【Redis】到底是单线程还是多线程以及Redis为什么这么快?
文章目录
- Redis到底是单线程还是多线程的?
- Redis为什么是单线程的?
- Redis为什么基于内存?
- 为什么要为Redis绑定某一固定CPU?
- Redis的多线程情况
- Redis的单线程到底有多快?
- Redis为什么这么快
Redis到底是单线程还是多线程的?
Redis 6.0版本之前的单线程指的是其网络IO和键值对的读写是由一个线程完成的。
Redis 6.0引入的多线程指的是网络请求过程采用了多线程,而键值对读写命令仍然是单线程处理的,所以Redis依旧是并发安全的。
也就是只有网络请求模块和数据操作模块是单线程的,而其他的持久化、集群数据同步等,其实是由额外的线程执行的。
Redis为什么是单线程的?
关于这个问题,官方给出的解释如下:
It’s not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound. For instance, using pipelining Redis running on an average Linux system can deliver even 1 million requests per second, so if your application mainly uses O(N) or O(log(N)) commands, it is hardly going to use too much CPU.
However, to maximize CPU usage you can start multiple instances of Redis in the same box and treat them as different servers. At some point a single box may not be enough anyway, so if you want to use multiple CPUs you can start thinking of some way to shard earlier.
You can find more information about using multiple Redis instances in the Partitioning page.
However with Redis 4.0 we started to make Redis more threaded. For now this is limited to deleting objects in the background, and to blocking commands implemented via Redis modules. For future releases, the plan is to make Redis more and more threaded.
翻译过后也就是:
CPU并不是您使用Redis的瓶颈,因为通常Redis要么受内存限制,要么受网络限制。例如,使用在一般Linux系统上运行的流水线Redis每秒可以发送一百万个请求,因此,如果您的应用程序主要使用О(N)或O (log(N))命令,则几乎不会使用过多的CPU 。
但是,为了最大程度地利用CPU,您可从在同一服务器上启动多个Redis实例,并将它们视为不同的服务器。在某个时候,单个实例可能还不够,因此,如果您要使用多个CPU,则可以开始考虑更早地分片的某种方法。
但是,在Redis 4.0中,我们升始使Redis具有更多线程。目前,这仅限于在后台删除对象(unlink方法),以及阻止通过Redis模块实观的命令。对于将来的版本,计划是使Redis越来越线程化。
既然redis的瓶颈不是cpu,那么在单线程可从实现的情况下,自然就使用单线程了。
在这里,不得不提的是,在Redis的版本迭代过程中,在以下两个版本上引入了多线程的支持:
- Redis v4.0:引入多线程异步处理一些耗时较长的任务,例如异步删除命令unlink
- Redis v6.0:在核心网络模型中引入多线程,进一步提高对多核CPU的利用率
我的理解:
首先我们都知道Redis是基于内存的,他之所以性能强也正是因为他基于内存存储。
那么接下来就需要了解多核CPU和在内存上直接操作的效率到底差多少。
多线程操作就是使用多个cpu模拟多个线程,对redis进行操作。这样会造成一个巨大的问题,就是cpu的上下文切换问题。cpu的上下文切换的效率比直接在内存中进行读取差的很多。redis使用单个cpu绑定一个内存,针对内存的处理就是单线程的,这样避免了上下文的切换,所以非常的快。
一次cpu的切换时间大约是1500ns。从内存中读取1mb的连续数据,耗时大约是250us。如果1mb的数据被多个线程读取了1000次。那么就是有1000次时间的上下文切换。于是就是1500ns*1000=1500us。结果显而易见。1500us和250us差的还是很多的。那么redis采取单线程还避免了很多问题。如果redis使用多线程来进行,那么就要考虑多线程带来的数据安全问题,如果我们在操作redis的list , hash等数据结构的时候。多线程就可能存在数据不安全的情况,这时就要加锁。一旦加锁就影响了程序的执行速度。
因此对这个问题,我总结如下:
- 抛开持久化不谈,Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程并不会带来巨大的性能提升。
- 多线程会导致过多的上下文切换,带来不必要的开销。
- 引入多线程会面临线程安全问题,必然要引入线程锁这样的安全手段,实现复杂度增高,而且性能也会大打折扣。
因此Redis使用单线程有如下优劣势:
优势
代码更清晰,处理逻辑更简单。
不用去考虑各种锁的问题,不存在加锁、释放锁操作,没有因为可能出现死锁而导致的性能消耗。
不存在“多进程或者多线程导致的切换”而消耗CPU。
劣势
无法发挥多核CPU性能,不过可从通过在单机开多个Redis实例来完善。
Redis为什么基于内存?
问到这个问题,很显然我们肯定会直接回答:因为内存他快。
但是为什么呢?
Redis他读取内存和读取磁盘有什么区别呢?
这里引入两个概念,IOPS和吞吐量。
【IOPS (lnput / output operations Per Second )是一个用于计算机存储设备(如硬盘(HDD) 、固态硬盘(SSD)或存储区域网络(SAN) )性能测试的量测方式】
【吞吐量是指对网络、设备、端口、虚电路或其他设施,单位时间内成功地传送数据的数量(以比特、字节、分组等测量)】
内存是一个 IOPS非常高的系统,因为我想申请一块内存就申请一块内存,销毁一块内存我就销毁一块内存,内存的申请和销毁是很容易的。
而且内存是可以动态的申请大小的。Redis中的许多数据结构在进行存取操作的时候都利用了内存的这一特性。
磁盘的特性是: IPOS很低,但吞吐量很高。
这就意味着,大量的读写操作都必须攒到一起,再提交到磁盘的时候,性能最高。为什么呢?
下面举个例子:
如果我有一个事务组的操作(就是几个已经分开了的事务请求,比如写读写读写,这么五个操作在一起),在内存中,因为IOPS非常高,我可以一个一个的完成,但是如果在磁盘中也有这种请求方式的话,我第一个写操作是这样完成的:我先在硬盘中寻址,大概花费10ms ,然后我读一个数据可能花费1m s然后我再运算(忽略不计),再写回硬盘又是10ms ,总共21ms,第二个操作去读花了10ms ,第三个又是写花费了21ms ,然后我再读10ms,写21ms ,五个请求总共花费83ms,这还是最理想的情况下,这如果在内存中,大概1ms不到。
所以对于磁盘来说,它吞吐量这么大,那最好的方案肯定是我将N个请求一起放在一个buffer里,然后一起去提交。
因为相对于内存,磁盘的空间非常大,不容易出现由于空间不足而导致的问题。
那么如何实现上面的同时提交?
方法就是用异步∶将请求和处理的线程不绑定,请求的线程将请求放在一个buffer里,然后等buffer快满了,处理的线程再去处理这个buffer。然后由这个buffer统一的去写入磁盘,或者读磁盘,这样效率就是最高。
对于慢速设备,这种处理方式就是最佳的,慢速设备有磁盘,网络,SSD等等。
为什么要为Redis绑定某一固定CPU?
Redis的核心业务部分是单线程的,而上面我们已经说到,如果应用程序在CPU之间进行上下文切换是需要浪费资源的,所以如果我们一般会将Redis与某一固定CPU进行绑定。
所从我们可以手动地为其分配CPU,而不会过多地占用CPU,黙认情况下单线程程序在进行系统调用的时候会随机使用CPU内核,为了优化Redis ,我们可以使用工具为单线程程序绑定固定的CPU内核,减少不必要的性能损耗!
Redis作为单线程模型的程序,为了充分利用多核CPU,常常在一台服务器上会启动多个实例。而为了减少切换的开销,有必要为每个实例指定其所运行的CPU。
而Redis一般运行在Linux系统上,而Linux 上 的 taskset可从将某个进程绑定到一个特定的CPU。这一可以避免调度器愚蠢的调度Redis,并且在多线程程序中避免缓存失效造成的开销。(Redis的缓存失效再将后面的文章中讲解)
Redis的多线程情况
一个Redis服务运行的时候,并不是单线程的,最简单的例子就是执行bgsave命令了。
相比于直接使用save命令,bgsave命令并不会直接阻塞Redis导致Redis无法继续接收请求,bgsave会使用fork方法来创建一个子进程,子进程将会对主进程的页表进行复制,而页表指向的就是正在在物理内存中的数据的位置。此时子进程就可以访问到在物理内存中的数据了。
所以这个时候子进程就可以对内存中的数据进行拷贝复制了。
当然,为了防止脏读问题,fork方法使用了一种copy-on-write技术。
当主进程进行写操作的时候,他会对要写的内容进行拷贝之后然后在写,这样就不会导致子进程在拷贝数据的时候数据变化了。
但是如果特殊情况下,可能会出现所有数据都需要拷贝后在进行写入的操作,这样就会导致内存占用翻倍。(咳咳扯远了)
Redis的单线程到底有多快?
Redis官网
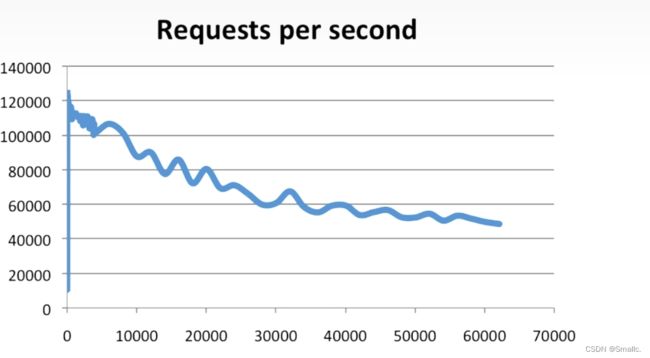
其中横轴为客户端连接数,纵轴为每秒查询次数。
可以发现Redis的每秒查询次数可以达到10w+,但是随着连接数的增加,每秒查询次数会减少。
Redis为什么这么快
1、Redis是纯内存数据库,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在IO上,所以读取速度快。
2、Redis使用的是非阻塞IO、IO多路复用,使用了单线程来轮询文件描述符(File Descriptor),将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切换和竞争。
3、Redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
4、Redis避免了多线程的锁的消耗。
5、Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
6、高效的数据存储结构:全局hash表以及多种高效的数据结构,比如:跳表(SkipList)、压缩列表(ZipList)、链表(QuickList)