汇编语言 --- 32位x86处理器架构
x86 CPU有实模式、保持模式、虚拟8086模式、系统管理模式等的分别。 x86 CPU只有在启动的时候才能进入实模式,一旦切换到保持模式就无法退出回到实模式。
简单的讲,实模式就是8086使用CPU的模式。当然那时还没有实模式的叫法。只有后面有保护模式,旧的模式才有了实模式的称呼。
寄存器扩展
内部通用寄存器宽度 16bits --> 32bits
高16位不能单独使用 低16位兼容16位模式使用 同样可以分为高8位和低8位使用
扩展后新的寄存器名在原来的基础上加上前缀E 代表Extend 即扩展

32位模式下源操作数和目的操作数必须具有相同的长度: mov eax,cx ; forbidden
操作数使用立即数会被视为32位: mov eax, 0xf2 ; EAX <-- 0x000000f2
可以在32位处理器上运行16位处理器上的软件
32位处理器有32根地址线,能够访问4GB内存,为了生成32位物理地址,处理器需要使用32位的指令指针寄存器。
幸运的是,32位处理器天生拥有扩展后的IP寄存器EIP,32位,当然他也可以兼容16位去使用,低16位和实模式下的16位IP一样使用
32位模式下内存访问 理论上不需要分段,因为32根地址线就可以自由访问任何一个内存位置
但是IA-32架构的处理器基于分段模型,不管是工作在16 位或是32位模式,32位处理器依然需要以段为单位访问内存
但是分段是自由的,可以分为8,16,32…个段,极端情况下是只分为一个段,基地址0x00000000,段长度4GB。这样就和没分段的情况下一样了。 这就是著名的平坦模型

基本工作模式
x86系列:8086,80286,80386等,这个x就代表“某”的意思
80286是intel的一款向保护模式过渡的产品,它也是一款16bit的处理器,但却拥有24根地址线(8086时16bit处理器20根地址线)。
虽然80286有24根地址线,但是段寄存器是16位的,而且只能使用16位的偏移地址,从这一方面看,16位段寄存器搭配16位偏移地址应该只能使用64kb的段,但80286是可以使用保护模式的,这也是intel首次提出保护模式的概念,段寄存器中保存的不再是段地址而是段选择子(16bit)
在保护模式出现以前,8086的寻址是通过CS和IP寄存器的组合而成的实际物理地址去寻址的,这个物理地址宽度和地址线实际宽度相等(20),实际物理地址为:CS<<16 + IP。
这种地址形成方法有两个弊端:
第一:
最大可以表示的数值是0xFFFF0 + 0xFFFF = 0x10FFEF 大约是1M+64KB - 16Bytes,然而地址线只有20根,这就导致这个最大地址会出现回卷现象,类似于对0xFFFFF取余,回到了地址低端0xFFEF处(64kb-16bytes处)
第二:
程序可以任意修改当前的CS/DS值,所有程序可以使用全部的1MB的内存,所以这个CPU几乎没有办法有效地支持多任务。两个任务一起运行就会出现相互踩到对方的内存的现象,所以那个时代使用DOS系统必须和应用程序之间做约定,DOS系统放在一块内存空间而应用程序放在另一个空间,二者互不干扰,如果想运行另一个用户程序还得将当前运行的程序停掉才能让另一个上
为了有效地保护多任务情况下用户程序的执行,就出现了保护模式的说法,从而以前的那种模式才有了实模式这个名字(相对的)。保护模式可以让一个进程的内存不被其他进程非法访问。
80286的保护模式在CS<<16+IP来生成实际物理地址的过程中加了一个转换层
CS里面的内存不再是20位物理地址的高16位,而变成了段描述符表中的索引。
DOS系统在启动应用程序前需要在内存中安装两个表:
全局描述符表GDT
局部描述符表LDT
表中的每个条目代表一段内存地址:
段内存的起始地址base
段内存的长度limit
一个表的多个条目就保存了这个用户程序可以访问的多块内存
两张表需要被使用起来,就要把他们的起始地址放到寄存器中,所以286中出现了GDTR和LDTR寄存器:GDTR中存放了GDT表所在的起始地址和界限大小:

描述符表中存储的是一个个描述符,一个描述符占据两个双字的大小,也就是64位,八个字节
描述符中存储了段基地址,段界限,DPL,等等信息,十分重要!
CS和DS寄存器中现在就保存初始索引。具体的寻址方法看下图:

注意 !!!这个图CS寄存器有说法,CS寄存器是16位的,这16位是图中的样子(段选择子),可以兼容实模式使用。但是CS寄存器还有一部分程序员不可见的扩展,这部分扩展是硬件控制的,叫做描述符高速缓存器。CS作为段选择子在GDT中找到段基址后就会将段基址放到描述符高速缓存器中,后面寻址时就会使用这个地址作为基址(IP作为偏移直接加上去!)。段选择子不重新到选择器中找新的基址,这个缓存器中的值就不会更改。(除非call jmp等指令)

任务 分段 分页
IA-32 处理器支持多任务。在多任务环境下,任务的创建需要分配内存空间;当任务终止后,还要回收它所占用的内存空间。在分段模型下,内存的分配是不定长的,程序大时,就分配一大块内存;程序小时,就分配一小块。时间长了,内存空间就会碎片化,就有可能出现一种情况:内存空间是有的,但都是小块,无法分配给某个任务。为了解决这个问题,IA-32 处理器支持分页功能,分页功能将物理内存空间划分成逻辑上的页。页的大小是固定的,一般为4KB,通过使用页,可以简化内存管理。
当开启页功能的时候,段部件产生的就不再是物理地址,而是线性地址,线性地址经过页部件转换后才能形成物理地址
线性地址的概念是用来描述任务的地址空间
IA-32处理器上每个任务都拥有4GB的虚拟内存空间,这是一段长4GB的平坦空间,就像一段平直的线段,故名线性地址空间
由段部件产生的地址,就对应着线性地址空间上的每一个点,这就是线性地址。
现代处理器的结构和特点
流水线
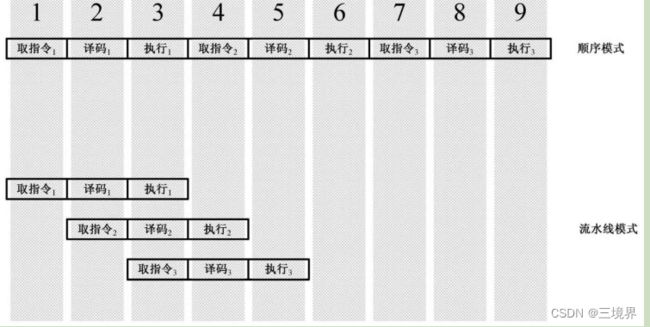
一条指令的执行需要三个步骤:取值,译码,执行。分别在三个机器周期完成。
如果顺序执行三条命令,则需要3*3=9个机器周期
但一个时钟周期并不是只能执行一个指令的一个步骤,完全可以在第一条指令的译码期间就取第二条指令,从而第一条指令的执行期间也可以译码。这个恩惠来源于8086指令预取队列。当指令执行时,如果总线是空闲的(没有访问内存的操作),就可以在指令执行的同时预取指令并提前译码,这种做法是有效的,能大大加快程序的执行速度。
做个比喻:
你是CPU,你的任务是美食鉴赏,桌上一次会放置三道菜,尝完三道菜就会换下一波的三道菜
顺序执行的情况就是,这三道菜通过这样的顺序鉴赏:
夹第一道菜到嘴里–>品尝–>给出鉴赏结果 --> 夹第二道菜到嘴里–>品尝–>给出鉴赏结果 --> 夹第三道菜到嘴里–>品尝–>给出鉴赏结果
这种情况默认你的口中同时只能放一道菜,现在你升级了,嘴里可以放三道菜,这就想指令预取队列
现在你可以以下面这种方式鉴赏:
夹第一道菜到嘴里–>品尝 并夹第二道菜到嘴里–>给出鉴赏结果 并品尝第二道菜 …
这样是不是就快多了呢?
高速缓存
触发器工作速度是纳秒级别,可以用来做内存的基本单元,即静态存储器 SRAM
一般的内存芯片的材料是电容和单个晶体管,由于电容需要定时刷新,所以也被叫做动态存储器(DRAM)
这也使得它的访问速度变得很慢,通常是几十个纳秒
硬盘是机电设备,机械和电子的混合体,速度最慢,毫秒级ms
机器在访问内存和硬盘时木桶效应就会出现,处理器无法全速运行为了缓解这一矛盾,高速缓存(Cache)技术应运而生。高速缓存是处理器与内存(DRAM)之间的一个静态存储器,容量较小,但速度可以与处理器匹配。
程序运行时有局部性规律,程序常访问最近刚访问过的指令和数据,或者与它们相邻的指令和数据。利用这个规律可以把处理器正在访问和即将访问的指令和数据块从内存调入高速缓存。处理器要访问内存时先访问高速缓存,如果要访问的内容已经在高速缓存中,那么,很好,可以用极快的速度直接从高速缓存中取得,这称为命中(Hit);否则,称为不中(miss)。在不中的情况下,处理器在取得需要的内容之前必须重新装载高速缓存,而不只是直接到内存中去取那个内容。高速缓存的装载是以块为单位的,包括那个所需数据的邻近内容。为此,需要额外的时间来等待块从内存载入高速缓存,在该过程中所损失的时间称为不中惩罚(miss penalty)。
乱序执行
选修
寄存器重命名
选修
寻址方式上的区别:
