2023.02.26 学习周报
文章目录
- 摘要
- 文献阅读
-
- 1.题目
- 2.摘要
- 3.介绍
- 4.模型
-
- 4.1 SESSION-PARALLEL MINI-BATCHES
- 4.2 SAMPLING ON THE OUTPUT
- 4.3 RANKING LOSS
- 5.实验
-
- 5.1 数据集
- 5.2 验证方式
- 5.3 baselines
- 5.4 实验结果
- 6.结论
- 深度学习
-
- 元胞自动机
-
- 1.定义
- 2.构成
- 3.特性
- 4.思想
- 5.统计特征
- 流形学习
-
- 1.降维
- 2.空间
- 3.距离
- 4.聚类与降维
- 5.流形
- 6.为什么用流形
- 总结
摘要
This week, I read an article related to the sequential recommendation system, this article proposes a method based on Recurrent Neural Network, which models the whole session and aims to solve the problem that recommendations can only be made based on short session data. Considering the actual situation, this article makes some modifications to the classical Recurrent Neural Network, mainly embodied in the ranking loss function, so as to make the model more suitable for this particular problem. This article compares the model with two datasets on four baselines, the experimental results show that the method used in this article has been significantly improved. In addition, I learn Cellular Automata and Manifold Learning; In the process of learning Cellular Automata, I explain its advantages and ideas from many aspects; In the process of Manifold Learning, I understand manifolds from two aspects: why to use manifold distance and what manifold is.
本周,我阅读了一篇与顺序推荐系统相关的文章,文章提出了一种基于循环神经网络的方法,它对整个会话进行建模,旨在解决只能基于短会话数据进行推荐的问题。文章考虑了实际情况,对经典的循环神经网络进行一些修改,主要体现在排名损失函数,以此让模型更适合于这个特定问题。文章将模型与两个数据集在四个基线上进行相比,实验结果表明文章使用的方法得到显著改进。此外,我学习了元胞自动机和流形学习,在学习元胞自动机的过程中,我从多个方面去说明它的优势与思想;在学习流形学习的过程中,我从为什么要用流形距离以及流形是什么两个方面去理解流形。
文献阅读
1.题目
文献链接:Session-based recommendations with recurrent neural networks
2.摘要
We apply recurrent neural networks (RNN) on a new domain, namely recommender systems. Real-life recommender systems often face the problem of having to base recommendations only on short session-based data (e.g. a small sportsware website) instead of long user histories (as in the case of Netflix). In this situation the frequently praised matrix factorization approaches are not accurate. This problem is usually overcome in practice by resorting to item-to-item recommendations, i.e. recommending similar items. We argue that by modeling the whole session, more accurate recommendations can be provided. We therefore propose an RNN-based approach for session-based recommendations. Our approach also considers practical aspects of the task and introduces several modifications to classic RNNs such as a ranking loss function that make it more viable for this specific problem. Experimental results on two data-sets show marked improvements over widely used approaches.
3.介绍
问题:对于缺少user-items矩阵的情况下,矩阵分解法不可用,而采用基于邻域的方法解决,但是基于领域的方法一般只会考虑session最后一个事件(比如user的最后一次点击),而忽略了前缀的session。
方案:本篇文章利用RNN的特性(LSTM和GRU的记忆性)来优化session-based recommendation。
本文贡献:
1)首次将递归神经网络(RNN)应用于推荐系统;
2)以往的推荐系统只考虑到用户的最后一次点击情况,而忽略了过去的点击信息;
3)通过对整个session进行建模,可以提出更为准确的建议。因此,文章提出了一种基于RNN的基于会话的推荐方法。
本文工作:
1)证明了RNN可以用于session-based recommendation;
2)文章不仅解决了对稀疏序列数据建模的问题,还设计了适配于该推荐任务的ranking loss function。
4.模型

1)推荐模型的初始化输入是用户进入该网站点击的第一个项目;
2)GRU的输入是session当前的输入item,输出是下一个item;
3)模型的输出是item的预测偏好,即每个item成为session下一个item的可能性;
4)文章通过实验证明了weighted one-hot representation优于embedding layer,其中weighted的含义是权重值随时序向前递减;
5)文章通过实验证明了将输入介入到深层GRU有助于提高模型表现效果。
4.1 SESSION-PARALLEL MINI-BATCHES
该任务可以对序列不等长的情况进行序列补长,即做Padding,如下图所示:
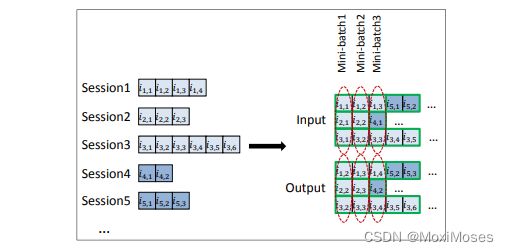
当一个batch内的session结束时,会用这个batch以外的session去填补,此时模型的参数需要重新设置。
4.2 SAMPLING ON THE OUTPUT
文章中提到由于item数量过大,文章将对正样本和负样本分别采样计算得分及更新权重。文章做了一个假设,missing item,因此文章中的负样本为该batch中其他训练数据中的item。
4.3 RANKING LOSS
推荐系统的核心是基于相关性的项目排名。文章使用了Pairwise ranking,即比较正样本和负样本的得分,并确保正样本的损失要低于负样本。文章使用了两种基于Pairwise ranking的loss function:
1)BPR:矩阵分解法,公式如下:
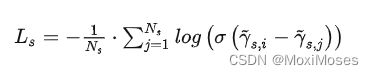
其中:Ns指采样大小,r s,i指desired item的得分,r s,j指负样本的得分。
2)TOP1:正则估计,公式如下:

由于正样本会被用于负样本,即这里加入正则化项的目的是为了稳定性。
5.实验
5.1 数据集
两个数据集:
1)RecSys Challenge 2015,网站点击流,并去除单点击session和验证集,其中不包含于训练集的item。
2)Youtube-like OTT video service platform Collection,作者自己收集的数据。
5.2 验证方式
两个指标:recall@20和MRR
方式:通过逐步检查session的下一个event的item排名来进行评估
5.3 baselines
1)POP:顺序推荐训练集中最受欢迎的item;
2)S-POP:推荐当前session中最受欢迎的item;
3)Item-KNN:推荐与实际item相似的item,相似度被定义为session向量之间的余弦相似度
4)BPR-MF:一种矩阵分解法,新会话的特征向量为其内的item的特征向量的平均,把它作为用户特征向量。
5.4 实验结果
如下图所示,实验结果表明物品协同过滤的表现更好。

如下图所示,总结了性能最佳的参数化。文章证明了adagrad优化效果最好,并且单层GRU表现最好。
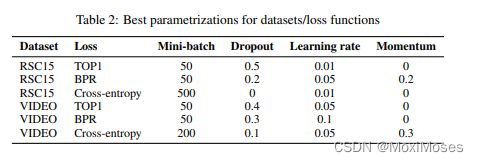
实验结果表明:
1)增加GRU的维度可以提升效果;
2)神经网络明显优于Item-KNN;
3)tanh作为神经网络输出的激活层更佳;
4)文章设计的TOP1 loss function略优于BPR。

6.结论
文章首次将RNN应用到新的领域(Session-based Recommendation),针对本次任务,作者修改了最基本的GRU,还设计了RNN的训练、评估方法及ranking loss,以更好地适应任务。通过实验表明,文章提出的方法可以显著优于用于此任务的最新基线。
深度学习
元胞自动机
1.定义
元胞自动机:把一个空间划分成网络,每一个点表示一个元胞;它们的状态赋值,在网格中用颜色的变化来表示;在事先设定的规则下,元胞的演化就用网格颜色的变化来描述。
通过对元胞自动机这些网络中格点的不同定义,以及初始条件的不同,可以模拟出不同的现象和过程。它用简单的局域相互作用表现复杂系统的整体行为及其时间演化。
元胞自动机有三个显著的特点,能高效地模拟许多复杂现象:
1)大规模同步并行;
2)局域相互作用;
3)结构简单。
2.构成
元胞自动机由元胞、元胞空间、邻居及规则四部分组成:
1)元胞:元胞自动机最基本的部分。元胞的状态是生还是死,随着时间的推移,元胞的状态不断地变化;
2)元胞空间:由多个元胞组成的元胞空间;
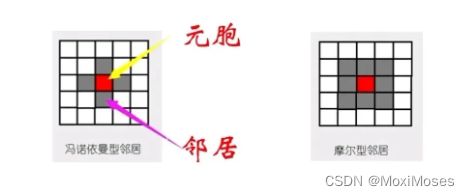
3)邻居:冯诺依曼型邻居和摩尔型邻居;
4)规则:元胞自动机根据规则进行局部元胞间的相互作用而引起全局变化。
简单来说,元胞自动机可以视为由一个元胞空间和定义于该空间的变换函数所组成。
A、元胞空间的几何划分
任意维数的欧几里德空间规则划分。对于一维元胞自动机,元胞空间划分只有一种;而高维的元胞自动机,元胞空间的划分则可能有多种形式;对于常见的二维自动机,元胞空间通常可按三角形、四边形或六边形三种网格排列。

1)三角网格拥有较少的邻居数目,但在某些时候很有用。缺点是计算机的表达与显示不方便。
2)四边形网格直观简单,特别适合在计算机环境下进行表达显示。
3)六边形网格能较好地模拟各向同性的现象,因此模型能更加自然而真实。缺点是计算机的表达与显示不方便。
B、边界条件
在理论上,元胞空间在各个维向上是无限延展的。但在实际应用过程中,无法在计算机上实现这一理想条件。
C、构形
某个时刻在元胞空间上所有元胞状态的空间分布组合。在数学上,它通常可以表示为一个多维的整数矩阵。
3.特性
1)离散性:元胞自动机是高度离散的。它不仅表现在空间和时间上离散,而且在函数值,即元胞的状态值也是离散的。
2)动力学演化的同步性:元胞自动机具有利用简单的,局部规则的和离散的方法,描述复杂的,全部的和连续系统的能力。
3)相互作用的局部性:元胞自动机的规则是局部的,而动力学行为规则是全局的,在模拟的过程中,具体的演化过程也是局部的,即仅同周围的元胞有关系。
4.思想
基于个体的自底向上的研究方法
5.统计特征
1)平稳型:当其在初始条件为中心的一个元胞状态为生时,在经过有限步演化后生的元胞比率趋于平稳。
2)周期型:当其在初始条件为中心的一个元胞状态为生时,在经过有限步演化后生的元胞比率趋于某一周期性的变化。
3)混沌型:自任何初始状态开始,经过一定时间演化后,处于一种完全无序随机的状态,几乎找不到任何规律。
4)复杂型:在演化的过程中可能产生复杂的结构,这种结构既不是完全的随机混乱,又没有固定的周期和状态。
流形学习
1.降维
降维的本质:换个角度、坐标系以及空间去重新审视数据。

2.空间
所谓换一个空间,就是换一种距离的度量手段,即两个点之间的距离。
在欧式空间中,两点之间的距离:

在流形学习中,这种度量手段换成了测地线距离、分散距离等等。不同的算法,采用不一样的定义。
3.距离
现在有一个问题,如何计算北京到纽约的距离?
根据欧式空间的思想,北京到纽约应该是穿过地心的一条直线;但在球形空间下,这种距离的度量手段,就不太适用了;于是采用测地线,即沿着球面走的一个曲线。

上图中,从聚类思想上看,①和③相似性高,①和②相似性低;但是明明①和②距离更近,①和③距离更远;从流形思想上看,①可以沿着周围的点一步步走到③,却无法沿着周围的点一步步走到②。
4.聚类与降维
聚类:将2维中的点,进行分类,即根据样本之间的相似度归堆。
降维(流形学习):将高维度降维到低维度后,再进行后续操作,即去掉冗余信息量或噪声。
5.流形
二维到一维:
如果用二维坐标来表示一个圆,我们没有办法让这个二维坐标系上的所有点都是这个圆上的点。也就是说,用二维坐标来表示这个圆其实是有冗余的。
在极坐标下,一个圆只用x轴就能被唯一确定。圆心在原点的圆,只需要一个参数就能确定:半径。当你连续改变半径的大小,就能产生连续不断的”能被转换成二维坐标“表示的圆。因此,二维空间中的圆就是一个一维流形。

6.为什么用流形
1)将原来在欧氏空间中适用的算法加以改造,使得它工作在流形上,直接或间接地对流形的结构和性质加以利用;
2)直接分析流形的结构,并试图将其映射到一个欧氏空间中,在得到的结果上运用以前适用于欧氏空间的算法来进行学习。
总结
本周,我学习了元胞自动机的相关知识,它是一个时间和空间都离散的动力系统;散布在规则格网中的每一元胞取有限的离散状态,遵循同样的作用规则,依据确定的局部规则作同步更新;大量元胞通过简单的相互作用而构成动态系统的演化。我学习了流形学习相关的知识,从为什么要用流形距离以及流形是什么去了解其中的关键点。由于本周对降维的知识未学习完,因此下周会补充关于降维的知识,以及继续机器学习的相关知识。