区的数据进行处理 part.map(line => { //获取IP地址 val ip: String = line.trim.split(",")(1) //解析IP地址 val arr = searcher.btreeSearch(ip).getRegion.split("\\|") //返回原来的内容 + 省份 + 城市 line+","+arr(2)+","+arr(3) }) }) //step3:保存结果 rsStream.foreachRDD((rdd,time) => { //判断是否为空 if(!rdd.isEmpty()){ //输出时间 val dtime = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss").format(time.milliseconds) println("----------------------------------") println(dtime) println("----------------------------------") //输出数据 rdd.foreach(println) //保存到文件系统 rdd.saveAsTextFile("datas/stream/etl") } }) //todo:3-启动 ssc.start() ssc.awaitTermination() ssc.stop(true,true) } }
小结
-
- 实现实时热点案例的需求一
15:实时热点应用案例:需求二实现
-
目标:实现实时热点案例的需求二
-
实施
-
状态函数
def updateStateByKey[S: ClassTag]( updateFunc: (Seq[V], Option[S]) => Option[S] ): DStream[(K, S)]-
功能:根据Key进行关联,与之前批次的结果进行Value的聚合
-
参数函数的语法:updateFunc: (Seq[V], Option[S]) => Option[S]
-
Seq[V]:当前批次这个Key的所有Value
-
Option[S]:上一个批次最终结果中这个Key的value
-
为什么为Option类型,这个Key在上个批次的最终结果中可能没有
-
-
-
-
代码实现、
-
package bigdata.spark.streaming.app.state import bigdata.spark.streaming.app.StreamingContextUtils import org.apache.commons.lang.time.FastDateFormat import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.spark.streaming.{State, StateSpec} import org.apache.spark.streaming.dstream.DStream import org.lionsoul.ip2region.{DbConfig, DbSearcher} /** * @ClassName StreamingWithState * @Description TODO 累计当前所有搜索词出现的次数,得到热门搜索词的Top10 */ object StreamingWithState { def main(args: Array[String]): Unit = { //todo:1-构建StreamingContext val ssc = StreamingContextUtils.getStreamingContext(this.getClass,3) ssc.sparkContext.setLogLevel("WARN") //配置Checkpoint目录:将上一个批次的最终结果写入CHK ssc.checkpoint("datas/stream/chk1") //todo:2-实现处理 //step1:读取数据 val kafkaStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc,"search-log-topic") //step2:处理数据 val etlStream = kafkaStream .map(record => record.value()) .filter(line => line != null && line.trim.split(",").length == 4) //当前批次的结果 val currentBatch: DStream[(String, Int)] = etlStream //标记每个搜索词出现1次 .map(line => (line.trim.split(",")(3),1)) //聚合每个搜索词出现的次数 .reduceByKey((tmp,item) => tmp+item) //程序的结果:当前批次的结果 + 上一个批次的结果 val rsStream = currentBatch.updateStateByKey( (currentList:Seq[Int],lastBatchRs:Option[Int]) => { //获取这个Key在当前批次的结果 val currentValue = currentList.sum //获取这个Key在上一个批次的最终结果 val lastValue = lastBatchRs.getOrElse(0) //最终返回结果 Some(currentValue + lastValue) } ) / /step3:输出结果 rsStream.foreachRDD((rdd,time) => { //判断是否为空 if(!rdd.isEmpty()){ //输出时间 val dtime = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss").format(time.milliseconds) println("----------------------------------") println(dtime) println("----------------------------------") //输出数据 rdd .sortBy(tuple => tuple._2,false) .take(10) .foreach(println) } }) //todo:3-启动 ssc.start() ssc.awaitTermination() ssc.stop(true,true) } }
- 注意:有状态的计算,一定要设置Checkpoint
//配置Checkpoint目录:将上一个批次的最终结果写入CHKssc.checkpoint("datas/stream/chk1") -
结果
-
-
-
小结
-
实现实时热点案例的需求二
-
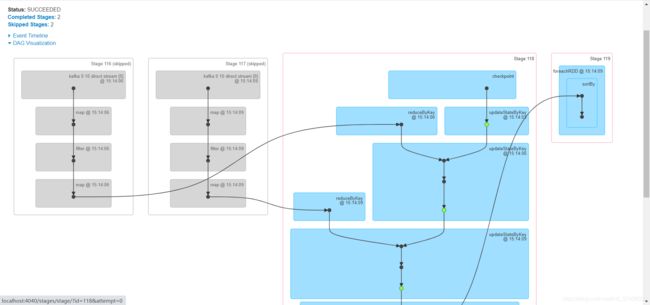
16:实时热点应用案例:需求三实现
-
目标:实现实时热点案例的需求三
-
实施
-
窗口概念
-
窗口设计:固定了计算数据的范围
-
需求:每多长时间处理多长时间范围的数据
-
窗口时间:必须为批次时间整数倍
-
滑动时间:Slide Interval
-
窗口大小:Window Size
-
-
SparkSreaming中的时间
-
批次时间:Batch Interval
-
-
-
代码实现
-
package bigdata.spark.streaming.app.window import bigdata.cn.spark.streaming.app.StreamingContextUtils import org.apache.commons.lang.time.FastDateFormat import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.{Seconds, State, StateSpec} /** * @ClassName StreamingWithWindow * @Description TODO 每3s处理前6s数据,统计热门搜索词的Top10 */ object StreamingWithWindow { def main(args: Array[String]): Unit = { //todo:1-构建StreamingContext val batchInterval = 3 val slideInterval = batchInterval * 1 val windowSize = batchInterval * 2 val ssc = StreamingContextUtils.getStreamingContext(this.getClass,batchInterval) ssc.sparkContext.setLogLevel("WARN") //todo:2-实现处理 //step1:读取数据 val kafkaStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc,"search-log-topic") //step2:处理数据 val etlStream = kafkaStream .map(record => record.value()) .filter(line => line != null && line.trim.split(",").length == 4) //方式一:ETL以后设置计算的窗口 // val windowStream = etlStream.window(Seconds(windowSize),Seconds(slideInterval)) // // val rsStream = windowStream // .map(line => (line.trim.split(",")(3),1)) // .reduceByKey((tmp,item) => tmp + item) //方式二:直接做窗口聚合 val rsStream = etlStream .map(line => (line.trim.split(",")(3),1)) .reduceByKeyAndWindow( (tmp:Int,item:Int) => tmp + item, Seconds(windowSize), Seconds(slideInterval) ) //step3:输出结果 rsStream.foreachRDD((rdd,time) => { //判断是否为空 if(!rdd.isEmpty()){ //输出时间 val dtime = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss").format(time.milliseconds) println("----------------------------------") println(dtime) println("----------------------------------") //输出数据 rdd .sortBy(tuple => tuple._2,false) .take(10) .foreach(println) } }) //todo:3-启动 ssc.start() ssc.awaitTermination() ssc.stop(true,true) } }
-
-
小结
-
实现实时热点案例的需求三
-
17:Streaming中的Checkpoint机制
-
目标:了解SparkStreaming的checkpoint的功能
-
实施
-
问题:有状态计算时问题
-
如果程序故障,重启,无法获取之前计算的结果
-
-
==解决:checkpoint==
A streaming application must operate 24/7 and hence must be resilient to failures unrelated to the application logic (e.g., system failures, JVM crashes, etc.). For this to be possible, Spark Streaming needs to checkpoint enough information to a fault- tolerant storage system such that it can recover from failures. There are two types of data that are checkpointed.
-
Metadata:程序的元数据
-
Configuration:整个程序的配置,理解就是driver对象,就是StreamingContext
-
下一次重启,读取之前的配置,恢复原来的StreamingContext
-
-
DStream:所有DStream以及对应的转换关系
-
Incomplete Batch:处理的位置
-
思考:为什么会出现问题1?
-
整个程序的所有配置所有数据都由StreamingContext负责维护和管理
-
每次重启,都构建了一个新的StreamingContext,原来的所有配置都丢失了
-
-
-
Data:上一个批次的结果
-
怎么能解决上面这个问题?
-
代码中构建StreamingContext需要做判断
-
先判断chk中有没有ssc,如果有,就恢复原来的
-
如果没有,构建一个新的
-
-
-
-
代码
val ssc = StreamingContext.getActiveOrCreate( chk_path,//指定chk路径,用于判断是否已经有一个ssc //如果当前没有,调用函数构建一个新的 () => { val sparkConf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[3]") //设置Kafka每个分区消费的最大消息数 .set("spark.streaming.kafka.maxRatePerPartition", "10000") val context = new StreamingContext(sparkConf, Seconds(5)) //设置日志级别 context.sparkContext.setLogLevel("WARN") //设置checkpoint目录 context.checkpoint(chk_path) //调用处理逻辑 processData(context) context } )
-
-
小结
-
了解SparkStreaming的checkpoint的功能
-
18:了解Streaming中Kafka Offset的管理
-
目标:了解Streaming中Kafka Offset的手动管理
-
实施
-
问题:消费Kafka的数据怎么保证一次性语义?
-
一定按照每个分区的offset顺序进行消费
-
Offset的安全性问题:怎么保存下一个批次要消费的offset
-
Kafka解决:允许消费者手动提交将自己消费的offset存储在__consumer_offsets这个topic中
-
工作中:可以将自己消费的offset存储外部系统
-
-
-
设计
-
step1:消费并处理成功,将Offset进行持久化存储:MySQL
-
step2:如果消费者故障,重启消费者时,从持久化存储中获取上一次正确消费的位置
-
从MySQL读取上一次消费成功的offset
-
作为这一次fromOffset,用最新的offset作为utilOffset,构建范围,向Kafka提交
-
-
-
实现
-
消费并处理成功,将本次消费的Offset记录在MySQL中
-
reduceDStream .foreachRDD{(rdd, time) => val batchTime: String = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss").format(new Date(time.milliseconds)) println("-------------------------------------------") println(s"BatchTime: $batchTime") println("-------------------------------------------") if(!rdd.isEmpty()){ rdd // .filter(tuple => tuple._2 > 5) .coalesce(1).foreachPartition{_.foreach(println)} //保存Offset到MySQL中 OffsetsUtils.writeToMySQL(offsetRanges,groupId) } } } -
消费者处理失败,从MySQL中读取上一次成功消费的Offset
-
val offsets:Map[TopicPartition, Long] = OffsetsUtils.readFromMySQL(topics,groupId) val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe( topics, kafkaParams, offsets ) -
OffsetUtils
package bigdata.spark.streaming.managerOffset import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet} import org.apache.kafka.common.TopicPartition import org.apache.spark.streaming.kafka010.OffsetRange import scala.collection.mutable /** * @ClassName OffsetsUtils * @Description TODO 实现将KafkaOffset存储在MySQL中,启动从MySQL中读,每次处理完成写入MySQL */ object OffsetsUtils { /** * 用于程序失败重启,从MySQL中获取上一次的offset,向Kafka继续提交消费 * @param topics:消费者组消费的所有的topic * @param groupId:消费者组的id * @return */ def readFromMySQL(topics: Array[String],groupId:String): Map[TopicPartition, Long] ={ //构建返回值 val maps: mutable.Map[TopicPartition, Long] = mutable.Map.empty //往Map集合中添加offset:TopicPartition(topic,partition) //申明驱动 Class.forName("com.mysql.cj.jdbc.Driver") //构建连接对象 var conn:Connection = null var pstm:PreparedStatement = null //构建实例 try{ conn = DriverManager.getConnection("jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true", "root","123456") //构建SQL语句 //将多个Topic的名称拼接为字符串:'topic1','topic2' val topicName = topics.map(name => s"\'${name}\'").mkString(", ") val sql = s"select * from db_spark.tb_offset where topic in (${topicName}) and groupid = ? " pstm = conn.prepareStatement(sql) //赋值 pstm.setString(1,groupId) //运行SQL val rs: ResultSet = pstm.executeQuery() //获取读取的数据 while(rs.next()){ //获取Topic val topic = rs.getString("topic") //获取分区编号 val part = rs.getInt("partition") //获取offset val offset = rs.getLong("offset") //将当前分区的offset构建KV,添加到Map集合中 maps += new TopicPartition(topic,part) -> offset } }catch { case e:Exception => e.printStackTrace() }finally { if(pstm != null) pstm.close() if(conn != null) conn.close() } //返回 maps.toMap } /** * 用于将消费成功的Offset写入MySQL * @param offsetRanges:本次消费的每个Topic的每个分区的offset * @param groupId:消费者组的id */ def writeToMySQL(offsetRanges: Array[OffsetRange],groupId:String): Unit ={ //申明驱动 Class.forName("com.mysql.cj.jdbc.Driver") //构建连接对象 var conn:Connection = null var pstm:PreparedStatement = null //构建实例 try{ conn = DriverManager.getConnection("jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true", "root","123456") //构建SQL语句 val sql = "replace into db_spark.tb_offset (`topic`, `partition`, `groupid`, `offset`) values(?, ?, ?, ?)" pstm = conn.prepareStatement(sql) //赋值 offsetRanges.foreach(offsetRange => { pstm.setString(1,offsetRange.topic) pstm.setInt(2,offsetRange.partition) pstm.setString(3,groupId) pstm.setLong(4,offsetRange.untilOffset) pstm.addBatch() }) pstm.executeBatch() }catch { case e:Exception => e.printStackTrace() }finally { if(pstm != null) pstm.close() if(conn != null) conn.close() } } def main(args: Array[String]): Unit = { // writeToMySQL( // Array( // OffsetRange("xx-tp", 0, 11L, 100L), // OffsetRange("xx-tp", 1, 11L, 100L), // OffsetRange("yy-tp", 0, 10L, 500L), // OffsetRange("yy-tp", 1, 10L, 500L) // ), // "group_id_00001" // ) readFromMySQL(Array("xx-tp","yy-tp"), "group_id_00001").foreach(println) } }
-
-
-
小结
-
了解Streaming中Kafka Offset的手动管理
-
附录一:Streaming Maven依赖
aliyun
http://maven.aliyun.com/nexus/content/groups/public/
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
jboss
http://repository.jboss.com/nexus/content/groups/public
2.11.12
2.11
2.4.5
2.6.0-cdh5.16.2
1.2.0-cdh5.16.2
2.0.0
8.0.19
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_${scala.binary.version}
${spark.version}
org.apache.spark
spark-sql_${scala.binary.version}
${spark.version}
org.apache.spark
spark-streaming_${scala.binary.version}
${spark.version}
org.apache.spark
spark-streaming-kafka-0-10_${scala.binary.version}
${spark.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.hbase
hbase-server
${hbase.version}
org.apache.hbase
hbase-hadoop2-compat
${hbase.version}
org.apache.hbase
hbase-client
${hbase.version}
org.apache.kafka
kafka-clients
${kafka.version}
org.lionsoul
ip2region
1.7.2
mysql
mysql-connector-java
${mysql.version}
c3p0
c3p0
0.9.1.2
target/classes
target/test-classes
${project.basedir}/src/main/resources
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile
附录二、Kafka集群操作
-
第一步:第一台机器执行:先启动三台机器的Zookeeper
zookeeper-daemons.sh start zookeeper-daemons.sh status -
第二步:第一台机器执行启动kafka server
kafka-daemons.sh start -
创建一个topic
kafka-topics.sh --create --topic sparkStream01 --partitions 3 --replication-factor 1 --zookeeper node1.itcast.cn:2181/kafka200 -
查看topic信息
#列举所有topic kafka-topics.sh --list --zookeeper node1.itcast.cn:2181/kafka200 #查看topic详细信息 kafka-topics.sh --describe --topic sparkStream01 --zookeeper node1:2181/kafka200 -
创建一个生产者
kafka-console-producer.sh --topic sparkStream01 --broker-list node1.itcast.cn:9092 -
创建一个消费者
kafka-console-consumer.sh --topic sparkStream01 --bootstrap-server node1.itcast.cn:9092 --from-beginning