Kafka 核心源码解读【五】--延迟操作模块
文章目录
-
- 1 TimingWheel:探究Kafka定时器背后的高效时间轮算法
-
- 1.1 时间轮简介
- 1.2 源码层级关系
- 1.3 时间轮各个类源码定义
-
- 1.3.1 TimerTask 类
- 1.3.2 TimerTaskEntry 类
- 1.3.3 TimerTaskList 类
- 1.3.4 TimingWheel 类
- 1.4 总结
- 2 DelayedOperation:Broker是怎么延时处理请求的?
-
- 2.1 Timer 接口及 SystemTimer
-
- 2.1.1 Timer 接口
- 2.1.2 SystemTimer 类
- 2.2 DelayedOperation 类
- 2.3 DelayedOperationPurgatory 类
- 2.4 总结
1 TimingWheel:探究Kafka定时器背后的高效时间轮算法
延时请求(Delayed Operation),也称延迟请求,是指因未满足条件而暂时无法被处理的 Kafka 请求。举个例子,配置了 acks=all 的生产者发送的请求可能一时无法完成,因为 Kafka 必须确保 ISR 中的所有副本都要成功响应这次写入。因此,通常情况下,这些请求没法被立即处理。只有满足了条件或发生了超时,Kafka 才会把该请求标记为完成状态。这就是所谓的延时请求。
今天,我们的重点是弄明白请求被延时处理的机制——分层时间轮算法。
时间轮的应用范围非常广。很多操作系统的定时任务调度(如 Crontab)以及通信框架(如 Netty 等)都利用了时间轮的思想。几乎所有的时间任务调度系统都是基于时间轮算法的。Kafka 应用基于时间轮算法管理延迟请求的代码简洁精炼,而且和业务逻辑代码完全解耦,你可以从 0 到 1 地照搬到你自己的项目工程中。
1.1 时间轮简介
在开始介绍时间轮之前,我想先请你思考这样一个问题:“如果是你,你会怎么实现 Kafka 中的延时请求呢?”针对这个问题,我的第一反应是使用 Java 的 DelayQueue。毕竟,这个类是 Java 天然提供的延时队列,非常适合建模延时对象处理。实际上,Kafka 的第一版延时请求就是使用 DelayQueue 做的。但是,DelayQueue 有一个弊端:它插入和删除队列元素的时间复杂度是 O(logN)。对于 Kafka 这种非常容易积攒几十万个延时请求的场景来说,该数据结构的性能是瓶颈。当然,这一版的设计还有其他弊端,比如,它在清除已过期的延迟请求方面不够高效,可能会出现内存溢出的情形。后来,社区改造了延时请求的实现机制,采用了基于时间轮的方案。
时间轮有简单时间轮(Simple Timing Wheel)和分层时间轮(Hierarchical Timing Wheel)两类。两者各有利弊,也都有各自的使用场景。Kafka 采用的是分层时间轮,这是我们重点学习的内容。
“时间轮”的概念稍微有点抽象,我用一个生活中的例子,来帮助你建立一些初始印象。想想我们生活中的手表。手表由时针、分针和秒针组成,它们各自有独立的刻度,但又彼此相关:秒针转动一圈,分针会向前推进一格;分针转动一圈,时针会向前推进一格。这就是典型的分层时间轮。
和手表不太一样的是,Kafka 自己有专门的术语。在 Kafka 中,手表中的“一格”叫“一个桶(Bucket)”,而“推进”对应于 Kafka 中的“滴答”,也就是 tick。后面你在阅读源码的时候,会频繁地看到 Bucket、tick 字眼,你可以把它们理解成手表刻度盘面上的“一格”和“向前推进”的意思。除此之外,每个 Bucket 下也不是白板一块,它实际上是一个双向循环链表(Doubly Linked Cyclic List),里面保存了一组延时请求。我先用一张图帮你理解下双向循环链表。
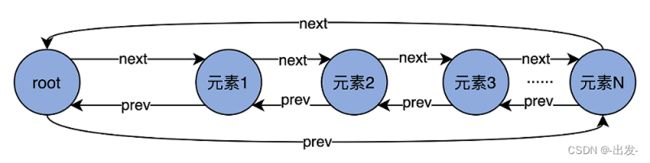
图中的每个节点都有一个 next 和 prev 指针,分别指向下一个元素和上一个元素。Root 是链表的头部节点,不包含任何实际数据。它的 next 指针指向链表的第一个元素,而 prev 指针指向最后一个元素。
由于是双向链表结构,因此,代码能够利用 next 和 prev 两个指针快速地定位元素,因此,在 Bucket 下插入和删除一个元素的时间复杂度是 O(1)。当然,双向链表要求同时保存两个指针数据,在节省时间的同时消耗了更多的空间。在算法领域,这是典型的用空间去换时间的优化思想。
1.2 源码层级关系
在 Kafka 中,具体是怎么应用分层时间轮实现请求队列的呢?
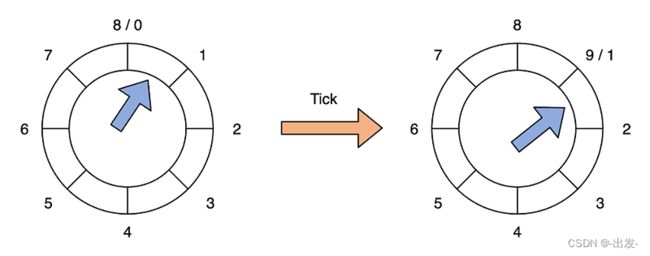
图中的时间轮共有两个层级,分别是 Level 0 和 Level 1。每个时间轮有 8 个 Bucket,每个 Bucket 下是一个双向循环链表,用来保存延迟请求。
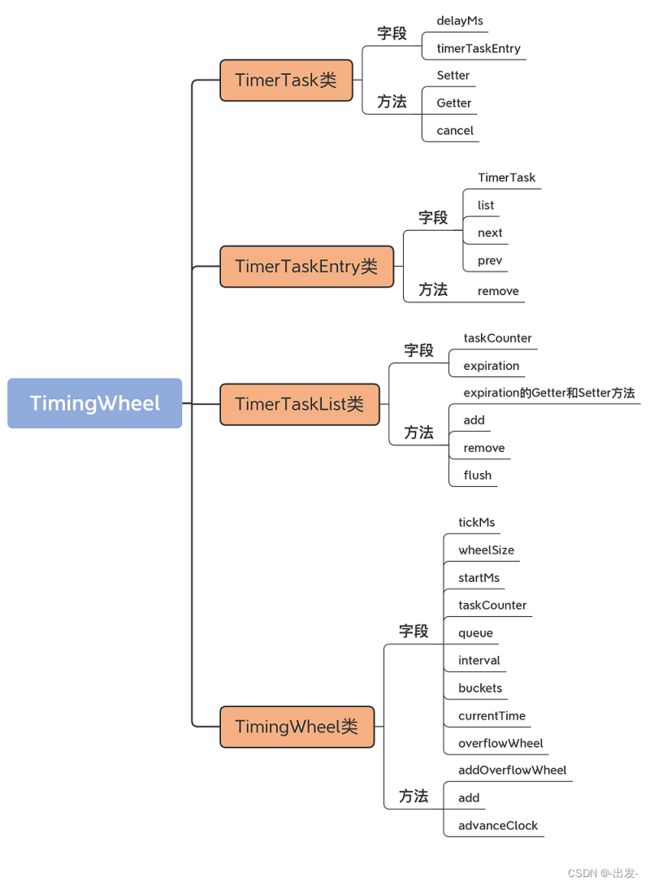
在 Kafka 源码中,时间轮对应 utils.timer 包下的 TimingWheel 类,每个 Bucket 下的链表对应 TimerTaskList 类,链表元素对应 TimerTaskEntry 类,而每个链表元素里面保存的延时任务对应 TimerTask。
在这些类中,TimerTaskEntry 与 TimerTask 是 1 对 1 的关系,TimerTaskList 下包含多个 TimerTaskEntry,TimingWheel 包含多个 TimerTaskList。我画了一张 UML 图,帮助你理解这些类之间的对应关系:

1.3 时间轮各个类源码定义
掌握了这些基础知识,下面我就结合这些源码,来解释下延迟请求是如何被这套分层时间轮管理的。根据调用关系,我采用自底向上的方法给出它们的定义。
1.3.1 TimerTask 类
首先是 TimerTask 类。该类位于 utils.timer 包下的 TimerTask.scala 文件中。它的代码只有几十行,非常容易理解。
trait TimerTask extends Runnable {
val delayMs: Long // 通常是request.timeout.ms参数值
// 每个TimerTask实例关联一个TimerTaskEntry
// 就是说每个定时任务需要知道它在哪个Bucket链表下的哪个链表元素上
private[this] var timerTaskEntry: TimerTaskEntry = null
// 取消定时任务,原理就是将关联的timerTaskEntry置空
def cancel(): Unit = {
synchronized {
if (timerTaskEntry != null) timerTaskEntry.remove()
timerTaskEntry = null
}
}
// 关联timerTaskEntry,原理是给timerTaskEntry字段赋值
private[timer] def setTimerTaskEntry(entry: TimerTaskEntry): Unit = {
synchronized {
// if this timerTask is already held by an existing timer task entry,
// we will remove such an entry first.
if (timerTaskEntry != null && timerTaskEntry != entry)
timerTaskEntry.remove()
timerTaskEntry = entry
}
}
// 获取关联的timerTaskEntry实例
private[timer] def getTimerTaskEntry: TimerTaskEntry = timerTaskEntry
}
从代码可知,TimerTask 是一个 Scala 接口(Trait)。每个 TimerTask 都有一个 delayMs 字段,表示这个定时任务的超时时间。通常来说,这就是客户端参数 request.timeout.ms 的值。这个类还绑定了一个 timerTaskEntry 字段,因为,每个定时任务都要知道,它存放在哪个 Bucket 链表下的哪个链表元素上。
既然绑定了这个字段,就要提供相应的 Setter 和 Getter 方法。Getter 方法仅仅是返回这个字段而已,Setter 方法要稍微复杂一些。在给 timerTaskEntry 赋值之前,它必须要先考虑这个定时任务是否已经绑定了其他的 timerTaskEntry,如果是的话,就必须先取消绑定。另外,Setter 的整个方法体必须由 monitor 锁保护起来,以保证线程安全性。
这个类还有个 cancel 方法,用于取消定时任务。原理也很简单,就是将关联的 timerTaskEntry 置空。也就是说,把定时任务从链表上摘除。
总之,TimerTask 建模的是 Kafka 中的定时任务。接下来,我们来看 TimerTaskEntry 是如何承载这个定时任务的,以及如何在链表中实现双向关联。
1.3.2 TimerTaskEntry 类
如前所述,TimerTaskEntry 表征的是 Bucket 链表下的一个元素。它的主要代码如下:
private[timer] class TimerTaskEntry(val timerTask: TimerTask, val expirationMs: Long) extends Ordered[TimerTaskEntry] {
@volatile
var list: TimerTaskList = null // 绑定的Bucket链表实例
var next: TimerTaskEntry = null // next指针
var prev: TimerTaskEntry = null // prev指针
// 关联给定的定时任务
// if this timerTask is already held by an existing timer task entry,
// setTimerTaskEntry will remove it.
if (timerTask != null) timerTask.setTimerTaskEntry(this)
// 关联定时任务是否已经被取消了
def cancelled: Boolean = {
timerTask.getTimerTaskEntry != this
}
// 从Bucket链表中移除自己
def remove(): Unit = {
var currentList = list
// If remove is called when another thread is moving the entry from a task entry list to another,
// this may fail to remove the entry due to the change of value of list. Thus, we retry until the list becomes null.
// In a rare case, this thread sees null and exits the loop, but the other thread insert the entry to another list later.
while (currentList != null) {
currentList.remove(this)
currentList = list
}
}
...
}
该类定义了 TimerTask 类字段,用来指定定时任务,同时还封装了一个过期时间戳字段,这个字段值定义了定时任务的过期时间。举个例子,假设有个 PRODUCE 请求在当前时间 1 点钟被发送到 Broker,超时时间是 30 秒,那么,该请求必须在 1 点 30 秒之前完成,否则将被视为超时。这里的 1 点 30 秒,就是 expirationMs 值。
除了 TimerTask 类字段,该类还定义了 3 个字段:list、next 和 prev。它们分别对应于 Bucket 链表实例以及自身的 next、prev 指针。注意,list 字段是 volatile 型的,这是因为,Kafka 的延时请求可能会被其他线程从一个链表搬移到另一个链表中,因此,为了保证必要的内存可见性,代码声明 list 为 volatile。
该类的方法代码都很直观,你可以看下我写的代码注释。这里我重点解释一下 remove 方法的实现原理。remove 的逻辑是将 TimerTask 自身从双向链表中移除掉,因此,代码调用了 TimerTaskList 的 remove 方法来做这件事。那这里就有一个问题:“怎么算真正移除掉呢?”其实,这是根据“TimerTaskEntry 的 list 是否为空”来判断的。一旦置空了该字段,那么,这个 TimerTaskEntry 实例就变成了“孤儿”,不再属于任何一个链表了。从这个角度来看,置空就相当于移除的效果。
需要注意的是,置空这个动作是在 TimerTaskList 的 remove 中完成的,而这个方法可能会被其他线程同时调用,因此,上段代码使用了 while 循环的方式来确保 TimerTaskEntry 的 list 字段确实被置空了。这样,Kafka 才能安全地认为此链表元素被成功移除。
1.3.3 TimerTaskList 类
说完了 TimerTask 和 TimerTaskEntry,就轮到链表类 TimerTaskList 上场了。我们先看它的定义:
private[timer] class TimerTaskList(taskCounter: AtomicInteger) extends Delayed {
private[this] val root = new TimerTaskEntry(null, -1)
root.next = root
root.prev = root
private[this] val expiration = new AtomicLong(-1L)
......
}
TimerTaskList 实现了刚刚那张图所展示的双向循环链表。它定义了一个 Root 节点,同时还定义了两个字段:
- taskCounter,用于标识当前这个链表中的总定时任务数;
- expiration,表示这个链表所在 Bucket 的过期时间戳。
就像我前面说的,每个 Bucket 对应于手表表盘上的一格。它有起始时间和结束时间,因而也就有时间间隔的概念,即“结束时间 - 起始时间 = 时间间隔”。同一层的 Bucket 的时间间隔都是一样的。只有当前时间越过了 Bucket 的起始时间,这个 Bucket 才算是过期。而这里的起始时间,就是代码中 expiration 字段的值。
除了定义的字段之外,TimerTaskList 类还定义一些重要的方法,比如 expiration 的 Getter 和 Setter 方法、add、remove 和 flush 方法。我们先看 expiration 的 Getter 和 Setter 方法。
def setExpiration(expirationMs: Long): Boolean = {
expiration.getAndSet(expirationMs) != expirationMs
}
def getExpiration: Long = expiration.get
我重点解释下 Setter 方法。代码使用了 AtomicLong 的 CAS 方法 getAndSet 原子性地设置了过期时间戳,之后将新过期时间戳和旧值进行比较,看看是否不同,然后返回结果。
这里为什么要比较新旧值是否不同呢?这是因为,目前 Kafka 使用一个 DelayQueue 统一管理所有的 Bucket,也就是 TimerTaskList 对象。随着时钟不断向前推进,原有 Bucket 会不断地过期,然后失效。当这些 Bucket 失效后,源码会重用这些 Bucket。重用的方式就是重新设置 Bucket 的过期时间,并把它们加回到 DelayQueue 中。这里进行比较的目的,就是用来判断这个 Bucket 是否要被插入到 DelayQueue。
此外,TimerTaskList 类还提供了 add 和 remove 方法,分别实现将给定定时任务插入到链表、从链表中移除定时任务的逻辑。这两个方法的主体代码基本上就是我们在数据结构课上学过的链表元素插入和删除操作,所以这里我就不具体展开讲了。你可以将这些代码和数据结构书中的代码比对下,看看它们是不是长得很像。
def add(timerTaskEntry: TimerTaskEntry): Unit = {
var done = false
while (!done) {
// 在添加之前尝试移除该定时任务,保证该任务没有在其他链表中
timerTaskEntry.remove()
synchronized {
timerTaskEntry.synchronized {
if (timerTaskEntry.list == null) {
val tail = root.prev
timerTaskEntry.next = root
timerTaskEntry.prev = tail
timerTaskEntry.list = this
// 把timerTaskEntry添加到链表末尾
tail.next = timerTaskEntry
root.prev = timerTaskEntry
taskCounter.incrementAndGet()
done = true
}
}
}
}
}
def remove(timerTaskEntry: TimerTaskEntry): Unit = {
synchronized {
timerTaskEntry.synchronized {
if (timerTaskEntry.list eq this) {
timerTaskEntry.next.prev = timerTaskEntry.prev
timerTaskEntry.prev.next = timerTaskEntry.next
timerTaskEntry.next = null
timerTaskEntry.prev = null
timerTaskEntry.list = null
taskCounter.decrementAndGet()
}
}
}
}
最后,我们看看 flush 方法。它的代码如下:
// 清空链表中的所有元素
def flush(f: TimerTaskEntry => Unit): Unit = {
synchronized {
// 找到链表第一个元素
var head = root.next
while (head ne root) {
// 移除遍历到的链表元素
remove(head)
// 执行传入参数f的逻辑
f(head)
head = root.next
}
// 清空过期时间设置
expiration.set(-1L)
}
}
基本上,flush 方法是清空链表中的所有元素,并对每个元素执行指定的逻辑。该方法用于将高层次时间轮 Bucket 上的定时任务重新插入回低层次的 Bucket 中。具体为什么要这么做,下节课我会给出答案,现在你只需要知道它的大致作用就可以了。
1.3.4 TimingWheel 类
最后,我们再来看下 TimingWheel 类的代码。先看定义:
private[timer] class TimingWheel(tickMs: Long, wheelSize: Int, startMs: Long, taskCounter: AtomicInteger, queue: DelayQueue[TimerTaskList]) {
private[this] val interval = tickMs * wheelSize
private[this] val buckets = Array.tabulate[TimerTaskList](wheelSize) { _ => new TimerTaskList(taskCounter) }
private[this] var currentTime = startMs - (startMs % tickMs)
@volatile private[this] var overflowWheel: TimingWheel = null
...
}
每个 TimingWheel 对象都定义了 9 个字段。这 9 个字段都非常重要,每个字段都是分层时间轮的重要属性。因此,我来逐一介绍下。
-
tickMs:滴答一次的时长,类似于手表的例子中向前推进一格的时间。对于秒针而言,tickMs 就是 1 秒。同理,分针是 1 分,时针是 1 小时。在 Kafka 中,第 1 层时间轮的 tickMs 被固定为 1 毫秒,也就是说,向前推进一格 Bucket 的时长是 1 毫秒。
-
wheelSize:每一层时间轮上的 Bucket 数量。第 1 层的 Bucket 数量是 20。
-
startMs:时间轮对象被创建时的起始时间戳。
-
taskCounter:这一层时间轮上的总定时任务数。
-
queue:将所有 Bucket 按照过期时间排序的延迟队列。随着时间不断向前推进,Kafka 需要依靠这个队列获取那些已过期的 Bucket,并清除它们。
-
interval:这层时间轮总时长,等于滴答时长乘以 wheelSize。以第 1 层为例,interval 就是 20 毫秒。由于下一层时间轮的滴答时长就是上一层的总时长,因此,第 2 层的滴答时长就是 20 毫秒,总时长是 400 毫秒,以此类推。
-
buckets:时间轮下的所有 Bucket 对象,也就是所有 TimerTaskList 对象。
-
currentTime:当前时间戳,只是源码对它进行了一些微调整,将它设置成小于当前时间的最大滴答时长的整数倍。举个例子,假设滴答时长是 20 毫秒,当前时间戳是 123 毫秒,那么,currentTime 会被调整为 120 毫秒。
-
overflowWheel:Kafka 是按需创建上层时间轮的。这也就是说,当有新的定时任务到达时,会尝试将其放入第 1 层时间轮。如果第 1 层的 interval 无法容纳定时任务的超时时间,就现场创建并配置好第 2 层时间轮,并再次尝试放入,如果依然无法容纳,那么,就再创建和配置第 3 层时间轮,以此类推,直到找到适合容纳该定时任务的第 N 层时间轮。
由于每层时间轮的长度都是倍增的,因此,代码并不需要创建太多层的时间轮,就足以容纳绝大部分的延时请求了。举个例子,目前 Clients 端默认的请求超时时间是 30 秒,按照现在代码中的 wheelSize=20 进行倍增,只需要 4 层时间轮,就能容纳 160 秒以内的所有延时请求了。
说完了类声明,我们再来学习下 TimingWheel 中定义的 3 个方法:addOverflowWheel、add 和 advanceClock。就像我前面说的,TimingWheel 类字段 overflowWheel 的创建是按需的。每当需要一个新的上层时间轮时,代码就会调用 addOverflowWheel 方法。我们看下它的代码:
private[this] def addOverflowWheel(): Unit = {
synchronized {
// 只有之前没有创建上层时间轮方法才会继续
if (overflowWheel == null) {
overflowWheel = new TimingWheel(
// 创建新的TimingWheel实例
// 滴答时长tickMs等于下层时间轮总时长
// 每层的轮子数都是相同的
tickMs = interval,
wheelSize = wheelSize,
startMs = currentTime,
taskCounter = taskCounter,
queue
)
}
}
}
这个方法就是创建一个新的 TimingWheel 实例,也就是创建上层时间轮。所用的滴答时长等于下层时间轮总时长,而每层的轮子数都是相同的。创建完成之后,代码将新创建的实例赋值给 overflowWheel 字段。至此,方法结束。
下面,我们再来学习下 add 和 advanceClock 方法。首先是 add 方法,代码及其注释如下:
def add(timerTaskEntry: TimerTaskEntry): Boolean = {
// 获取定时任务的过期时间戳
val expiration = timerTaskEntry.expirationMs
// 如果该任务已然被取消了,则无需添加,直接返回
if (timerTaskEntry.cancelled) {
false
// 如果该任务超时时间已过期
} else if (expiration < currentTime + tickMs) {
false
// 如果该任务超时时间在本层时间轮覆盖时间范围内
} else if (expiration < currentTime + interval) {
val virtualId = expiration / tickMs
// 计算要被放入到哪个Bucket中
val bucket = buckets((virtualId % wheelSize.toLong).toInt)
// 添加到Bucket中
bucket.add(timerTaskEntry)
// 设置Bucket过期时间
// 如果该时间变更过,说明Bucket是新建或被重用,将其加回到DelayQueue
if (bucket.setExpiration(virtualId * tickMs)) {
queue.offer(bucket)
}
true
// 本层时间轮无法容纳该任务,交由上层时间轮处理
} else {
// 按需创建上层时间轮
if (overflowWheel == null) addOverflowWheel()
// 加入到上层时间轮中
overflowWheel.add(timerTaskEntry)
}
}
我结合一张图来解释下这个 add 方法要做的事情:
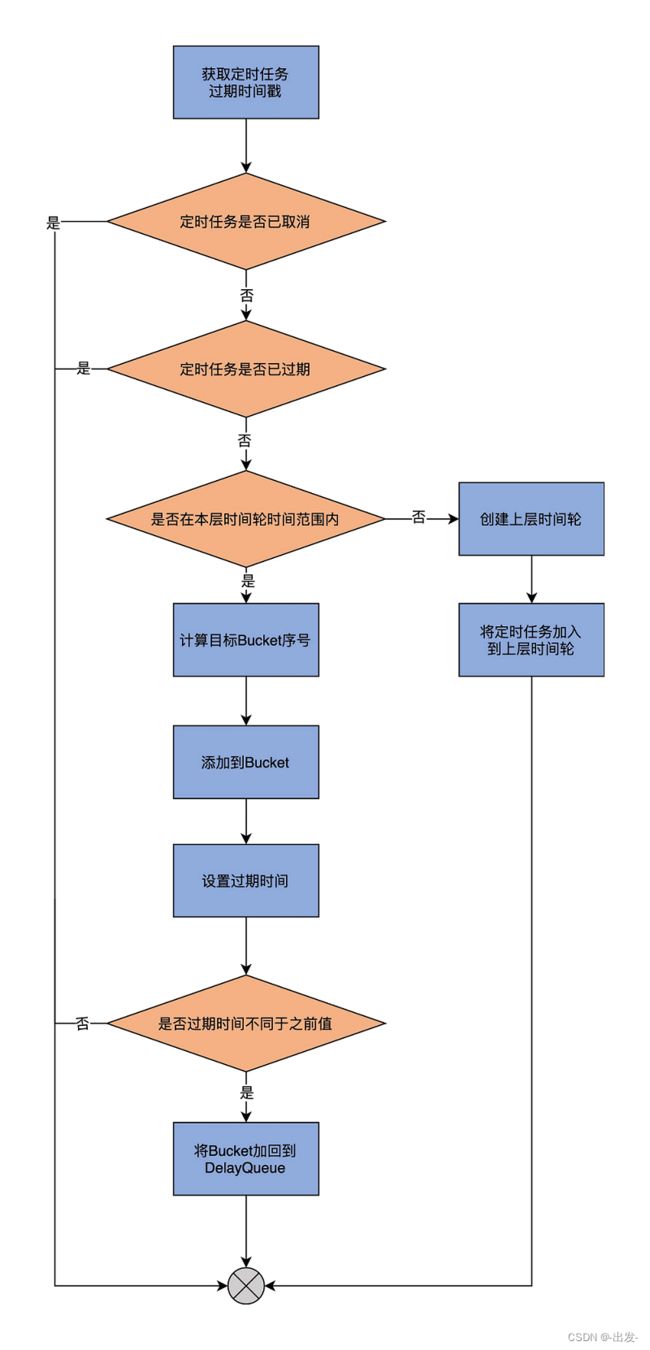
方法的第 1 步是获取定时任务的过期时间戳。所谓过期时间戳,就是这个定时任务过期时的时点。
第 2 步是看定时任务是否已被取消。如果已经被取消,则无需加入到时间轮中。如果没有被取消,就接着看这个定时任务是否已经过期。如果过期了,自然也不用加入到时间轮中。如果没有过期,就看这个定时任务的过期时间是否能够被涵盖在本层时间轮的时间范围内。如果可以,则进入到下一步。
第 3 步,首先计算目标 Bucket 序号,也就是这个定时任务需要被保存在哪个 TimerTaskList 中。我举个实际的例子,来说明一下如何计算目标 Bucket。前面说过了,第 1 层的时间轮有 20 个 Bucket,每个滴答时长是 1 毫秒。那么,第 2 层时间轮的滴答时长应该就是 20 毫秒,总时长是 400 毫秒。第 2 层第 1 个 Bucket 的时间范围应该是[20,40),第 2 个 Bucket 的时间范围是[40,60),依次类推。假设现在有个延时请求的超时时间戳是 237,那么,它就应该被插入到第 11 个 Bucket 中。在确定了目标 Bucket 序号之后,代码会将该定时任务添加到这个 Bucket 下,同时更新这个 Bucket 的过期时间戳。在刚刚的那个例子中,第 11 号 Bucket 的起始时间就应该是小于 237 的最大的 20 的倍数,即 220。
第 4 步,如果这个 Bucket 是首次插入定时任务,那么,还同时要将这个 Bucket 加入到 DelayQueue 中,方便 Kafka 轻松地获取那些已过期 Bucket,并删除它们。如果定时任务的过期时间无法被涵盖在本层时间轮中,那么,就按需创建上一层时间戳,然后在上一层时间轮上完整地执行刚刚所说的所有逻辑。
说完了 add 方法,我们看下 advanceClock 方法。顾名思义,它就是向前驱动时钟的方法。代码如下:
def advanceClock(timeMs: Long): Unit = {
// 向前驱动到的时点要超过Bucket的时间范围,才是有意义的推进,否则什么都不做
// 更新当前时间currentTime到下一个Bucket的起始时点
if (timeMs >= currentTime + tickMs) {
currentTime = timeMs - (timeMs % tickMs)
// 同时尝试为上一层时间轮做向前推进动作
if (overflowWheel != null) overflowWheel.advanceClock(currentTime)
}
}
参数 timeMs 表示要把时钟向前推动到这个时点。向前驱动到的时点必须要超过 Bucket 的时间范围,才是有意义的推进,否则什么都不做,毕竟它还在 Bucket 时间范围内。相反,一旦超过了 Bucket 覆盖的时间范围,代码就会更新当前时间 currentTime 到下一个 Bucket 的起始时点,同时递归地为上一层时间轮做向前推进动作。推进时钟的动作是由 Kafka 后台专属的 Reaper 线程发起的。
今天,我反复提到了删除过期 Bucket,这个操作是由这个 Reaper 线程执行的。下节课,我们会提到这个 Reaper 线程。
1.4 总结
今天,我简要介绍了时间轮机制,并结合代码重点讲解了分层时间轮在 Kafka 中的代码实现。Kafka 正是利用这套分层时间轮机制实现了对于延迟请求的处理。在源码层级上,Kafka 定义了 4 个类来构建整套分层时间轮体系。
- TimerTask 类:建模 Kafka 延时请求。它是一个 Runnable 类,Kafka 使用一个单独线程异步添加延时请求到时间轮。
- TimerTaskEntry 类:建模时间轮 Bucket 下延时请求链表的元素类型,封装了 TimerTask 对象和定时任务的过期时间戳信息。
- TimerTaskList 类:建模时间轮 Bucket 下的延时请求双向循环链表,提供 O(1) 时间复杂度的请求插入和删除。
- TimingWheel 类:建模时间轮类型,统一管理下辖的所有 Bucket 以及定时任务。
在下一讲中,我们将继续学习 Kafka 延时请求,以及管理它们的 DelayedOperation 家族的源码。只有了解了 DelayedOperation 及其具体实现子类的代码,我们才能完整地了解,当请求不能被及时处理时,Kafka 是如何应对的。
2 DelayedOperation:Broker是怎么延时处理请求的?
上节课,我们学习了分层时间轮在 Kafka 中的实现。既然是分层时间轮,那就说明,源码中构造的时间轮是有多个层次的。每一层所表示的总时长,等于该层 Bucket 数乘以每个 Bucket 涵盖的时间范围。另外,该总时长自动成为下一层单个 Bucket 所覆盖的时间范围。
举个例子,目前,Kafka 第 1 层的时间轮固定时长是 20 毫秒(interval),即有 20 个 Bucket(wheelSize),每个 Bucket 涵盖 1 毫秒(tickMs)的时间范围。第 2 层的总时长是 400 毫秒,同样有 20 个 Bucket,每个 Bucket 20 毫秒。依次类推,那么第 3 层的时间轮时长就是 8 秒,因为这一层单个 Bucket 的时长是 400 毫秒,共有 20 个 Bucket。
基于这种设计,每个延迟请求需要根据自己的超时时间,来决定它要被保存于哪一层时间轮上。我们假设在 t=0 时创建了第 1 层的时间轮,那么,该层第 1 个 Bucket 保存的延迟请求就是介于[0,1)之间,第 2 个 Bucket 保存的是介于[1,2) 之间的请求。现在,如果有两个延迟请求,超时时刻分别在 18.5 毫秒和 123 毫秒,那么,第 1 个请求就应该被保存在第 1 层的第 19 个 Bucket(序号从 1 开始)中,而第 2 个请求,则应该被保存在第 2 层时间轮的第 6 个 Bucket 中。
这基本上就是 Kafka 中分层时间轮的实现原理。Kafka 不断向前推动各个层级的时间轮的时钟,按照时间轮的滴答时长,陆续接触到 Bucket 下的各个延迟任务,从而实现了对请求的延迟处理。
但是,如果你仔细查看的话,就会发现,到目前为止,这套分层时间轮代码和 Kafka 概念并无直接的关联,比如分层时间轮里并不涉及主题、分区、副本这样的概念,也没有和 Controller、副本管理器等 Kafka 组件进行直接交互。但实际上,延迟处理请求是 Kafka 的重要功能之一。你可能会问,到底是 Kafka 的哪部分源码负责创建和维护这套分层时间轮,并将它集成到整体框架中去的呢?答案就是接下来要介绍的两个类:Timer 和 SystemTimer。
2.1 Timer 接口及 SystemTimer
这两个类的源码位于 utils.timer 包下的 Timer.scala 文件。其中,Timer 接口定义了管理延迟操作的方法,而 SystemTimer 是实现延迟操作的关键代码。后续在学习延迟请求类 DelayedOperation 时,我们就会发现,调用分层时间轮上的各类操作,都是通过 SystemTimer 类完成的。
2.1.1 Timer 接口
接下来,我们就看下它们的源码。首先是 Time 接口类,代码如下:
trait Timer {
// 将给定的定时任务插入到时间轮上,等待后续延迟执行
def add(timerTask: TimerTask): Unit
// 向前推进时钟,执行已达过期时间的延迟任务
def advanceClock(timeoutMs: Long): Boolean
// 获取时间轮上总的定时任务数
def size: Int
// 关闭定时器
def shutdown(): Unit
}
该 Timer 接口定义了 4 个方法。
- add 方法:将给定的定时任务插入到时间轮上,等待后续延迟执行。
- advanceClock 方法:向前推进时钟,执行已达过期时间的延迟任务。
- size 方法:获取当前总定时任务数。
- shutdown 方法:关闭该定时器。
其中,最重要的两个方法是 add 和 advanceClock,它们是完成延迟请求处理的关键步骤。接下来,我们结合 Timer 实现类 SystemTimer 的源码,重点分析这两个方法。
2.1.2 SystemTimer 类
SystemTimer 类是 Timer 接口的实现类。它是一个定时器类,封装了分层时间轮对象,为 Purgatory 提供延迟请求管理功能。所谓的 Purgatory,就是保存延迟请求的缓冲区。也就是说,它保存的是因为不满足条件而无法完成,但是又没有超时的请求。
下面,我们从定义和方法两个维度来学习 SystemTimer 类。
定义
首先是该类的定义,代码如下:
class SystemTimer(executorName: String,
tickMs: Long = 1,
wheelSize: Int = 20,
startMs: Long = Time.SYSTEM.hiResClockMs) extends Timer {
// 单线程的线程池用于异步执行定时任务
private[this] val taskExecutor = Executors.newFixedThreadPool(1,
(runnable: Runnable) => KafkaThread.nonDaemon("executor-" + executorName, runnable))
// 单线程的线程池用于异步执行定时任务
private[this] val delayQueue = new DelayQueue[TimerTaskList]()
// 总定时任务数
private[this] val taskCounter = new AtomicInteger(0)
// 时间轮对象
private[this] val timingWheel = new TimingWheel(
tickMs = tickMs,
wheelSize = wheelSize,
startMs = startMs,
taskCounter = taskCounter,
delayQueue
)
// 维护线程安全的读写锁
private[this] val readWriteLock = new ReentrantReadWriteLock()
private[this] val readLock = readWriteLock.readLock()
private[this] val writeLock = readWriteLock.writeLock()
...
}
每个 SystemTimer 类定义了 4 个原生字段,分别是 executorName、tickMs、wheelSize 和 startMs。
tickMs 和 wheelSize 是构建分层时间轮的基础,你一定要重点掌握。不过上节课我已经讲过了,而且我在开篇还用具体数字带你回顾了它们的用途,这里就不重复了。另外两个参数不太重要,你只需要知道它们的含义就行了。
- executorName:Purgatory 的名字。Kafka 中存在不同的 Purgatory,比如专门处理生产者延迟请求的 Produce 缓冲区、处理消费者延迟请求的 Fetch 缓冲区等。这里的 Produce 和 Fetch 就是 executorName。
- startMs:该 SystemTimer 定时器启动时间,单位是毫秒。
除了原生字段,SystemTimer 类还定义了其他一些字段属性。我介绍 3 个比较重要的。这 3 个字段与时间轮都是强相关的。
- delayQueue 字段。它保存了该定时器下管理的所有 Bucket 对象。因为是 DelayQueue,所以只有在 Bucket 过期后,才能从该队列中获取到。SystemTimer 类的 advanceClock 方法正是依靠了这个特性向前驱动时钟。关于这一点,一会儿我们详细说。
- timingWheel。TimingWheel 是实现分层时间轮的类。SystemTimer 类依靠它来操作分层时间轮。
- taskExecutor。它是单线程的线程池,用于异步执行提交的定时任务逻辑。
方法
说完了类定义与字段,我们看下 SystemTimer 类的方法。该类总共定义了 6 个方法:add、addTimerTaskEntry、reinsert、advanceClock、size 和 shutdown。
其中,size 方法计算的是给定 Purgatory 下的总延迟请求数,shutdown 方法则是关闭前面说到的线程池,而 addTimerTaskEntry 方法则是将给定的 TimerTaskEntry 插入到时间轮中。如果该 TimerTaskEntry 表征的定时任务没有过期或被取消,方法还会将已经过期的定时任务提交给线程池,等待异步执行该定时任务。至于 reinsert 方法,它会调用 addTimerTaskEntry 重新将定时任务插入回时间轮。
其实,SystemTimer 类最重要的方法是 add 和 advanceClock 方法,因为它们是真正对外提供服务的。我们先说 add 方法。add 方法的作用,是将给定的定时任务插入到时间轮中进行管理。代码如下:
def add(timerTask: TimerTask): Unit = {
// 获取读锁。在没有线程持有写锁的前提下,
// 多个线程能够同时向时间轮添加定时任务
readLock.lock()
try {
// 调用addTimerTaskEntry执行插入逻辑
addTimerTaskEntry(new TimerTaskEntry(timerTask, timerTask.delayMs + Time.SYSTEM.hiResClockMs))
} finally {
// 释放读锁
readLock.unlock()
}
}
add 方法就是调用 addTimerTaskEntry 方法执行插入动作。以下是 addTimerTaskEntry 的方法代码:
private def addTimerTaskEntry(timerTaskEntry: TimerTaskEntry): Unit = {
// 视timerTaskEntry状态决定执行什么逻辑:
// 1. 未过期未取消:添加到时间轮
// 2. 已取消:什么都不做
// 3. 已过期:提交到线程池,等待执行
if (!timingWheel.add(timerTaskEntry)) {
// 定时任务未取消,说明定时任务已过期
// 否则timingWheel.add方法应该返回True
if (!timerTaskEntry.cancelled)
taskExecutor.submit(timerTaskEntry.timerTask)
}
}
TimingWheel 的 add 方法会在定时任务已取消或已过期时,返回 False,否则,该方法会将定时任务添加到时间轮,然后返回 True。因此,addTimerTaskEntry 方法到底执行什么逻辑,取决于给定定时任务的状态:
- 如果该任务既未取消也未过期,那么,addTimerTaskEntry 方法将其添加到时间轮;
- 如果该任务已取消,则该方法什么都不做,直接返回;
- 如果该任务已经过期,则提交到相应的线程池,等待后续执行。
另一个关键方法是 advanceClock 方法。顾名思义,它的作用是驱动时钟向前推进。我们看下代码:
def advanceClock(timeoutMs: Long): Boolean = {
// 获取delayQueue中下一个已过期的Bucket
var bucket = delayQueue.poll(timeoutMs, TimeUnit.MILLISECONDS)
if (bucket != null) {
// 获取写锁
// 一旦有线程持有写锁,其他任何线程执行add或advanceClock方法时会阻塞
writeLock.lock()
try {
while (bucket != null) {
// 推动时间轮向前"滚动"到Bucket的过期时间点
timingWheel.advanceClock(bucket.getExpiration)
bucket.flush(addTimerTaskEntry)
// 读取下一个Bucket对象
bucket = delayQueue.poll()
}
} finally {
// 释放写锁
writeLock.unlock()
}
true
} else {
false
}
}
由于代码逻辑比较复杂,我再画一张图来展示一下:
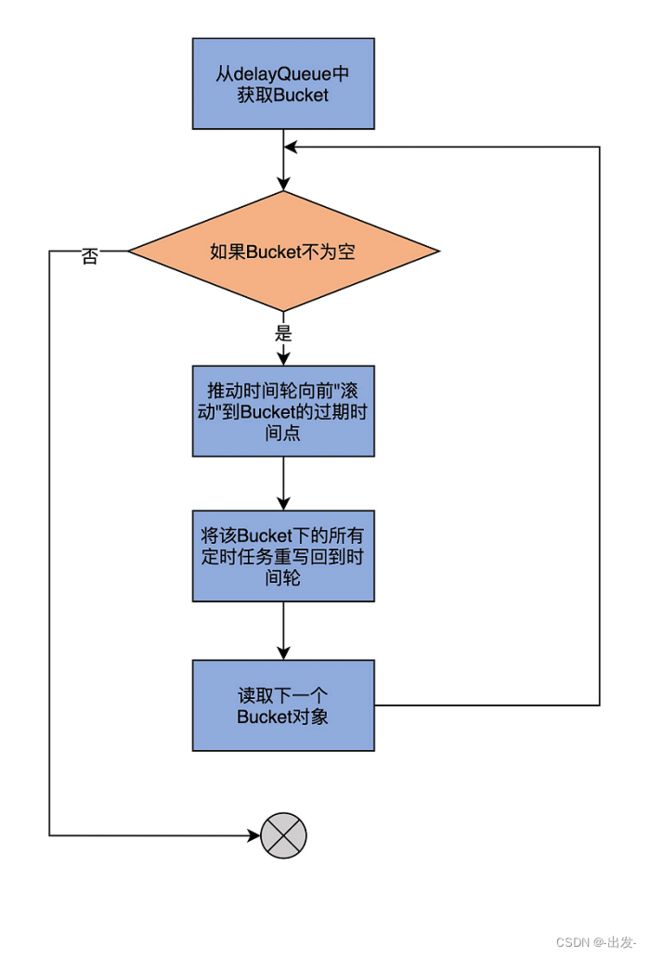
advanceClock 方法要做的事情,就是遍历 delayQueue 中的所有 Bucket,并将时间轮的时钟依次推进到它们的过期时间点,令它们过期。然后,再将这些 Bucket 下的所有定时任务全部重新插入回时间轮。
我用一张图来说明这个重新插入过程。
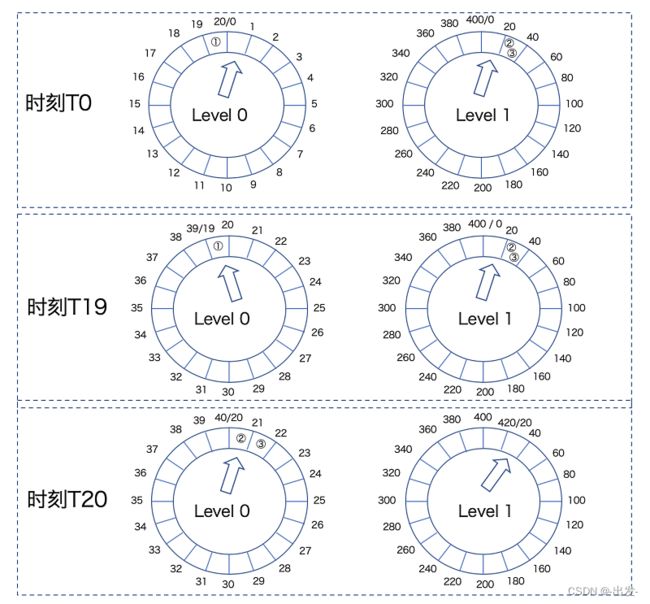
从这张图中,我们可以看到,在 T0 时刻,任务①存放在 Level 0 的时间轮上,而任务②和③存放在 Level 1 的时间轮上。此时,时钟推进到 Level 0 的第 0 个 Bucket 上,以及 Level 1 的第 0 个 Bucket 上。
当时间来到 T19 时刻,时钟也被推进到 Level 0 的第 19 个 Bucket,任务①会被执行。但是,由于一层时间轮是 20 个 Bucket,因此,T19 时刻 Level 0 的时间轮尚未完整走完一圈,此时,Level 1 的时间轮状态没有发生任何变化。
当 T20 时刻到达时,Level 0 的时间轮已经执行完成,Level 1 的时间轮执行了一次滴答,向前推进一格。此时,Kafka 需要将任务②和③插入到 Level 0 的时间轮上,位置是第 20 个和第 21 个 Bucket。
至于为什么要重新插入回低层次的时间轮,其实是因为,随着时钟的推进,当前时间逐渐逼近任务②和③的超时时间点。它们之间差值的缩小,足以让它们被放入到下一层的时间轮中。
总的来说,SystemTimer 类实现了 Timer 接口的方法,它封装了底层的分层时间轮,为上层调用方提供了便捷的方法来操作时间轮。那么,它的上层调用方是谁呢?答案就是 DelayedOperationPurgatory 类。这就是我们建模 Purgatory 的地方。
不过,在了解 DelayedOperationPurgatory 之前,我们要先学习另一个重要的类:DelayedOperation。前者是一个泛型类,它的类型参数恰恰就是 DelayedOperation。因此,我们不可能在不了解 DelayedOperation 的情况下,很好地掌握 DelayedOperationPurgatory。
2.2 DelayedOperation 类
这个类位于 server 包下的 DelayedOperation.scala 文件中。它是所有 Kafka 延迟请求类的抽象父类。我们依然从定义和方法这两个维度去剖析它。
定义
首先来看定义。代码如下:
abstract class DelayedOperation(override val delayMs: Long,
lockOpt: Option[Lock] = None)
extends TimerTask with Logging {
// 标识该延迟操作是否已经完成
private val completed = new AtomicBoolean(false)
private[server] val lock: Lock = lockOpt.getOrElse(new ReentrantLock)
...
}
DelayedOperation 类是一个抽象类,它的构造函数中只需要传入一个超时时间即可。这个超时时间通常是客户端发出请求的超时时间,也就是客户端参数 request.timeout.ms 的值。这个类实现了上节课学到的 TimerTask 接口,因此,作为一个建模延迟操作的类,它自动继承了 TimerTask 接口的 cancel 方法,支持延迟操作的取消,以及 TimerTaskEntry 的 Getter 和 Setter 方法,支持将延迟操作绑定到时间轮相应 Bucket 下的某个链表元素上。
completed 表征延迟操作是否完成。
方法
DelayedOperation 类有 7 个方法。我先介绍下它们的作用,这样你在读源码时就可以心中有数。
- forceComplete:强制完成延迟操作,不管它是否满足完成条件。每当操作满足完成条件或已经过期了,就需要调用该方法完成该操作。
- isCompleted:检查延迟操作是否已经完成。源码使用这个方法来决定后续如何处理该操作。比如如果操作已经完成了,那么通常需要取消该操作。
- onExpiration:强制完成之后执行的过期逻辑回调方法。只有真正完成操作的那个线程才有资格调用这个方法。
- onComplete:完成延迟操作所需的处理逻辑。这个方法只会在 forceComplete 方法中被调用。
- tryComplete:尝试完成延迟操作的顶层方法,内部会调用 forceComplete 方法。
- safeTryComplete:线程安全版本的 tryComplete 方法。这个方法其实是社区后来才加入的,不过已经慢慢地取代了 tryComplete,现在外部代码调用的都是这个方法了。
- run:调用延迟操作超时后的过期逻辑,也就是组合调用 forceComplete + onExpiration。
我们说过,DelayedOperation 是抽象类,对于不同类型的延时请求,onExpiration、onComplete 和 tryComplete 的处理逻辑也各不相同,因此需要子类来实现它们。
最好结合一两个具体子类的方法实现,体会下具体延迟请求类是如何实现 tryComplete 方法的。我推荐你从 DelayedProduce 类的 tryComplete 方法开始。
我们之前总说,acks=all 的 PRODUCE 请求很容易成为延迟请求,因为它必须等待所有的 ISR 副本全部同步消息之后才能完成,你可以顺着这个思路,研究下 DelayedProduce 的 tryComplete 方法是如何实现的。
2.3 DelayedOperationPurgatory 类
接下来,我们补上延迟请求模块的最后一块“拼图”:DelayedOperationPurgatory 类的源码分析。
该类是实现 Purgatory 的地方。从代码结构上看,它是一个 Scala 伴生对象。也就是说,源码文件同时定义了 DelayedOperationPurgatory Object 和 Class。Object 中仅仅定义了 apply 工厂方法和一个名为 Shards 的字段,这个字段是 DelayedOperationPurgatory 监控列表的数组长度信息。因此,我们还是重点学习 DelayedOperationPurgatory Class 的源码。
前面说过,DelayedOperationPurgatory 类是一个泛型类,它的参数类型是 DelayedOperation 的具体子类。因此,通常情况下,每一类延迟请求都对应于一个 DelayedOperationPurgatory 实例。这些实例一般都保存在上层的管理器中。比如,与消费者组相关的心跳请求、加入组请求的 Purgatory 实例,就保存在 GroupCoordinator 组件中,而与生产者相关的 PRODUCE 请求的 Purgatory 实例,被保存在分区对象或副本状态机中。
定义
至于怎么学,还是老规矩,我们先从定义开始。代码如下:
final class DelayedOperationPurgatory[T <: DelayedOperation](
purgatoryName: String,
timeoutTimer: Timer,
brokerId: Int = 0,
purgeInterval: Int = 1000,
reaperEnabled: Boolean = true,
timerEnabled: Boolean = true) extends Logging with KafkaMetricsGroup {
......
}
定义中有 6 个字段。其中,很多字段都有默认参数,比如,最后两个参数分别表示是否启动删除线程,以及是否启用分层时间轮。现在,源码中所有类型的 Purgatory 实例都是默认启动的,因此无需特别留意它们。
purgeInterval 这个参数用于控制删除线程移除 Bucket 中的过期延迟请求的频率,在绝大部分情况下,都是 1 秒一次。当然,对于生产者、消费者以及删除消息的 AdminClient 而言,Kafka 分别定义了专属的参数允许你调整这个频率。比如,生产者参数 producer.purgatory.purge.interval.requests,就是做这个用的。
事实上,需要传入的参数一般只有两个:purgatoryName 和 brokerId,它们分别表示这个 Purgatory 的名字和 Broker 的序号。
而 timeoutTimer,就是我们前面讲过的 SystemTimer 实例,我就不重复解释了。
Wathcers 和 WatcherList
DelayedOperationPurgatory 还定义了两个内置类,分别是 Watchers 和 WatcherList。
Watchers 是基于 Key 的一个延迟请求的监控链表。它的主体代码如下:
private class Watchers(val key: Any) {
private[this] val operations = new ConcurrentLinkedQueue[T]()
...
}
每个 Watchers 实例都定义了一个延迟请求链表,而这里的 Key 可以是任何类型,比如表示消费者组的字符串类型、表示主题分区的 TopicPartitionOperationKey 类型。你不用穷尽这里所有的 Key 类型,你只需要了解,Watchers 是一个通用的延迟请求链表,就行了。Kafka 利用它来监控保存其中的延迟请求的可完成状态。
既然 Watchers 主要的数据结构是链表,那么,它的所有方法本质上就是一个链表操作。比如,tryCompleteWatched 方法会遍历整个链表,并尝试完成其中的延迟请求。再比如,cancel 方法也是遍历链表,再取消掉里面的延迟请求。至于 watch 方法,则是将延迟请求加入到链表中。
说完了 Watchers,我们看下 WatcherList 类。它非常短小精悍,完整代码如下:
private class WatcherList {
// 定义一组按照Key分组的Watchers对象
val watchersByKey = new Pool[Any, Watchers](Some((key: Any) => new Watchers(key)))
val watchersLock = new ReentrantLock()
// 返回所有Watchers对象
def allWatchers = {
watchersByKey.values
}
}
WatcherList 最重要的字段是 watchersByKey。它是一个 Pool,Pool 就是 Kafka 定义的池对象,它本质上就是一个 ConcurrentHashMap。watchersByKey 的 Key 可以是任何类型,而 Value 就是 Key 对应类型的一组 Watchers 对象。
说完了 DelayedOperationPurgatory 类的两个内部类 Watchers 和 WatcherList,我们可以开始学习该类的两个重要方法:tryCompleteElseWatch 和 checkAndComplete 方法。
前者的作用是检查操作是否能够完成,如果不能的话,就把它加入到对应 Key 所在的 WatcherList 中。以下是方法代码:
def tryCompleteElseWatch(operation: T, watchKeys: Seq[Any]): Boolean = {
assert(watchKeys.nonEmpty, "The watch key list can't be empty")
if (operation.safeTryCompleteOrElse {
// 遍历所有要监控的Key,将该operation加入到Key所在的WatcherList
watchKeys.foreach(key => watchForOperation(key, operation))
if (watchKeys.nonEmpty) estimatedTotalOperations.incrementAndGet() // 更新Purgatory中总请求数
}) return true
// 如果依然不能完成此请求,将其加入到过期队列
if (!operation.isCompleted) {
if (timerEnabled)
timeoutTimer.add(operation)
if (operation.isCompleted) {
operation.cancel()
}
}
false
}
该方法的名字折射出了它要做的事情:先尝试完成请求,如果无法完成,则把它加入到 WatcherList 中进行监控。
那么,代码是在哪里进行重试的呢?这就需要用到第 2 个方法 checkAndComplete 了。
def checkAndComplete(key: Any): Int = {
// 获取给定Key的WatcherList
val wl = watcherList(key)
// 获取WatcherList中Key对应的Watchers对象实例
val watchers = inLock(wl.watchersLock) { wl.watchersByKey.get(key) }
// 尝试完成满足完成条件的延迟请求并返回成功完成的请求数
val numCompleted = if (watchers == null)
0
else
watchers.tryCompleteWatched()
debug(s"Request key $key unblocked $numCompleted $purgatoryName operations")
numCompleted
}
代码很简单,就是根据给定 Key,获取对应的 WatcherList 对象,以及它下面保存的 Watchers 对象实例,然后尝试完成满足完成条件的延迟请求,并返回成功完成的请求数。
可见,非常重要的步骤就是调用 Watchers 的 tryCompleteWatched 方法,去尝试完成那些已满足完成条件的延迟请求。
2.4 总结
今天,我们重点学习了分层时间轮的上层组件,包括 Timer 接口及其实现类 SystemTimer、DelayedOperation 类以及 DelayedOperationPurgatory 类。你基本上可以认为,它们是逐级被调用的关系,即 DelayedOperation 调用 SystemTimer 类,DelayedOperationPurgatory 管理 DelayedOperation。它们共同实现了 Broker 端对于延迟请求的处理,基本思想就是,能立即完成的请求马上完成,否则就放入到名为 Purgatory 的缓冲区中。后续,DelayedOperationPurgatory 类的方法会自动地处理这些延迟请求。
我们来回顾一下重点。
- SystemTimer 类:Kafka 定义的定时器类,封装了底层分层时间轮,实现了时间轮 Bucket 的管理以及时钟向前推进功能。它是实现延迟请求后续被自动处理的基础。
- DelayedOperation 类:延迟请求的高阶抽象类,提供了完成请求以及请求完成和过期后的回调逻辑实现。
- DelayedOperationPurgatory 类:Purgatory 实现类,该类定义了 WatcherList 对象以及对 WatcherList 的操作方法,而 WatcherList 是实现延迟请求后续自动处理的关键数据结构。
总的来说,延迟请求模块属于 Kafka 的冷门组件。毕竟,大部分的请求还是能够被立即处理的。了解这部分模块的最大意义在于,你可以学习 Kafka 这个分布式系统是如何异步循环操作和管理定时任务的。这个功能是所有分布式系统都要面临的课题,因此,弄明白了这部分的原理和代码实现,后续我们在自行设计类似的功能模块时,就非常容易了。