从新认识redis总结
本文是看完黑马的redis课程后,个人整理的笔记。
redis特征
- 键值(key-value)型,value支持多种不同数据结构,功能丰富。
- 单线程,每个命令具备原子性。
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)。
- 支持数据持久化、支持主从集群、分片集群支持多语言客户端。
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)。
- 支持数据持久化 支持主从集群、分片集群 支持多语言客户端。
redis 安装
https://blog.csdn.net/lwang_IT/article/details/125635580
redis图形化桌面客户端
安装包下载地址:
Releases · lework/RedisDesktopManager-Windows · GitHub
软件界面:

Redis通用命令
KEYS:查看符合模板的所有key
local redis:1>keys *
1) "name"
2) "sex"
3) "age"
local redis:1>keys nam*
1) "name"DEL:删除一个指定的key
local redis:1>del name
"1"EXISTS:判断key是否存在
local redis:1>exists name
"1"EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
TTL:查看一个KEY的剩余有效期
redis 数据结构及场景介绍
更详细的使用 ️ Redis 命令 | 菜鸟教程
String类型
特点:
String类型,也就是字符串类型,是Redis中最简单的存储类型。
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
- string:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
使用场景:分布式锁和需要计数的场景(用户的访问次数、热点文章的点赞转发数量等)。
LIST类型
特点:Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
使用场景:队列等。
Hash类型
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:
| key | value |
| user:1 | {name:"Jack", age:19} |
| user:2 | {name:"Rose", age:21} |
Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:
| key | value | |
| field | value | |
| user:1 | name | Jack |
| age | 19 | |
| user:2 | name | Rose |
| age | 21 | |
Set类型
特点:无序,元素不可重复,查找快,支持交集、并集、差集等功能
使用场景:需要存放的数据不能重复以及需要获取多个数据源交集和并集等场景,共同喜爱,共同粉丝等场景。
SortedSet类型
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
特点:
可排序,元素不重复,查询速度快
使用场景:一些热点话题(文章被用户的访问量),排行榜等
Bitmaps类型
Bitmaps底层存储的是一种二进制格式的数据。在一些特定场景下,用该类型能够极大的减少存储空间,因为存储的数据只能是0和1。
使用场景:签到统计等。
GEO 类型
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作。
使用场景:附近位置等依赖于地理位置信息的功能。
RedisTemplate
在开发当中我们一般使用RedisTemplate类来进行redis的相关操作。
引入依赖:
org.springframework.boot
spring-boot-starter-data-redis
org.apache.commons
commons-pool2
RedisTemplate封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中。
| API |
返回值类型 |
说明 |
| redisTemplate.opsForValue() |
ValueOperations |
操作String类型数据 |
| redisTemplate.opsForHash() |
HashOperations |
操作Hash类型数据 |
| redisTemplate.opsForList() |
ListOperations |
操作List类型数据 |
| redisTemplate.opsForSet() |
SetOperations |
操作Set类型数据 |
| redisTemplate.opsForZSet() |
ZSetOperations |
操作SortedSet类型数据 |
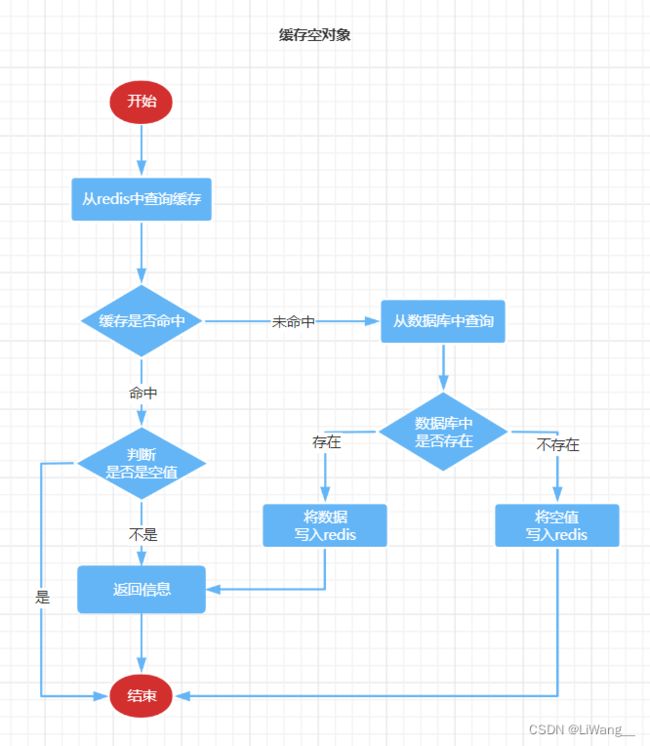
缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库,给数据库带来巨大压力。
常见的解决方案有两种:
- 缓存空对象
- 布隆过滤
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值,防止大量的key在同时失效。
- 利用Redis集群提高服务的可用性。
- 给缓存业务添加降级限流策略。
缓存击透
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
互斥锁
优点:保证了缓存数据一致性;
缺点:线程需要等待获取锁,在高并发的环境下,激烈的锁竞争会导致程序的性能下降。
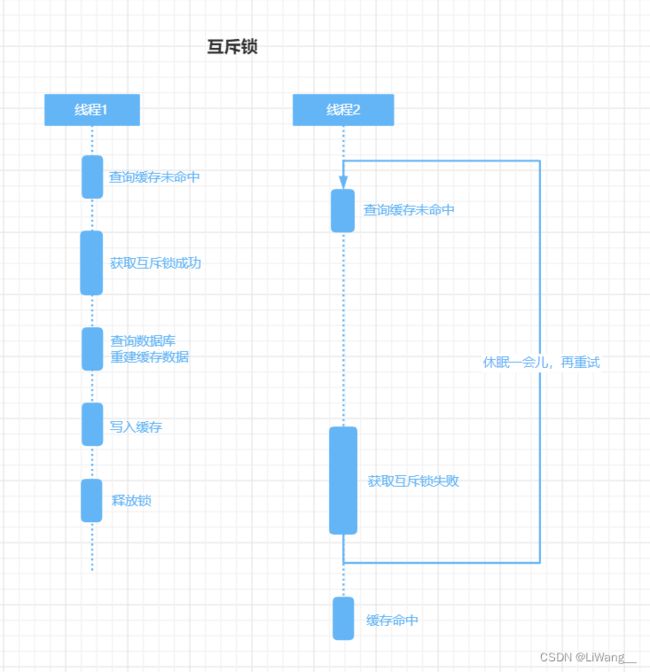
多个线程同时去查询缓存,当缓存中没有命中的时候,先获取互斥锁。只有获取到锁的请求才能重建缓存数据,防止多个线程同时去重建一个要经过复杂的查询、计算才能得到的缓存值。
逻辑过期
优点:线程无需等待。但是有可能返回过期数据,导致缓存数据一致性问题。

缓存中的值,由一个实际的数据和一个逻辑过期时间组成:
@Data
public class RedisData {
private LocalDateTime expireTime;
private Object data;
}
每次获取到缓存中的值后,判断expireTime是否过期,如果已过期则尝试获取互斥锁,重建缓存数据、写入缓存并重置缓存过期时间;
redis秒杀
秒杀逻辑:
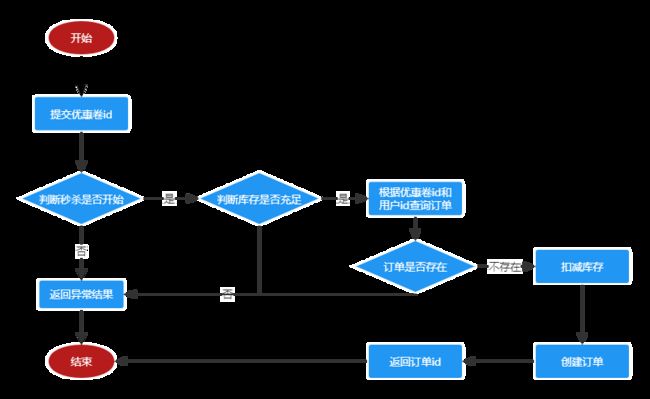
单体架构解决一人一单问题
在秒杀场景中,我们要限制每个用户只能抢到一个名额。
可以使用给用户id加synchronized锁的方式:
//秒杀用户
String userId=***;
//intern()方法:首先检查字符串常量池中是否有该对象的引用,如果存在,则将这个引用返回给变量,否则将引用加入并返回给变量。
//保证了相同userId的用户,不会同时执行抢优惠卷逻辑
synchronized(userId.intern()){
...
判断用户是否秒杀成功过
减库存
...
}单体架构解决超卖问题:
超卖指得是,库存为100,同一时刻有大量的用户同时抢优惠卷,本来库存为100,却卖出了超过100的数量。
在减少库存的时候我们可以,利用CAS去判断:
- 先查询stock(库存)数量为count;
- 然后修改库存的时候减一,同时判断库存数量是否等于原来的库存(set stock=count-1 where stock=count)。
但是这种情况下会存在,抢单不均匀问题:
比如当前库存为50,有100个用户同时请求,很多请求并发查询某一时刻的库存都为100。当一个用户抢成功了,此时库存减去1为99。其他的用户请求修改库存就会失败,因为此时数据库中的库存为99,而其他请求查询出的为库存数量仍为100,CAS修改数据库就会失败。但是此时的库存是大于0的,理论上只要库存大于0,优惠卷应该要顺序发放给抢的用户的。
解决办法:
在修改库存的时候,判断库存大于0就可以抢单成功。
update seckillVoucher set stock=stock-1 where stock>0分布式系统或集群模式下秒杀问题
在分布式系统或集群模式下,超卖和一人一单问题就变得更加复杂了,就要使用分布式锁来解决这些问题,先了解下基于redis实现的Redisson框架吧。
Redisson
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
可重入锁(Reentrant Lock)、公平锁(Fair Lock)、联锁(MultiLock)、红锁(RedLock)、读写锁(ReadWriteLock)、信号量(Semaphore)、可过期性信号量(PermitExpirableSemaphore)、闭锁(CountDownLatch)
中文文档地址:目录 · redisson/redisson Wiki · GitHub
Redisson小案例
编写一个配置类:
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.0.142:6379").setPassword("123");
// 创建RedissonClient对象
return Redisson.create(config);
}
}使用junit测试可重入锁:
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
@Slf4j
@SpringBootTest
class RedissonTest {
@Resource
private RedissonClient redissonClient;
private RLock lock;
@BeforeEach
void setUp() {
lock = redissonClient.getLock("anyLock");
}
@Test
void lock1() throws InterruptedException {
// 加锁以后10秒钟自动解锁
boolean isLock = lock.tryLock(10L, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
// boolean isLock = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (!isLock) {
log.error("获取锁失败 .... 1");
return;
}
try {
log.info("获取锁成功 .... 1");
lock2();
log.info("开始执行业务 ... 1");
} finally {
log.warn("准备释放锁 .... 1");
lock.unlock();
}
}
void lock2() {
// 尝试获取锁
boolean isLock = lock.tryLock();
if (!isLock) {
log.error("获取锁失败 .... 2");
return;
}
try {
log.info("获取锁成功 .... 2");
log.info("开始执行业务 ... 2");
} finally {
log.warn("准备释放锁 .... 2");
lock.unlock();
}
}
}运行:
29:58.246 INFO 52968 --- [ main] com.hmdp.RedissonTest : 获取锁成功 .... 1
29:58.249 INFO 52968 --- [ main] com.hmdp.RedissonTest : 获取锁成功 .... 2
29:58.249 INFO 52968 --- [ main] com.hmdp.RedissonTest : 开始执行业务 ... 2
29:58.249 WARN 52968 --- [ main] com.hmdp.RedissonTest : 准备释放锁 .... 2
29:58.251 INFO 52968 --- [ main] com.hmdp.RedissonTest : 开始执行业务 ... 1
29:58.252 WARN 52968 --- [ main] com.hmdp.RedissonTest : 准备释放锁 .... 1
通过运行输出的结果,我们看到锁被获取成功了两次,释放了两次。
通过debug查看锁的被占用情况

当执行到第一个断点的时候,value为1,代表重入了一次

当执行到第二个断点的时候,value为2,代表又重入了一次

源码解析
- RLock lock=redissonClient.getLock("anyLock");
创建一个名称为anyLeck的锁。
getLock方法会调用Redisson的实现,返回一个RedissonLock实例
public class Redisson implements RedissonClient {
...
public RLock getLock(String name) {
return new RedissonLock(this.commandExecutor, name);
}
...
}- boolean isLock = lock.tryLock(10L, TimeUnit.SECONDS);
tryLock尝试获取锁
参数:waitTime为最多等待时间,unit为waitTime的单位(TimeUnit.SECONDS代表秒)。
@Override
public boolean tryLock(long waitTime, TimeUnit unit) throws InterruptedException {
return tryLock(waitTime, -1, unit);
}参数:leaseTime为上锁的时间
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
//转化为毫秒
long time = unit.toMillis(waitTime);
//获取当前的时间(毫秒)
long current = System.currentTimeMillis();
//当前的线程id
long threadId = Thread.currentThread().getId();
//尝试获取锁
Long ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
// 为null,代表加锁成功
if (ttl == null) {
return true;
}
// System.currentTimeMillis() - current :计算tryAcquire(尝试获取锁)这个方法所耗的时间
// 用等待时间减去获取锁的耗时,如果小于0代表,已经获取锁超时了
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
//更新当前时间
current = System.currentTimeMillis();
// 订阅锁释放事件
CompletableFuture subscribeFuture = subscribe(threadId);
try {
subscribeFuture.get(time, java.util.concurrent.TimeUnit.MILLISECONDS);
} catch (ExecutionException | TimeoutException e) {
if (!subscribeFuture.cancel(false)) {
subscribeFuture.whenComplete((res, ex) -> {
if (ex == null) {
unsubscribe(res, threadId);
}
});
}
acquireFailed(waitTime, unit, threadId);
return false;
}
try {
//经过上面的处理,看下现在时间是否过期
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
while (true) {
long currentTime = System.currentTimeMillis();
//尝试获取锁
ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
//ttl是空,说明获取到锁
if (ttl == null) {
return true;
}
//看时间是否到了,到了就过期了。
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
// waiting for message
currentTime = System.currentTimeMillis();
//ttl 大于0,并且ttl小于过期时间,那么尝试去获取锁。
if (ttl >= 0 && ttl < time) {
commandExecutor.getNow(subscribeFuture).getLatch().tryAcquire(ttl, java.util.concurrent.TimeUnit.MILLISECONDS);
} else {
commandExecutor.getNow(subscribeFuture).getLatch().tryAcquire(time, java.util.concurrent.TimeUnit.MILLISECONDS);
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
}
} finally {
//最终释放掉订阅。
unsubscribe(commandExecutor.getNow(subscribeFuture), threadId);
}
// return get(tryLockAsync(waitTime, leaseTime, unit));
} 从 Long ttl = this.tryAcquire(leaseTime, unit, threadId)这句进去到tryAcuire中:
private Long tryAcquire(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
return get(tryAcquireAsync(waitTime, leaseTime, unit, threadId));
}private RFuture tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
RFuture ttlRemainingFuture;
if (leaseTime > 0) {
ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {
// 从上面得到leastTime的值为-1L,所以会进入到else中。
// internalLockLeaseTime的默认值为:30 * 1000
// TimeUnit.MILLISECONDS 毫秒
ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime,
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
}
CompletionStage f = ttlRemainingFuture.thenApply(ttlRemaining -> {
// lock acquired
if (ttlRemaining == null) {
if (leaseTime > 0) {
internalLockLeaseTime = unit.toMillis(leaseTime);
} else {
// 锁过期时间续期,此方法的具体逻辑为:每次间隔租期的1/3时间执行这个续约。
scheduleExpirationRenewal(threadId);
}
}
return ttlRemaining;
});
return new CompletableFutureWrapper<>(f);
} 先看tryLockInnerAsync尝试去获取到锁,这里面的实现主要是通过lua脚本来实现的,保证了原子性。
RFuture tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand command) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,
//如果锁不存在
"if (redis.call('exists', KEYS[1]) == 0) then " +
//获取锁
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
//设置有效期
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
//如果锁已存在,并且锁的是当前线程
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
//重入次数+1
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
//设置有效期
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
//如果锁已存在,但并非本线程,则返回过期时间ttl
"return redis.call('pttl', KEYS[1]);",
Collections.singletonList(getRawName()), unit.toMillis(leaseTime), getLockName(threadId));
} 重新设置锁的过期时间:
protected CompletionStage renewExpirationAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getRawName()),
internalLockLeaseTime, getLockName(threadId));
} -
lock.unlock();
最终会调用unlockInnerAsync方法实现解锁。
protected RFuture unlockInnerAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
// 如果分布式锁存在,但是value不匹配,表示锁已经被占用,那么直接返回
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
// 如果就是当前线程占有分布式锁,那么将重入次数减1
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
// 重入次数减1后的值如果大于0,还在占用分布式锁,那么只设置失效时间,还不能删除
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
// 重入次数减1后的值如果为0,表示锁已经没有被占用了,那么删除这个KEY,并发布解锁消息
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end; " +
"return nil;",
Arrays.asList(getRawName(), getChannelName()), LockPubSub.UNLOCK_MESSAGE, internalLockLeaseTime, getLockName(threadId));
} 使用Redisson、LUA实现分布式秒杀功能
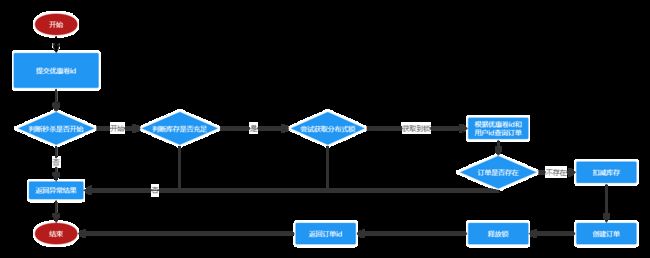
实现核心代码:
private void createVoucherOrder(VoucherOrder voucherOrder) {
Long userId = voucherOrder.getUserId();
Long voucherId = voucherOrder.getVoucherId();
// 创建锁对象
RLock redisLock = redissonClient.getLock("lock:order:" + userId);
// 尝试获取锁
boolean isLock = redisLock.tryLock();
// 判断
if (!isLock) {
// 获取锁失败,直接返回失败或者重试
log.error("不允许重复下单!");
return;
}
try {
// 5.1.查询订单
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
log.error("不允许重复下单!");
return;
}
// 6.扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // set stock = stock - 1
.eq("voucher_id", voucherId).gt("stock", 0) // where voucher_id= ? and stock > 0
.update();
if (!success) {
// 扣减失败
log.error("库存不足!");
return;
}
// 7.创建订单
save(voucherOrder);
} finally {
// 释放锁
redisLock.unlock();
}
}但是上面的代码实现会频繁的操作数据库,因此我们可以进行优化:
- 减少数据库的操作,使用lua实现。
创建seckill.lua:
-- 1.参数列表
-- 1.1.优惠券id
local voucherId = ARGV[1]
-- 1.2.用户id
local userId = ARGV[2]
-- 2.数据key
-- 2.1.库存key
local stockKey = 'seckill:stock:' .. voucherId
-- 2.2.订单key
local orderKey = 'seckill:order:' .. voucherId
-- 3.脚本业务
-- 3.1.判断库存是否充足 get stockKey
if(tonumber(redis.call('get', stockKey)) <= 0) then
-- 3.2.库存不足,返回1
return 1
end
-- 3.2.判断用户是否下单 SISMEMBER orderKey userId
if(redis.call('sismember', orderKey, userId) == 1) then
-- 3.3.存在,说明是重复下单,返回2
return 2
end
-- 3.4.扣库存 incrby stockKey -1
redis.call('incrby', stockKey, -1)
-- 3.5.下单(保存用户)sadd orderKey userId
redis.call('sadd', orderKey, userId)
return 0秒杀逻辑:
public Result seckillVoucher(Long voucherId) {
Long userId = UserHolder.getUser().getId();
// 1.执行lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
vouchrId.toString(), userId.toString()
);e
int r = result.intValue();
// 2.判断结果是否为0
if (r != 0) {
// 2.1.不为0 ,代表没有购买资格
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 2.2.为0 ,有购买资格,把下单信息保存到阻塞队列
VoucherOrder voucherOrder = new VoucherOrder();
// 2.3.订单id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 2.4.用户id
voucherOrder.setUserId(userId);
// 2.5.代金券id
voucherOrder.setVoucherId(voucherId);
// 2.6.创建订单
save(voucherOrder);
// 3.返回订单id
return Result.ok(orderId);
}单节点redis问题和解决办法
- 数据丢失问题:redis持久化
- 并发能力问题:搭建主从集群,实现读写分离
- 故障恢复问题:利用Redis哨兵,实现健康检测和自动恢复
- 存储能力问题:搭建分片集群,利用插槽机制实现动态扩容
redis持久化
RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
redis.conf配置文件中,设置RDB相关配置如下:
- 开启RDB:
# 给定的秒数和发生给定的对数据库的写操作次数,触发RDB。
# save 3600 1 代表3600秒内发生至少1次写操作,触发RDB。
save 3600 1
# 或者300秒内发生至少100次写操作,触发RDB。
save 300 100
# 或者60秒内发生至少10000次写操作,触发RDB。
save 60 10000- 禁用RDB
# 禁用RDB
save ""
-
其他设置
# DB文件名称
dbfilename dump.rdb
# DB将被写入这个目录
dir ./
RDB方式bgsave的基本流程?
fork主进程得到一个子进程,共享内存空间
子进程读取内存数据并写入新的RDB文件
用新RDB文件替换旧的RDB文件。
RDB会在什么时候执行?save 60 1000代表什么含义?
默认是服务停止时。
代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
fork子进程、压缩、写出RDB文件都比较耗时
AOF持久化
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
redis.conf配置文件中,设置RDB相关配置如下:
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
# appendfsync用来配置AOF记录的频率
# always 表示每执行一次写命令,立即记录到AOF文件,优点:可靠性高,几乎不丢数据;缺点:性能影响大
# appendfsync always
# 每秒只同步一次,最多丢失一秒的数据
appendfsync everysec
# 让操作系统在需要的时候刷新数据
# appendfsync no因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。
配置重写AOF的阈值:
# AOF文件比上次文件增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
redis主从集群
搭建redis主从集群
共包含三个节点,一个主节点,两个从节点。
这里我们会在同一台虚拟机中开启3个redis实例,模拟主从集群,信息如下:
| IP | PORT | 角色 |
| 192.168.253.128 | 7001 | master |
| 192.168.253.128 | 7002 | slave |
| 192.168.253.128 | 7003 | slave |
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
- 创建目录
我们创建三个文件夹,名字分别叫redis7001 、redis7002 、redis7003:
[root@vm local]# mkdir redis7001 redis7002 redis7003
- 下载redis安装包
[root@vm local]# cd redis7001
[root@vm redis7001]# wget http://download.redis.io/releases/redis-6.2.6.tar.gz
- 解压下载好的安装包
[root@vm redis7001]# tar -xvzf redis-6.2.6.tar.gz
- 查看Linux系统有没有 gcc 环境
[root@vm redis7001]# gcc --version
- 没有就安装,下载安装最新版的
gcc编译器,安装C语言的编译环境
root@vm redis7001]# yum install gcc-c++
- 进入redis-6.2.6目录,运行编译命令
[root@vm redis7001]# cd redis-6.2.6/
[root@vm redis-6.2.6]# make- 运行安装指令make install
[root@vm redis-6.2.6]# make install
cd src && make install
make[1]: 进入目录“/usr/local/redis7001/redis-6.2.6/src”
Hint: It's a good idea to run 'make test' ;)
INSTALL redis-server
INSTALL redis-benchmark
INSTALL redis-cli
make[1]: 离开目录“/usr/local/redis7001/redis-6.2.6/src”
redis安装目录:/usr/local/bin

- 然后修改redis.conf文件中的一些配置
# 设置密码
requirepass redis7001
# 添加端口号
port 7001
# pid 文件,会自动创建的,直接指定目录
pidfile /var/run/redis7001.pid
# 设置为守护进程,配置 redis 后台运行
daemonize yes
# 数据库数量,设置为1
databases 1
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 关闭保护模式
protected-mode no- 修改完配置文件后,运行redis
[root@vm redis-6.2.6]# redis-server redis.conf
[root@vm redis-6.2.6]# ps -ef|grep redis
root 108741 1 0 23:46 ? 00:00:00 redis-server 127.0.0.1:7001
root 108759 2773 0 23:47 pts/0 00:00:00 grep --color=auto redis运行成功后,我们就可以对这个端口为7001的、master 角色的redis进行读写操作了。
下面我们开始搭建redis slave服务。
- 先将代码拷贝到redis7002目录中
[root@vm redis-6.2.6]# cp redis.conf /usr/local/redis7002
并修改如下配置:
# 设置密码
requirepass redis7002
# 添加端口号
port 7002
# pid 文件,会自动创建的,直接指定目录
pidfile /var/run/redis7002.pid
# 设置为守护进程,配置 redis 后台运行
daemonize yes
# 数据库数量,设置为1
databases 1
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 关闭保护模式
protected-mode no
# 配置master的ip和端口
replicaof 192.168.253.128 7001
# 配置master的密码
masterauth redis7001- 运行redis7002
[root@vm redis7002]# vi redis.conf
[root@vm redis7002]# redis-server redis.conf
[root@vm redis7002]# ps -ef|grep redis
root 109583 1 0 10:35 ? 00:00:06 redis-server 0.0.0.0:7001
root 111972 1 0 11:56 ? 00:00:00 redis-server 0.0.0.0:7002
root 111987 2773 0 11:56 pts/0 00:00:00 grep --color=auto redis- 查看master(主)状态
Redis-cli客户端连接Redis服务器命令:redis redis-cli -a 密码 -p 端口 -h 主机IP
查看主/从复制的相关信息命令:info replication
[root@vm local]# redis-cli -a redis7001 -p 7001
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:7001> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.253.128,port=7002,state=online,offset=994,lag=0
master_failover_state:no-failover
master_replid:199d257b540309fa1f4a49eacfa89a0b644ce355
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:994
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:994
- 查看slave(从)状态
[root@vm local]# redis-cli -a redis7002 -p 7002
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:7002> info replication
# Replication
role:slave
master_host:192.168.253.128
master_port:7001
master_link_status:up
master_last_io_seconds_ago:7
master_sync_in_progress:0
slave_read_repl_offset:1624
slave_repl_offset:1624
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:199d257b540309fa1f4a49eacfa89a0b644ce355
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1624
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1624
127.0.0.1:7002>
- 接着搭建端口为7003的redis
将redis7002下的配置文件拷贝到redis7003目录下
[root@vm local]# cp /usr/local/redis7002/redis.conf /usr/local/redis7003
进入redis7003目录下,修改端口等信息
[root@vm local]# cd /usr/local/redis7003
[root@vm redis7003]# vi redis.conf # 设置密码
requirepass redis7003
# 添加端口号
port 7003
# pid 文件,会自动创建的,直接指定目录
pidfile /var/run/redis7003.pid
# 设置为守护进程,配置 redis 后台运行
daemonize yes
# 数据库数量,设置为1
databases 1
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任
意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 关闭保护模式
protected-mode no
# 配置master的ip和端口
replicaof 192.168.253.128 7001
# 配置master的密码
masterauth redis7001
运行
[root@vm redis7003]# redis-server redis.conf
[root@vm redis7003]# ps -ef|grep redis
root 109583 1 0 10:35 ? 00:00:12 redis-server 0.0.0.0:7001
root 111972 1 0 11:56 ? 00:00:05 redis-server 0.0.0.0:7002
root 114167 1 0 13:20 ? 00:00:00 redis-server 0.0.0.0:7003
root 114182 2773 0 13:20 pts/0 00:00:00 grep --color=auto redis
查看
[root@vm redis7003]# redis-cli -a redis7001 -p 7001
127.0.0.1:7001> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.253.128,port=7002,state=online,offset=7001,lag=0
slave1:ip=192.168.253.128,port=7003,state=online,offset=7001,lag=0
master_failover_state:no-failover
master_replid:199d257b540309fa1f4a49eacfa89a0b644ce355
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:7001
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:7001
至此,一主两从的redis主从集群已搭建完毕,下面我们测试下利用redis-cli连接7001,执行set num 123
127.0.0.1:7001> set num 123
OK
127.0.0.1:7001> get num
"123"利用redis-cli连接7002,执行get num,再执行set num 456(会提示错误,不能对只读副本进行写操作 )
127.0.0.1:7002> get num
"123"
127.0.0.1:7002> set num 456
(error) READONLY You can't write against a read only replica.
可以发现,只有在7001这个master节点上可以执行写操作,7002这个slave节点只能执行读操作。
常见问题:
master如何判断slave是不是第一次来同步数据?
Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid。
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。 因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据。
简述全量同步的流程?
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
简述全量同步和增量同步区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave。
什么时候执行全量同步?
slave节点第一次连接master节点时。
slave节点断开时间太久,repl_baklog中的offset已经被覆盖时。
什么时候执行增量同步?
slave节点断开又恢复,并且在repl_baklog中能找到offset时。
redis哨兵集群
常见问题:
主观下线:每个Sentinel节点会每隔1秒对主节点、从节点、其他Sentinel节点发送ping命令做心跳检测,当这些节点超过down-after-milliseconds(sentinel配置文件中的down-after-milliseconds设置了判断主观下线的时间长度)没有进行有效回复,那么sentinel回认为该实例已(主观)下线。
客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。