IC验证之求学路
文章目录
- 前言
- 第零章 那些总被遗忘的概念
-
- 总线
- ++i 和 i++的区别
- verilog中的for语句综合出什么
- 格雷码和二进制码的转换
- 第一章 数电和verilog基础
-
- 1.1 verilog 编程 常见错误
- 1.2 同步FIFO
-
- 1.2.1 Spec
- 1.3 异步FIFO
-
- 1.3.1 设计理念
- 1.3.2 异步FIFO的作用
- 1.3.3 异步FIFO的读/写指针
- 1.3.4 异步FIFO空/满标志
- 1.3.5 Spec
- 1.3.6 异步FIFO 答疑解惑
- 1.4 锁存器、触发器、寄存器、缓冲器
- 第二章 SV
-
- SV4.接口和连接设计与验证平台
- SVA断言-有待后续
- SV5.面向对象编程
- SV6.随机化
- SV7.线程及线程间的通信
- SV8.OOP高级
- SV9.功能覆盖率
- SV12.SV与C语言的接口
- 第三章 UVM
-
- UVM与SV的比对
- 第四章 脚本语言
-
- 4.1 一文读懂Shell
-
- 4.1.1 Shell 是什么?
- 4.1.2 shell的种类 : .sh、.bash、.csh、.tcsh(命令补全)、.ash 等。
- 4.1.3 shell命令的基本格式
- 4.1.4 notice
- 4.1.5 输入输出重定向:
- 4.1.6 常用命令
-
- 4.1.6.1 切换工作目录命令cd
- 4.1.6.2 显示当前路径命令pwd
- 4.1.6.3 查看目录命令ls [ls: list]
- 4.1.6.4 显示文件命令 cat
- 4.1.6.5 分屏显示命令 more:
- 4.1.6.6 按页显示命令less
- 4.1.6.7 复制命令cp:[cp:Copy file]
- 4.1.6.8 删除命令rm:[rm :Remove(删除目录或文件)]
- 4.1.6.9 移动或重命名命令
- 4.1.6.10 创建目录命令
- 4.1.6.11 删除空目录命令
- 4.1.6.12 查找文件或者目录命令find
- 4.1.6.13 文件定位命令 locate/slocate
- 4.1.6.14 文件内容检索命令grep
- 4.1.6.15 链接命令
- 4.1.6.16 创建文件、改变文件或目录生成时间命令 touch
- 4.1.6.17 打包命令 tar
- 4.1.6.18 压缩命令 zip 和gzip
- 4.1.6.19 修改时间 date; 日历 cal ; 显示时间命令 clock
- 4.2 Perl
-
- 4.2.0 Perl的小技巧集合
- 4.2.1 Perl的概述
- 4.2.2 Perl的数据类型
-
- 4.2.2.1 标量
-
- 4.2.2.1.1 **数字标量:** Scalar, 以$开头, 值为 “数字” 的标量,
- 4.2.2.1.2 **字符串标量:** 标量值为字符串, **由引号标识**
- 4.2.2.1.3 **字符串操作符:**
- 4.2.2.1.4 **单引号、双引号 的区别:**
- 4.2.2.1.5 **标量的声明及作用域:**
- 4.2.2.1.6 变量
- **私有变量:** 分为my类型,local类型
- **持久性私有变量:**
- 4.2.2.2 数组
-
- **数组:** 标量数据的有序列表,是多个标量数据的一种集合;
- **列表:** 包含了一系列值的列表,**以括号标识,中间用逗号隔开**
- **列表赋值**
- **数组赋值**
-
- 3. pop 和 push 赋值(对数组**最右边**的元素操作)
- 4. shift 和 unshift 赋值 (对数组**最左边**的元素操作)
- 5. splice操作符
- 6. 字符串中的数组内插
- 数组元素的访问(索引)
- 4.2.2.3 引用
-
- **格式:** \$<标量>,\@<数组>, 即为 地址
- 软引用
- 硬引用
- 引用有助于创建复杂数据
- 4.2.2.4 chomp()函数
- 4.2.2.5 undef值
- 4.2.2.6 defined() 函数
- 4.2.2.7 默认变量:$_
- 4.2.2.8 reverse操作符
- 4.2.2.9 sort操作符
- 4.2.2.10 each 操作符
- 4.2.2.11 标量与列表上下文(Perl中最重要的知识点)
- 4.2.2.12 return 操作符
- 4.2.3 运算符
-
- 4.2.3.1 算数运算符
-
- 四则运算
- 乘幂运算
- 取余运算
- 单目负运算
- 运算符的省略形式
- 4.2.3.2 比较运算符
-
- 数字比较运算符
- 字符串比较运算符
- 4.2.3.3 逻辑运算符(和SV相同)
- 4.2.3.4 位运算符
- 4.2.3.5 赋值运算符
- 4.2.3.6 其他运算符
- 4.2.3.7 运算符的优先级和结合性
- 4.2.4 Perl 控制结构
-
- 4.2.4.1 控制结构 if and unless
- 4.2.4.2 控制结构 foreach and for
- 4.2.4.3 控制结构 while、until、switch
- 4.2.4.4 控制结构 实例分析
- 4.2.5 子程序
-
- 4.2.5.1 定义子程序
- 4.2.5.2 调用子程序
- 4.2.5.3 返回值(列表值和标量值都可)
-
- 非标量返回值, 不给任何参数
- 4.2.5.4 传入参数
- 4.2.6 输入与输出
-
- 4.2.6.1 获取用户输入 标准输入 STDIN
- 4.2.6.2 钻石操作符的输入
- 4.2.6.3 调用参数
- 4.2.6.4 输出到标准输出
- 4.2.6.5 打开文件句柄
- 4.2.7 哈希
-
- 4.2.7.1 哈希的简介
- 4.2.7.2 访问哈希元素
- 4.2.7.3 访问整个哈希 %
- 4.2.7.3 哈希赋值
- 4.2.7.4 旁箭头(=>)
- 4.2.7.5 哈希函数
-
- 4.2.7.5.1 keys 和 values 函数
- 4.2.7.5.2 each 函数
- 4.2.7.5.3 哈希的典型应用
- 4.2.8 正则表达式 regular expression
-
- 4.2.8.1 简介
-
- 4.2.8.1.1 简单模式
- 4.2.8.1.2 Unicode 属性
- 4.2.8.1.3 元字符 metacharacter
- 4.2.8.1.3 (...) 特征标群
- 4.2.8.1.3 | 或运算符
- 4.2.8.1.3 转码特殊字符
- 4.2.8.1.3 锚点
- 4.2.8.1.3 ^ 号
- 4.2.8.1.3 $ 号
- 简写字符集
- 零宽度断言(前后预查)
- 标志
- 贪婪匹配与惰性匹配 (Greedy vs lazy matching)
- 4.2.8.1.4 模式分组
- 4.2.8.2 简介
- 4.3 C语言
- 4.4 DPI
- 4.5 Python
-
- 4.5.1 pyhon解释器
- 4.5.2 pyhon 基础
- 4.6 Vim 编辑器
- 4.7 VCS 简单 操作
- 4.8 linux 简单 操作
- 4.9 Questa 简单 操作
- 4.10 DVT 简单操作
- 第五章、 APB-Watchdog 项目
-
- 5.1 what and applied
- 5.2 much register control this module
- 二、使用步骤
-
- 1.引入库
- 2.读入数据
- 总结
前言
内容:IC验证学习笔记:SV、UVM、shell、Perl、Vim、C语言,验证项目APB-Watchdog
目的:捋顺学习思路,方便自己复习,总结,归纳
第零章 那些总被遗忘的概念
总线
- 系统总线: 连接多个部件的信息传输线,是各部件共享的传输介质。
- 分散总线: 各部件之间使用单独的连线.
- 总线上信息的传送 总线实际上是由一条或多条传输线或通路组成,每条线可一位一位地传输二进制代码,一串二进制代码可在一段时间内逐一传输完成。
- 总线上信息的传送分为串行和并行两种。 串行即只有一条数据线(通路),数据只能一位一位排好队传输,而并行则是有一排传输线(通路),可以同时发送一组数据,例如,16条传输线组成的总线可同时传输16位二进制代码。
++i 和 i++的区别

verilog中的for语句综合出什么
Verilog中的for语句是将所以可能的结构全部展开成电路(因为属于组合逻辑,在仿真中第0ns就展开完毕),并且可以通过改变 parameter变量的值来改变电路层级,较为方便,但其他地方慎用for语句,因为可能会综合出较大面积的电路,浪费LUT资源。
格雷码和二进制码的转换
1. 二进制数 转 格雷码
二进制数: Bn-1、Bn-2、....B2、B1、B0;
格雷码: Gn-1、Gn-2、....G2、G1、G0;
最高位保留:
Gn-1 = Bn-1;
其他位:
Gi = Bi+1 ^ Bi,i = n-2, n-1 .... 2, 1;
代码:
assign Gray = (Bin>>1) ^ Bin;
2. 格雷码 转 二进制数
二进制数: Bn-1、Bn-2、....B2、B1、B0;
格雷码: Gn-1、Gn-2、....G2、G1、G0;
最高位保留:
Bn-1 = Gn-1;
其他位:
Bi = Gi ^ Bi+1,i = n-2, n-1 .... 2, 1;
代码:
module gray2bin(
input [size - 1 : 0] bin,
output[size - 1 : 0] gray,
);
always@(*)
begin
parameter size = 4;
interger i ;
for(i=0;i<size-1;i=i+1)
begin
if(i = size-1)
bin[i] = gray[i];
else
bin[i] = gray[i] ^ bin[i+1];
end
end
or
module gray2bin(
input [size - 1 : 0] bin,
output[size - 1 : 0] gray,
);
always@(*)
begin
parameter size = 4;
interger i ;
for(i=0;i<size-1;i=i+1)
begin
bin[i] = ^[gray >> i];
end
end
第一章 数电和verilog基础
1.1 verilog 编程 常见错误
- 阻塞赋值: 先计算等号右侧的值,再赋给左侧,完成左侧赋值前,不能执行其他赋值语句; 常用于: 产生组合逻辑语句的always 块中;直接赋值assign 语句中,注意assign 语句不能使用reg类型的变量;
- 非阻塞赋值:再时钟步开始前 计算右侧值,再时钟结束时 赋值给左侧,在此期间,可以执行其他Verilog 代码; 用于 产生时序逻辑语句的always 或者initial 块中; 只能用reg类型;只能出现再过程块中;
- 异步逻辑同步化处理, 方法有:
1.采用握手信号进行同步
2.采用打2拍的方法进行同步处理
3.采用FIFO进行同步处理 - 异步复位 与 同步复位 :
(1) asynchronous 异步复位
always @(posedge clk or negedge reset)
if(!reset) q <= 1’b0;
else q <= data;
优点: a: 大多D触发器 都有 异步复位端口 ,不带组合逻辑电路,节省端口资源;
b: 异步复位信号识别方便:方便使用FPGA 全局复位端口(如果不是FPGA全局端口,并且复位信号上没有上拉电阻,容易受到干扰并产生毛刺,这对异步复位危害大);
缺点:a: 复位信号释放 在时钟有效沿附近,就很容易出现寄存器输出出现亚稳态,不能保证每个always块被同时复位,从而不能保证每个always块同时工作;
b: 复位信号容易受到毛刺的影响
(2) synchronous 同步复位
always @(posedge clk)
if(!reset) q <= 1’b0;
else q <= data;
优点:a: 有利于仿真器的仿真;b: 可以使所设计的系统成为100%的同步时序电路,有利于时序分析; c: 只在时钟有效沿到来时才有效,可滤除高于时钟频率的毛刺
缺点:a: 复位信号的有效时长 必须大于 时钟周期,(否则的话有概率正好在2个上升沿之间而不被always块执行),b: 由于大多数的逻辑器件的目标库内的DFF都只有异步复位端口,所以,倘若采用同步复位的话,综合器就会在寄存器的数据输入端口插入组合逻辑,这样就会耗费较多的逻辑资源。
异步复位同步释放
所谓异步复位和同步释放,是指复位信号是异步有效的,即复位的发生与clk无关。后半句“同步释放”是指复位信号的撤除(释放)则与clk相关,即同步的。
异步复位:显而易见,rst_async_n异步复位后,rst_sync_n将拉低,即实现异步复位。
同步释放:这个是关键,看如何实现同步释放,即当复位信号rst_async_n撤除时,由于双缓冲电路的作用,rst_sync_n复位信号不会随着rst_async_n的撤除而撤除。
常见错误:
1.妄图修改敏感列表或赋值方式,得到不同的综合结果。
2.敏感列表不全或者赋值方式的不正确,只是会影响综合结果和仿真结果不一致,并不会对综合结果产生影响。
3.出现锁存器,锁存器主要是在没有列全的if/else,case语句中出现。锁存器的危害是其让综合器对时序估算会出问题,以及组合逻辑的缺点其也有(延迟、竞争等)
程序:
1.在程序内部,赋值中不要出现’bx,'bz等,对于三态输出,可以在最后一级通过assign语句实现。
2.敏感列表全部用always @(*)表示
3.注意寄存器的初始值,一般需要通过复位信号将其归为。
1.2 同步FIFO
- 概念:同步FIFO的写时钟和读时钟为同一个时钟,同步逻辑,常常用于交互数据缓冲。 同步:时钟间有确定的倍数关系或确定的相位关系 FIFO:Frist-in-first-out,先进先出,是一种数据缓存器,实现速率匹配。
- 典型同步FIFO有三部分组成: (1) FIFO写控制逻辑; (2)FIFO读控制逻辑;(3)FIFO 存储实体(如Memory、Reg)。
- FIFO写控制逻辑主要功能:产生FIFO写地址、写有效信号,同时产生FIFO写满、写错等状态信号;
- FIFO读控制逻辑主要功能:产生FIFO读地址、读有效信号,同时产生FIFO读空、读错等状态信号
- 既然是数据缓冲器,那么缓冲器的大小,存储深度,读写地址和存储器空满状态都需要确定
- 可以设置一个计数器,只写,来一个数据,写一个,写地址,+1,计数器+1,写满为止;只读,来一个,读出一个数据,读地址+1,计数器-1;同时读写,计数器值不变,读写地址均+1。
1.2.1 Spec
(1) Function description
同步FIFO实现了对write/read的控制,其接口解决了接口两端数据速率不匹配的问题。
(2) Feature list
支持存储宽度、深度可配置
时钟工作频率为1MHz
(3) Block diagram
一般FIFO使用循环指针(计数溢出自动归零)。一般可以称写指针为头head,读指针为尾tail。初始化时,读写指针指向同一数据地址。
 模块主要分为读/写接口、读/写指针、读写指针的比较逻辑和array存储阵列四部分。
模块主要分为读/写接口、读/写指针、读写指针的比较逻辑和array存储阵列四部分。
- 读/写接口:为模块提供读写数据和读写使能信号;
- 读写指针:主要标志读写指针当前array的地址
- 比较逻辑:使用element counter(elem_cnt)记录FIFO RAM 中的数据个数:
-
等于0时,给出empty信号;等于BUF_LENGTH时,给出full信号 elem_cnt:
-
写而未满时增加1
-
读而未空时减1
-
同时发生读写操作时,elem_cnt不变22
(4) Interface description

(5) Timing

设计思路:先分析需求,定义接口,画出具体的实现框图;按照协议和理解,画出相应时序图;看图写程序,验证仿真波形是否与时序图对应。
同步FIFO设计要点是什么时候产生空满标志位,即怎么衡量array被写满或者被读空。在这里,我使用了4bit的elem_cnt表示,通过elem_cnt的值表示当前array存储阵列的资源使用情况。0表示没有数据,即空状态;8表示写满,因为array的存储深度就是8。在spec中提到实现FIFO可配置,在这里只实现了宽度为32bit,深度为8的同步fifo设计。
对于同步FIFIO,主要是实现速率匹配,起到数据缓冲的作用。设计的关键在于array存储阵列或RAM空满标志的产生。设计的思路大概可以描述为:设置计数器elem_cnt,计数器的最小计数值为0,最大计数值,是array的最大存储深度。当写使能时,计数器计数+1,读使能时,计数器计数-1,读/写同时使能时,计数器计数值不变。当计数器的值为0时,表明此时的array没有存储数据,产生空标志;当计数值为最大存储深度值时,array存满了,此时产生满标志。 详细可参考文章《同步FIFO设计与功能验证》
1.3 异步FIFO
1.3.1 设计理念
对于异步FIFO,主要是实现不同时钟域之间的数据交互。与同步FIFO有着明显的区别,同步FIFO是使用一个时钟,读写在同一个时钟域内。而异步FIFO使用两个时钟,读/写在不同时钟域内,这个过程就涉及了跨时钟域处理的过程,跨时钟域又会产生亚稳态问题,所以这是异步FIFO设计的一个重点,与同步FIFO一样,通过空满标志衡量存储器的使用情况,那么在异步FIFO中,空满标志产生的条件和方式是什么呢,这也是设计的重点。
 **对于跨时钟域之间的信号传输,需要进行同步(synchronize)处理;**一般来讲,我们可以采用同步器(由2~3级FF组成)对单bit的信号进行同步操作。注意,这里的打拍子是针对单bit信号而已的。
**对于跨时钟域之间的信号传输,需要进行同步(synchronize)处理;**一般来讲,我们可以采用同步器(由2~3级FF组成)对单bit的信号进行同步操作。注意,这里的打拍子是针对单bit信号而已的。
1.3.2 异步FIFO的作用
1. 异步FIFO用于在不同的时钟域(clock domain)之间安全地传输数据。2. 作为不同数据宽度的数据接口(如:ADC 将数据从16位传递到32位) 而同步FIFO主要是解决数据传输速率匹配问题。
解决跨时钟域的问题:
- 对于单bit 信号,则需要使用两级或者三级同步器(FF)同步信号;
- 对于多bit 信号, 则需要用到异步fifo 或 双口 RAM
1.3.3 异步FIFO的读/写指针
写指针(write pointer)
▷ 始终指向下一次将要写入的数据的地址;
▷ 系统复位后(FIFO为空),写指针指向0地址;
▷ 每写入一笔数据,写指针地址加1;
读指针(read pointer)
▷ 始终指向当前要读出的数据的地址;
▷ 系统复位后(FIFO为空),读指针指向0地址;
▷ 此时的数据是无效的,因为还没有数据写入,空标志有效;
1.3.4 异步FIFO空/满标志

空标志(empty)
情形一,复位时,两指针都为0;
情形二,当读指针和写指针相等时,空标志=1;
满标志(full)
当写指针和读指针最高位不同,其他相等时,满标志=1;
例如,写入的速度快,写指针转了一圈(wrap around),又追上了读指针;
空满标志处理
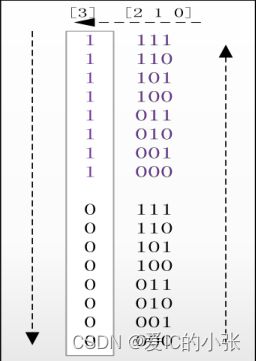
▷ 把读、写指针都额外增加1bit,假如FIFO的深度为8,理论上指针位只需要[2:0]。为了能够正确甄别空、满,需要将指针都扩展到[3:0]。
▷ 其中额外引入的最高位[3],用于辅助甄别是否已经发生了回环(wrap around)的情形。当指针计满FIFO的深度,折回头重新开始时,最高位MSB加1,其它位清0。
▷ 如果读写指针的最高位不同,就意味着写指针速度快,并已经多完成一次回环。
▷ 如果两个指针的最高位相同,就意味着双方完成了相同次数的回环。
满信号的产生: 读地址指针 延迟两拍 和 写地址 比较;
空信号的产生: 读地址指针 和 写地址指针 延迟两拍 比较;
延迟两拍的原因: 产生虚空 和 虚满 , 给设计留有余量; 解决跨时钟域 单bit 的亚稳态
指针计数器的选择
- 普通二进制计数器(Binary counter)
在异步FIFO的设计中,读写两边要互相参考对方的指针,以便生成空、满标志;
数据同步问题: > 1 bit,从一个clock domain到另一个clock domain,由于亚稳态现象的出现,会导致数据出错; 极端情形:所有的数据位都变化;
解决办法: 采用sample & hold机制,引入保持寄存器和握手机制,以确保接收端正确地采集到想要的数据,之后通知发送端,进行下一轮的数据传输;
- 二进制转成了格雷码,但仍存在一个隐藏的竞争冒险问题

A点输出的是二进制数据,可能存在多位变化,但是经过转格雷码电路 bin to gray (组合逻辑电路)就不会产生竞争现象了吗,仔细想想,当A点二进制数据处于变化中的中间态时,由于 bin to gray 是组合逻辑电路,那么B点也会出现中间态二进制数据对应的格雷码数据,这个中间数据就有可能被读时钟域采样到,从而再次引发误判,解决方法就是在二进制转格雷码电路后打一拍转为时序逻辑电路,这样在写时钟的驱动下,C点数据每次更新必然只有一位在变化,就避免了出现冒险现象。
- 格雷码计数器(Gray code counter):每次当从一个值变化到相邻的一个值时,有且仅有一位发生变化;
- 由于格雷码的这种特性,我们就可以通过简单的synchronizer对指针(多位宽)进行同步操作了,而不用担心由于发生亚稳态而出现数据错误的情形;
- 但是对于我们习惯了二进制码的风格,这种码易读性稍差;
- 对于2的整数次幂的FIFO,采用格雷码计数器器; 接近2的整数次幂的FIFO, 采用接近2的幂次方格雷码修改实现;如果这两种都满足不了,就设计一种查找表的形式实现。所以,一般采用2的幂次方格雷码实现FIFO,会浪费一些地址空间,但可以简化控制电路;
**需要注意:**格雷码计数器适用于地址范围空间为2的整数次幂的FIFO,例如8, 16, 32, 64…
答:格雷码如果每2的n次方 个数一循环,首尾两个格雷码仍然是只有一位变化,如果不是2的n次方 个数,那么首尾数据就不是仅有一位变化,那就不是真正的格雷码,所以这也是异步FIFO的存储深度只能是2的n次方的原因。
1.3.5 Spec
(1)Function descripton
通过控制两个不同时钟域的读/写操作,完成了两个时钟域之间数据的同步处理。
(2)Feature list
- 存储器采用宽度为16,深度为8的regs
- FIFO宽度、深度可配置
- 写时钟为3MHz,读时钟为2MHz
(3)Block Diagram

异步FIFO的核心部件就是一个 Simple Dual Port RAM ;左右两边的长条矩形是地址控制器,负责控制地址自增、将二进制地址转为格雷码以及解格雷码;下面的两对D触发器 sync_r2w 和 sync_w2r 是同步器,负责将写地址同步至读时钟域、将读地址同步至写时钟域。
(4)Interface description

(5)Timing
Write timing

Read Timing
1.3.6 异步FIFO 答疑解惑
- 为什么判断空满信号,要使用格雷码,我知道使用格雷码不容易出错,为什么要使用格雷码?
答:异步FIFO是通过比较读指针和写指针的位置来判断FIFO是否写满或读空,但是不可以直接比较两个指针,因为他们属于不同时钟域,直接相比可能会产生亚稳态从而引起误判,这就需要将两个指针分别进行跨时钟域处理,然后再判断。 - 为什么同步时,写格雷码 要用 读时钟?
答:为了同步读写时钟域的数据 - 对格雷码编码电路打拍和跨时钟域的打两拍会导致其中一个时钟域跨过来的地址数据滞后,这样会导致FIFO工作异常吗?
答:不会。在写时钟域中,写地址是本地数据,无延迟,读地址是跨时钟域而来,有一定的延迟。“写满” 的判断条件是读写指针高位不同,其他位相同,当 “写满” 信号出现时,意味着写指针和读指针的低四位已经相同,而此时的读指针可能不是真正的读指针,也就是假设参与判断的读指针是5时,实际的读指针可能已经到8了,这说明读出的数据更多了,也就是 “写满” 标志来早了,其实这并不是真正的写满,而是 “假满” 。
在读时钟域中,读地址是本地数据,无延迟,写地址是跨时钟域而来,有一定的延迟。“读空” 的判断条件是读写指针相同,当 “读空” 信号出现时,意味着读指针和写指针已经相同,而此时的写指针可能不是真正的写指针,也就是假设参与判断的写指针是3时,实际的写指针可能已经到6了,这说明写入的数据更多了,也就是 “读空” 标志来早了,其实这并不是真正的读空,而是 “假空” 。
但 “写满” 和 “读空” 标志来早并不会影响异步FIFO的正常工作,仅相当于FIFO的有效深度减小了,也可以看做是对FIFO的一种保护,防止写溢出或读溢出。 - 异步FIFO的读写时钟频率不同,在进行两级跨时钟同步时,慢时钟会对快时钟域下的数据产生 “漏采” 现象,这会影响异步FIFO的功能吗?
答:不会。当读慢写快时,将格雷码格式的写指针同步到读时钟域,可能会发生漏采现象。比如写指针从1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8,而读时钟仅采样到了2 -> 4 -> 6,但这些漏掉的读指针并不会影响FIFO的逻辑功能,当读时钟采样到6时,它以为采样到了最新的数据6,而实际的最新的数据已经写到了8,和第一个问题一样,这也会让 “读空” 标志来早,从而保护FIFO。
1.4 锁存器、触发器、寄存器、缓冲器
1、锁存器(latch)
是电平触发单元,数据存储的动作取决于输入时钟(或使能)信号的电平值,仅当锁存器处于使能状态时,输出才会随着数据的输入发生变化。
简单说:两输入信号为使能信号EN,数据输入信号DATA_IN,以及一个输出信号Q,它的功能就是在EN有效的时候把输入数据DATA_IN的值传给Q,EN无效的时候就保持原有输出状态,直到EN再次有效,这就是锁存过程。也称透明锁存器,即不锁存时输出与输入始终一致,输出对输入而言是透明的。
2、触发器(Flip_Flop,简写FF)
也叫双稳态门,又称双稳态触发器,是一种可在两种状态下运行的数字逻辑电路。触发器一直保持它们的状态,直到它们收到输入脉冲,即触发。当收到输入脉冲时,触发器输出就会根据规则改变状态,然后保持这种状态直到下一次触发。触发器对脉冲边沿敏感,其状态只在时钟的上升/下降沿的瞬间改变。
3、锁存器和触发器的区别
锁存器和触发器是具有记忆功能的二进制存储器件,是组成时序逻辑电路的基本器件之一。
区别在于,latch同所有的输入信号相关,当输入信号变化时latch就变化,没有时钟端;flip-flop受时钟控制,只有在时钟触发时才采样当前的输入,产生输出。当然,因为锁存器和触发器都是时序逻辑,所以输出不但同当前的输入相关,还与上一时间的输出相关
具体如下:
(1)latch是电平触发,非同步控制。使能信号有效时,latch相当于通路,无效时保持输出状态。DFF由时钟边沿触发,同步控制。优点:面积小,速度快,消耗资源少
(2)latch对输入电平敏感,受布线延迟影响较大,很难保证输出没有毛刺产生,而DFF则不易产生毛刺。
(3)如果使用门电路搭建latch和DFF,则latch消耗的门资源比DFF要少,这是latch优越的地方。故ASIC中使用latch的集成度比DFF高,但在FPGA中则正好相反,因为FPGA中没有标准的latch单元,但有DFF单元,一个Latch多个LE才能实现。
很多时候latch是不能代替FF的。
(4)latch将静态时序分析变得极为复杂。
一般设计规则是,在绝大多数设计中避免产生latch。因为latch会让设计的时序混乱,并且它的隐蔽性很强,很难检查。**Latch最大的危害在于不能过滤毛刺,这对下一级电路是极其危险的。**所以能用D触发器的地方就不用latch。
有些地方没有时钟,也只能使用latch了。比如现在将一个clk接到latch的使能端(假设高电平是能),这样需要的setup时间(建立时间)就是数据在时钟的下降沿之前需要的时间
4、寄存器(register)
用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果,它被广泛的用于各类数字系统和计算机中。就是个常用的时序逻辑电路,但这总时序逻辑电路只包含存储电路。
**寄存器的存储电路是由 锁存器 或 触发器 构成的,**因为一个锁存器或触发器存储1位二进制数,所以由N个锁存器或触发器可以构成N位的寄存器。工程中的寄存器一般按计算机中字节的位数设计,所以一般有8位、16位寄存器。
寄存器的应用:
- 完成数据的并串、串并转换;
- 用作显示数据锁存器: 如许多设备需要显示计数器值,以BCD码计数以数码管
- 显示,若计数速度较高人眼则无法发觉变化的字符。在计数器和译码器之间加一个锁存器,控制数据的显示时间是常用的方法
- 用作缓冲期;
- 组成计数器:移位寄存器可以组成移位型计数器如环形和扭环形计数器。
寄存器与锁存器的区别
寄存器与锁存器的功能是提供数据寄存和锁存。寄存功能是指把数据暂时保存,需要时取出。锁存功能是指总线电路中,锁定数据输出,使输出端不随输入端变化。
5、移位寄存器
移位寄存器:具有移位功能的寄存器称为移位寄存器。寄存器只有寄存数据或代码的功能。**有时为了处理数据,需要将寄存器中的各位数据在移位控制信号作用下,依次向高位或向低位移动1位。**移位寄存器按数码移动方向分类有左移,右移,可控制双向(可逆)移位寄存器;按数据输入端、输出方式分类有串行和并行之分。除了D边沿触发器构成移位寄存器外,还可以用诸如JK等触发器构成移位寄存器。
6、总线收发器/缓冲器
缓冲寄存器:又称缓冲器(buffer):多用在总线上,提高驱动能力、隔离前后级。
缓冲器多半有三态输出功能。当负载不具有非选通,输出为高阻特性时,将起到隔离作用;当总线的驱动能力不够驱动负载时,将起到驱动作用。
由于 缓冲器接在数据总线 上,故必须具有三态输出功能。它分 输入缓冲器 和 输出缓冲器 两种。
输入缓冲器: 将外设送来的数据暂时存放,以便处理器将它取走;
输出缓冲器: 是用来暂时存放处理器送往外设的数据。有了数控缓冲器,就可以使高速工作的CPU与慢速工作的外设起协调和缓冲作用,实现数据传送的同步。
Buffer: 缓冲区, 一个用于在初速度不同步的设备或者优先级不同的设备之间传输数据的区域。通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据时,速度快的设备的操作进程不发生间断。
缓冲器主要是计算机领域的称呼。具体实现上,缓冲器有用锁存器结构的电路来实现,也有用不带锁存结构的电路来实现。一般来说,当收发数据双方的工作速度匹配时,这里的缓冲器可以用不带锁存结构的电路来实现;而当收发数据双方的工作速度不匹配时,就要用带锁存结构的电路来实现了(否则会出现数据丢失)。
缓冲器在数字系统中用途很多:
如果器件带负载能力有限,可加一级带驱动器的缓冲器;
前后级间逻辑电平不同,可用电平转换器加以匹配;
逻辑极性不同或需要将单性变量转换为互补变量时,加带反相缓冲器;
需要将缓变信号变为边沿陡峭信号时,加带施密特电路的缓冲器;
数据传输和处理中不同装置间温度和时间不同时,加一级缓冲器进行弥补等等。
第二章 SV
SV4.接口和连接设计与验证平台
SVA断言-有待后续
SV5.面向对象编程
SV6.随机化
SV7.线程及线程间的通信
SV8.OOP高级
SV9.功能覆盖率
SV12.SV与C语言的接口
第三章 UVM
UVM与SV的比对
第四章 脚本语言
4.1 一文读懂Shell
4.1.1 Shell 是什么?
shell是一个命令解释器,它可以用来启动、挂起、停止甚至编写程序。shell是Linux操作系统的一个整体组成部分,也是Linux操作系统和UNIX设计的一部分。
4.1.2 shell的种类 : .sh、.bash、.csh、.tcsh(命令补全)、.ash 等。
4.1.3 shell命令的基本格式
命令名 [选项] <参数1> <参数2> …
[选项]是对命令的特别定义,以减号(-)开始,多个选项可以用一个减号(-)连起来,
ls -l -h 与 ls -lh 相同。
<参数>提供命令运行的信息,或者是命令执行过程中所使用的文件名。
4.1.4 notice
- .Linux严格区分大小写
- 使用分号( ; ) 一行中输入多个命令。
- 按下Table键,自动补齐命令、目录或文件名
- 系统会把过去输入过的命令记忆下来,只要按方向键中的上下箭头
4.1.5 输入输出重定向:
输入定向:
输出定向: >, >>
4.1.6 常用命令
4.1.6.1 切换工作目录命令cd
[cd : Change Directory]
所谓工作目录,就是当前操作所在的目录。用户在使用Linux的时候,经常需要更换工作目录。cd命令可以帮助用户切换工作目录,后面可跟绝对路径,也可以跟相对路径。 (1).如果省略目录,则默认切换到当前用户的主目录。 (2).还可以使用“~”、“.”和“…”作为目录名, cd 目录名 例如,切换到/usr/bin/可用如下命令: # cd /usr/bin
4.1.6.2 显示当前路径命令pwd
[pwd: print work directory]
打印当前目录 显示出当前工作目录的绝对路径
4.1.6.3 查看目录命令ls [ls: list]
[ls: list]
ls常用的参数及含义
ls -R 显示当前目录及以下的所有文件(递归的)
ls -r 从后向前地列举当前目录中的内容
-a 显示指定目录下所有子目录与文件,包括隐藏文件
-c 按文件的修改时间排序
-F 在列出的文件名后以符号表示文件类型:目录文件后加“/”,可执行文件后加“*”,符号链接文件后加“@”,管道文件后加“|”,socket文件后加“=”
-h 以用户习惯的单位表示文件的大小,K表示千,M表示兆。通常与-l选项搭配使用
-l 以长格式显示文件的详细信息。每行列出的信息依次是:文件类型与权限、链接数、文件属主、文件属组、文件大小、文件建立或修改的时间、文件名。对于符号链接文件,显示的文件名后有“—>”和引用文件路径名;对于设备文件,其“文件大小”字段显示主、次设备号,而不是文件大小。目录中总块数显示在长格式列表的开头,其中包含间接块
-s 按文件大小排序
-t 按文件建立的时间排序,越新修改的越排在前面
-u 按文件上次存取时间排序
4.1.6.4 显示文件命令 cat
文件查看和连接命令cat : , :可以用于即合并文件
常用参数及含义
-b 显示文件中的行号,空行不编号
-E 在文件的每一行行尾加上“$”字符
-T 将文件的Tab键用字符“^I”来显示
-n 在文件的每行前面显示行号
-s 将连续的多个空行用一个空行来显示
-v 显示除Tab和Enter之外的所有字符

4.1.6.5 分屏显示命令 more:
more [选项] 文件名
和cat命令类似,more可将文件内容显示在屏幕上,
1.每次只显示一页,
2.按下空格键可以显示下一页,
3.按下q键退出显示. 文件中搜索指定的字符串。

4.1.6.6 按页显示命令less
less [选项] 文件名
less 命令作用和more命令类似,可用于浏览文本文件的内容。
(1).less命令允许用户使用光标键反复浏览文本。
(2).less可以不读入整个文本文件,因此在处理大型文件时速度较快。
(3).与more命令相比,less命令的功能更加前大。
4.1.6.7 复制命令cp:[cp:Copy file]
其基本使用格式如下: cp [选项] 源目录或文件 目标目录或者文件 (选项一般用 -i)
cp 命令的功能是将给出的文件或目录复制到另一个文件或目录中,相当于DOS下的copy命令。
该命令可以同时复制多个源文件到目标目录中,在进行文件复制的同时,可以指定目标文件的名称。
-a 该选项通常在复制目录时使用,它保留链接、文件属性,并递归地复制目录
-d 复制时保留链接
-f 删除已经存在的目标文件而不提示
-i 交互式复制,在覆盖目标文件之前将给出提示要求用户确认
-p 此时cp命令除复制源文件的内容外,还将把其修改时间和访问权限也复制到新文件中
-r 若给出的源文件是目录文件,则cp将递归复制该目录下的所有子目录和文件,目标文件必须为一个目录名
-l 不作复制,只是链接文件
4.1.6.8 删除命令rm:[rm :Remove(删除目录或文件)]
rm [选项] 文件名
rm 命令可以删除一个目录中的一个或多个文件或目录,也可以将某个目录及其下的所以文件及子目录均删除。删除链接文件时,只是断开了链接,原文件保持不变。
-i 以进行交互式方式执行
-f 强制删除,忽略不存在的文件,无需提示
-r 递归地删除目录下的内容
4.1.6.9 移动或重命名命令
mv [选项] 源文件或目录A 目标文件或目录B
使用mv命令跨文件系统移动文件时,先复制文件,再将原有文件删除,而链接至该文件的链接也将丢失。
-i 交互方式操作,如果mv操作将导致对已存在的目标文件的覆盖,系统会询问是否重写,要求用户回答以避免误覆盖文件
-f 禁止交互式操作,如有覆盖也不会给出提示
4.1.6.10 创建目录命令
mkdir [参数] 目录名
-m 对新建目录设置存取权限
-p 如果欲建立的目录的上层目录尚未建立,则一并建立其上的所有祖先目录
4.1.6.11 删除空目录命令
rmdir [-p] 目录
参数-p表示递归删除目录,当子目录删除后,其父目录为空时也一同被删除。命令执行完毕后,显示相应信息。 rm –r 也可删除目录及其下的文件和子目录。
4.1.6.12 查找文件或者目录命令find
find [路径] [选项]
-name 指定搜索的文件名,输出搜索结果
-user 搜索指定用户搜索所属的文件
-atim 搜索在指定的时间内读取过的文件
-ctim 搜索在指定的时间内修改过的文件
4.1.6.13 文件定位命令 locate/slocate
locate [参数] 文件名
locate命令是利用事先在系统中建立系统文件索引资料库的,然后再检查资料库的方式工作的。
为了提高locate命令的查出率,在使用该命令前必须拥有最新的资料数据库。
-u 建立资料数据库,从根目录开始
-U 建立资料数据库,从目录开始
-e 排除dir目录搜索
4.1.6.14 文件内容检索命令grep
grep [选项] < string 文件内容> 文件名
搜索/etc/vsftpd目录下后缀为.conf文件中,其内容中包含“anon”字符串的文本行。
[root@myhost root]# grep anon /etc/vsftpd/*.conf
-v 显示不包含匹配文本的所有行
-n 显示匹配行及行号
4.1.6.15 链接命令
In [参数] <源文件或目录> <源文件或目录>
分为软链接和硬链接
- 软链接:[root@linux pp]# In -s /usr/share/doc doc 创建一个软链接文件doc, 并指向目录/usr/share/doc
- 硬链接:[root@linux pp]# In /usr/share/test hard 创建一个硬链接文件hard,这时对于test文件对应的存储区域来说,又多了一个文件指向它。
4.1.6.16 创建文件、改变文件或目录生成时间命令 touch
touch [参数] <文件名>
touch* 将当前的文件时间修改为系统的当前时间
touch -d 20200111 test 将test文件的日期改为20200111
4.1.6.17 打包命令 tar
tar -cvf test.tar * 将所有文件打包成test.tar, 扩展名.tart需自己给定;
tar -zcvf test.tar.gz * 将所有文件打包成test.tar,再用gzip命令压缩;
tar -tf test.tar 查看test.tar文件中包括了那些文件;
tar -xvf test.tar 将test.tar解开
tar -zxvf foo.tar.gz 解压缩
-c: 创建一个新tar文件
-v: 显示运行过程的信息
-f: 指定文件名
-z: 调用gzip压缩命令进行压缩
-t: 查看压缩文件的内容
-x: 解开tar文件
4.1.6.18 压缩命令 zip 和gzip
解压缩命令unzip 和gunzip
zip是将文件打包为zip格式的压缩文件
unzip是从zip包中解压出某个文件
gzip是将文件打包为tar.gz格式的压缩文件
gunzip从tar.gz包中解压出某个文件
4.1.6.19 修改时间 date; 日历 cal ; 显示时间命令 clock

4.2 Perl
4.2.0 Perl的小技巧集合
- 可得到布尔类型的变量:!! !会颠倒真假值,但是perl没有布尔变量,所以!返回某个代表真假的标量值,
可以通过两次的!反转操作,得到表示布尔值的变量:
$still_true = !! ‘fred’; #真
$still_false = !! ‘0’; #假 - control+C 可以 停止程序运行
- perl -c 文件, 检查语法错误
- 以root权限运行 find /your/path/ -type f -name “*.py” -exec chmod u+x {} ;
- 程序开头 #!/your/path/perl 表示 perl作为本文件的解释器
- chmod u+x /your/path/perl 打开执行文本的权限, 写入一些perl程序后,再赋予执行权限就可以执行了
- 我的Linux中 不支持 ./filename0 filename1 filename2, 这样可以执行
perl filename0 filename1 filename2
意思是 运行 filename0,如果 filename0 里由输入<>,则将 filename1 filename2 输入 filename0 的<>;
4.2.1 Perl的概述
-
Perl : Practical Extraction and Report Language (实用报表提取语言)
-
perl2 (添加了正则表达式引擎), perl3 (支持而简直数据流)perl 5(直译器)+module,目前perl 5.36
-
perl的特点:
简单: 无需事先声明, 不区分整型、字符串等
c 程序:
int num = 1;
char sArr [] =“Hello World”;
printf(“%s, I’m class %d\n”, sArr, num);
Perl程序:
my $num =1;
my $p_str ="Hello World, I'm class ". $num."\n";
printf "$p_str\n";
快速: Perl 解释器直接对源代码程序解释执行,不需要编译器 链接器
灵活: 借鉴了C/C++ Basic Pascal awk sed等多种语言
开源、免费
-
应用场合: 文本处理,Web网站、数据库处理、邮件处理和FTP功能自动化、 作图
-
下载文件: 搜索www.activestate.com ,划到最下边找到perl ,一步步下载安装(自己搜索)
-
linux自带perl 输入 perl -v 即可显示 version; 且 在linux的 terminal下直接输入perl 程序名即可执行, 如 perl test.pl
-
良好的Perl 开发习惯:
如果想在源代码中使用 Unicode(或者出现了除ASCII字符外的字符)书写直接量的话,请加上 use utf8 编译指令;
使用内建警告信息:
程序中加上 -w 命令行(推荐) 如 #! /usr/bin/perl -w;运行时, $perl -w my_program;
perl 5.6 版本后,可以通过warning 指令打开 #!/usr/bin/perl use warnings 局部代码 no warnings,*看不懂警告信息时,程序中加上这个命令:use dianostics *程序很长,找不到错误的原因时,* 加上 use strict 强制终止程序运行,可避免错误拼写 *遇到不认识的函数等时,* 使用命令 perldoc 查询内容; perldoc -f 查询perl内建函数; perldoc perlsyn: 返回perl语法的详细说明; preldoc -f print: 返回print函数的说明; perlodc perl: 返回perl文章列表, 如概述、使用手册等
4.2.2 Perl的数据类型
4.2.2.1 标量
4.2.2.1.1 数字标量: Scalar, 以$开头, 值为 “数字” 的标量,
全部为双精度浮点数,范围是 +/-10的100次方 如
$data = 10; <=> $data = 10.00; 等价
3.1415926;
2.18e-10 <=> 2.10E-10; 等价
3141592639 <=> 3_141_592_639; 下划线隔开,便于查看
八进制, 以0开头 0377 ##十进制的255
16进制, 以0x开头 0xFF ##十进制的255(0xff)
八进制, 以0b开头 0b1111_1111 ##十进制的255
4.2.2.1.2 字符串标量: 标量值为字符串, 由引号标识
字符串由可输出的字母、数字和标点符号组成,如 $data = “Hello, World”;
“Hello, World” <=> ‘Hello, World’ <=> ‘\Hello, World’ <=> “\Hello, World” 等价
4.2.2.1.3 字符串操作符:
- 英文的句号**.** 用于 连接字符串
“Hello” . “world” ##等同于“Helloworld” . 英文的句号用于 连接字符串; - 重复操作符:小写字母 x
“fred” x (2+1) ## “fredfredfred”;
5 x 4.8 ## “5555” 本质是5先从单字符转化成字符串"5", 然后被重复了4次,得到“5555”
3.1 数字和字符串之间的自动切换 这取决于操作符,
自动转换总是对十进制数字处理的,
运算符 会识别 字符串里的数字;
连接字符和重复操作符 将数字 转化为 字符串 再操作;
“12” * “3” 结果会是数字36
“12fred34” * “3” 结果会是数字36
“fred” * “3” 结果会是数字0
“Z” . 5 * 7 结果会是’‘Z35’
3.2 字符串中的标量变量内插
$m = "fred";
$barney = "fred ate a $m";
$barney = 'fred ate a' . $m; 和上一个等效
print $m; 等效于 print $m";
3.3 借助代码点创建字符
目的是 输入键盘上没有的 那些字符
代码点 code point ; chr()函数
#通过chr 函数把 代码点 转成 字符
$alef = chr(0x05D0);
$alpha = chr(hex('03B1'));
$omega = chr(0x03C9);
#双引号的变量内插
#"$alef$omega"
#通过ord函数把 字符 转成 代码点
$code_point = ord('? ');
#如果不预先创建遍变量,也可以用\x{}
"\x{03B1}\x{03C9}"
4.2.2.1.4 单引号、双引号 的区别:
- 转义字符 只在 双引号 中有效
| \n | 换行 |
|---|---|
| \r | 回车 |
| \t | 水平制表符 |
| \f | 换页符 |
| \l | 下个字符转小写 |
| \u | 下个字符转大写 |
4.2.2.1.5 标量的声明及作用域:
**标量的声明:**
- 标量可在任意位置随时声明并使用, 默认初始值为空
- 标量名
可以是字母、数字或者下划线,区分大小写,取名和用途相关
标量的作用域:
- 指的是一个标量可以被有效访问使用的范围
- 两种标量的作用域范围
4.2.2.1.6 变量
符号 $
包变量:
一个package or 一个主函数就看做是一个包
默认情况是包变量,包内全局变量,在包内及子函数均可使用
私有变量: 分为my类型,local类型
my 变量:只 在本层模块可以看到这个变量(一个模块指的是两个花括号之间的内容),当其内部调用外部子函数时,外部子函数不选用my 变量
my 操作符 并不会改变 变量赋值时的上下文;
my ($fred, $barney); 声明两个变量
持久性私有变量:
my创建的私有变量, 会在每次调用这个子程序的时候,这个私有变量会被重新定义,没有保留上次调用时的值。
my 声明的必须是独立变量,不能声明哈希或数组里的元素
使用 state 操作符声明变量, 可以在子程序的多次调用期间保留变量之前的值,并将变量的作用域限制在子程序内部。这个只能声明变量,不能声明哈希类型
想声明 持久性数组 如 state @names, 须在 use warnings; 后添加 use feature ‘state’;
sub marine{
my $n += 1;
print $n;
}
compare 这两个
sub marine{
state $n = 0; #持久性私有变量 $n;
$n += 1;
print $n;
}
local 变量:本层和本层以下 的函数都可以看到的变量
4.2.2.2 数组
数组: 标量数据的有序列表,是多个标量数据的一种集合;
perl中数组只是一维 通过引用使用二维数组
可以包含任意多个元素,从0到全部占满内存;
以@符号作为标识, 有序排列:元素位置固定; 不区分字符串和数字类型
$rocks[0] = 'bed';
...
rocks[99] = 'schist';
$rocks[$#rocks] = 'the last member of array'; # $#rocks代表索引值
$rocks[-1] = 'the last member of array';# 结果同上,一般利用‘负数数组索引值’,无效的负数索引值如-105,不会绕道数组尾部,而是undef

列表: 包含了一系列值的列表,以括号标识,中间用逗号隔开

“…” 范围操作符 注意 if m>n, 列表为空

纯字符串列表 可以用"qw" 表示,省去对字符串加引号的过程

qw(this is \ real); 两个连续的反斜线 表示一个 实际的反斜线;
qw{
/usr/dict/words
/home/rootbeer/.ispell_english
} #
列表赋值
($fred, $barney, $dino) = ("flintstone","rubble",undef); #列表值赋给变量
($fred, $barney) = ($barney, $fred); #交换这两个变量的值
($fred, $barney) = qw< flintstone rubble slate granite>; #忽略末尾的两个元素
($fred, $dino) = qw[flintstone]; # $dino的值为undef
数组赋值
- 可直接将 列表量 传递给 数组

- 数组间赋值 (修改array2,并不会影响array1)

3. pop 和 push 赋值(对数组最右边的元素操作)
pop操作符: 取出数组最右边一个元素,同时返回该元素值

push操作符:添加一个元素(标量或者数组)到数组的尾端

4. shift 和 unshift 赋值 (对数组最左边的元素操作)
shift操作符: 取出数组最左边的一个元素,同时返回该元素值
若 在子程序中调用shift 如: my $list = shift; shift 后边没有数组,其实是省略的数组@参数,即为 my $list = shift @;

unshift操作符:添加一个元素(标量或者数组)到数组的前端

5. splice操作符
添加或者删除或替换 数组中间的某些元素; 最多可接受4个参数,最后两个是可选参数;
替换:
@array = qw( pebbles dino fred barbey betty);
@removed = splice @array, 1, 2 qw(wilma); # 删除dino fred这两个元素
# @removed 变成qw(dino fred)
# 而 @array则变成qw(pebbles wilma barbey betty)
参数 @array: 要操作的目标数组
参数 1 :要操作的一组元素的开始位置
参数 2 :操作的元素个数,即长度
参数 qw(wilma): 要替换的列表,如果不写第四个参数,则用空元素代替要删除的字
6. 字符串中的数组内插
数组被内插后,首尾不会增添额外空格
@rocks = qw{ fred barbey betty };
print "quatrz @rocks limstone\n";
这样可能会因为内插数组@符号,被警告:
$email = "fred\@bedrock.edu"; #正确,加\即可,将@转义
$email = '[email protected]'; #效果相同
内插数组中的某个元素:
@fred = qw(hello dolly);
$y = 2;
$x = "This is $fred[1]'s place"; # 得到 This is dolly's place
$x = "This is $fred[$y-1]'s place"; # 得到 This is dolly's place
索引表达式[1]会被当成普通字符串处理:
@fred = qw(eating rocks is wrong);
$fred = "right"; # 我们想表达 "this is right[3]"
print "this is $fred[3]\n"; # 用到了$fred[3], 打印”this is wrong“
print "this is $fred"."[3]\n"; # 打印 "this is right[3]"
print "this is ${fred}[3]\n"; # 打印 "this is right[3]",这个相当重要
print "this is $fred\[3]\n"; # 打印 "this is right[3]"
数组元素的访问(索引)
-
通过 索引 对数组元素访问(修改列表的值,对应数组的值也会改变, $array[4]是空值)

-
特殊索引
$end = $#array; 显示 数组元素格式
$array[-1]; 显示 数组元素中的最后一个

4.2.2.3 引用
引用 作为一种数据变量,可以指向变量、数组甚至子程序,代指值的地址;
Perl中 引用 和 指针 无差别, 通用
格式: $<标量>,@<数组>, 即为 地址

软引用
软引用 类似 软链接, 存储了一个变量的名字

硬引用
硬引用 类似 硬链接, 存储地址

硬引用 的 解引用
由于引用时地址,所以用 {} 解引用

引用有助于创建复杂数据
下列形式类似于二维数组
@array = ([1..5], "Hello");
${$array[0]}[0] ##值为1
4.2.2.4 chomp()函数
chomp 只能用于单个变量,且变量内容必须是字符串,如果该字符串末尾是\n换行符,chomp()只能去掉一个换行符,不能去掉两个换行符。
函数chomp()的返回值是 实际移除的字符数
如果没有可移除的换行符,会返回0.
$food = chomp($text = 4.2.2.5 undef值
新变量当作0或者空字符来使用
# 这里的$sum就是undef,不妨碍运行,默认当成数字
#累加一些奇数
$n = 1;
while ($n < 10){
$sum += $n;
$n +=2; # 准备下一个奇数
}
print "The total was $sum.\n";
# $string 初始值是undef, 这是一个字符串累加器,
$string .= "more text\n";
4.2.2.6 defined() 函数
文章结尾,没有更多输入时,输入函数STDIN 会返回 undef, 要判断某个字符串是否为空字符串,可以使用defined函数。
如果是undef,则defined()函数返回假, 否则返回真
$madonna = 4.2.2.7 默认变量:$_
不唯一,但最常用;省略,减少动手
# $_ 除了长得比较特殊外,和其他标量变量没差别
foreach (1..10) { #默认会用$_ 作为控制变量
print "I can count to $_!\n";
}
$_ = "Yabba doo\n";
print; #默认打印$_变量的值
4.2.2.8 reverse操作符
reverse 会读取 列表的值(也可能来自数组),并按照相反的次序 返回该列表,
但不修改传进来的参数。
假如reverse 函数的返回值 无处可去,则reverse 毫无意义
@fred = 6..10;
reverse(@fred); #错误,不会修改@fred的值,毫无意义
@ba = reverse(@fred); #得 10,9,8,7,6
@aa = reverse 6..10; #同上
@fred = reverse @fred; #将逆序后的结果放回原来那个数组
Perl 会先计算 等号右边 要赋的值,再实际进行赋值操作。
4.2.2.9 sort操作符
sort()会读取列表的值或者数组,根据内部的字符编码顺序对他们进行排序;
按照ASCII码, 数字在字母前,大写字母在小写字母前,
@rocks = qw / bedrock slate rubble granite/;
@sorted = sort(@rocks); # 得 bedrock granite rubble slate
@back = reverse sort @rocks; # 等同于 reverse @sorted
@rocks = sort @rocks; # 将排序后的结果存回@rocks
@numbers = sort 97..102; # 得 100,101,102,97,98,99
sort @rocks; 错误,不会排序@rocks的值,毫无意义
4.2.2.10 each 操作符
对 数组 调用 each,会返回数组中下一个元素对应得两个值–该元素得索引以及该元素得值;
my @rocks = qw/ bedrock slate rubble granite /;
while(my($index, $value) = each @rocks){
say "$index: $value";
}
or
foreach $index (0..$#rocks){
print "$index: $rocks[$index]\n";
}
4.2.2.11 标量与列表上下文(Perl中最重要的知识点)
体会这些code吧, 相信你的直觉 判断表达式得到得是 标量 或者是 列表 !
简单通过上下文知道 是标量还是列表:
42 + something # something 必须是标量
sort something # something 必须是列表
@people = qw(fred barney betty);
@sorted = sort @people; # 列表上下文:barney, betty, fred
$number = 42 + @people; # 标量上下文:42 + 3,得45
@list = @people; # 得到3个人得姓名列表
$n = @people; # 得到人数3
在标量上下文中使用 产生列表的表达式:
$sorted = sort @people; # 返回undef,而不是排列后得元素个数
@backwards = reverse qw/ yabba dabba doo/; # 会得到doo,dabba,yabba
$backwards = reverse qw/ yabba dabba doo/; # 会得到doodabbayabba
在列表上下文中使用 产生标量的表达式:
@fred = 6*7; #得到列表(42)
@barney = "Hello" . '' . "World";
@wilma = undef; # 得到 未定义的(undef)
@betty = (); # 这是清空数组的做法
看上下文:
$fred = something; # 标量上下文
@pebbles = something; # 列表上下文
($wilma, $betty) = something; # 列表上下文
($dino) = something; # 列表上下文
标量上下文:
$fred = something;
$fred[3] = something;
123 + something;
if (something){...}
while(something){...}
$fred[something] = something;
列表上下文:
@fred = something;
($fred, $barney) = something;
($fred) = something;
push @fred, something;
foreach $fred (something) {...}
sort something;
reverse something;
print something;
强制指定 标量 上下文:
@rocks = qw( talc quartz jade obsidian );
print "How many rocks do you have?\n";
print "I have ", @rocks, " rocks!\n"; # 错误,这会对输出各种石头的名称
print "T have ", scalar @rocks, "rocks!\n" # 对, 打印出石头的种数
伪函数 scalar 不是真的函数,而是告诉 Perl 这里要切换到标量上下文
4.2.2.12 return 操作符
如果想在子程序中执行到一半时停止操作,return 会停止操作,并返回某个值
my @names = qw / fred barney betty dino/;
my $result = &which_elements_is("dino", @names); # “dino” = $waht; @names = @array 对应两个参数
sub which_elements_is {
my ($waht, @array) = @_;
foreach (0..$#array) { # 数组@array中所有元素的索引
if( $waht eq $array[$_]) {
return $_; # 一发现就提前返回
}
}
return -1; # 没找到符合条件的元素(写不写return都没关系)
}
4.2.3 运算符
4.2.3.1 算数运算符
四则运算
特殊的四则运算 :带有字符串的变量间 运算,从最左起看,如果第一个时a-z,则该变量就是0;如果第一个是数字0-9,则该变量即为该 连续的数字, 如“30ac2” 即为30。

乘幂运算

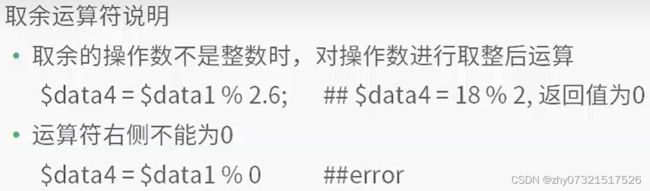
取余运算

单目负运算
d a t a 5 = − − data5 = -- data5=−−data4;
运行时,在data4的基础上-1即data4为-6,再将右侧结果-6赋给data5。最终 $data4 = -6;


运算符的省略形式

4.2.3.2 比较运算符
数据的 大小 和 相等性 比较
数字比较运算符
满足比较符,返回1,否则0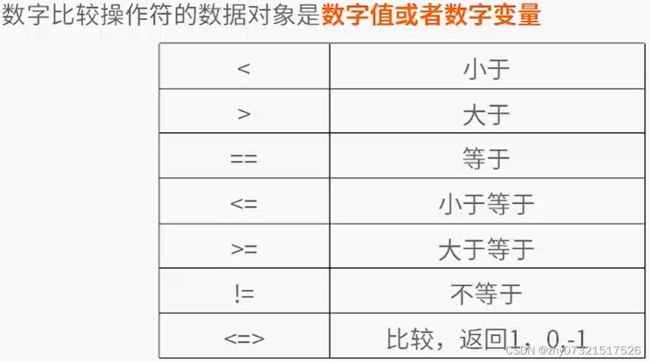
字符串比较运算符
gt: greatter than
ge: greatter equal
lt: little than


4.2.3.3 逻辑运算符(和SV相同)

4.2.3.4 位运算符
(和SV相同,除了 左移 右移)
位运算符不能用负整数,perl会把负整数转化位无符号数
不同:左移: Perl:右边填0,左边不抛弃; SV:右边填0,左边 抛弃;
相同:右移: Perl:右边抛弃,左边填0; SV:右边抛弃,左边填0;



4.2.3.5 赋值运算符


 .
.
4.2.3.6 其他运算符




4.2.3.7 运算符的优先级和结合性

优先顺序: 自增 >> 乘幂 >> 赋值



实例

4.2.4 Perl 控制结构
4.2.4.1 控制结构 if and unless
if(条件)
条件是字符串时,一般都是真,只有字符串‘0’是假



4.2.4.2 控制结构 foreach and for
for

- next: 跳至本循环的结束位置,开始下一个循环
- last: 跳至循环的最后位置

解
use strict
use warnings
my @array = (1..50,55,51,61,54,82..99);
my $length_array = @array;
for (my $i = 0; $i < $length_array; $i++)
{
if($array[$i]<60){
printf"item $i, value is:$array[$i]\n";
next;
printf"this value is litter than 60\n";
}
else
{
printf"i is: $i, its value is:$array[$i], greatter than 60\n";
last;
}
}
$length_array = @array;


foreach: for 的变体
foreach 循环逐个遍历列表中的值,依次迭代
foreach 变量(列表)
{
执行语句;
}
注意:默认变量是 $_ , 如果不写自定义的变量,即为默认变量
$item就是自定义的变量
use strict;
use warnings;
my @array = (1,2,3..50,60,43,32,82..99);
foreach my $item (@array) ##每次从数组@array中的一个元素 赋值 给 变量$item
{
if ($item >60)
{
printf("$item\n");
}
$item = 150;
}
printf"write's result\n";
foreach my $item (@array) {
printf("$item\n");
}

看到结果
先输出 大于60的数组元素无序输出,
再输出 150,$item 每次都返回给@array,是因为把 @array的元素值都变成了150 么?
sort {$a <==> $b} @array; ##array都是数字
sort {$a cmp $b} @arry; ##array都是字母

4.2.4.3 控制结构 while、until、switch
1. while结构
while(条件)
{
执行语句;
}
三种方法控制循环:
对1-100求和
- 计数控制:
use strict;
use warnings;
my $count = 1;
my $sum = 0;
while ($count <= 100)
{
$sum += $count;
$count++;
}
printf("total count: $count\n");
printf("total sum: $sum\n");
- 特殊值控制:
use strict;
use warnings;
my $count = 1;
my $sum = 0;
while ($sum <= 5050)
{
$sum += $count;
$count++;
}
printf("total count: $count\n");
printf("total sum: $sum\n");
- 用户交互值控制: 通过显性的询问用户意见来判断是否执行程序
use strict;
use warnings;
my $count = 0;
my $sum = 0;
while ($count < 200)
{
$sum += $count;
$count++;
if($count >180)
{
printf("count is bigger than 180, will exit\n");
last;
printf("here is a flag\n");
}
}
printf("Final count is : $count\n");
printf("total sum is : $sum\n");

2. until结构
until (条件)
{执行语句; }
continue
{ 执行语句; }
注意: 条件为假时,执行语句,同时也会执行continue后的语句,否则跳出循环
use strict;
use warnings;
until(-e "test.txt") ##-e 意思是test.txt文件是否存在,如果存在返回值为真,
##不存在则会执行下列语句包括continue里的
{
printf("begin to sleep\n");
sleep(1);
}
continue
{
printf("waiting for update\n");
}
3. switch结构
Perl 不支持switch,Python支持,以后可能会出现Perl里;
switch(条件)
case条件值1:执行语句;
case条件值2:执行语句;
default: 执行语句;
4.2.4.4 控制结构 实例分析

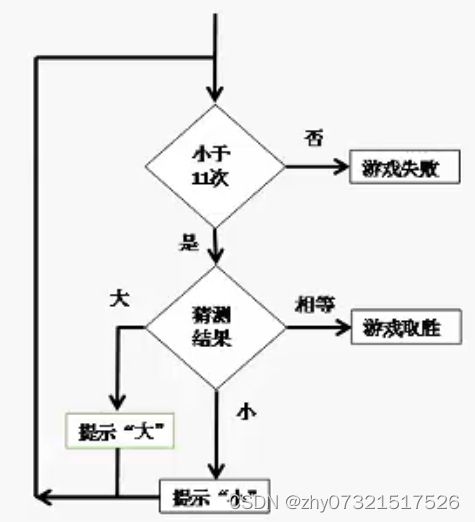
供参考
use strict;
use warnings;
my $count = 0;
my $guess_value = 0;
my $target_value = 88;
my @array = ();
while ($count<10)
{
printf"type the input:\n";
$guess_value = 4.2.5 子程序
4.2.5.1 定义子程序
子程序的定义是全局的;
若有两个重名的子程序,后面的那个子程序会覆盖掉前面的那个。
sub是关键字;marine 是子程序名(不包含与号),由数字、字母、_、组成,数字不能在最前面
sub marine {
$n += 1; #全局变量 $n
}
4.2.5.2 调用子程序
调用语法:&marine,
省略与号 : 子程序定义 写在前面, 调用 时写在后面, 或者内置函数,调用内置函数名时,也可省略&号。 如下:
若 自定义函数名 和 内置函数名 相同,如 chomp,必须使用 &, 才能调用自定义函数,绝不能省略, 否则将调用内置函数。
sub division{
$_[0] / $_[1];
}
my $quotient = division 355, 113; # 括号可写可不写
4.2.5.3 返回值(列表值和标量值都可)
每个子程序都有返回值,但不是所有的返回值都有效;
子程序的 最后执行的表达式结果 就是返回值,如果最后执行的是print,那么返回值是1; 最后执行的表达式结果 不是最后一行的意思!
非标量返回值, 不给任何参数
sub list_from_fred_to_barney{
if ($fred < $barney) {
# 从$fred数到$barney
$fred..$barney;
}else {
# 从$fred倒数回$barney
reverse $barney..$fred;
}
}
$fred = 11;
$barney = 6;
@c = &list_from_fred_to_barney; # @c 的值为 (11,10,9,8,7,6)
4.2.5.4 传入参数
在当前的子程序调用中, @_总是包含了它的参数列表; 每个子程序的@_都是独立的。
$n = &large_of_fred_or_barney(10,15,27); # $_[0] =10, $_[1] = 15,$_[2] = 27
现在10 就是$fred, 15 就是 $barney, 那么多余的27会被忽略,
如果参数少,则会得到 undef
sub large_of_fred_or_barney{
if ($fred > $barney) { $fred;}
else {$barney;}
}
利用 @_ 构造私有变量
sub max{
my($m, $n) = @_; #创建私有变量,并赋值
if ($m > $n) {$m} else {$n} #没错';'是可以省略的,只是隔绝语句,并不是结束符
}
变长参数列表
’高水线算法‘:
$maximum = &max(3,5,4,10,6);
sub max {
my($max_so_far) = shift @_; #把@_中的3移走赋值给私有变量 $max_so_far
foreach (@_) {
if(@_ > $max_so_far) {
$max_so_far = @_;
}
$max_so_far; # 这是给子程序max 的返回值
}
}
空参数列表
$maximum = &max(@numbers);
@numbers 也许是一个空列表,也许数组内容是程序从文件读入的,但文件时空的。
此时 &max 的返回值可能时undef
4.2.6 输入与输出
4.2.6.1 获取用户输入 标准输入 STDIN
让perl程序读取键盘输入的值: 使用 ”行输入“ 操作符
在标量上下文中 STDIN 会返回输入数据的下一行;
在列表上下文中 STDIN 会返回所有剩下的行,直到文件结尾为止。返回的每一行都会称为列表中的元素。
如果在列表里,如果是输入的文件,会读取文件的剩余部分; 如果输入源是键盘,那么如何发送文件结尾标记呢? 注意换行符也是输入的内容
linux里 control + D
windows control + Z
my $line = 4.2.6.2 钻石操作符的输入
在terminal 名两行写入, 命令行参数:
$ ./my_program fred barney betty
意思是:执行my_program命令(位于当前目录), 然后他会依次处理文件 fred 、barney、 betty;
也可以这样:从标准输入读取数据:
$ ./my_program fred-barney-betty
钻石操作符的输入 会处理所有的输入,一个程序中只出现一次;
<> 用来读取输入, 输入的内容可以在 $_中找到
它不是从用户键盘取得输入,而是 从用户指定的 fred、barney、 betty文件 读取
逐个文件,逐行读取。
正在处理的文件名会被保存在特殊变量$ARGV或@_ARGV中,如果当前是从标准输入获取数据,那么文件名就是“-”(连字符)
如果无法打开某个文件并读入内容,会有提示出现,并自动跳到下一个文件
while(defined($line = <>)){
chomp($line);
print "It was $line that I saw!\n";
}
上下效果相同,只是更节约按键
while(<>){
chomp;
print "It was $line that I saw!\n";
}
4.2.6.3 调用参数
在程序开始运行之后,只要尚未使用<>,就可以对@ARGV列表操作,改变处理三个特殊的文件,不管用户在命令行参数中指定了什么:
@ARGV = qw# larry moe curly #; #强制让钻石操作符只读取这三个文件
while(<>){
chomp;
print "It was $line that I saw!\n";
}
4.2.6.4 输出到标准输出
假如print 得调用看起来像函数调用,他就是一个函数调用;
@array = qw/fred bar bet/;
print @array; #得 fredbarbet
print "@array"; #得 fred
bar
bet
print "@array\n"; 通常加\n
print 2+3; # 5
print (2+3)*4; # 会输出5,它也做了5*4,但是会丢掉,因为你没告诉它接下来做什么
用printf 格式化输出
printf "%g %g %g\n", 5/2, 51/17, 51**17; # 2.5 3 1.0683e+29
%g : 以恰当的数字形式输出,如 浮点数、证书、指数;
%d :十进制整数,如果是小数,则会截断,而不是四舍五入
printf "%6d\n", 42; # ````42(`符号代表空格)
%d :字符串
printf "%10s\n", "wilma"; # `````wilma,
printf "%-15s\n", "flintstone"; # flintstone`````
%f : 按需要四舍五入,也可以指定小点数之后的输出位数:
printf "%12f\n", 6*7 +2/3; # ```42.666667
printf "%12.3f\n", 6*7 +2/3; # ``````42.667
printf "%12.0f\n", 6*7 +2/3; # ``````````43
%%: 会输出真正的 %
printf形式打印数组
my @items = qw( wilma dino pebbles);
my $format = "The items are:\n" . ("%10s\n" x @itmes); # . 连接字符串
## 打印 "the format is >>$format<<\n"; #用于调试
printf $format, @items;
文件句柄 filehandle, 就是Perl 进程与 外界之间的 I/O联系的名称。
这种联系的名称,不是文件的名称。
文件句柄 的名字,以字母、数字、下划线组成,不能以数字开头
避免与标签lable混淆,建议使用全大写字母命名
不能使用 Perl 的6 个保留字: STDIN STDOUT STDERR DATA ARGV ARGOUT;
**$ ./your_programwilma**
程序 输入来自文件dino,输出到文件wilma
$ cat fred barney | sort | ./your_program | grep something |lpr
在Unix命令里输入这个,意思: 由cat命令将文件fred 的每一行输出,再加上文件barney 里的每一行。 将以上输出作为sort命令的输入,对所有的行进行排序,将排序结果交给 your——program 处理,之后,再将输出数据送给grep,由它过滤掉数据中的某些行,并将剩下的数据输出到lpr这个命令,让它负责传给打印机打印出
$ netstat | ./your_program 2>/tmp/my_error
STDERR 标准错误流:将错误信息输出到指定文件或者某程序
4.2.6.5 打开文件句柄
- open CONFIG,‘dino’; open 操作符,为你的程序和外界文件加了一座桥梁,打开名为CONFIG的文件句柄,让它指向(已存在的)文件dino; 文件中的内容会从文件句柄CONFIG读到程序中去。 open 默认是 读取 文件内容
- open CONFIG,‘
- open BEDROCK, ‘>fred’; 大于号用来创建一个新的文件:打开文件句柄 BEDROCK 并输出到新文件 fred, 如果之前由fred文件,会清除原有的内容并以新内容取代;
- open LOG, ‘>>logfile’; 两个大于号以追加的方式打开,logfile由原有内容不动,在后边写入内容;如果没有该文件logfile,那么会创建该文件
- 可以用 标量表达式 代替 文件名:
my $selected_output = 'my_output'; open LOG, "> $selected_output";注意 大于号 后有 空格;如果没有空格,会以替换的方式写入到该文件 - 三种参数形式 这样写更安全
open CONFIG, '<', 'dino';
open BEDROCK, '>', $file_name;
open LOG, '>>', $logfile_name();
如果要读取的文件是UTF-8编码的
open CONFIG, ', 'dino';
open BEDROCK, '>:encoding(UTF-8)', $file_name;
open LOG, '>>encoding(UTF-8)', $logfile_name();
使用 下边的命令 打印出 所有perl 能理解和处理的字符编码清单:
% perl -MEncode -le "print for Encode->encodings(':all')"
windows 这样使每行 都以 换行符 结尾
open BEDROCK, '>:crlf', $file_name;读
open BEDROCK, '>:crlf', $file_name;写
以二进制方式读写文件句柄
当某个二进制文件中恰好有一段字节顺序和换行符的内码相同,用binmode关闭换行符:命令行如下:
binmode STDIN, ':encoding(UTF-8)'; STDOUT STDERR,相同
有问题的文件句柄
Perl 无法打开系统文件,如果读取或者写入有问题的文件句柄,会有警告信息;
也可以这样写程序:
my $success = open LOG, '>>', 'logfile'; # 捕获返回值
if (! $success){
...
}
关闭文件句柄 释放有限资源
close BEDROCK; open close 成对出现
让Perl 通知操作系统,请系统将尚未写入的输出数据写到磁盘,以免有人等着使用。
重新打开文件句柄时,会自动关闭原先的文件句柄。
用die处理致命错误 (如内存不足,收到意外信号,会有die;但是除以0不致命)
用 die 函数 实现:当Perl遇到致命性错误,你的程序应该立刻中止运行,并发出错误信息。
use autodie;
open LOG, '>>', 'logfile'; # 记得关注 open file的返回值
autodie 源代码:详细解释见 Perl 语言入门, P108
if (! open LOG, '>>', 'logfile') {
die "Cannot create logfile: $!"
} # linux用$!; windows 用 $^E;
用warn送出警告信息,
相比 die 函数, warn 函数不会 终止程序的运行。
使用文件句柄
以读取模式打开文件句柄:
if (! open PASSWD, "/etc/passwd") {
die "How did you get logged in? ($!)";
}
while (改变默认的文件输出句柄 select 操作符
默认情况: 如果你不为print 指定文件,则输出会送到STDOUT。
把默认输出改成BEDROCK这个文件句柄:
select BEDROCK; # 先选择BEDROCK 文件输出
$| = 1; # 但不要将BEDROCK 的内容保留在缓冲区,即立刻显示BEDROCK的内容
select STDOUT; # 等输出完毕后, 再转换输出到标准输出流,不影响其他程序的输出
print BEDROCK "I hope Mr. Slate doesn't find out about this.\n";
重新打开标准文件句柄
if (! open STDERR, ">>/home/barney/.error_log") {
die "Cannot oppen error log for append: $!";
}
即使这样写了,但是如果无法打开error_log文件,那么错误信息会流入哪里?
如果打开STDIN、STDOUT、STDERR失败时,Perl 会找到原先的文件句柄。即流向了原先的句柄。只由打开成功STDERR时,原先的文件句柄才会关闭,否则不会。
用say来输出
和print 差不多,但在每行内容打印时,会自动加上换行符。
当需要末尾附带换行符,不额外构造字符串,不给print 函数提供数据列表,用say。
print "Hello!\n";
say "Hello!";
变量:
my $name = 'fred';
print "$name\n";
print $name, "\n";
say $name;
内插数组,需要引号,以便空格隔开数组中的每个元素:
my @array = qw( a b c d);
say @array; # "abcd\n"
say "@array"; # "a b c d\n"
类似print 函数, 可以为say 指定一个文件句柄:
say BEDROCK "Hello!"
标量变量中的文件句柄
习惯以_fh表示 这是保存文件句柄的变量;
my $rocks_fh;
open $rocks_fh, '<', 'rocks.txt'
or die "Could not open rocks.txt: $!";
while( <$rocks_fh> ) {
chomp;
....
}
open my $rocks_fh, '<', 'rocks.txt'
or die "Could not open rocks.txt: $!";
foreach my $rock ( qw( slate lava gran ) ) {
say $rocks_fh $rock;
}
print $rocks_fh "limestone\n"; 这里不需要逗号
close $rocks_fh;
print STDOUT; 正确
print $rock_fh; 错误
print { $rock_fh }; #默认打印$_中的内容
print { $rock[0] } "sandstone\n"; 正确
4.2.7 哈希
4.2.7.1 哈希的简介
哈希 是一种数据结构,和数组类似,不同的是数组以数字索引,而哈希以任意唯一的字符串,称之为哈希的键 (key)。
哈希是一堆数据,没有顺序
原因: 总是需要将一组数据(键) “对应到” 另一组数据(值)
找出重复, 唯一, 交叉引用,查表,则要联想到 哈希;
4.2.7.2 访问哈希元素
赋值给哈希元素,再访问;
哈希表里不存在的值 会 返回 undef
语法:
$hash{$some_key}
key的表达式是字符串, 对哈希键赋值:
$family_name{'fred'} = 'flintstone';
$family_name{'barney'} = 'rubble';
$foo = 'bar';
print $family_name{ $foo . 'ney'}; # "rubble"
$family_name{'fred'} = 'astaire'; # 给已有的元素赋上新值
$bedrock = $family_name{'fred'}; # 得到 astaire
$family_name{'betty'} .= $family_name{'barney'}; # 在需要的时候动态创建该元素
4.2.7.3 访问整个哈希 %
%family_name #访问整个哈希
对哈希赋值:
%some_hash = ( 'foo',35, 'bar',12.4, 2.5, 'hello','wilma', 1.72e30, 'betty',"bye\n"); # 键-值对列表
@any_array = %some_hash; # 展开unwinding 哈希
print "@any_array\n"; # 不一定按照当初赋值时的顺序展开,
4.2.7.3 哈希赋值
my %new_hash = %old_hash;
my %inverse_hash = reverse %any_hash; # 反序的hash,只是 键 和 值 互换了 最后的键 会覆盖掉 之前的键;最好是在键和值 一 一的对应的情况下使用。
哈希赋值,** my 声明的必须是独立变量,不能声明哈希或数组里的元素:**
my %any_hash = (
....
)
my $v = $any_hash{4.2.7.4 旁箭头(=>)
对Perl来说,这就是逗号。
my %last_name = (
'fred' => 'flintstone',
'dino' => undef,
'betty' => 'rubble',
);
my %last_name = (
fred => 'flintstone',
dino => undef,
betty => 'rubble',
); # 可以省略键的引号, 这种称为裸字 bareword
省略键的引号:
$hash{ bar.foo} = 1; # 构成键名 ‘barfoo’
4.2.7.5 哈希函数
4.2.7.5.1 keys 和 values 函数
my %hash = ('a' => 1, 'b' => 2, 'c' => 3);
my @k = keys %hash; keys 函数能返回 键列表
my @v = values %hash; values 函数能返回 键列表 @ K 对应的值列表 @v
如果hash 没有,返回空列表
my $count = keys %hash; 得到3, 就是有三队键值
%hash 至少有一个键-值对,则 :
if(%hash) {..} %hash 为真
4.2.7.5.2 each 函数
如果想逐项处理其中的每一个元素(迭代)整个hash, 用each 函数,返回 包含两个元素的列表,即返回键-值对。
实际适合each函数的只有在while循环, while 内部时布尔上下文,内部只要有值。
while(($key, $value) = each %hash) {
print "$key => $value\n";
} 返回的列表("c",3)
每个哈希,都有个迭代器iterator, 会记着上次返回的位置:
foreach $key (sort keys %hash) { 先keys函数,返回key列表,再给列表排序
$value = $hash[$key];
print "$key => $value\n";
}
4.2.7.5.3 哈希的典型应用
判断某项 哈希元素 的真假 很简单,只要这么做:
if($books{$someone}) {
print "$someone has at least one book checked out.\n";
}
$books{"barney"} = 0; # 现在没有借阅图书
$books{"pebbles"} = undef; # 从未借阅过图书,这是新办的借书证
exists 函数
检查哈希中是否存在某个键(即借书证),可以使用exists函数,返回真或假,分别表示键存在与否,与值无关;
if (exists $books{"dino"}) {
print "Hey, there's a librabry card for dino!\n";
}
delete 函数
删除哈希中的指定键和对应的值,如果没有该键,会结束,不会有警告信息
my $person = "betty";
delete $books{$person}; # 撤销$person的借书证
哈希元素内插到双引号的字符串中
不支持整个哈希内插,
foreach $person (sort keys %books) { #按次序访问每位借阅者
if ($books[$person]) {
print "$person has $books[$person] items\n"; # fred 借了 3 本书
}
}
%ENV哈希
Perl 感知环境变量,就是访问 %ENV哈希,从%ENV中读取PATH键的值:
print "PATH is $ENV{PATH}\n";
shell设置环境变量:
$ CHARACTER = Fred; export CHARACTER
$ export CHARACTER = Fred
csh设置环境变量:
% setenv CHARACTER Fred
windows设置环境变量:
C:> set CHARACTER=Fred
Perl里面这样访问环境变量:
print "CHARACTER is $ENV{CHARACTER}\n";
4.2.8 正则表达式 regular expression
4.2.8.1 简介
学习资料:网站 stackflow
https://stackoverflow.com/questions/22937618/reference-what-does-this-regex-mean/22944075#22944075
在Perl 里也叫模式 pattern,用来匹配某个字符串的特征模板。
任务就是 查看一个字符串,判定它是否匹配。
4.2.8.1.1 简单模式
$_ = "yabba dabba doo";
if(/abba/) {
print "It matched\n";
}
表达式 /abba/ 会在 $_ 里寻找, 返回真假;
这里/ / 的换行符或者制表符等,凡是可以在 双引号 中使用的,
都可以在/ / 这里识别那些换行符或者制表符等
4.2.8.1.2 Unicode 属性
如果想匹配某项属性,放入\p{property}里面;
空白符 Space, 数字属性 Digit,连续两个十六进制数字的字符 用\p{Hex}\p{Hex}
匹配:用小写p
if(/\p{Space}/) { # 总共有26个不同的字符带空白符
print "The string has some whitespace.\n";
}
不匹配:用大写P
if(/\P{Space}/) { # 总共有26个不同的字符带空白符
print "The string has some whitespace.\n";
}
4.2.8.1.3 元字符 metacharacter

.是元字符中最简单的例子。 .匹配任意单个字符,但不匹配换行符。 例如,表达式.ar匹配一个任意字符后面跟着是a和r的字符串。
".ar" => The car parked in the garage. #匹配到 car par gar
字符集也叫做字符类。 方括号用来指定一个字符集。 在方括号中使用连字符来指定字符集的范围。 在方括号中的字符集不关心顺序。 例如,表达式[Tt]he 匹配 the 和 The。
"[Tt]he" => The car parked in the garage. #匹配到 The the
方括号的句号就表示句号。 表达式 ar[.] 匹配 ar.字符串
"ar[.]" => A garage is a good place to park a car. #匹配到ar.
一般来说 ^ 表示一个字符串的开头,但它用在一个方括号的开头的时候,它表示这个字符集是否定的。 例如,表达式[^c]ar 匹配一个后面跟着ar的除了c的任意字符。
"[^c]ar" => The car parked in the garage.#匹配到 par gar
*号匹配 在*之前的字符出现大于等于0次。 例如,表达式 a* 匹配0或更多个以a开头的字符。表达式[a-z]* 匹配一个行中所有以小写字母开头的字符串。
"[a-z]*" => The car parked in the garage #21. #匹配到 he car parked in the garage
*字符和.字符搭配可以匹配所有的字符.*。 *和表示匹配空格的符号\s连起来用,如表达式\s*cat\s*匹配0或更多个空格开头和0或更多个空格结尾的cat字符串。
"\s*cat\s*" => The fat cat sat on the concatenation. #匹配到 cat concatenation中的cat
+号匹配+号之前的字符出现 >=1 次。 例如表达式c.+t 匹配以首字母c开头以t结尾,中间跟着至少一个字符的字符串。
"c.+t" => The fat cat sat on the mat. #匹配到 cat sat on the mat
在正则表达式中元字符 ? 标记在符号前面的字符为可选,即出现 0 或 1 次。 例如,表达式 [T]?he 匹配字符串 he 和 The。
"[T]?he" => The car is parked in the garage. #匹配到 he 和 The
在正则表达式中 {} 是一个量词,常用来限定一个或一组字符可以重复出现的次数。 例如, 表达式 [0-9]{2,3} 匹配最少 2 位最多 3 位 0~9 的数字
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0. #匹配到 999 10
我们可以省略第二个参数。 例如,[0-9]{2,} 匹配至少两位 0~9 的数字。
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0. #匹配到 9997 10
如果逗号也省略掉则表示重复固定的次数。 例如,[0-9]{3} 匹配3位数字
"[0-9]{3}" => The number was 9.9997 but we rounded it off to 10.0. #匹配到 999
4.2.8.1.3 (…) 特征标群
特征标群是一组写在 (…) 中的子模式。(…) 中包含的内容将会被看成一个整体,和数学中小括号( )的作用相同。例如, 表达式 (ab)* 匹配连续出现 0 或更多个 ab。如果没有使用 (…) ,那么表达式 ab* 将匹配连续出现 0 或更多个 b 。再比如之前说的 {} 是用来表示前面一个字符出现指定次数。但如果在 {} 前加上特征标群 (…) 则表示整个标群内的字符重复 N 次。
我们还可以在 () 中用或字符 | 表示或。例如,(c|g|p)ar 匹配 car 或 gar 或 par.
"(c|g|p)ar" => The car is parked in the garage. #匹配到 car par gar
4.2.8.1.3 | 或运算符
例如 (T|t)he|car 匹配 (T|t)he 或 car。
"(T|t)he|car" => The car is parked in the garage. #匹配到 The car the
4.2.8.1.3 转码特殊字符
反斜线 \ 在表达式中用于转码紧跟其后的字符。用于指定 { } [ ] / \ + * . $ ^ | ? 这些特殊字符。如果想要匹配这些特殊字符则要在其前面加上反斜线 \。
例如 . 是用来匹配除换行符外的所有字符的。如果想要匹配句子中的 . 则要写成 \. 以下这个例子 \.?是选择性匹配.
"(f|c|m)at\.?" => The fat cat sat on the mat. #匹配到 fat cat mat.
4.2.8.1.3 锚点
在正则表达式中,想要匹配指定开头或结尾的字符串就要使用到锚点。^ 指定开头,$ 指定结尾。
4.2.8.1.3 ^ 号
^ 用来检查匹配的字符串是否在所匹配字符串的开头。
例如,在 abc 中使用表达式 ^a 会得到结果 a。但如果使用 ^b 将匹配不到任何结果。因为在字符串 abc 中并不是以 b 开头。
例如,^(T|t)he 匹配以 The 或 the 开头的字符串。
"(T|t)he" => The car is parked in the garage. #匹配到 The the
"^(T|t)he" => The car is parked in the garage. #匹配到 The
4.2.8.1.3 $ 号
同理于 ^ 号,$ 号用来匹配字符是否是最后一个。
例如,(at\.)$ 匹配以 at. 结尾的字符串。
"(at\.)" => The fat cat. sat. on the mat. #匹配到 cat. sat. mat. 中的at.
"(at\.)$" => The fat cat. sat. on the mat. #匹配到 mat.中的 at.
简写字符集

零宽度断言(前后预查)
先行断言和后发断言(合称 lookaround)都属于非捕获组(用于匹配模式,但不包括在匹配列表中)。当我们需要一个模式的前面或后面有另一个特定的模式时,就可以使用它们。
例如,我们希望从下面的输入字符串 $4.44 和 $10.88 中获得所有以 $ 字符开头的数字,我们将使用以下的正则表达式 (?<=$)[0-9.]*。意思是:获取所有包含 . 并且前面是 $ 的数字。

?=… 正先行断言
?=… 正先行断言 表示第一部分表达式之后必须跟着 ?=…定义的表达式。
返回结果只包含满足匹配条件的第一部分表达式。 定义一个正先行断言要使用 ()。在括号内部使用一个问号和等号: (?=...)。
正先行断言的内容写在括号中的等号后面。 例如,表达式 (T|t)he(?=\sfat) 匹配 The 和 the,在括号中我们又定义了正先行断言 (?=\sfat) ,即 The 和 the 后面紧跟着 (空格)fat。
"(T|t)he(?=\sfat)" => The fat cat sat on the mat. #匹配到 The
?!.. 负先行断言
负先行断言 ?! 用于筛选所有匹配结果,筛选条件为 其后不跟随着断言中定义的格式。
正先行断言 定义和 负先行断言 一样,区别就是 = 替换成 ! 也就是 (?!...)。
表达式 (T|t)he(?!\sfat) 匹配 The 和 the,且其后不跟着 (空格)fat。
"(T|t)he(?!\sfat)" => The fat cat sat on the mat. #匹配到 the
?<= … 正后发断言
正后发断言 记作(?<=…) 用于筛选所有匹配结果,筛选条件为 其前跟随着断言中定义的格式。
例如,表达式 (?<=(T|t)he\s)(fat|mat) 匹配 fat 和 mat,且其前跟着 The 或 the。
"(?<=(T|t)he\s)(fat|mat)" => The fat cat sat on the mat. #匹配到fat mat
? 标志也叫模式修正符,因为它可以用来修改表达式的搜索结果。 这些标志可以任意的组合使用,它也是整个正则表达式的一部分。 全局搜索 (Global search) 多行修饰符 (Multiline) 正则表达式默认采用贪婪匹配模式,在该模式下意味着会匹配尽可能长的子串。我们可以使用 ? 将贪婪匹配模式转化为惰性匹配模式。 点号(.) 是能匹配任意 一个字符的通配符,除换行符 简单的量词 星号(*) 是量词 组合 星号和点号 (.*) 如/fred.*barney/, 任何一行出现了fred, 并在其后提到barney,就会匹配此模式 加号(+) 也是量词, 会匹配前一个条目 一次以上: 如/fred+barney/ 匹配在 fred 与 barney 之间用一个空格及以上隔开 而且只用空格隔开的字符串(空格不是元字符) 问号(?) 也是量词,表示 前一个条目可以出现一次或者不出现 :/bamm-?bamm/ 匹配到两种情况: bamm-bamm ,bamm-bamm, 圆括号() 的作用是对字符串分组, 捕获组:反向引用来引用圆括号中的模式 所匹配的文字,这个行为,称为 反向引用 \1、\2, (.)\1 表示需要匹配 连续出现的两个同样的字符, -命令行模式( C:> ) 进入命令提示符 用 win+R 输入cmd 0.0打开DVE界面, dve -full64 & Terminal: The APB watchdog module is a 32-bit down-counter 代码如下(示例): 代码如下(示例): 该处使用的url网络请求的数据。 例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
负后发断言 记作 (?
"(? => The cat sat on cat. #匹配到on后边的 cat
标志

忽略大小写 (Case Insensitive)修饰语 i 用于忽略大小写。 例如,表达式 /The/gi 表示在全局搜索 The,在后面的 i 将其条件修改为忽略大小写,则变成搜索 the 和 The,g 表示全局搜索。
"The" => The fat cat sat on the mat. #匹配到The
"/The/gi" => The fat cat sat on the mat. #匹配到The the
修饰符 g 常用于执行一个全局搜索匹配,即(不仅仅返回第一个匹配的,而是返回全部)。 例如,表达式 /.(at)/g 表示搜索 任意字符(除了换行)+ at,并返回全部结果。
"/.(at) /" => The fat cat sat on the mat. #匹配到 fat
"/.(at)/g" => The fat cat sat on the mat. #匹配到 fat cat sat mat
多行修饰符 m 常用于执行一个多行匹配。
像之前介绍的 (^,$) 用于检查格式是否是在待检测字符串的开头或结尾。但我们如果想要它在每行的开头和结尾生效,我们需要用到多行修饰符 m。
例如,表达式 /at(.)?$/gm 表示小写字符 a 后跟小写字符 t ,末尾可选除换行符外任意字符。根据 m 修饰符,现在表达式匹配每行的结尾。
"/.at(.)?$/" => The fat
cat sat
on the mat. #匹配到 mat.
"/.at(.)?$/gm" => The fat
cat sat
on the mat. #匹配到 fat sat mat.
贪婪匹配与惰性匹配 (Greedy vs lazy matching)
"/(.*at)/" => The fat cat sat on the mat. #匹配到 The fat cat sat on the mat
"/(.*?at)/" => The fat cat sat on the mat. #匹配到 The fat
不想被通配到,在 点号 前加反斜线, 如/3 .14159/
若要匹配真的反斜线,用两个反斜线即可,如 /\/
星号()可以匹配前边的条目 0次或者多次,如 /fred\tbarney/ 匹配的是制表符\t 0个或多个4.2.8.1.4 模式分组
/fred+/ 匹配: fredddddddddd
/(fred)+/ 匹配: fredfredfredfredfredfredfredfred
/(fred)*/ 匹配: 任意一个 字符串 如 hello world $_ = "abba";
if(/(.)\1/) { #匹配'bb'
print "It matched same character next to itself!\n";
}
$_ = "yabba dabba doo";
if(/y(....) d\1/) { 表示 y后面的4个连续的非换行符,并用\1 反向引用 表示 匹配d后也出现这4个字符的情况
print "It matched the same after y and d!\n";
}
$_ = "yabba dabba doo";
if(/y(.)(.)\2\1/) { 匹配 'abba' 回文模式
print "It matched the same after y and d!\n";
}
$_ = "yabba dabba doo";
if(/y((.)(.)\3\2) d\1/) { 匹配 ''
print "It matched!\n";
}
$_ = "aa11bb";
if (/(.)\g{1}11/) {
print "It matched!\n";
}
$_ = "aa11bb";
if (/(.)(.)\g{-1}11/) { 使用相对位置
print "It matched!\n";
}
4.2.8.2 简介
4.3 C语言
4.4 DPI
4.5 Python
4.5.1 pyhon解释器
4.5.2 pyhon 基础
可执行python进入python交互模式,也可以执行python hello.py运行一个.py文件,执行一个.py文件只能在命令行模式执行。
-Python交互模式( >>> )
python交互模式的代码是输入一行,执行一行,而命令行模式下直接运行.py文件,是一次性执行该文件内的所有代码。
4.6 Vim 编辑器

4.7 VCS 简单 操作
0. start: makefile: make elab TB=** TESTNAME = ** &
make rung GUI=1 TB=** TESTNAME = mcdf_full_random_test &
vcs -full64 -sverilog **.sv
3.1在命令窗口:do ./文件名字 即可打开之前报存过的图形界面
4.0 保存wave图形界面: file->save current view->debug_wave.do文件->4.8 linux 简单 操作
0. rm -rf ** 删除文件
4.9 Questa 简单 操作
1.compile: vlog -sv ./mcdf/v1/{设计文件} volg -sv chnl_pkg3_ref.sv tb3_ref.sv
vsim -voptargs+=acc +(UVM_)TESTNAME=chnl_basic_test -classdebug -gui work.tb3_ref -sv_seed 0 or random
7.quit -sim4.10 DVT 简单操作
添加参数或端口,敏感列表,引用检查,实现个更新外部方法(extern method),remove local,protected,
3.1 ctrl + 单词, 可快速查找该词 的父类或者子类
3.2 单词 右键,可refactor,可以重构 extern 的切换; add port or parameter
也可 code template 处 拖拽
(很重要)**项目模板: project 空白处 右键new -> DVT project from Template
设置好,可在project中选中文件,右键+formatting sourcefile
6.2单词 右键->show->layers, 可出现被覆盖方法的整个实现层次
6.3 单词 F4 ,看 type heirachi,可在类型窗口中使能所有已继承的成员 即 Type View -> show All inherited Mebers,选择其继承的某个方法,再右键选择override
或者 单词 右键->source->Override Methods弹出对话框,选择要覆盖的多个方法
7.使用跟踪 usage trace : 对于一个类、模块、接口、变量、方法,在那些地方被调用,
7.1 单词 右键 Show->Usages,在DVT下方窗口中显示该目标被使用的地方。
7.2. 跟踪 constraint: 单词 右键 Show->constraint,在DVT下方窗口中显示该目标被使用的地方。
7.3. ctrl+H 搜索 keyword
7.4 在design hierarchy窗口中,端口 右键,“trace Driver and Load”
10.类UML 图: Types -> ubus_env 右键-> show digram or 10.2验证结构UML 图:UVM Types -> ubus_env 右键-> show digram or 10.3树状图uvm_sequence_tree;
12.状态机图:FSM:先找到状态机, 右键 show ->digram
14.生成HTML文档:菜单栏有一个按钮 generate HTML doc,
15.UVM check看自己的错误code 建议: 菜单栏 绿色对勾->lint with->1 System verilog UVM Compliance Rules
UVM->search for Factory Override or
15.2 域的编辑:单词 右键->Source-> UVM Field Editor
16 +
dvt_init_auto+questa.vlog //兼容questa指令(external builder),
-O0 //不要优化代码
-novopt //不要优化代码
+incdir+…/mcdf/v0
…/mcdf/v0/arbiter.v
…/mcdf/v0/formater.v
…/mcdf/v0/slave_fifo.v
…/mcdf/v0/reg.v
…/mcdf/v0/mcdf.v
rpt_pkg.sv
reg_pkg.sv
arb_pkg.sv
chnl1_pkg.sv
fmt_pkg.sv
mcdf_pkg.sv
tb.sv第五章、 APB-Watchdog 项目
5.1 what and applied
Applied: The watchdog module applies a reset to a system in the event of a software failure, providing a
way to recover from software crashes. You can enable or disable the watchdog unit as required.5.2 much register control this module




二、使用步骤
1.引入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
总结
提示:这里对文章进行总结: