什么是哈希Hash
为什么要有哈希?
假设我们要设计一个系统来存储将员工手机号作为主键的员工记录,并希望高效地执行以下操作:
插入电话号码和相应的信息。(插入)
搜索电话号码并获取信息。(查找)
删除电话号码及相关信息。(删除)
我们可以考虑使用以下数据结构来维护不同电话所对应的信息:
- 数组
- 链表
- 平衡二叉树(红黑树等等)
- 直接访问表
对于数组和链表而言,我们需要以线性的方式进行查找,这在实际应用中代价太大;如果我们使用数组且保证数组中电话号码有序排列,那么使用二分查找可将查找电话号码的时间复杂度降到O(logN),但同时由于要维持数组的有序性,插入和删除操作的代价将变大O(N)。
对于平衡二叉查树而言,插入、查找和删除操作的时间复杂度均为O(logN),这似乎已经看着很不错了,那么是否有更好的数据结构呢?
再来看直接访问表的方式,首先创建一个大数组(至少能够用电话号码作为数组下标),如果电话号码没有出现在数组当中,就在相应下标填充 NULL;如果电话号码出现了,则下标中数据填充该电话号码关联的记录的地址。
这样一来,插入、查找和删除的时间复杂度将降为O(1),比如插入一条记录(15002629900,0xFF0A “可爱的读者”),只需要将手机号码 15002629900 当做下标,然后在该下标的位置填充记录的地址,即 arr[15002629900] = 0xFF0A;
但是直接访问表有实践上的限制。首先需要申请额外的存储空间,并且存在大量的空间浪费。比如对于一个含有 n 位的电话号码,我们需要O(m x 10^n)的空间复杂度,其中 m 表示数据本身所占用的空间。另外一个问题是,编程语言本身提供的整型无法表示电话号码。
由于上述限制,使用直接访问表并不是最明智的方法。而哈希则是解决以上问题的最好数据结构,并且与上面所提到的数据结构(数组,链表,AVL树)在实践中相比,性能非常好。通过哈希,可以在O(1)的时间复杂度内实现插入、查找和删除操作(在合理的假设下),最坏情况下为O(n)的时间复杂度。
哈希是对直接访问表的改进。使用哈希函数将给定的电话号码或任何其他键转换为较小的数字,将该较小的数字称为哈希表的索引(哈希值)
什么是哈希表
哈希表和直接访问表很类似,同样是一个用于存储指向给定电话号码对应记录的指针的数组,只不过,此时的数组下标不再是电话号码,而是经过哈希函数映射后的输出值。
什么是哈希函数
哈希函数用于将一个大数(手机号码)或字符串映射为一个可以作为哈希表索引的较小整数的函数。比如活动开发中经常使用的 MD5 和 SHA 都是历史悠久的Hash算法。
Mac-mini:~ $ echo -n "I love J" | openssl md5
ef821d9b424fd5f0aac7faf029152e04
一个好的哈希函数应该满足四个条件:
- 执行效率要高(效率高)
对于一段很长的字符串或者二进制文本也能快速计算出哈希值。 - 散列结果应当具有同一性(输出值尽量均匀,越均匀冲突就越少)。(同一性)
例如对于电话号码而言,一个好的哈希函数应该考虑电话号码的后四位,而一个糟糕的哈希算法可能考虑电话号码的前四位,因为后四位更有区分性,相当于输入更加分散,那么输出也可能更加均匀,当然这两种选择方式都不是什么好办法,只是希望大家理解同一性原理。 - 雪崩效应(微小的输入值变化使得输出值发生巨大的变化)。
Mac-mini:~ $ echo -n "I love J" | openssl md5
ef821d9b424fd5f0aac7faf029152e04
Mac-mini:~ $ echo -n "I love Y" | openssl md5
fb49af24bebae07658650ae8eb1c0f5b
其中输入 I love J 和 I love Y 只改变了一个字母,输出值却千差万别。
什么是 Hash 碰撞
由于哈希函数的原理是将输入空间的一个较大的值映射成 hash 空间内一个较小的值,那么就会出现两个不同的输入值被映射到了同一个较小的输出值。当一个新插入的值被哈希函数映射到了哈希表中一个已经被占用的槽,就认为产生了 Hash 碰撞(冲突)。
那么这种冲突是否可以避免呢?答案是只能缓解,不可避免。
由于哈希函数的原理是将输入空间一个较大的值映射到一个较小的 Hash 空间内,而 Hash空间一般远小于输入的空间。根据抽屉原理,一定会存在不同的输入被映射成同一输出的情况。
何为抽屉原理?
桌上有十个苹果,要把这十个苹果放到九个抽屉里,无论怎样放,我们会发现至少会有一个抽屉里面放不少于两个苹果。这一现象就是“抽屉原理”。抽屉原理的一般含义为:“如果每个抽屉代表一个集合,每一个苹果就可以代表一个元素,假如有n+1个元素放到n个集合中去,其中必定有一个集合里至少有两个元素。” 抽屉原理有时也被称为鸽巢原理。它是组合数学中一个重要的原理
知道了为什么哈希碰撞不可避免,那哈希碰撞该如何缓解呢?
Hash 碰撞的解决方案
- 链地址法
- 开放地址法
- 再哈希
1. 链地址法
链地址法的思想就是将所有发生碰撞的元素用一个单链表串起来。
我们以一个简单的哈希函数 H(key) = key%7 (除数取余法)对一组元素 [50, 700, 76, 85, 92, 73, 101]进行映射,来理解链地址法处理 Hash 碰撞。
除数为 7 ,初始化一个大小为 7 的空 Hash 表:
然后插入元素 50 ,首先对 50 % 7 = 1 ,得到为 1 的位置插入 50 :

然后计算 700 % 7 = 0 ,76 % 7 = 6 ,得到的哈希值均未发生碰撞,填入相应位置:
然后计算 85 % 7 = 1 , 但是下标为 1 的位置已经有元素 50 ,发生了碰撞,所以使用单链表将 85 和 50 链接起来:
以同样的方式插入所有元素得到如下的哈希表。链地址法解决冲突的方式与图的邻接表存储方式在样式上很相似,思想还是蛮简单,发生冲突,就用单链表组织起来。
链地址法实现
首先创建一个空的哈希表,哈希表的表长为 N = 7
哈希函数:Hash(key) = key % N
插入:计算要插入关键字 key 的哈希值 Hash(key) ,然后在哈希表中找到对应哈希值的位置,再将 key 插入链表的末尾;
删除:计算要删除关键字 key 的哈希值 Hash(key) ,然后在哈希表中找到对应哈希值的位置,再将 key 充链表中删除。
查找:计算要查找关键字 key 的哈希值 Hash(key) ,然后在哈希表中找到对应哈希值的位置,从该位置开始进行单链表的线性查找。
C++代码实现
using namespace std;
class Hash
{
int N; // 哈希表的表长
// 指向对应存储下标的指针。
list<int> *table;
public:
Hash(int V);
void insertKey(int x);
void deleteKey(int key);
int hashFunction(int x) {
return (x % N);
}
void displayHash();
};
Hash::Hash(int b)
{
this->N = b;
table = new list<int>[N];
}
void Hash::insertKey(int key)
{
int index = hashFunction(key);
table[index].push_back(key);
}
void Hash::deleteKey(int key)
{
//计算key的哈希值 Hash(key)
int index = hashFunction(key);
//找到 index
list <int> :: iterator i;
for (i = table[index].begin();
i != table[index].end(); i++) {
if (*i == key){
break;
}
}
//如果找到了对应的key,删除之
if (i != table[index].end())
table[index].erase(i);
}
// 输出哈希表
void Hash::displayHash() {
for (int i = 0; i < N; i++) {
cout << i;
for (auto x : table[i]){
cout << " --> " << x;
}
cout << endl;
}
}
int main()
{
int a[] = {50, 700, 76, 85, 92, 73, 101};
int n = sizeof(a)/sizeof(a[0]);
Hash h(7);
for (int i = 0; i < n; i++){
h.insertKey(a[i]);
}
h.deleteKey(92);
h.displayHash();
return 0;
}
链地址法的优缺点:
优点:
- 实现起来简单;
- 哈希表永远不会溢出,我们可以向单链表中添加更多的元素;
- 对于哈希函数和装填因子(后面会说)的选择没啥要求;
- 在不知道要插入和删除关键字多少和频率的情况下,链地址法有绝对优势。
缺点:
- 由于使用链表来存储关键字,链地址法的缓存性能不佳。开放寻址法使用连续的地址空间进行存储,所以缓存性能更好;
- 浪费空间(因为哈希表的有些位置从未被使用);
- 如果链表太长,在最坏的情况下查找的时间复杂度将变为O(n);
- 需要额外的空间存储链表指针。
链地址法的性能:
假设任何一个关键字都以相等的概率被映射到哈希表的任意一个槽位。
其中m表示哈希表的槽位数,n表示插入到哈希表中的关键字的数目。
装填因子(load factor)α = n/m(将 n 个球随机均匀地扔进 m 个箱子里的概率)。
期望的查找,插入和删除的时间均等于O(1+α)
当 α为O(1)量级时,链地址法的插入、查找和删除操作的时间复杂度就是O(1)量级。
极端情况下我们将 n 个数都扔进了同一个槽,也就是 n 个数形成了一个单链表,那么时间复杂度将降为O(n),但这个概率微乎其微。
2. 开放地址法
与链地址法一样,开放地址法也是一个经典的处理冲突的方式。只不过,对于开放地址法,所有的元素都是存储在哈希表当中的,所以无论任何时候都要保证哈希表的槽位数m大于或等于关键字的数目n(必要的时候,我们还会复制旧数据,然后对哈希表进行动态扩容)。
开放地址法分三种方式。
- 线性探测法
- 平方探测法
- 双重哈希
1. 线性探测法(Linear Probing)
设 Hash(key) 表示关键字 key 的哈希值,M表示哈希表的槽位数(哈希表的大小)。
线性探测法则可以表示为:
如果 Hash(x) % M 已经有数据,则尝试 (Hash(x) + 1) % M ;
如果 (Hash(x) + 1) % M 也有数据了,则尝试 (Hash(x) + 2) % M ;
如果 (Hash(x) + 2) % M 也有数据了,则尝试 (Hash(x) + 3) % M;
…
我们同样以哈希函数 H(key) = key MOD 7 (除数取余法)对 [50, 700, 76, 85, 92, 73, 101] 进行映射,来理解线性探测法处理 Hash 碰撞。
依次计算 50 % 7 = 1 、700 % 7 = 0 及 76 % 7 = 6 ,均没有发生冲突(碰撞),则直接放入相应的位置:
计算 85 % 7 = 1 ,但是下标 1 的位置已经有元素 50 ,发生碰撞,则寻找下一个可以存放元素 85 的空位 (85 % 7 + 1) % 7 = 2,下标二没有元素,所以将 85 放进去:

计算 92 % 7 = 1 ,50 已经在 1 的位置,发生碰撞;线性探测下一个位置 (92 % 7 + 1) % 7 = 2 ,85 已经在 2 的位置,发生碰撞;线性探测下一个位置 (92 % 7 + 2) % 7 = 3,此时为空位,填入 92 :
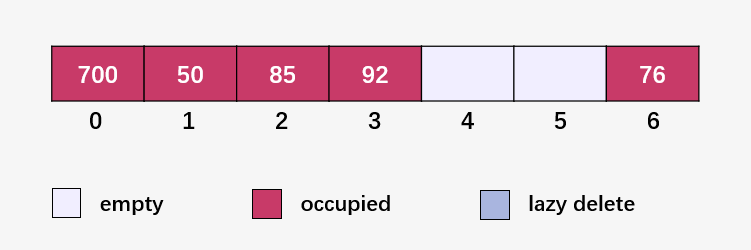
计算 73 % 7 = 3 ,92 已经占用了 3 号位置,发生碰撞;线性探测下一个位置 (73 % 7 + 1) % 7 = 4 ,此时为空位,填入 73 :
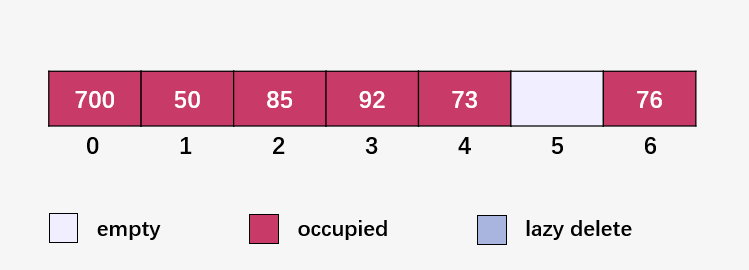
计算 101 % 7 = 3, 3 号位置已经有元素,发生碰撞;线性探测下一个位置 (101 % 7 + 1) % 7 = 4 ,4 号位置已有元素,发生碰撞;线性探测下一个位置(101 % 7 + 2) % 7 = 5, 此时为空,填入 101 :
到这里你不难看出线性探测的缺陷,容易产生聚集(发生碰撞的元素形成组,比如 [50,85,92,73,101] 之间均是由于碰撞而紧挨着),而且发生碰撞的情况大大增加,需要花费更多的时间来寻找空闲的槽位和查找元素。
至于(lazy delete)懒删除就是并不将存储空间释放,只是将里面的数据清除。
比如删除元素 92 ,先计算 92 % 7 = 1 ,但是发现下标 1 是 50,线性向下探测 (92 % 7 + 1) % 7 = 2,下标 2 为 85,继续线性向下探测 (92 % 7 + 2) % 7 = 3,发现下标 3 刚好为 92,将该存储单元的数据清空。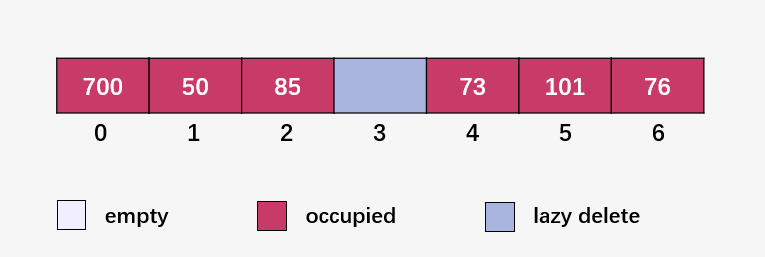
2. 平方探测法(Quadratic Probing)
所谓 Quadratic Probing,就是每次向下探测的宽度变成了i²,其中的i表示迭代次数。
设 Hash(key) 表示关键字 key 的哈希值,M表示哈希表的槽位数(哈希表的大小)。
平方探测法则可以表示为:
如果 Hash(x) % M 已经有数据,则尝试 (Hash(x) + 1 * 1) % M;
如果 (Hash(x) + 1 * 1) % M 也有数据了,则尝试 (Hash(x) + 2 * 2) % M ;
如果 (Hash(x) + 2 * 2) % M 也有数据了,则尝试 (Hash(x) + 3 * 3) % M;
…
3. 双重哈希(Double Hashing)
对于双重哈希,我们需要一个新的哈希函数 Hash2(key),而且对于第i次迭代探测,我们查找的位置为i * Hash2(key)。
设 Hash(key) 表示关键字 key 的一个哈希值, Hash2(key) 表示关键字 key 的另一个哈希值, 表示哈希表的槽位数(哈希表的大小)。
双重哈希探测法则可以表示为:
如果 Hash(x) % M 已经有数据,则尝试 (Hash(x) + 1 * Hash2(x)) % M ;
如果 (Hash(x) + 1 * Hash2(x)) % M也有数据了,则尝试(Hash(x) + 2 * Hash2(x)) % M;
如果 (Hash(x) + 2 * Hash2(x)) % M 也有数据了,则尝试 (Hash(x) + 3 * Hash2(x)) % M;
…
开放地址法的实现:
C++ 代码
using namespace std;
// 哈希表的大小
#define TABLE_SIZE 13
// 用于定义 Hash2(key)
#define PRIME 7
class DoubleHash {
// 定义一个哈希表
int* hashTable; //int[] hashTable;
int curr_size;
public:
// 判断哈希表是否满了
bool isFull()
{
//当前的大小大于哈希表的大小
return (curr_size == TABLE_SIZE);
}
// 哈希函数1
int hash1(int key)
{
return (key % TABLE_SIZE);
}
// 哈希函数2
int hash2(int key)
{
return (PRIME - (key % PRIME));
}
DoubleHash()
{
hashTable = new int[TABLE_SIZE];
curr_size = 0;
for (int i = 0; i < TABLE_SIZE; i++){
hashTable[i] = -1;
}
}
// 插入操作
void insertHash(int key)
{
// 判断哈希表是否已满
if (isFull())
return;
// 获取哈希函数1计算的结果
int index = hash1(key);
// 如果发生碰撞
if (hashTable[index] != -1) {
//由哈希函数2获取另一个哈希值
int index2 = hash2(key);
int i = 1;
while (1) {
//得到双重哈希的索引,对于线性探测,平方探测改这里就可以
int newIndex = (index + i * index2) % TABLE_SIZE;
//如果新的哈希值newIndex为空,退出循环。
if (hashTable[newIndex] == -1) {
hashTable[newIndex] = key;
break;
}
i++;
}
}
else{
hashTable[index] = key;
}
curr_size++;
}
// 哈希表查找操作
void search(int key)
{
int index1 = hash1(key);
int index2 = hash2(key);
int i = 0;
while (hashTable[(index1 + i * index2) % TABLE_SIZE] != key) {
if (hashTable[(index1 + i * index2) % TABLE_SIZE] == -1) {
cout << key << ":\t哈希表中不存在" << endl;
//java 这里自己改成响应输出
return;
}
i++;
}
cout << key << "找到啦!" << endl;
}
// 打印输出
void displayHash()
{
for (int i = 0; i < TABLE_SIZE; i++) {
if (hashTable[i] != -1)
cout << i << " --> "
<< hashTable[i] << endl;
else
cout << i << endl;
}
}
};
int main()
{
int a[] = {50, 700, 76, 85, 92, 73, 101};
int n = sizeof(a) / sizeof(a[0]);
//创建哈希表,插入a[]中的元素
DoubleHash h;
for (int i = 0; i < n; i++) {
h.insertHash(a[i]);
}
//查找
h.search(36); //不存在
h.search(101); //存在
//打印输出
h.displayHash();
return 0;
}
至于线性探测和平方探测的实现比较简单,只需要修改一下代码中 newIndex 的计算方式即可。
线性探测:
int newIndex = (index + i) % TABLE_SIZE;
平方探测:
int newIndex = (index + i*i) % TABLE_SIZE;
以上三种探测方法的比较:
线性探测具有最佳的缓存性能,但会受到原始聚集(primary cluster)的影响。
线性探测易于计算。
何为原始聚集?(原始聚集是相对于线性探测而言的)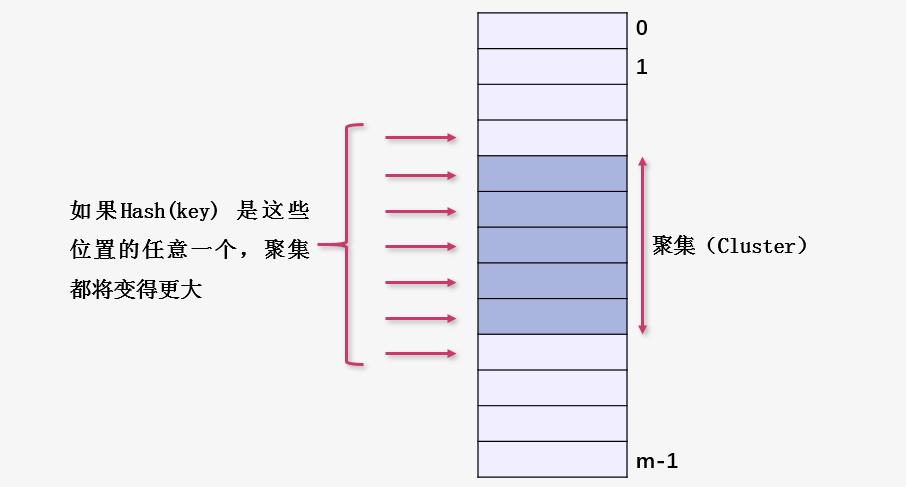
如图所示,如果对于任意一个关键字 key ,其哈希值Hash(key)指向图中从左向右的红色箭头的任意位置,聚集(图中的浅蓝色区域)都将得到扩充,而随着聚集的不断扩充,这个聚集会越来越大。
还不理解聚集的概念的话,我们一起看个例子:

上图中的 700,50,76 在插入的时候均未产生碰撞,所以以元素本身单位构成聚集(聚集的大小为 1,此时可以认为不是聚集)。
但是之后插入的元素就不一样了,85 与 50 发生碰撞,插入到了 50 的后面,导致聚集变大。

插入 92 与 50 发生碰撞,线性探测插入到了 85 之后,聚集进一步扩大。

插入 73 与 92 产生碰撞,线性探测插入到 92 之后,聚集进一步扩大。

插入 101 与 92 产生碰撞,线性探测插入到 73 之后,聚集进一步扩大。
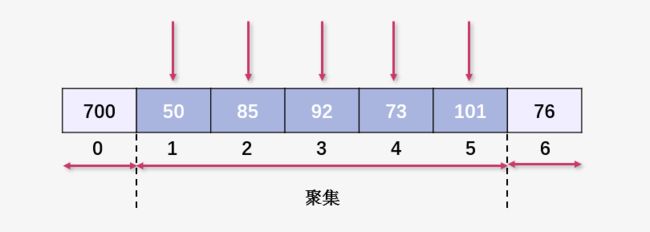
这就是原始聚集的概念,显然聚集越大,产生碰撞的可能越来越大,哈希算法的性能也会受到影响。
平方探测在缓存性能和受聚集影响方面介于两者中间,平方探测随解决了线性探测的原始聚集问题,但是同时也会产生更细的二次聚集问题。
二重探测的缓存性能较差,但不用担心聚集的情况,但同时由于要计算两个散列函数,时间性能方面受限。
开放地址法的性能分析:
与链地址法类似,假设任何一个关键字都以相等的概率被映射到哈希表的任意一个槽位。
其中m表示哈希表的槽位数,n表示插入到哈希表中的关键字的数目。
装填因子(load factor)α = n/m < 1(对于开放地址法而言, m > n)。
期望的插入、查找和删除的时间 < 1/(1-α) .
所以对于开放地址法而言,插入、查找和删除的时间复杂度为O(1/(1-α)) .
这里你一定会有困惑,举个栗子,α = 90% ,那么 1/(1-α) = 10 则表示最多探测10次就可以查找、插入或删除一个元素。
至于为什么是 < 1/(1-α)
对这个感兴趣的小伙伴,推荐看看严蔚敏老师的书籍《数据结构(C语言版)》262 页的证明。
开放地址法与链地址法的比较
| No | 链地址法 | 开放地址发 |
|---|---|---|
| 1 | 易于实现 | 需要更多的计算 |
| 2 | 使用链地址法,哈希表永远不会填充满,不用担心溢出。 | 哈希表可能被填满,需要通过拷贝来动态扩容。 |
| 3 | 对于哈希函数和装载因子不敏感 | 需要额外关注如何规避聚集以及装载因子的选择。 |
| 4 | 适合不知道插入和删除的关键字的数量和频率的情况 | 适合插入和删除的关键字已知的情况。 |
| 5 | 由于使用链表来存储关键字,缓存性能差。 | 所有关键字均存储在同一个哈希表中,所以可以提供更好的缓存性能。 |
| 6 | 空间浪费(哈希表中的有些链一直未被使用) | 哈希表中的所有槽位都会被充分利用。 |
| 7 | 指向下一个结点的指针要消耗额外的空间。 | 不存储指针。 |
3. 再哈希(Rehashing)
对于开放地址法而言,插入、查找和删除的时间复杂度为 O(1/(1-α)),意味着哈希算法的时间复杂度取决于装填因子α,α越大,开放地址法的时间复杂度也就越高。
装填因子α = 表中填入的记录数/哈希表的长度
一般将装填因子的值设置为 0.75,随着填入哈希表中记录数的增加,装填因子就会增大甚至超过设置的默认值 0.75,意味着哈希算法的时间复杂度的增加。为了解决装填因子超过默认设置的值 0.75,可以对数组(哈希表)进行扩容(二倍扩容),并将原哈希表中的值进行 再哈希,存储到二倍大小的新数组(哈希表)中,从而保证装填因子维持在一个较低的值(不超过 0.75),哈希算法的时间复杂度保证在O(1)量级。
这就是为什么需要在哈希的原因所在,下面我们一起看一下再哈希的实现。
再哈希可以大致分为四个步骤:
- 对于每一次向哈希表中添加新的键值对,检查装填因子 的大小;
- 如果α > 0.75,则进行 再哈希 。
- 对于再哈希而言,创建一个新的数组(原数组的两倍大小)作为哈希表。
- 遍历原数组中的每一个元素,并将其插入到新的数组当中。
我们依旧以 [50, 700, 76, 85, 92, 73, 101] 为例进行说明,其中可能会省略部分计算步骤。
开辟一个大小为 7 的空数组:

接下来就是插入并检查装填因子 ,我们将装填因子自己写到了图中:






此时要注意啦,此时装填因子α = 6/7 > 3/4 ,创建一个长度为 14 的新数组(原始数组的两倍):

此时的数组长度为 14 ,我们的哈希函数也变了,由原来的 Hash(key) = key % 7 变成了 Hash(key) = key % 14。然后遍历原始数组,并将原始数组中的元素映射到新的数组当中:

然后计算 101 % 14 = 3 ,插入到 73 的后面:

这就是再哈希,我相信你也理解啦!但是我们的实现可能不是这样的,我们将插入的是一个键值对,比如[<50, "I">, <700, "Love">, <76, "Data">, <85, "Structure">, <92, "and">, <73, "Jing">, <101, "Yu">] 。此外代码是以链地址法来实现再哈希的!可不是画图讲的开放地址法线性探测。
再哈希实现:
java代码
import java.util.ArrayList;
class Map<K, V> {
class MapNode<K, V> {
K key;
V value;
MapNode<K, V> next; //链地址法
public MapNode(K key, V value)
{
this.key = key;
this.value = value;
next = null;
}
}
// 键值对就存储在
ArrayList<MapNode<K, V> > hashTable;
// 装填因子 alpha 的分子 -- 表中填入的记录数
int size;
// 装填因子 alpha 的分母 -- 哈希表的长度。
int numHashTable;
// 默认的装填因子 0.75
final double DEFAULT_LOAD_FACTOR = 0.75;
public Map()
{
numHashTable = 5;
hashTable = new ArrayList<>(numHashTable);
for (int i = 0; i < numHashTable; i++) {
// 初始化哈希表
hashTable.add(null);
}
}
private int getBucketInd(K key)
{
// Using the inbuilt function from the object class
int hashCode = key.hashCode();
// array index = hashCode%numHashTable
return (hashCode % numHashTable);
}
public void insert(K key, V value)
{
// 获取插入的关键字 key 的哈希值
int bucketInd = getBucketInd(key);
MapNode<K, V> head = hashTable.get(bucketInd);
//插入 K-V
while (head != null) {
if (head.key.equals(key)) {
head.value = value;
return;
}
head = head.next;
}
MapNode<K, V> newElementNode = new MapNode<K, V>(key, value);
head = hashTable.get(bucketInd);
newElementNode.next = head;
hashTable.set(bucketInd, newElementNode);
size++;
// 计算当前的装填因子
double loadFactor = (1.0 * size) / numHashTable;
// 装填因子 > 0.75,执行再哈希
if (loadFactor > DEFAULT_LOAD_FACTOR) {
rehash();
}
}
private void rehash()
{
System.out.println("\n***Rehashing Started***\n");
// 保存原始哈希表
ArrayList<MapNode<K, V> > temp = hashTable;
//创建新的数组(原始数组的两倍)
hashTable = new ArrayList<MapNode<K, V> >(2 * numHashTable);
for (int i = 0; i < 2 * numHashTable; i++) {
buckets.add(null);
}
// 将旧数组中数据拷贝到新数组中
size = 0;
numHashTable *= 2;
for (int i = 0; i < temp.size(); i++) {
MapNode<K, V> head = temp.get(i);
while (head != null) {
K key = head.key;
V val = head.value;
insert(key, val);
head = head.next;
}
}
}
public void printMap()
{
ArrayList<MapNode<K, V> > temp = hashTable;
System.out.println("当前的哈希表:");
for (int i = 0; i < temp.size(); i++) {
// 获取哈希表当前 i 的头结点
MapNode<K, V> head = temp.get(i);
while (head != null) {
System.out.println("key = " + head.key + ",
val = " + head.value);
head = head.next;
}
}
System.out.println();
}
}
public class Rehashing {
public static void main(String[] args)
{
// 创建一个哈希表
Map<Integer, String> map = new Map<Integer, String>();
// 插入元素[<50, "I">, <700, "Love">, <76, "Data">,
//<85, "Structure">, <92, "and">, <73, "Jing">, <101, "Yu">]
map.insert(50, "I");
map.printMap();
map.insert(700, "Love");
map.printMap();
map.insert(76, "Data");
map.printMap();
map.insert(85, "Structure");
map.printMap();
map.insert(92, "and");
map.printMap();
map.insert(73, "Jing");
map.printMap();
map.insert(101, "Yu");
map.printMap();
}
}
哈希算法的应用
哈希算法在日常生活中的应用非常普遍,包括信息摘要(Message Digest),密码校验(Password Verification),数据结构(编程语言),编译操作(Compiler Operation),Rabin-Karp 算法(模式匹配算法),负载均衡等等。
当你注册一个网站在客户端输入邮箱和密码时,客户端会对用户输入的密码进行 hash 运算,然后在服务端的数据库中保存用户密码的 Hash 值,从而保护用户的数据。
C++ 当中的 unordered_set & unordered_map ,以及 Java 中 HashSet & HashMap和 Python 中的 dict 等各种编程语言均实现了哈希表数据结构。
Rabin-Karp 算法利用哈希来查找字符串的任意一组模式,并且可以用来检查抄袭。
可以利用一致性哈希解决负载均衡问题。
同样可以用于版本校验、防篡改、密码校验,此外还广泛应用于各类数据库当中(包括MySQL、Redis等等)。
关于哈希算法应用的详细内容大家可以看看参考资料。
参考资料
[1] https://www.zhihu.com/question/26762707/answer/890181997
[2] https://hit-alibaba.github.io/interview/basic/algo/Hash-Table.html
[3] 严蔚敏老师的《数据结构(C语言)》版。
[4] https://www.cs.princeton.edu/~rs/AlgsDS07/10Hashing.pdf
[5] http://courses.csail.mit.edu/6.006/fall09/lecture_notes/lecture05.pdf
[6] http://courses.csail.mit.edu/6.006/fall11/lectures/lecture10.pdf
[7] https://www.cse.cuhk.edu.hk/irwin.king/_media/teaching/csc2100b/tu6.pdf
*本文整理自其他文章,仅供学习使用,侵权必删。