五、中央处理器(五)指令流水线
目录
5.1指令流水线的基本概念
五段式流水线
5.2流水线的表示方法和性能指标
5.3结构冒险、数据冒险和控制冒险的处理
5.3.1结构相关(资源冲突)
5.3.2数据相关(数据冲突)
5.3.3控制相关(控制冲突)
5.4流水线的分类
5.4.1部件功能级、处理机级和处理机间级流水线。
5.4.2单功能、多功能流水线
5.4.3静态、动态流水线
5.4.4线性、非线性流水线
5.5高级流水线技术
5.5.1超标量流水线技术(动态多发射)
5.5.2超长指令字技术(静态多发射)
5.5.3超流水线技术
5.1指令流水线的基本概念
流水线技术:时间上的并行技术,将一个任务分解为几个不同的子阶段,每个阶段所用到的功能部件不同。所以多个任务可以同时执行,只是执行的子阶段不同。这种指令执行方案就是指令流水线。(不同于之前的两种方案:单周期方案和多周期方案)。
超标量处理机:空间上的并行技术,在一个处理机内设置多个执行相同任务的功能部件,并让这些功能部件并行工作。
五段式流水线
每个功能段的时间保持一致,以最长的功能段时间为准:比如100ns=80ns →其中最长的取指(IF)耗时+20ns →流水段寄存器锁存时长。
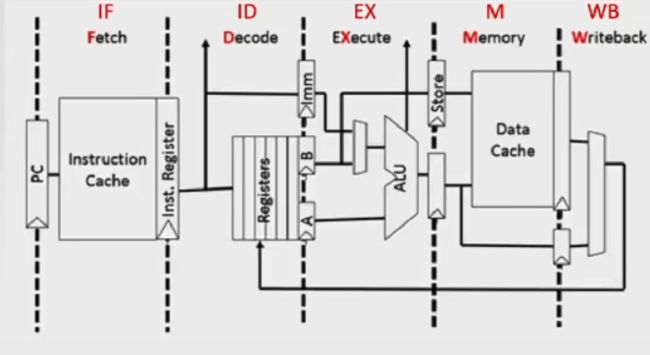
- 取指(IF):取指通常是在数据cache取指,而不在主存中取指。下面的访存也是。取出指令放在指令寄存器IR中,PC+“1”。
- 译码&读寄存器(ID):控制器中的ID对OP(IR)进行译码,然后从寄存器组中读出操作数。
- 执行/计算地址(EX):执行运算操作或者计算有效地址。
- 访存(MEM):对存储器进行读写操作(load/store)
- 写回(WB):将指令执行结果写回寄存器堆。
| 阶段\指令类型 | 运算类指令 | load取数 | store存数 | 条件转移指令 | 无条件转移指令 |
| 取指(IF) 都一样 |
根据PC从数据Cache取指令到IF段的锁存器 | 从Cache取指令到IF段的锁存器 | 从Cache取指令到IF段的锁存器 | 从Cache取指令到IF段的锁存器 | 从Cache取指令到IF段的锁存器 |
| 译码/读寄存器(ID) | 从寄存器组中读出操作数放至ID段锁存器 | 将基址寄存器的值放在A,偏移量放置IMM | 将基址寄存器的值放在A,偏移量放置IMM,要存的数放置B | 将进行比较的两个数放入A和B,偏移量放入IMM | 偏移量放入IMM |
| 执行/计算地址(EX) | 运算,将结果放置EX段锁存器 | 计算得到有效地址放入EX段锁存器 | 计算得到有效地址,并将要存的数放置store | 运算,进行条件比较 | 将目标PC值写入PC |
| 访存(MEM) | 对于RISC,运算结果存回寄存器,故该段为空段。 | 从数据Cache中取数放到MEM段锁存器中 | 将要存的数写入数据cache |
将目标PC值写入PC,也称WrPC段 |
空段 |
| 写回(WB) | 将运算结果写回寄存器 | 将取出的数写回寄存器 | 空段 | 空段 | 空段 |
上表分析:
- 运算类指令有很多情况:比如ADD(立即数和寄存器相加,ID段放在IMM和A)ADD(两个寄存器相加,放在A和B)
- 在RISC中,只有load和store才能访问主存,其他指令的操作数都来自寄存器或含有立即数。
- 注意取数指令和存数指令的区别和共同点,两者都需要计算有效地址并访问数据cache;load最后要将结果写回寄存器,而store指令不需要。
- 条件转移指令:ARM架构的汇编格式:beq Rs, Rt,偏移量 功能:当(Rs)==(Rt),(PC)+指令字长+偏移量×指令字长=PC;否则(PC)+指令字长=PC;同理bnq是不等时
补充(与下面的流水线冒险有关):
- 要求“按序发射,按序完成”,所以如果上一条指令在ID段发生冲突,下一条指令IF段要在上一条指令的ID段进行,因为上一条指令取指后放在IF段锁存器中,在ID没进行前不能被覆盖。

- x=x*2+a对应的指令序列为:(别忘了取数存数操作)

5.2流水线的表示方法和性能指标
两种流水线的表示方法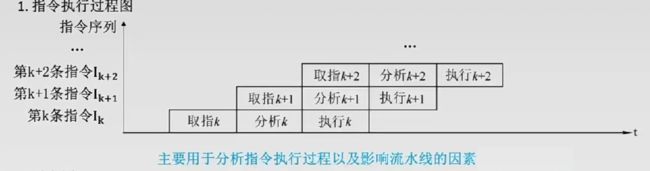

- 吞吐率:单位时间内流水线完成的工作数量,或输出结果的数量。



5.3结构冒险、数据冒险和控制冒险的处理
5.3.1结构相关(资源冲突)
多条指令在同一时刻争用同一资源而形成的冲突。
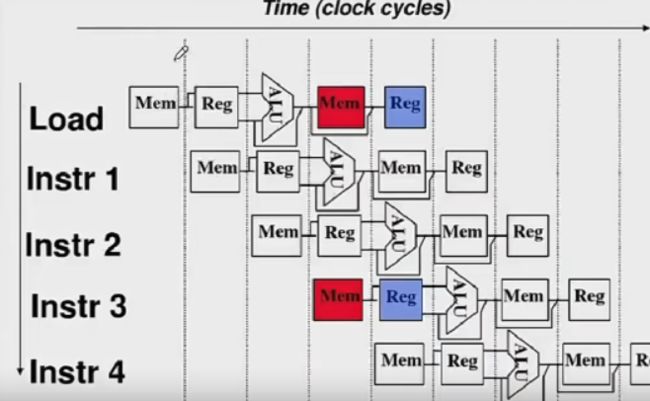
解决方法:
- 后一相关指令暂停一周期。
- 资源重复配置:数据存储器+指令存储器
5.3.2数据相关(数据冲突)
在一个程序中,下一条指令会用到当前指令计算出的结果,此时这两条指令发生数据冲突。
数据冒险可分为三类:
- 写后读(RAW,read after writer):当前指令将数据写入寄存器后,下一条指令才能从该寄存器读取数据。
- 读后写(WAR)
- 写后写(WAW):否则下一条指令在当前指令之前写,将使寄存器的值不是最新值。
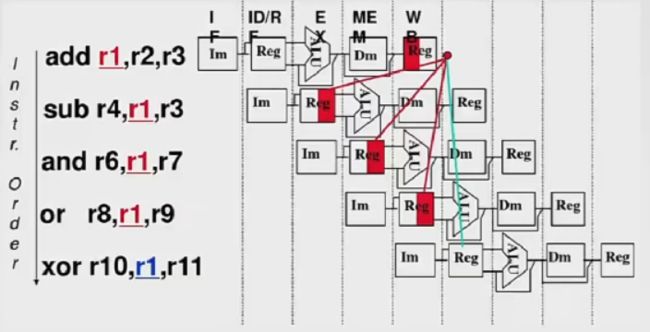
解决方法:
- 把遇到数据相关的指令及其后续指令都暂停一至几个时钟周期,直到数据相关问题消失后再继续执行。可分为硬件阻塞(stall)和软件插入“NOP”两种方法。
- 数据旁路技术(转发机制)。
- 编译优化:通过编译器调整指令顺序来解决数据冲突。
5.3.3控制相关(控制冲突)
指令通常是顺序执行的,但是在遇到改变指令执行顺序的情况下,例如执行转移、调用或返回指令时,会改变PC值,会造成断流,从而引起控制冒险。
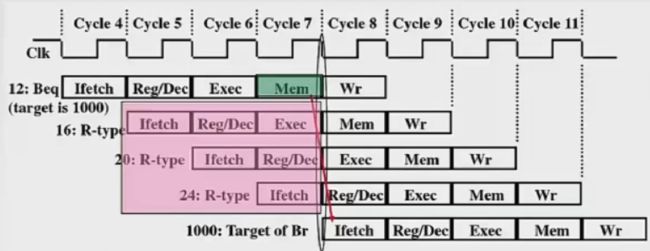
解决方法:
- 转移指令分支预测。简单预测(永远猜ture或false)、动态预测(根据历史情况动态调整)
- 预取转移成功和不成功两个控制流方向上的目标指令。
- 加快和提前形成条件码。
- 提高转移方向的猜准率。
5.4流水线的分类
5.4.1部件功能级、处理机级和处理机间级流水线。
根据流水线的使用级别不同分类。
部件功能级:复杂的算术逻辑运算组成流水线的工作方式。例如:浮点加法操作分为求阶差、对阶、尾数相加和结果规格化等4个子过程。
处理机级:把一条指令解释过程分为多个子过程,如前面的5段式流水线。
处理机间级:是一种宏流水,其中每个处理机完成某一专门任务,各个处理机所得到的结果需存放在与下一个处理机所共享的存储器中。
5.4.2单功能、多功能流水线
按流水线可以完成的功能多少分类
单功能流水线是指只能完成一种固定功能的流水线,如浮点加法流水线只能完成浮点加法操作,无法进行其他操作。
多功能流水线是指流水线的各个段可以进行不同的连接,从而使流水线在不同的时间,或者在同一时间完成不同的功能。可以完成不同功能的指令。
5.4.3静态、动态流水线
按同一时间内各段之间的连接方式分类
静态流水线指在同一时间内,流水线的各段只能按同一种功能的连接方式工作。
动态流水线指在同一时间内,当某些段正在实现某种运算时,另一些段却正在进行另一种运算。这样对提高流水线的效率很有好处,但会使流水线控制变得很复杂。
5.4.4线性、非线性流水线
按流失线的各个功能段之间是否有反馈信号分类
线性流水线中,从输入到输出,每个功能段只允许经过一次,不存在反馈回路。
非线性流水线中存在反馈回路,从输入到输出过程中,某些功能段将数次通过流水线,这种流水线适合进行线性递归的运算。
5.5高级流水线技术
流水线技术已经是一种时间上的并行技术了,更高级流水线技术主要有两种:一种是多发射技术即增加在空间上并行技术;另一种是超流水线技术即划分更多的流水线功能段以适应更高的流水线主频来提高指令吞吐率。
5.5.1超标量流水线技术(动态多发射)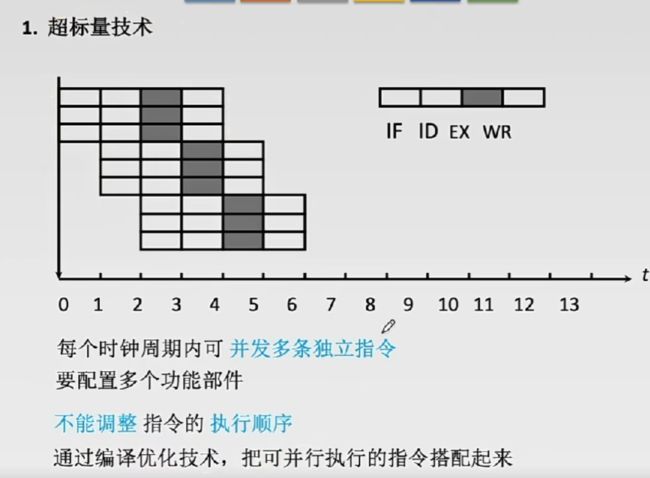
5.5.2超长指令字技术(静态多发射)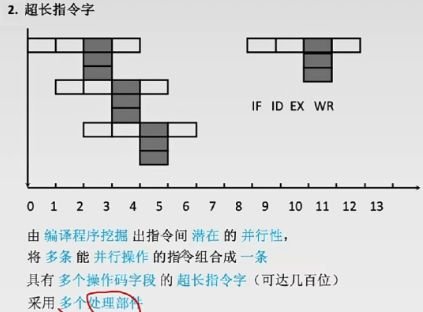
5.5.3超流水线技术
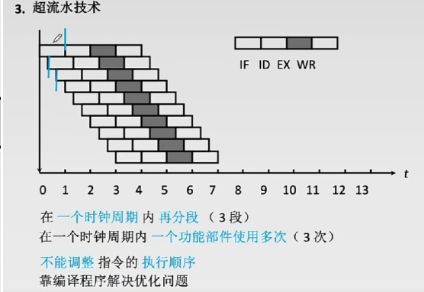
上图的时钟周期是原本的时钟周期,新的时钟周期是原来的三分之一,即提高了时钟频率。
流水线技术与超流水线技术没有本质的区别,CPI也是为1。超流水线技术只是划分了更多的功能段,将时钟周期变短。
超流水线技术虽然提高了CPU的主频,但是也带来了很大的副作用:
首先,细分后的每一个阶段都要在其后使用锁存器锁存,因此将一个阶段细分为N的子阶段并不能让单位时间减少到s/N, 而是s/N + d, 其中d为锁存器的反应时间。这实际上就是增加了多余的时间消耗。
其次,随着流水线级数的加深,一旦分支预测出现错误,会导致CPU中大量的指令作废,这样的消耗是十分巨大的。