基础入门NLP - 新闻文本分类(二)
数据读取与数据分析
- 1 数据读取
- 2 数据分析
-
- 2.1 句子长度分析
- 2.2 新闻类别分布
- 2.3 字符分布统计
- 3 数据结论
1 数据读取
前言:本次提供的是新闻文本数据,数据中得每个新闻是不定长的,格式采用csv进行存储,因此可以直接用Pandas完成数据读取的操作。(数据获取链接)
数据描述:含有训练集20w条样本,(见上一节讲解链接)
import pandas as pd #导入
train_df = pd.read_csv(r'D:/data1/train_set.csv', sep='\t',nrows=20000 )
train_df.head()结果:
分析以上代码和结果:
- D:/data1:表示文件的存储路径;
- train_set:表示文件的命名;
- 分隔符sep,为每列分割的字符,设置为\t即可;
- 读取行数nrows,为此次读取文件的函数,是数值类型(注:若数据集比较大,建议先设置为100,也可直接去掉);
- head()默认显示前5条数据,数据以表格的形式,表中:第一列为新闻的类别,第二列为新闻的字符。
2 数据分析
任务要求:
- 本次数据中,新闻文本的长度是多少?
- 本次数据的类别分布是怎么样的,哪些类别比较多?
- 本次数据中,字符分布是怎么样的?
2.1 句子长度分析
- 句子长度分析思路:将数据中每行句子的字符使用空格进行隔开,接下来就可以直接统计单词的个数来得到每个句子的长度。
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
print(train_df['text_len'].describe())结果:

分析以上代码和结果:
- Python中apply函数的格式为:apply(func,*args,**kwargs),用途:当一个函数的参数存在于一个元组或者一个字典中时,用来间接的调用这个函数,并将元组或者字典中的参数按照顺序传递给参数;
- args是一个包含按照函数所需参数传递的位置参数的一个元组,简而言之,假如A函数的函数位置为 A(a=1,b=2),那么这个元组中就必须严格按照这个参数的位置顺序进行传递(a=3,b=4),而不能是(b=4,a=3)这样的顺序;
- kwargs是一个包含关键字参数的字典,而其中args如果不传递,kwargs需要传递,则必须在args的位置留空;
- apply的返回值就是函数func函数的返回值;
- lambda 参数:操作(参数),简称:匿名函数,它允许快速定义单行函数,可以用在任何需要函数的地方;在本代码中,x为入口参数,len(x.split(’ '))为函数体;
- x.split(’ '):以空格为分隔符,包含 \n;
- describe()函数就是返回这两个核心数据结构的统计变量。其目的在于观察这一系列数据的范围、大小、波动趋势等等,为后面的模型选择打下基础;
- 结果分析:新闻的每个句子平均由907个字符构成,最短的句子长度为2,最长的句子长度为57921。
- 为了能够更直观的看清楚句子长度的一个分布情况,我们绘制了直观图。
import matplotlib.pyplot as plt #引入
plt.hist(train_df['text_len'], bins=200) #
plt.xlabel('Text char count') #X坐标轴标签
plt.title("Histogram of char count") #标题结果:
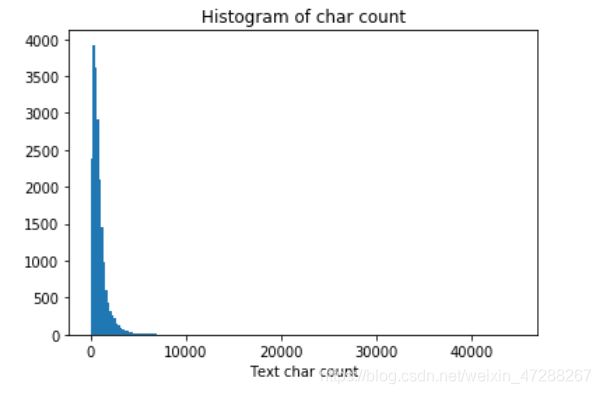
分析以上代码和结果:
- bins:这个参数指定bin(箱子)的个数,也就是总共有几条条状图;
- 结果分析:大部分句子的长度都几种在2000以内。
2.2 新闻类别分布
解题思路:将数据打好标签,获得数据集中标签的对应的关系,接下来可以对数据集的类别进行分布统计,具体统计每类新闻的样本个数。
数据集中标签的对应的关系如下:{‘科技’: 0, ‘股票’: 1, ‘体育’: 2, ‘娱乐’: 3, ‘时政’: 4, ‘社会’: 5, ‘教育’: 6, ‘财经’: 7, ‘家居’: 8, ‘游戏’: 9, ‘房产’: 10, ‘时尚’: 11, ‘彩票’: 12, ‘星座’: 13}
train_df['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")结果:
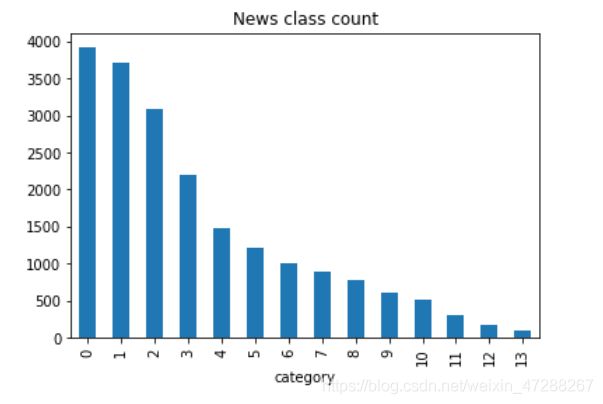
分析以上代码和结果:
- kind='bar:表示采用的是柱状图类型;
- value_counts()是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中有多少重复值。属于Series拥有的方法,一般在DataFrame中使用时,需要指定对哪一列或行使用,该函数返回的也是Series类型,且index为该列的不同值,values为不同值的个数;
- 结果:数据集类别分布存在较为不均匀的情况。在训练集中科技类新闻最多,其次是股票类新闻,最少的新闻是星座新闻。
2.3 字符分布统计
- 思路:接下来可以统计每个字符出现的次数,首先可以将训练集中所有的句子进行拼接进而划分为字符,并统计每个字符的个数。
from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count))
print(word_count[0])
print(word_count[-1])结果:
6869
(‘3750’, 7482224)
(‘3133’, 1)
分析以上代码和结果:
- Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串;
- 将每一项word_count.items()键值对的元祖进行迭代,每一项都作为参数传入key()函数(我说的是这个:key=lambda d:d[1],)中;
- word_count.items():返回字典键值对的元祖集合;
- key=lambda d:d[1] :是将键值(value)作为排序对象;而如果选择 key = lambda d:d[0],则选择【键Key】作为排序对象;
- reverse 是否反向,reverse=Ture表示反向;
- 结果:在训练集中总共包括6869个字,其中编号3750的字出现的次数最多,编号3133的字出现的次数最少。
- 根据字在每个句子的出现情况,反推出标点符号
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
print(word_count[0])
print(word_count[1])
print(word_count[2])结果:
(‘3750’, 197997)
(‘900’, 197653)
(‘648’, 191975)
分析以上代码和结果:
- 其中字符3750,字符900和字符648在20w新闻的覆盖率接近99%,很有可能是标点符号。
3 数据结论
通过上述分析我们可以得出以下结论:
- 赛题中每个新闻包含的字符个数平均为1000个,还有一些新闻字符较长;
- 赛题中新闻类别分布不均匀,科技类新闻样本量接近4w,星座类新闻样本量不到1k;
- 赛题总共包括7000-8000个字符。
通过数据分析,推出结论:
- 每个新闻平均字符个数较多,可能需要截断;
- 由于类别不均衡,会严重影响模型的精度。