论文笔记:Reusing Discriminators for Encoding: Towards Unsupervised Image-to-Image Translation
摘要
(1)该文通过重新使用Discriminator对目标域的图像进行编码,来证明Discriminator的新作用。
(2)目前流行的翻译框架(translation frameworks)一旦完成训练过程就将遗弃Discriminator。
(3)该文提出的架构叫做NICE-GAN,有两个优点:
- 第一,它不需要独立的编码部分,所以它更加紧凑。
- 第二,该插件编码器是直接通过对抗损失进行训练的,如果应用了多尺度Discriminator,使它内容更丰富,训练效率更高。
(4)NICE-GAN中的主要问题是编码器上的translation与discrimination之间的耦合,当我们通过GAN玩min-max游戏时,可能会导致训练不一致。为了解决这个问题,作者发明了一种解耦的训练策略,仅在最大化对抗损失时才对编码器进行训练,除此之外则将其冻结。
论文代码地址
1.Introduction
1.1 在域之间收集配对图像需要大量工作,所以更实际的研究方向将目标定向到了无监督信息的无监督情况下。由于无监督翻译中的不可识别性问题,已提出了各种方法来解决此问题,方法是使用额外的规则,包括权重耦合,周期一致性,强制生成器使用身份一致性损失(identity function),或更常见的是将它们组合。
1.2 Discrimiator应在对输入图像进行某种语义编码之后才能分辨出哪些图像是正确的,哪些是错误的。换句话说,这意味着Discrimiator的两个作用:编码和分类。实际上,DCGAN论文已经揭示了鉴别器的编码能力:从鉴别器的最后一个卷积层开始的前6个可学习的卷积特征中观察到对输入图像的强烈响应。
基于上述动机,该文提出将Discriminator重新用于编码。特别是,Discriminator中将一定数量的早期层重用作为目标域的编码器,如图一所示,

这种重用具有两个优点:
- 一,实现了更紧凑的架构。 由于Encoder现在已成为Discriminator的一部分,因此我们不再需要用于编码的独立部分。此外,与现有的方法不同(在训练后放弃了Discriminator),它的编码部分仍保留在我们的框架中以供推断。
- 二, 编码器得到了更有效的训练。 传统的Encoder训练是通过间接传播来自生成器的梯度进行的。在这里,通过将其插入鉴别器,可以直接通过discriminative loss来训练编码器。 而且,现代的Discriminator已经诉诸于多尺度方案以达到更有效的效果。如果应用多尺度Discriminator,我们的Encoder将自然地继承这种能力。
1.3 重用Discriminator方法的一个问题是如何进行对抗性训练。
- 对于传统方法,Encoder与Generator一起训练以最小化GAN Loss,而Discriminator则单独进行训练以使目标最大化。在作者设计的框架中,Encoder和Discriminator会重叠, 如果我们应用传统训练设置编码器,则会带来不稳定,因为Encoder在翻译过程中要被训练为最小化(minimizing),而Encoder又属于Discriminator,并且还要进行训练为最大化(maximizing)。所以不能使用传统的GAN Loss进行训练。
- 为了消除这种不一致情况,作者设计了一种可分离训练范式。具体而言,编码器的训练仅与鉴别器相关联,而与生成器无关。经实验表明,这种简单的去耦显着促进了训练。
- 另一个直觉是,使Encoder脱离翻译训练的束缚将使Encoder朝着除翻译之外的更通用编码目的,从而实现更大的通用性。
2. Related Work
- Image-to-image translation. (基于CGAN)
- Unsupervised image-to-image translation.(CycleGAN,DiscoGAN,Dual GAN,StarGAN,coupledGAN,ComboGAN , XGAN , U-GAT-IT ,TravelGAN)
- Introspective Networks.(Introspective Neural Networks (INN) and Introspective Adversarial Networks (IAN) . (1)INN用于纯生成,Discriminator可重复用于从隐藏矢量到图像的生成(作为解码);而作者的NICE-GAN用于翻译,Discriminator可重复用于从图像嵌入到隐藏的矢量(作为编码)。此外,即使进行推理,INN也需要进行顺序训练,而NICE-GAN仅需向前通过即可生成新颖的图像,从而表现出更高的效率。(2)关于IAN,它也用于纯生成,并重用一个Discriminator来生成原始域假样本,这是一种内省机制。我们的NICE-GAN重用了一个域的鉴别符来生成另一个域的假样本,这的确是一种相互内省的机制)
3. Our NICE-GAN
3.1 通用方法:
3.1.1 问题定义:
- 令X,Y为两个图像域。给定联合分布p(X,Y)时,有监督的图像到图像的翻译需要学习条件映射 f x → y = p ( Y ∣ X ) f_{x→y} = p(Y | X) fx→y=p(Y∣X)和 f y → x = p ( X ∣ Y ) f_{y→x} = p(X | Y) fy→x=p(X∣Y)。无监督翻译仅提供边际条件p(X)和p(Y)即可学习 f x → y f_{x→y} fx→y和 f y → x f_{y→x} fy→x。
- 由于存在无限多个条件概率对应于相同的边际分布,因此无监督翻译是不恰当的。为了解决这个问题,当前的方法诉诸于增加额外的规定,例如 weight-coupling, cycle-consistency , and identity-mapping enforcing(权重耦合,循环一致性和身份映射强制),作者采用了后两者。
- 在大多数现有框架中,转换 f x → y f_{x→y} fx→y(分别为 f y → x f_{y→x} fy→x)由编码器Ex(resp. Ey)和生成器 G x → y G_{x→y} Gx→y(resp. G y → x G_{y→x} Gy→x)组成。通过将它们全部组合在一起,得出 y ′ = f x → y ( x ) = G x → y ( E x ( x ) ) y'= f_{x→y}(x)= G_{x→y}(E_x(x)) y′=fx→y(x)=Gx→y(Ex(x)) (resp. x ′ x' x′= f y → x ( y ) f_{y→x}(y) fy→x(y)= G y → x ( E y ( y ) ) G_{y→x}(E_y(y)) Gy→x(Ey(y))。通常采用GAN 的训练方式来使翻译后的输出适合目标域的分布。即,我们使用Discriminator D y D_y Dy(resp. D x D_x Dx)在真实图像y和翻译后的图像y’(resp. x和x’)之间进行分类。
3.1.2 NICE没有独立的编码器部分:
作者提出的NICE-GAN可重复使用Discriminator进行编码,从而为训练提供了效率和有效性的优势。
- 正式地,作者将Discriminator D y D_y Dy分为编码部分 E y D E^D_ {y} EyD和分类部分 C y C_y Cy。编码部分 E y D E^D_ {y} EyD取代原始编码器 f y → x f_{y→x} fy→x,类似地,对于Discriminator Dx,作者定义 E x D E^D_ {x} ExD和 C x C_x Cx,并将翻译函数重新表示为 f x → y ( x ) = G x → y ( E x D ( x ) ) f_{x→y}(x)= G_{x→y}(E^D_ {x}(x)) fx→y(x)=Gx→y(ExD(x))。至于分类部分 C x C_x Cx, C y C_y Cy ,作者进一步采用了multiscale structure(多尺度结构)来增强表达能力。
- 此外,新制定的Encoder E x D E^D_ {x} ExD和 E y D E^D_ {y} EyD存在于翻译和判别的训练循环中,使它们很难训练。因此,我们在NICE-GAN中提出了一个解耦的训练流程图。 框架图如图二说所示。 除非另有说明,否则为简单起见,我们将从 E x D E^D_ {x} ExD和 E y D E^D_ {y} EyD中删除上标D。

3.2 结构:
3.2.1 Multi-Scale Discriminators D x D_x Dx 和 D y D_y Dy.
D x D_x Dx 和 D y D_y Dy具有相似的表达方式,所以拿 D x D_x Dx 举例:
- Dicriminator D x D_x Dx包含两部分:Encoder E x E_x Ex和分类器 C x C_x Cx。为了实现多尺度处理,将分类器 C x C_x Cx进一步分为三个子分类器:用于局部尺度的 C x 0 C^0_x Cx0(10 x10感受野), C x 1 C^1_x Cx1 对于中规模(70 x 70感受野), C x 2 C^2_x Cx2对于全局规模(286 x 286感受野)。(类似SSD的方法)
- C x 0 C^0_x Cx0直接连接到 E x E_x Ex的输出。然后,在 E x E_x Ex进行下采样卷积以提供更小比例的feature map,这些feature map被连接到两个分支上:一个分支连接到 C x 1 C^1_x Cx1,另一分支通过卷积层进一步进行下采样,然后连接到 C x 2 C^2_x Cx2。对于单个输入图像, C x 0 C^0_x Cx0, C x 1 C^1_x Cx1和 C x 2 C^2_x Cx2都被训练用来预测图像是真或假。
- multi-scale Discriminator如图二所示:这里仅显示一个从X到Y(从狗到猫)的翻译过程。 请注意,我们采用了一种解耦的训练方式:在最小化 (minimizing) the adversarial loss, the reconstruction loss 和 the cycle loss时,将Encoder E y E_y Ey固定,而在最大化(maximizing) the adversarial loss时进行训练。
- 除了multi-scale的设计之外,作者还设计了一种残余注意力机制(residual attention mechanism),以进一步促进特征在Discriminator中的传播。
- U-GAT-IT最初提出在鉴别器中使用注意力机制。 假设编码器包含编号为K的feature map,( E x E_x Ex = { E x k } k = 1 K \{ E_x^k\}^K_{k=1} {Exk}k=1K)。U-GAT-IT的想法是首先学习一个注意力向量 w w w, w w w中的每个元素会对每个feature map的重要性进行计数。利用 a ( x ) a(x) a(x) = w × E x E_x Ex( x x x) = { \{ { w x w_x wx x E x k ( x ) } k = 1 K E_x^k(x)\}^K_{k=1} Exk(x)}k=1K计算的参加过的特征(attended feature)用于以后的分类。
- 而该文NICE-GAN在U-GAT-IT的基础上使用残差连接去进行计数,使用 a ( x ) = γ × w × E x ( x ) + E x ( x ) a(x) = γ × w × E_x(x) + E_x(x) a(x)=γ×w×Ex(x)+Ex(x),可训练参数 γ γ γ决定了参加的feature和原始feature两者之间的权衡。当 γ γ γ=0, E x ( x ) E_x(x) Ex(x)表示不使用注意力机制,否则激活注意力机制。
3.2.2 生成器Generator G x → y G_{x→y} Gx→y和 G y → x G_{y→x} Gy→x:
- G x → y G_{x→y} Gx→y和 G y → x G_{y→x} Gy→x都由6个残差块和2个用于上采样的子像素卷积层组成组成。并且,使用AdaLIN 的light版本。 另外,进行用于Discriminator和循环一致性损失(cycle-consistency loss)的频谱归一化[29],以防止Generator模式崩溃。
AdaLIN就是instance normalization和layer normalization的结合。AdaLIN的前提要保证通道之间不相关。因为它仅仅对图像map做归一化。【U-GAT-IT论文中使用】
3.3 解耦训练(Decoupled Training):
由于Encoder E x E_x Ex不仅是Discriminator D x D_x Dx的一部分,而且还被当作Generator G x → y G_{x→y} Gx→y的输入,所以不能使用常规的对抗损失训练。 为了克服这一缺陷,我们将 E x E_x Ex的训练从Generator G x → y G_{x→y} Gx→y下解耦。 下文提供了计算每种损失的详细信息。
3.3.1 Adversarial loss:
首先,我们利用最小二乘对抗损失,因为它具有更稳定的训练和更高的生成质量。 最小-最大博弈是通过以下方式进行的:

在最大化 L g a n x → y L^{x→y}_{gan} Lganx→y 时, E x E_x Ex是固定的, E y E_y Ey是训练的,在最小化 L g a n x → y L^{x→y}_{gan} Lganx→y时,固定 E x E_x Ex和 E y E_y Ey。
3.3.2 Cycle-consistency loss:
循环一致性损失首先由CycleGAN和DiscoGAN引入,这是迫使Generator成为彼此相反的结果。如式所示:

这里使用L1正则化计算损失, E x E_x Ex和 E y E_y Ey是是固定的。
3.3.3 Reconstruction loss:
我们的reconstruction基于共享潜在空间(shared-latent space)进行假设。
当源域真实样本的隐藏向量被提供作为源域生成器的输入, Reconstruction loss将翻译正则化为一种接近身份映射。
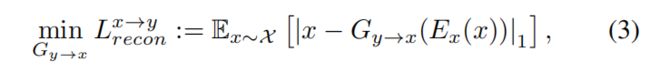
这里 E x E_x Ex保持不变。类似地,我们可以定义从域Y到X的损耗: L g a n y → x L^{y→x}_{gan} Lgany→x, L c y c l e y → x L^{y→x}_{cycle} Lcycley→x和 L r e c o n y → x L^{y→x}_{recon} Lrecony→x。
3.4 完整目标(Full objective):
Discriminator的最终Loss如式所示:
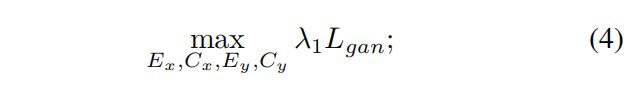
Generator的最终Loss如式所示:
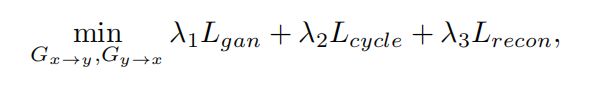
L g a n = L g a n x → y + L g a n y → x L_{gan} = L^{x→y}_{gan} + L^{y→x}_{gan} Lgan=Lganx→y+Lgany→x , L c y c l e = L c y c l e x → y + L c y c l e y → x L_{cycle} = L^{x→y}_{cycle} + L^{y→x}_{cycle} Lcycle=Lcyclex→y+Lcycley→x, L r e c o n = L r e c o n x → y + L r e c o n y → x L_{recon} = L^{x→y}_{recon} + L^{y→x}_{recon} Lrecon=Lreconx→y+Lrecony→x。这里面 λ1 = 1, λ2 = 10, λ3 = 10。
4. Experiments
4.1 Baselines:
作者与CycleGAN,UNIT,MUNIT,DRIT,U-GAT-IT进行对比。
4.2 Datasets:
实验在未配对图像的四个普遍基准上进行:
- horse↔zebra
- summer↔winter-yosemite
- vangogh↔photo
- cat↔dog
4.3 Evaluation Metrics:
4.3.1 人力标准(Human Preference)
为了比较不同方法生成的翻译输出的准确性,我们进行了人类感知研究。为志愿者们展示了一个输入图像和三个来自不同方法的翻译输出,并且给了他们无限的时间,他们选择了哪个翻译输出看起来更好。
4.3.2The Frechet Inception Distance (FID)
对于每个比较的图像集的InceptionNet的隐藏激活函数,FID拟合了一个高斯分布,然后计算这些高斯之间的Frechet距离´(也称为Wasserstein-2距离)。FID越低越好,对应的生成图像与真实图像更相似。
4.3.3The Kernel Inception Distance (KID)
KID是类似于FID的度量,但使用多项式内核 k ( x , y ) k(x,y) k(x,y)=( 1 d \frac 1 d d1 x T x^T xT y + 1 ) 3 )^3 )3的起始表示之间的平方最大均值差异(MMD)。 其中d是表示尺寸。 它也可以直接在内核为 K ( x , y ) = k ( θ ( x ) , θ ( y ) ) K(x,y)= k(θ(x),θ(y)) K(x,y)=k(θ(x),θ(y))的输入图像上视为MMD,其中θ是将图像映射到Inception表示的函数。
与FID不同,KID具有简单的无偏估计量,因此使其可靠性更高,尤其是当接收特征通道的数量比图像编号多时。 较低的KID表示实际图像与生成的图像之间具有更高的视觉相似度。