软考中级-软件设计师-查缺补漏
提要:设计模式、关系数据库、编译原理CFG
1 计算机与软件工程知识
1.1 计算机系统基础知识
计算机性能指标
平均无故障时间MTTF
平均修复时间MTTR
平均无故障工作时间MTBF
可靠性MTTF/(1+MTTF)
可用性MTBF/(1+MTBF)
可维护性1/(1+MTTR)
海明码
https://www.cnblogs.com/godoforange/p/12003676.html
多媒体
试题(13)
数字语音的采样频率定义为8kHz, 这是因为~ 。
A. 语音信号定义的频率最高值为4kHz
B. 语音信号定义的频率最高值为8kHz
C. 数字语音传输线路的带宽只有8kHz
D. 一般声卡的采样频率最高为每秒8 于次
试题(13) 分析
本题考查多媒体基础知识。
语音信号频率范围是300Hz - 3.4kHz, 也就是不超过4kHz, 按照奈奎斯特定律, 要保持话音抽样以后再恢复时不失真, 最低抽样频率是2 倍的最高频率, 即8kHz 就可以保证信号能够正确恢复, 因此将数字语音的采样频率定义为8kHz 。
参考答案
( 13 ) A
试题(14)
使用图像扫描仪以300DPI 的分辨率扫描一幅3X4 平方英寸的图片, 可以得到( 14) 像素的数字图像。
(14)33004300=9001200 。
关键路径

正规式
关键词:正规式、编译原理、正规集、正则定义
https://blog.csdn.net/starter_____/article/details/86659588
https://blog.csdn.net/jxch____/article/details/78909757
编译原理
关键词:编译过程、词法分析、语法分析、语义分析、代码生成
程序语言中的词(符号)的构成规则可由正规式描述, 词法分析的基本任务就是识别出源程序中的每个词。
语法分析是分析语句及程序的结构是否符合语言定义的规范, 对于语法正确的语句, 语义分析是判断语句的含义是否正确, 因此判断语句的形式是否正确是语法分析阶段的工作。
有限自动机DFA

Cache
Cache与主存地址映射由硬件完成
浮点数运算
过程:对阶 -> 尾数运算 -> 规格化
对阶:小数(阶码小)向大数(阶码大)看齐,尾数右移。
平均CPI、MIPS计算


1.2 系统开发和运行知识
位示图

页面变换表
关键词:页面大小、物理地址、逻辑地址

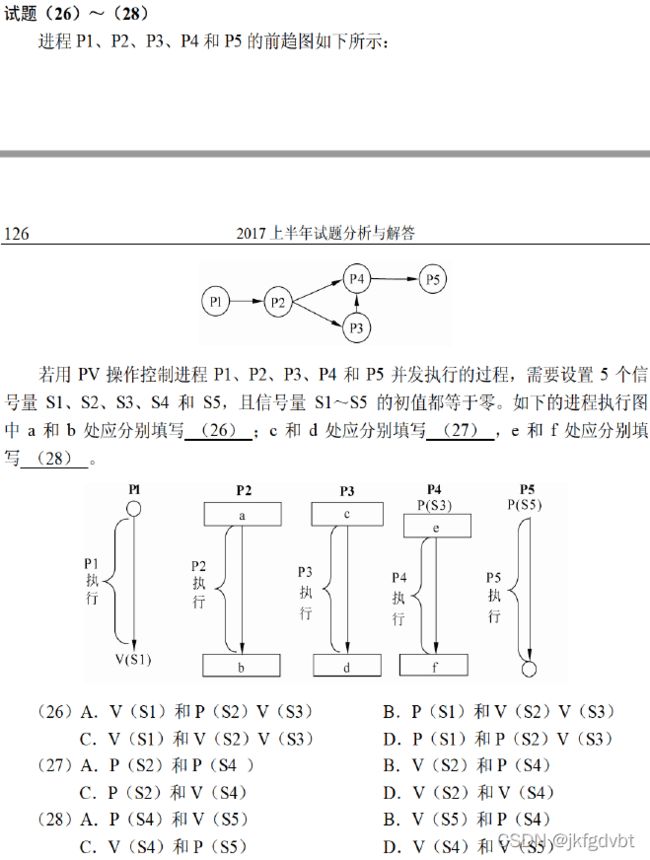
PV操作
关键词:PV操作、信号量机制
需要什么资源就P什么资源,提供什么资源就V什么资源

客户机/服务器体系结构

1.3 面向对象基础知识
多继承
在面向对象方法中, 对象是基本的运行时实体, 一组大体上相似的对象定义为一个类。有些类之间存在一般和特殊关系, 在定义和实现一个类的时候, 可以在已经存在的类的基础上来进行, 把已经存在的类所定义的属性和行为作为自己的内容, 并加入新的内容, 这种机制就是超类(父类)和子类之间共享数据和方法的机制(即继承)。在继承的支持下, 不同对象在收到同一消息是可以产生不同的结果, 这就是多态。
定义一个类时继承多于一个超类称为多重继承。使用多重继承时, 多个超类中可能定义有相同名称而不同含义的成员, 就可能会造成子类中存在二义性的成员。例如下图所示为典型的”钻石问题“, 类B 和C 都继承A, 类D 继承B 和C 。若A 中有一个方法,B 和C 进行覆盖, 而D 没有进行覆盖, 那么D 应该继承B 中的方法版本还是C 中的方法版本就无法确定, 从而产生二义性。

多态
多态的实现受到继承的支持, 利用类的继承的层次关系, 把具有通用功能的消息存放在高层次, 而不同的实现这一功能的行为放在较低层次。当一个客户类对象发送通用消息请求服务时, 它无需知道所调用方法的特定子类的实现, 是根据接收对象的具体情况将请求的操作与实现的方法进行连接, 即动态绑定, 以实现在这些低层次上生成的对象给通用消息以不同的响应。
1.4 网络与信息安全知识
HTTP协议
HTTPS (Hyper Text Transfer Protocol over Secure Socket Layer ) 是以安全为目标的HTTP 通道, 即使用SSL 加密算法的HTTP 。
加密算法
RSA 是一种非对称加密算法, 由于加密和解密的密钥不同, 因此便于密钥管理和分发, 同时在用户或者机构之间进行身份认证方面有较好的应用;
SHA-1 是一种安全散列算法, 常用于对接收到的明文输入产生固定长度的输出, 来确保明文在传输过程中不会被篡改;
MD5 是一种使用最为广泛的报文摘要算法;
RCS 是一种用于对明文进行加密的算法, 在加密速度和强度上, 均较为合适, 适用于大量明文进行加密并传输。
证书、认证机构
用户可在一定的认证机构( CA ) 处取得各自能够认证自身身份的数字证书, 与该用户在同一机构取得的数字证书可通过相互的公钥认证彼此的身份;当两个用户所使用的证书来自于不同的认证机构时, 用户双方要相互确定对方的身份之前, 首先需要确定彼此的证书颁发机构的可信度。即两个CA 之间的身份认证, 需交换两个CA 的公钥以确定CA 的合法性, 然后再进行用户的身份认证。
1.5 标准化、信息化和知识产权基础知识
软件著作权
依照《计算机软件保护条例》的相关规定, 计算机软件著作权的归属可以分为以下情况。
- 独立开发
这种开发是最普遍的情况。此时, 软件著作权当然属于软件开发者, 即实际组织开发、直接进行开发, 并对开发完成的软件承担责任的法人或者其他组织;或者依照自己具有的条件独立完成软件开发, 并对软件承担责任的自然人。 - 合作开发
由两个以上的自然人、法人或者其他组织合作开发的软件, 一般是合作开发者签定书面合同约定软著作权归属。如果没有书面合同或者合同并未明确约定软件著作权的归属, 合作开发的软件如果可以分割使用的, 开发者对各自开发的部分可以单独享有著作权;但是行使著作权时, 不得扩展到合作开发的软件整体的著作权。如果合作开发的软件不能分割使用, 其著作权由各合作开发者共同享有, 通过协商一致行使; 不能协商一致, 又无正当理由的, 任何一方不得阻止他方行使除转让权以外的其他权利, 但是所提收益应当合理分配给所有合作开发者。 - 委托开发
接受他人委托开发的软件, 一般也是由委托人与受托人签订书面合同约定该软件著作权的归属; 如无书面合同或者合同未作明确约定的, 则著作权人由受托人享有。 - 国家机关下达任务开发
由国家机关下达任务开发的软件, 一般是由国家机关与接受任务的法人或者其他组织依照项目任务书或者合同规定来确定著作权的归属与行使。这里需要注意的是, 国家机关下达任务开发, 接受任务的人不能是自然人, 只能是法人或者其他组织。但如果项目任务书或者合同中未作明确规定的, 软件著作权由接受任务的法人或者其他组织享有。 - 职务开发
自然人在法人或者其他组织中任职期间所开发的软件有下列情形之一的, 该软件著作权由该法人或者其他组织享有。(一)针对本职工作中明确指定的开发目标所开的软件;( 二)开发的软件是从事本职工作活动所预见的结果或者自然的结果; (三)主要使用了法人或者其他组织的资金、专用设备、未公开的专门信息等物质技术条件所开发并由法人或者其他组织承担责任的软件。但该法人或者其他组织可以对开发软件的自然人进行奖励。 - 继承和转让
软件著作权是可以继承的。软件著作权是属于自然人的, 该自然人死亡后, 在软件著作权的保护期内, 软件著作权法的继承人可以依照继承法的有关规定, 继承除署名权以外的其他软件著作权权利, 包括人身权利和财产权利。软件著作权属于法人或者其他组织的, 法人或者其他组织变更、终止后, 其著作权在条例规定的保护期内由承受其权利义务的法人或者其他组织享有; 没有承受其权利义务的法人或者其他组织的, 由国家 享有。
商标法
我国商标法第六条规定: “国家规定必须使用注册商标的商品, 必须申请商标注册,未经核准注册的, 不得在市场销售。”
目前根据我国法律法规的规定必须使用注册商标的是烟草类商品。
知识产权
试题(12)
甲、乙两人在同一天就同样的发明创造提交了专利申请, 专利局将分别向各申请人通报有关情况, 并提出多种可能采用的解决办法。下列说法中, 不可能采用( 12) 。
A. 甲、乙作为共同申请人
B. 甲或乙一方放弃权利并从另一方得到适当的补偿
C. 甲、乙都不授予专利权
D. 甲、乙都授予专利权
试题(12) 分析
本题考查知识产权知识。
专利权是一种具有财产权属性的独占权以及由其衍生出来和相应处理权。专利权人的权利包括独占实施权、转让权、实施许可权、放弃权和标记权等。专利权人对其拥有的专利权享有独占或排他的权利,未经其许可或者出现法律规定的特殊情况, 任何人不得使用, 否则即构成侵权。这是专利权(知识产权)最重要的法律特点之一。
参考答案
( 12) D
1.6 软件开发新进展
软件过程模型
https://www.jb51.net/article/218744.htm
瀑布模型、原型化模型、增量或迭代的阶段化开发、螺旋模型等都是典型的软件过程模型, 要求考生理解这些模型的优缺点以及适用的场合。螺旋模型是一个风险驱动的过程模型, 因此要求开放人员必须具有丰富的风险评估知识和经验, 否则因为忽视或过于重视风险造成问题。在对测试风险评估后, 可以降低过多测试或测试不足带来的风险。而且, 螺旋模型是一个迭代的模型, 维护阶段是其中的一个迭代。螺旋模型适用于大规模的软件项目开发。
敏捷开发
极限编程:敏捷开发方法是一个强调灵活性和快速开发的一种开发方法, 有多种具体的方法,其中极限编程是敏捷方法中最普遍的一种方法。极限编程包含12 个实践操作。其中, 集体所有权表示任何开发人员可以对系统任何部分进行改变, 结对编程实际上存在一个非正式的代码审查过程, 可以获得更高的代码质量。据统计, 结对编程的编码速度与传统的单人编程相当。
1.7 计算机专业英语
2 软件设计
2.1 结构化分析与设计
设计图

UML图
UML2.0 及后续版本提供了13 种图, 部分图用于刻画系统的静态方面, 如类图、对象图等; 部分图刻画系统的动态方面, 如序列图、状态图、通信图和活动图等。
序列图
关键词:场景、以时间顺序组织、

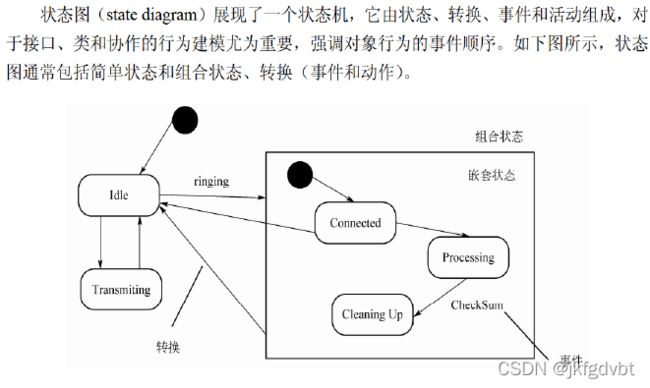
状态图
关键词:状态机、行为的事件顺序
通信图
关键点:收发的消息有序号

活动图
一个活动到另一个活动的流程

设计的模块结构
改进设计质量

内聚
https://dontla.blog.csdn.net/article/details/104769406?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=1
巧合内聚、逻辑内聚、时间内聚、过程内聚

设计模式
观察者模式
http://c.biancheng.net/view/1317.html
2.2 面向对象分析与设计
面向对象开发阶段
关键词:架构师、软件开发阶段
采用面向对象技术进行软件开发时, 需要进行面向对象分析(OOA) 、面向对象设计(OOD) 、面向对象实现和面向对象测试几个阶段。分析阶段的目的是为了获得对应用问题的理解, 确定系统的功能、性能要求, 在此阶段主要关注系统的行为, 明确系统需要提供什么服务。在设计阶段, 采用面向对象技术将OOA 所创建的分析模型转化为设计模型, 其目标是定义系统构造蓝图。在实现阶段(面向对象程序设计) , 系统实现人员选用一种面向对象程序设计语言, 采用对象、类及其相关概念进行程序设计, 即实现系统。
2.3 数据库应用分析与设计
共享锁、排它锁
在多用户共享的系统中, 许多用户可能同时对同一数据进行操作, 可能带来数据不一致问题。为了解决这类问题, 数据库系统必须控制事务的并发执行, 保证数据库处于一致的状态, 在并发控制中引入两种锁: 排他锁( Exclusive Locks, 简称X 锁)和共享锁( Share Locks, 简称S 锁)。
排他锁又称为写锁, 用于对数据进行写操作时进行锁定。如果事务T 对数据A 加上X 锁后, 就只允许事务T 读取和修改数据A, 其他事务对数据A 不能再加任何锁, 从而也不能读取和修改数据A, 直到事务T 释放A 上的锁。
共享锁又称为读锁, 用于对数据进行读操作时进行锁定。如果事务T 对数据A 加上了S 锁后,事务T 就只能读数据A 但不可以修改,其他事务可以再对数据A 加S 锁来读取,只要数据A 上有S 锁, 任何事务都只能再对其加S 锁(读取)而不能加X 锁(修改)。
关系、关键字

2.4 软件实现
2.5 软件测试
语句覆盖测试、路径覆盖测试、McCabe度量法
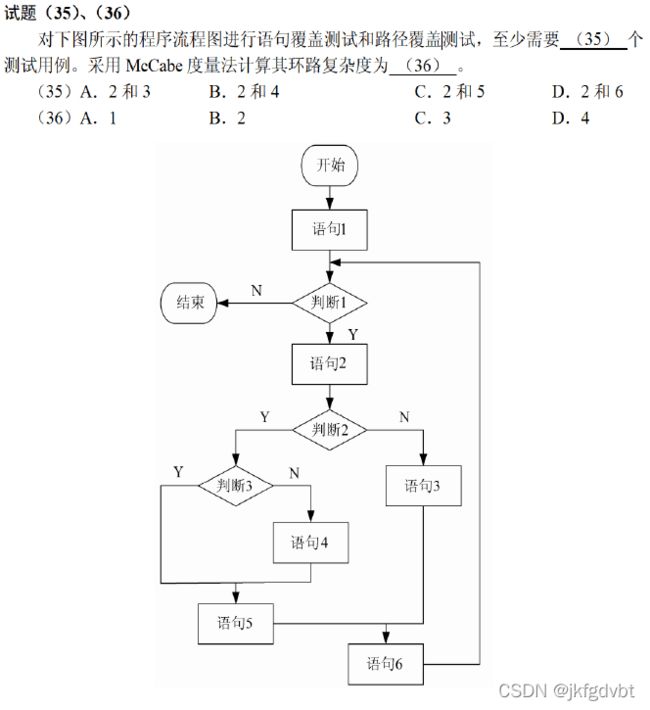
语句覆盖和路径覆盖是两种具体的白盒测试方法,语句覆盖是指设计若干测试用例, 覆盖程序中的所有语句, 而路径覆盖是指设计若干个测试用例, 覆盖程序中的所有路径。


https://blog.csdn.net/t_1007/article/details/53034408
环路复杂度 = 区域数 = 判定节点数 + 1 = 边数 - 节点数 + 2