并行处理及分布式系统 第二章 并行硬件和并行软件
1、局部性原理:程序访问完一个存储区域往往会访问接下来的区域,这个原理成为局部性。在访问完一个内存区域(指令或者数据),程序会在不久的将来(时间局部性)访问邻近的区域(空间局部性)。
2、解决Cache中的值域主存中的值不一致问题的两种方法:
方法一:写直达:当CPU向Cache写数据时,高速缓存行会立即写入主存中。
方法二:写回:数据不是立即更新到主存中,而是将发生数据更新的高速缓存行标记为脏,当发生高速缓存行替换时,标记为脏的高速缓存行被写入主存中。
3、Cache映射
全相联:每个高速缓存行能够放置在Cache中的任意位置。
直接映射:每个高速缓存行在Cache中的有唯一的位置。
n路组相联:每个高速缓存行能放置在Cache中n个不同区域位置中的一个。
4、实现指令级并行的两种主要方法:
流水线:将功能单元分阶段安排,通过将功能分成多个独立的硬件或者功能单元,并把它们按顺序串接起来提高性能。
多发射:让多条指令同时启动,通过复制功能单元来同时执行程序中的不同命令。
静态多发射:功能单元是在编译时调度的
动态多发射:功能单元是在运行时调度的
超标量:一个支持动态多发射的处理器称为超标量
5、硬件多线程
线程级并行(TLP):尝试通过同时执行不同线程来提供并行性。与ILP相比,TLP提供的是粗粒度的并行性,即同时执行的程序基本单元(线程)比细粒度的程序单元(单条指令)更大或更粗。
硬件多线程:为系统提供一种机制,使得当前执行的任务被阻塞时,系统能够继续其他有用的工作。
在细粒度多线程中,处理器在每条指令执行完后切换线程,从而跳过被阻塞的线程。尽管这种方法能够避免因为阻塞而导致机器时间浪费,但她的缺点是执行很长一段指令的线程在执行每条指令的时候都需要等待。粗粒度多线程为了避免这个问题,只切换那些需要等待较长时间才能完成操作(如从主存中加载)而被阻塞的线程。这种机制的优点是,不需要线程间的立即切换,但是,处理器还是可能在短阻塞时空闲,线程的切换也还是会导致延迟。
同步多线程(SMT):是细粒度多线程的变种,他通过允许多个线程同时使用多个功能单元来利用超标量处理器的性能。如果我们指定优先线程,那么能够在一定程度上减轻线程减速的问题,优先线程是指多条指令就绪的线程。
6、并行硬件
6.1SIMD系统(单指令多数据流):
是并行系统。
通过对多个数据执行相同的指令从而实现多个数据流上的操作。
一个抽象的SIMD系统可以认为由一个控制单元和多个ALU组成,一条指令从控制单元广
播到多个ALU,每个ALU要么在当前数据上执行,要么处于空闲状态。
注:在经典的SIMD系统中,ALU必须同步操作,即在下一条指令开始执行之前,每个
ALU必须等待广播,ALU中没有指令寄存器,所以ALU不能通过存储指令来延迟执行指令。
数据并行:通过将多个数据分配给多个处理器,然后让各个处理器使用相同的指令来操
作数据子集实现并行化。
任务并行:一个程序是通过将任务划分给各个进程或者线程来实现并行的。
6.2MIMD系统(多指令多数据流):
系统支持同时多个指令流在多个数据流上操作。
MIMD系统通常还包括一组完全独立的处理单元或者核,每个处理单元或者核都有自己的
控制单元和ALU。MIMD系统通常是异步的。
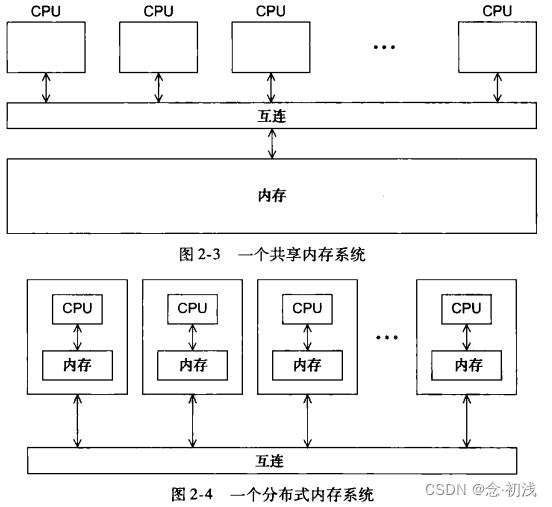
共享内存系统:一组自治的处理器通过互联网络与内存系统相互连接,每个处理器能够
访问每个内存区域,处理器通过访问共享内存的数据结构来影视的通信。
分布式内存系统:每个处理器有自己私有的内存空间,处理器—内存之间通过互联网络
相互通信。处理器之间是通过发送消息或者使用特殊的函数来访问其他处理器的内存,从而
进行显式的通信。
7、近年来典型系统的特征:
①向量寄存器:能够存储由多个操作数组成的向量,并且能够同时对其内容进行操作的寄存器,向量的长度由系统决定,从4到128个64位元素不等。
②向量化和流水化的功能单元。注意,对向量中的每个元素需要做同样的操作,或者某些类似于加法的操作,这些操作需要应用到两个向量中相应的元素对上,因此,向量操作是SIMD。
③向量指令。这些是在向量上操作而不是在标量上操作的指令。
④交叉存储器。内存系统由多个内存“体”组成,每个内存体能够独立访问。在访问完一个内存体后,再次访问它之前需要有一个时间延迟,但如果接下来的内存访问是访问另一个内存体,那么它很快就能访问到。所以,如果向量中的各个元素分布在不同的内存体中,那么在装入/存储连续数据时能够几乎无延迟的访问。
⑤步长式存储器访问和硬件散射/聚集。在步长式存储访问中,程序能够访问向量中固定间隔的元素。
8、链路的带宽是指它传输数据的速度。通常用兆位每秒或者兆字节每秒来表示。
9、等分带宽通常用来衡量网络的质量。它与等分带宽度类似。但是等分带宽不是计算连接两个等分之间的链路数,而是计算链路的带宽。
10、全相连网络:每个交换器与每一个其他的交换器直接连接。
11、超立方体:是一种已经同于实际系统中的高度互连的直接互连网络。超立方体是递归构造的。
12、间接互连为直接互连提供了一个替代的选择,在间接互连网络中,交换器不一定与处理器直接连接,他们通常有一些单向连接和一组处理器组成,每个处理器有一个输入链路和一个输出链路,这些链路通过一个交换网络连接。
13、延迟是指从发送源开始传送数据到目的地开始接受数据之间的时间。
14、带宽是指目的地在开始接受数据后接受数据的速度。
15、如果一个互连网络的延迟是l秒,带宽是b字节每秒,则传输一个n字节的消息需要花费的时间是:消息传送的时间=l+n/b。
16、Cache一致性问题:在多核系统中,各个核的Cache存储相同变量的副本,当一个处理器更新Cache中该变量的副本时,其他处理器应该知道该变量已更新,即其他处理器中Cache的副本也应该更新。
17、负载均衡:在进程/线程之间平均分配任务从而满足使得每个进程/线程获得大致相等的工作量。
18、广播与规约
广播:在广播通信中,单个进程传送相同的数据给所有的进程。
规约:在规约函数中,将各个进程计算的结果汇总成一个结果。
19、并行程序需要输入输出时遵循的规则
①在分布式内存程序中,只有进程0能够访问stdin。在共享内存程序中,只有主线程或者线程
0能够访问stdin。
②在分布式内存和共性内存系统中,所有进程和线程都能够访问stdout和是stderr。
③因为输出到stdout的非确定性顺序,大多数情况下只有一个进程/线程会将结果输出到
stdout。但输出调试程序的结果是个例外,在这种情况下,允许多个进程/线程写stdout。
④只有一个进程/线程会尝试访问一个除stdin、stdout或者stderr外的文件。每个进程/线程都
能够打开自己私有的文件进行读、写,但是没有两个进程/线程能够打开相同的文件
⑤调试程序输出在生成输出结果时,应该包括进程/线程的序号或者进程标识符。
20、性能
线性加速比:T并行=T串行/p。T并行表示并行运行时间,T串行表示串行运行时间,p表示核
数
加速比:S=T并行/T串行。线性加速比为s=p。
效率:E=S/p=(T串行/T并行)/p=T串行/p*T并行
当问题的规模变大时,加速比和效率增加。当问题规模变小时,加速比和效率降低。
21、可扩展性
可扩展性:增加程序所用的进程/线程数,如果在输入规模也以相应增长率增加的情况下,该程序的效率值一直都是固定的,那么就称该程序是可扩展的。
强可扩展性:在增加进程/线程的个数时,可以维持固定的效率,却不增加问题的规模,那么程序称为强可扩展的。
弱可扩展性:增加进程/线程个数的同时,只有以相同倍率增加问题的规模才能使效率值保持不变,那么程序就称为弱可扩展性。
22、并行化步骤:
①划分:将要执行的指令和数据按照计算部分拆分成多个小任务,这一步的关键在于识别出任何可以并行执行的任务。
②通信:确定上一步所识别出来的任务之间需要执行哪些通信。
③凝聚或聚合:将第一步所确定的任务与通信结合成更大的任务。
④分配:将上一步聚合好的任务分配到进程/线程中。这一步还要使通信量最小化,使各个进程/线程所得到的工作量大致均匀。