小白学Pytorch系列--Torch.nn API Quantized Functions(19)
小白学Pytorch系列–Torch.nn API Quantized Functions(19)

| 方法 | 注释 |
|---|---|
| parametrizations.orthogonal | |
| parametrizations.spectral_norm | |
| parametrize.register_parametrization | |
| parametrize.remove_parametrizations | |
| parametrize.cached | |
| parametrize.is_parametrized | |
| parametrize.ParametrizationList | |
| stateless.functional_call | |
| nn.utils.rnn.PackedSequence | |
| nn.utils.rnn.pack_padded_sequence | |
| nn.utils.rnn.pad_packed_sequence | |
| nn.utils.rnn.pad_sequence | |
| nn.utils.rnn.pack_sequence | |
| nn.utils.rnn.unpack_sequence | |
| nn.utils.rnn.unpad_sequence | |
| nn.Flatten | |
| nn.Unflatten | |
| nn.modules.lazy.LazyModuleMixin |
Parametrizations implemented using the new parametrization functionality in torch.nn.utils.parameterize.register_parametrization().
parametrizations.orthogonal
对一个矩阵或一组矩阵应用正交参数化或酉参数化。


>>> orth_linear = orthogonal(nn.Linear(20, 40))
>>> orth_linear
ParametrizedLinear(
in_features=20, out_features=40, bias=True
(parametrizations): ModuleDict(
(weight): ParametrizationList(
(0): _Orthogonal()
)
)
)
>>> Q = orth_linear.weight
>>> torch.dist(Q.T @ Q, torch.eye(20))
tensor(4.9332e-07)
parametrizations.spectral_norm
对给定模块中的参数应用光谱归一化。


>>> snm = spectral_norm(nn.Linear(20, 40))
>>> snm
ParametrizedLinear(
in_features=20, out_features=40, bias=True
(parametrizations): ModuleDict(
(weight): ParametrizationList(
(0): _SpectralNorm()
)
)
)
>>> torch.linalg.matrix_norm(snm.weight, 2)
tensor(1.0081, grad_fn=<AmaxBackward0>)
parametrize.register_parametrization
将参数化添加到模块中的张量。


>>> import torch
>>> import torch.nn as nn
>>> import torch.nn.utils.parametrize as P
>>>
>>> class Symmetric(nn.Module):
>>> def forward(self, X):
>>> return X.triu() + X.triu(1).T # Return a symmetric matrix
>>>
>>> def right_inverse(self, A):
>>> return A.triu()
>>>
>>> m = nn.Linear(5, 5)
>>> P.register_parametrization(m, "weight", Symmetric())
>>> print(torch.allclose(m.weight, m.weight.T)) # m.weight is now symmetric
True
>>> A = torch.rand(5, 5)
>>> A = A + A.T # A is now symmetric
>>> m.weight = A # Initialize the weight to be the symmetric matrix A
>>> print(torch.allclose(m.weight, A))
True
>>> class RankOne(nn.Module):
>>> def forward(self, x, y):
>>> # Form a rank 1 matrix multiplying two vectors
>>> return x.unsqueeze(-1) @ y.unsqueeze(-2)
>>>
>>> def right_inverse(self, Z):
>>> # Project Z onto the rank 1 matrices
>>> U, S, Vh = torch.linalg.svd(Z, full_matrices=False)
>>> # Return rescaled singular vectors
>>> s0_sqrt = S[0].sqrt().unsqueeze(-1)
>>> return U[..., :, 0] * s0_sqrt, Vh[..., 0, :] * s0_sqrt
>>>
>>> linear_rank_one = P.register_parametrization(nn.Linear(4, 4), "weight", RankOne())
>>> print(torch.linalg.matrix_rank(linear_rank_one.weight).item())
1
parametrize.remove_parametrizations
删除模块中张量的参数化。


parametrize.cached
上下文管理器,使缓存系统在注册寄存器参数化()。

parametrize.is_parametrized

parametrize.ParametrizationList
一个顺序容器,保存并管理参数化torch.nn.Module的original或original0、original1、参数或缓冲区。

stateless.functional_call

nn.utils.rnn.PackedSequence
PackedSequence将长度不同的序列数据封装成一个batch,可以直接作为RNN的输入。既然这么好用,那么如何创建PackedSequence呢?Pytorch提供了pack_padded_sequence()方法,用于创建PackedSequence。

nn.utils.rnn.pack_padded_sequence
打包一个包含可变长度填充序列的张量。

nn.utils.rnn.pad_packed_sequence


>>> from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
>>> seq = torch.tensor([[1, 2, 0], [3, 0, 0], [4, 5, 6]])
>>> lens = [2, 1, 3]
>>> packed = pack_padded_sequence(seq, lens, batch_first=True, enforce_sorted=False)
>>> packed
PackedSequence(data=tensor([4, 1, 3, 5, 2, 6]), batch_sizes=tensor([3, 2, 1]),
sorted_indices=tensor([2, 0, 1]), unsorted_indices=tensor([1, 2, 0]))
>>> seq_unpacked, lens_unpacked = pad_packed_sequence(packed, batch_first=True)
>>> seq_unpacked
tensor([[1, 2, 0],
[3, 0, 0],
[4, 5, 6]])
>>> lens_unpacked
tensor([2, 1, 3])
nn.utils.rnn.pad_sequence


>>> from torch.nn.utils.rnn import pad_sequence
>>> a = torch.ones(25, 300)
>>> b = torch.ones(22, 300)
>>> c = torch.ones(15, 300)
>>> pad_sequence([a, b, c]).size()
torch.Size([25, 3, 300])
nn.utils.rnn.pack_sequence


>>> from torch.nn.utils.rnn import pack_sequence
>>> a = torch.tensor([1, 2, 3])
>>> b = torch.tensor([4, 5])
>>> c = torch.tensor([6])
>>> pack_sequence([a, b, c])
PackedSequence(data=tensor([1, 4, 6, 2, 5, 3]), batch_sizes=tensor([3, 2, 1]), sorted_indices=None, unsorted_indices=None)
nn.utils.rnn.unpack_sequence


>>> from torch.nn.utils.rnn import pack_sequence, unpack_sequence
>>> a = torch.tensor([1, 2, 3])
>>> b = torch.tensor([4, 5])
>>> c = torch.tensor([6])
>>> sequences = [a, b, c]
>>> print(sequences)
[tensor([1, 2, 3]), tensor([4, 5]), tensor([6])]
>>> packed_sequences = pack_sequence(sequences)
>>> print(packed_sequences)
PackedSequence(data=tensor([1, 4, 6, 2, 5, 3]), batch_sizes=tensor([3, 2, 1]), sorted_indices=None, unsorted_indices=None)
>>> unpacked_sequences = unpack_sequence(packed_sequences)
>>> print(unpacked_sequences)
[tensor([1, 2, 3]), tensor([4, 5]), tensor([6])]
nn.utils.rnn.unpad_sequence


>>> from torch.nn.utils.rnn import pad_sequence, unpad_sequence
>>> a = torch.ones(25, 300)
>>> b = torch.ones(22, 300)
>>> c = torch.ones(15, 300)
>>> sequences = [a, b, c]
>>> padded_sequences = pad_sequence(sequences)
>>> lengths = torch.as_tensor([v.size(0) for v in sequences])
>>> unpadded_sequences = unpad_sequence(padded_sequences, lengths)
>>> torch.allclose(sequences[0], unpadded_sequences[0])
True
>>> torch.allclose(sequences[1], unpadded_sequences[1])
True
>>> torch.allclose(sequences[2], unpadded_sequences[2])
True
nn.Flatten
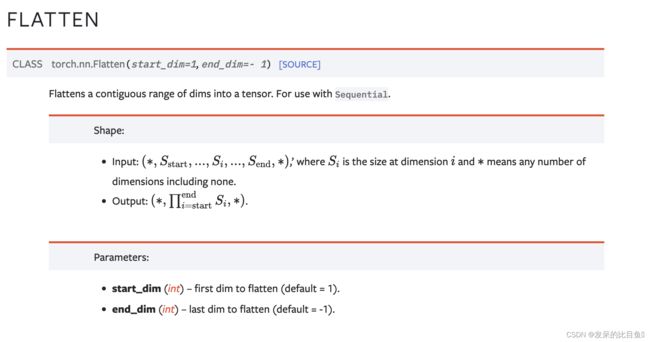
>>> input = torch.randn(32, 1, 5, 5)
>>> # With default parameters
>>> m = nn.Flatten()
>>> output = m(input)
>>> output.size()
torch.Size([32, 25])
>>> # With non-default parameters
>>> m = nn.Flatten(0, 2)
>>> output = m(input)
>>> output.size()
torch.Size([160, 5])
nn.Unflatten

>>> input = torch.randn(2, 50)
>>> # With tuple of ints
>>> m = nn.Sequential(
>>> nn.Linear(50, 50),
>>> nn.Unflatten(1, (2, 5, 5))
>>> )
>>> output = m(input)
>>> output.size()
torch.Size([2, 2, 5, 5])
>>> # With torch.Size
>>> m = nn.Sequential(
>>> nn.Linear(50, 50),
>>> nn.Unflatten(1, torch.Size([2, 5, 5]))
>>> )
>>> output = m(input)
>>> output.size()
torch.Size([2, 2, 5, 5])
>>> # With namedshape (tuple of tuples)
>>> input = torch.randn(2, 50, names=('N', 'features'))
>>> unflatten = nn.Unflatten('features', (('C', 2), ('H', 5), ('W', 5)))
>>> output = unflatten(input)
>>> output.size()
torch.Size([2, 2, 5, 5])
nn.modules.lazy.LazyModuleMixin
用于惰性初始化参数的模块的mixin,也称为惰性模块。

>>> class LazyMLP(torch.nn.Module):
... def __init__(self):
... super().__init__()
... self.fc1 = torch.nn.LazyLinear(10)
... self.relu1 = torch.nn.ReLU()
... self.fc2 = torch.nn.LazyLinear(1)
... self.relu2 = torch.nn.ReLU()
...
... def forward(self, input):
... x = self.relu1(self.fc1(input))
... y = self.relu2(self.fc2(x))
... return y
>>> # constructs a network with lazy modules
>>> lazy_mlp = LazyMLP()
>>> # transforms the network's device and dtype
>>> # NOTE: these transforms can and should be applied after construction and before any 'dry runs'
>>> lazy_mlp = lazy_mlp.cuda().double()
>>> lazy_mlp
LazyMLP( (fc1): LazyLinear(in_features=0, out_features=10, bias=True)
(relu1): ReLU()
(fc2): LazyLinear(in_features=0, out_features=1, bias=True)
(relu2): ReLU()
)
>>> # performs a dry run to initialize the network's lazy modules
>>> lazy_mlp(torch.ones(10,10).cuda())
>>> # after initialization, LazyLinear modules become regular Linear modules
>>> lazy_mlp
LazyMLP(
(fc1): Linear(in_features=10, out_features=10, bias=True)
(relu1): ReLU()
(fc2): Linear(in_features=10, out_features=1, bias=True)
(relu2): ReLU()
)
>>> # attaches an optimizer, since parameters can now be used as usual
>>> optim = torch.optim.SGD(mlp.parameters(), lr=0.01)

>>> lazy_mlp = LazyMLP()
>>> # The state dict shows the uninitialized parameters
>>> lazy_mlp.state_dict()
OrderedDict([('fc1.weight', Uninitialized parameter),
('fc1.bias',
tensor([-1.8832e+25, 4.5636e-41, -1.8832e+25, 4.5636e-41, -6.1598e-30,
4.5637e-41, -1.8788e+22, 4.5636e-41, -2.0042e-31, 4.5637e-41])),
('fc2.weight', Uninitialized parameter),
('fc2.bias', tensor([0.0019]))])
Lazy模块可以加载常规torch.nn.Parameter(即,您可以序列化/反序列化初始化的LazyModules,它们将保持初始化状态)
>>> full_mlp = LazyMLP()
>>> # Dry run to initialize another module
>>> full_mlp.forward(torch.ones(10, 1))
>>> # Load an initialized state into a lazy module
>>> lazy_mlp.load_state_dict(full_mlp.state_dict())
>>> # The state dict now holds valid values
>>> lazy_mlp.state_dict()
OrderedDict([('fc1.weight',
tensor([[-0.3837],
[ 0.0907],
[ 0.6708],
[-0.5223],
[-0.9028],
[ 0.2851],
[-0.4537],
[ 0.6813],
[ 0.5766],
[-0.8678]])),
('fc1.bias',
tensor([-1.8832e+25, 4.5636e-41, -1.8832e+25, 4.5636e-41, -6.1598e-30,
4.5637e-41, -1.8788e+22, 4.5636e-41, -2.0042e-31, 4.5637e-41])),
('fc2.weight',
tensor([[ 0.1320, 0.2938, 0.0679, 0.2793, 0.1088, -0.1795, -0.2301, 0.2807,
0.2479, 0.1091]])),
('fc2.bias', tensor([0.0019]))])
