Spring Data JPA
Spring Data JPA
什么是 JPA
JPA (Java Persistence API) 是 Sun 官方提出的 Java 持久化规范。它为 Java 开发人员提供了一种对象/关联映射工具来管理 Java 应用中的关系数据。他的出现主要是为了简化现有的持久化开发工作和整合 ORM 技术,结束现在 Hibernate,TopLink,JDO 等 ORM 框架各自为营的凌乱局面。JPA 在充分吸收了现有 Hibernate,TopLink,JDO 等ORM框架的基础上发展而来的,具有易于使用,伸缩性强等优点。从上面的解释中我们可以了解到JPA 是一套规范,而类似 Hibernate,TopLink,JDO 这些产品是实现了 JPA 规范。
了解了什么是 JPA,我们来看看本文的主角——spring data jpa。
Spring Data JPA
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套 JPA 应用框架,底层使用了 Hibernate 的 JPA 技术实现,可使开发者用极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率。
什么意思呢?如果用过Hibernate或者MyBatis的话,就会知道对象关系映射(ORM)框架有多么方便。但是Spring Data JPA框架功能更进一步,为我们做了 一个数据持久层框架几乎能做的任何事情。
目录
- Spring JPA集成
- 基础查询实例
- 复杂查询+分页
#1. Spring JPA集成
#1.1 项目配置
如截图所示,需要导入对应的组件,其他的和正常创建SpringBoot一致。需要加入的组件
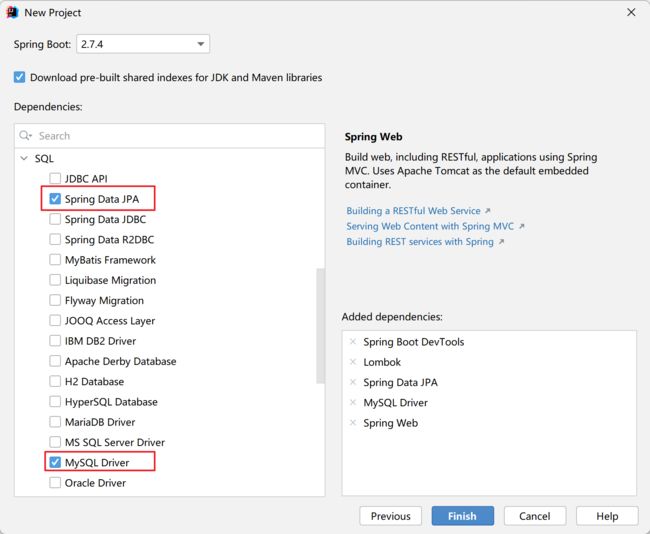
#1.2 配置文件配置
修改application.yml文件进行如下配置:
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql:///test
hikari:
username: root
password: root
jpa:
hibernate:
#可选参数
#create 启动时删数据库中的表,然后创建,退出时不删除数据表
#update 如果启动时表格式不一致则更新表,原有数据保留
ddl-auto: update
show-sql: true
#2. 基础查询实例
#2.1 类创建
#2.1.1 实体类创建
@Data
@Entity
@Table(name = "user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
}
对应的注解意思如下:
- @Data:lombok注解,生成对应的getter(),setter(),有参构造方法,无参构造方法等。
- @Entity:表明该类是jpa的一个实体
- @Table:映射到具体的数据库中的表
- @Id: 主键
- @GeneratedValue:生成该值的策略
IDENTITY: 采用数据库ID自增长的方式来自增主键字段,Oracle 不支持这种方式;
AUTO: JPA自动选择合适的策略,是默认选项;
SEQUENCE: 通过序列产生主键,通过@SequenceGenerator 注解指定序列名,MySql不支持这种方式
TABLE: 通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。
- @Column: 显示建立该表的字段连接关系,默认情况会将驼峰命名转成xx_xxx进行映射。
#2.1.2 Dao实体创建[简单]
public interface UserDao extends JpaRepository {
}
直接测试下:
需要注意在第一次执行时配置文件中的
ddl-auto: create之后执行前需要把这个配置修改为update
@SpringBootTest
class UserDaoTest {
@Resource
UserDao userDao;
// 新增一条数据
@Test
void testSave(){
User user = new User();
user.setName("李四");
User save = userDao.save(user);
System.out.println(save);
}
// 根据ID查询
@Test
void testFindOne(){
System.out.println(userDao.findById(1).get());
}
// 删除所有
@Test
void deleteAll(){
userDao.deleteAll();
}
// 查询所有
@Test
void findAll(){
System.out.println(userDao.findAll());
}
// 批量新增
@Test
void saveAll(){
List users = new ArrayList<>();
users.add(User.builder().name("张三").age(18).address("河南郑州").build());
users.add(User.builder().name("李四").age(18).address("河南洛阳").build());
users.add(User.builder().name("王五").age(19).address("河南焦作").build());
users.add(User.builder().name("赵六").age(20).address("河南郑州").build());
List list = userDao.saveAll(users);
System.out.println(list);
}
// 排序
@Test
void findAllWithSort(){
System.out.println(userDao.findAll(Sort.by(Sort.Direction.DESC,"name")));
}
// 分页
@Test
void findAllWithPage(){
// withPage 第几页,下标从0开始
// ofSize 每页多少条数据
Page page = userDao.findAll(Pageable.ofSize(2).withPage(0));
System.out.println("共有多少条数据:"+page.getTotalElements());
System.out.println("共有多少页:"+page.getTotalPages());
// 当前页的内容
System.out.println(page.getContent());
}
}
上面的这些方法,都是使用的父接口中的提供好的方法
#2.1.3 Dao实体创建[复杂]
修改实体类,新增几个属性
@Data
@Entity // 标识当前类是JPA的实体类
@Table(name = "user") // 当前类映射数据库中的那张表
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class User {
@Id // 主键
@GeneratedValue(strategy = GenerationType.IDENTITY) // 自增主键
private Integer id;
@Column(name = "name")
private String name;
@Column
private Integer age;
@Column
private String address;
}
修改DAO接口
public interface UserDao extends JpaRepository {
// 根据name查询 findBy属性名
List findByName(String name);
// 根据name和age同时查询 findBy属性名And属性名
List findByNameAndAge(String name,Integer age);
// 根据name或者age查询 findBy属性名Or属性名
List findByNameOrAge(String name,Integer age);
// 模糊查询
List findByAddressLike(String address);
}
对应继承的类作用:
- JpaRepository<实体类型,主键类型>:封装了基础的CURD操作。
对应的操作类型:
- SQL 语句查询:通过**@Query**注解, nativeQuery : false(使用jpql查询) | true(使用本地查询 :sql查询),第一个参数则为?1,第二个参数则为?2以此类推。
- 方法命名规则查询:
/**
* 方法名的约定:
* findBy : 查询
* 对象中的属性名(首字母大写) : 查询的条件
* Name
* * 默认情况 : 使用 等于的方式查询
*
* findByName -- 根据客户名称查询
*
* 会根据方法名称进行解析 findBy from xxx(实体类)
* 属性名称 where name =
*
* 1.findBy + 属性名称 (根据属性名称进行完成匹配的查询=)
* 2.findBy + 属性名称 + “查询方式(Like | isnull)”
* findByNameLike
* 3.多条件查询
* findBy + 属性名 + “查询方式” + “多条件的连接符(and|or)” + 属性名 + “查询方式”
*/
#2.2 测试
@Test
void findByName(){
System.out.println(userDao.findByName("李四"));
}
@Test
void findByNameAndAge(){
System.out.println(userDao.findByNameAndAge("张三",18));
}
@Test
void findByNameOrAge(){
System.out.println(userDao.findByNameOrAge("赵六",18));
}
@Test
void findByAddressLike(){
System.out.println(userDao.findByAddressLike("%郑%"));
}
#3.其他查询
#3.1 原生查询
// 原生查询
// nativeQuery = true 使用原生的SQL语句查询,需要自己写SQL语句
// ?1 表示方法中的第一个参数 ?2 表示方法中的第二个参数[如果有]
// 方法名字可以任意,原生查询中JPA不会在根据方法名自动生产SQL语句
@Query(nativeQuery = true, value = "select * from cloud2208.user where address like ?1 order by convert(address using 'gbk')")
List findByAddressLikeAndOrderByAddress(String address);
测试
@Test
void findByAddressLikeAndOrderByAddress(){
System.out.println(userDao.findByAddressLikeAndOrderByAddress("%河南%"));
}
#3.2 JPQL查询
// JPQL 查询的是类和属性 而不是表和字段
@Query(value = "select u.address from User u where u.id=?1")
String findAddressById(Integer id);
测试
@Test
void findAddressById(){
System.out.println(userDao.findAddressById(1));
}
#3.3 投影查询
// JPQL 投影查询,只查询部分字段
// JPQL 查询的是类和属性 而不是表和字段
@Query(value = "select new User(u.age,u.address) from User u where u.id=?1")
User findAgeAndAddressById(Integer id);
需要修改实体类,增加对应的带参构造
public User(Integer age, String address) {
this.age = age;
this.address = address;
}
测试
@Test
void findAgeAndAddressById(){
System.out.println(userDao.findAgeAndAddressById(1));
}
age,u.address) from User u where u.id=?1")
User findAgeAndAddressById(Integer id);
需要修改实体类,增加对应的带参构造
public User(Integer age, String address) {
this.age = age;
this.address = address;
}
测试
@Test
void findAgeAndAddressById(){
System.out.println(userDao.findAgeAndAddressById(1));
}