【MySQL】查询优化
【MySQL】查询优化
- 1. 优化目的与目标
-
- 1.1 为什么要进行查询优化
- 1.1 MySQL优化目标
- 2. 优化流程及思路
-
- 2.1 调优时你需要关注哪些指标
- 2.1 合理监控
- 2.3 MySQL优化流程
- 2.4 SQL优化原则与方法
-
- 2.4.1 原则
- 2.4.2 方法
- 3. 原理剖析
-
- 3.1 B+ Tree index
- 3.2 InnoDB Table
- 3.3 索引检索过程
- 4. MySQL的行为
-
- 4.1 MySQL SQL执行过程
- 4.2 MySQL SQL执行顺序
- 4.3 MySQL优化器与执行计划
-
- 4.3.1 查询优化器
- 4.3.2 查询优化器工作过程
- 4.3.3 查看和干预执行计划
- 4.3.4 processlist
- 5. 常规优化策略
-
- 5.1 order by - 排序
-
- 5.1.1 order by 查询的两种情况
- 5.1.2 优化目标
- 5.1.3 filesort
- 5.2 Subquery - 子查询
- 5.3 limit - 分页查询
- 5.4 or/and condition - 条件查询
- 5.5 join - 连接
-
- 5.5.1 Nested-Loop Join 算法
- 5.5.2 Hash Join Optimization
- 5.5.3 关联字段索引
- 5.5.4 小表驱动原则
- 5.6 insert - 插入
1. 优化目的与目标
✓ 优化的目的是让资源发挥价值;
✓ SQL和索引是调优的关键,往往可以起到“四两拨千斤”的效果。
1.1 为什么要进行查询优化
- ✓ 提高资源利用率
- ✓ 避免短板效应
- ✓ 提高系统吞吐量
- ✓ 同时满足更多用户的在线需求
1.1 MySQL优化目标

2. 优化流程及思路
✓ 充分了解核心指标,并构建完备的监控体系,这是优化工作的前提;
✓ SQL优化的原则是减少数据访问及计算;
✓ 常用的优化方法主要是调整索引、改写SQL、干预执行计划。
2.1 调优时你需要关注哪些指标
- CPU 使用率
SQL 查询关键资源指标
数据扫描、显式计算
- IOPS
每秒 IO 请求次数
物理读写关键资源指标
- QPS/TPS
吞吐量
业务压力
- 会话数/活跃会话数
应用配置
执行效率
- InnoDB 逻辑读/物理读
反映整体查询效率的引擎指标
- 临时表
导致SQL执行效率下降的特殊行为
2.1 合理监控
知道了我们关注的指标,接下来就是定点监控,看看究竟是哪个/哪些指标影响了应用系统的性能,这样就可以定点排查问题,制定具体的优化策略与方法。

2.3 MySQL优化流程

2.4 SQL优化原则与方法
2.4.1 原则
- 减少访问量:
数据存取是数据库系统最核心功能,所以IO是数据库系统中最容易出现性能瓶颈,减少SQL访问IO量是SQL优化的第一步;数据块的逻辑读也是产生CPU开销的因素之一。
减少访问量的方法:创建合适的索引、减少不必访问的列、使用索引覆盖、语句改写。
- 减少计算操作:
计算操作进行优化也是SQL优化的重要方向。SQL中排序、分组、多表连接操作等计算操作都是CPU消耗的大户。
减少SQL计算操作的方法:排序列加入索引、适当的列冗余、SQL拆分、计算功能拆分。
2.4.2 方法
- 创建索引减少扫描量
- 调整索引减少计算量
- 索引覆盖(减少不必访问的列,避免回表查询)
- SQL改写
- 干预执行计划
3. 原理剖析
✓ InnoDB 的表是典型的 IOT,数据本身是 B+ tree 索引的叶节点。
3.1 B+ Tree index

3.2 InnoDB Table

3.3 索引检索过程
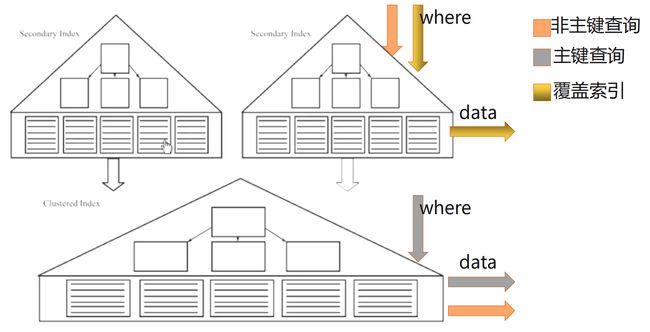
4. MySQL的行为
✓ 扫描二级索引可以直接获取数据,或者返回主键 id;
✓ 优化器是数据库的大脑,我们要了解优化器,并观测以及干预 MySQL 的行为。
4.1 MySQL SQL执行过程

- 客户提交一条语句
- 先在查询缓存查看是否存在对应的缓存数据,如有则直接返回(一般有的可能性极小,因此一般建议关闭查询缓存);
- 交给解析器处理,解析器会将提交的语句生成一个解析树;
- 预处理器会处理解析树,形成新的解析树,这一阶段存在一些SQL改写的过程;
- 改写后的解析树提交给查询优化器,查询优化器生成执行计划;
- 执行计划交由执行引擎调用存储引擎接口,完成执行过程,这里要注意,MySQL的Server层和Engine层是分离的。
- 最终的结果由执行引擎返回给客户端,如果开启查询缓存的话,则会缓存。
4.2 MySQL SQL执行顺序
(9) SELECT
(10) DISTINCT column,
(6) AGG FUNC(column or expression), ...
(1) FROM left tab1
(3) JOIN right tab2
(2) ON tab1.column = tab2.column
(4) WHERE constraint_expression
(5) GROUP BY column
(7) WITH CUBE ROLLUP
(8) HAVING constraint_expression
(11) ORDER BY column ASC|DESC
(12) LIMIT count OFFSET count;
4.3 MySQL优化器与执行计划
4.3.1 查询优化器
- 负责生成 SQL 语句的有效执行计划的数据库组件
- 优化器是数据库的核心价值所在,它是数据库的“大脑”
- 优化SQL,某种意义上就是理解优化器的行为
- 优化的依据是执行成本(CBO)
- 优化器工作的前提是了解数据,工作的目的是解析SQL,生成执行计划
4.3.2 查询优化器工作过程

- 词法分析、语法分析、语义检查;
- 预处理阶段(查询改写等);
- 查询优化阶段(可详细划分为逻辑优化、物理优化两部分);
- 查询优化器优化依据,来自于代价估算器估算结果(它会调用统计信息作为计算依据);
- 交由执行器执行。
4.3.3 查看和干预执行计划
- 执行计划
➢ explain [extended] SQL_Statement

- 优化器开关
➢ show variables like ‘optimizer_switch’

4.3.4 processlist
show [full] processlist
information_schema.processlist
copy to tmp table:出现在某些alter table语句的copy table操作
Copying to tmp table on disk:由于临时结果集大于tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存
converting HEAP to MyISAM:线程正在转换内部MEMORY临时表到磁盘MyISAM临时表
Creating sort index:正在使用内部临时表处理select查询
Sorting index:磁盘排序操作的一个过程
Sending data:正在处理SELECT查询的记录,同时正在把结果发送给客户端
Waiting for table metadata lock: 等待元数据锁
…
5. 常规优化策略
5.1 order by - 排序
5.1.1 order by 查询的两种情况
Using index:MySQL 直接通过索引返回有序记录,不需要额外的排序操作,操作效率较高;
Using filesort:无法只通过索引获取有序结果集,需要额外的排序,某些特殊情况下,会出现 Using temporary。
5.1.2 优化目标
尽量通过索引来避免额外的排序,减少CPU资源的消耗。
✓ where 条件和 order by 使用相同的索引
✓ order by 的顺序和索引顺序相同
✓ order by 的字段同为升序或降序
注意: 当 where 条件中的过滤字段为覆盖索引的前缀列,而 order by 字段是第二个索引列时,只有 where 条件是 const 匹配时,才可以通过索引消除排序,而 between…and 或 >?、
5.1.3 filesort
当无法避免filesort操作时,优化思路就是让filesort的操作更快。
- 排序算法:
✓ 两次扫描算法: 两次访问数据,第一步获取排序字段的行指针信息,在内存中排序,第二步根据行指针获取记录;
✓ 一次扫描算法: 一次性取出满足条件的所有记录,在排序区中排序后输出结果集,是采用空间换时间的方式。
注: 需要排序的字段总长度越小,越趋向于第二种扫描算法,MySQL通过 max_length_for_sort_data 参数的值来进行参考选择。
- 优化策略:
✓ 适当调大 max_length_for_sort_data 这个参数的值,让优化器更倾向于选择第二种扫描算法;
✓ 只使用必要的字段,不要使用 select * 的写法
✓ 适当加大 sort_buffer_size 这个参数的值,避免磁盘排序的出现(线程参数,不要设置过大)
5.2 Subquery - 子查询
➢ 子查询会用到临时表,需尽量避免
➢ 可以使用效率更高的 join 查询来替代
- 优化策略:
✓ 等价改写、反嵌套
如下SQL:
select * from customer where customer_id not in (select customer_id from payment);
改写成:
select * from customer a left join payment b on a.customer_id = b.customer_id where b.customer_id is null;
5.3 limit - 分页查询
➢ 分页查询,就是将过多的结果在有限的界面上分好多页来显示;
➢ 其实质是每次查询只返回有限行,翻页一次执行一次。
- 优化目标:
✓ 消除排序
✓ 避免扫描到大量不需要的记录
SQL场景(film_id为主键):
# 此时 MySQL 排序出前 10020 条记录后仅仅需要返回第 10001 到 10020 条记录,前 10000 条记录造成额外的代价消耗
select film_id,description from film order by title limit 10000,20;
- 优化策略:
优化策略1:覆盖索引:
alter table film add index idx_lmtest(title,description);
✓ 记录直接从索引中获取,效率最高
✓ 仅适合查询字段较少的情况
优化策略2:SQL改写
select a.film_id,a.description from film a inner join (select film_id from film order by title limit 1000,20) b on a.film_id=b.film_id;
✓ 优化的前提是 title 字段有索引
✓ 思路是从索引中取出 20 条满足条件记录的主键值,然后回表获取记录
5.4 or/and condition - 条件查询
- and 结果集为关键字前后过滤结果的交集
- or 结果集为关键字前后分别查询的并集
- and 条件可以在前一个条件过滤基础上过滤
- or 条件被处理为 UNION,相当于两个单独条件的查询
- 复合索引对于 or 条件相当于一个单列索引
处理策略:
✓ and 子句多个条件中拥有一个过滤性较高的索引即可
✓ or 条件前后字段均要创建索引
✓ 为最常用的 and 组合条件创建复合索引
5.5 join - 连接
5.5.1 Nested-Loop Join 算法
嵌套循环连接算法
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions, send to client
}
}
}
5.5.2 Hash Join Optimization
Hash Join

5.5.3 关联字段索引
✓ 每层内部循环仅获取需要关心的数据;
✓ 引申算法:Bloack Nested-Loop。
添加索引前:
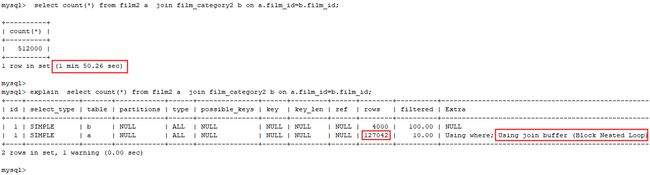
添加索引后:

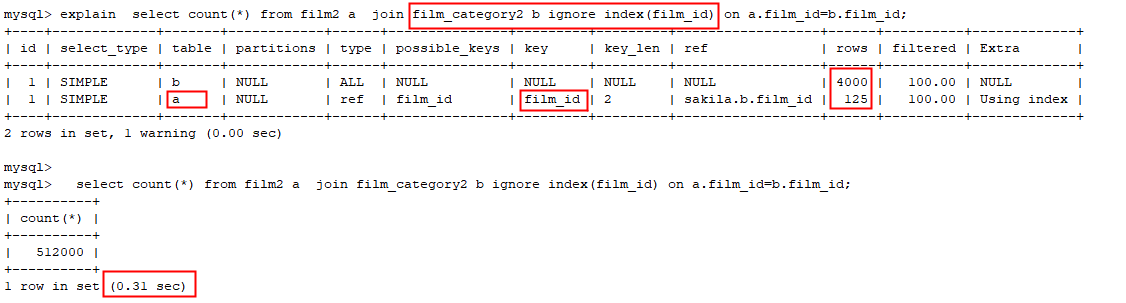
5.5.4 小表驱动原则
✓ 减少循环次数;
✓ 小表:返回结果集较少的表。
忽略b表的索引,使b表作为驱动表:
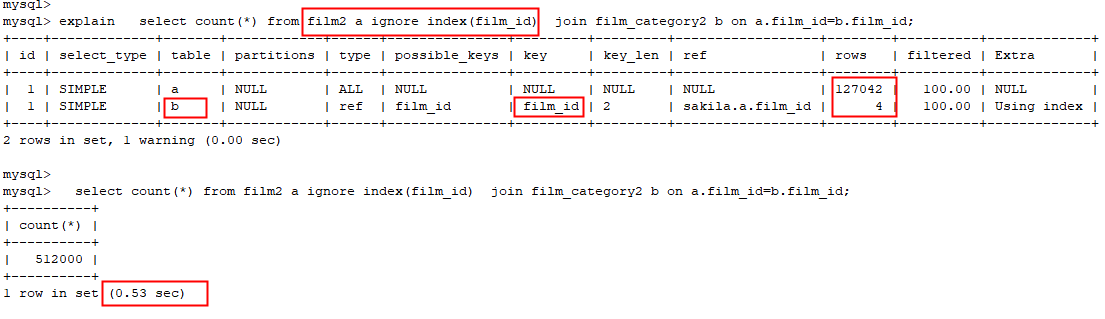
忽略a表的索引,使a表作为驱动表:
5.6 insert - 插入
- 减少交互次数
-- 如批量插入语句:
insert into test values(1,2,3);
insert into test values(4,5,6);
insert into test values(7,8,9);
...
-- 可改写为如下形式:
insert into test values(1,2,3),(4,5,6),(7,8,9) ...;
- 文本装载方式
通过 LOAD DATA INFILE 句式,从文本装载数据,通常比 insert 语句快 20 倍。