shell基础--正则表达式行列提取
目录
一、概述:什么是正则表达式
二、基础正侧表达式
1..(点)
2.*:
3.^符号
4.和上边^相对$
5.\{n,m\}符号:
6.\{n,m\} :
7.[]符号
8.\符号
9. \<符号和\>符号:
三、扩展正则表达
1.()括号模式单元的使用:
四、字符截命令和替换命令
1.cut列提取命令:
2.文本处理工具awk
3.printf格式化输出:
4.awk基本使用
awk的保留字:
关系运算符:
正则表达式:
awk内置变量
awk的条件
6.awk流程控制
7.awk中调用脚本
五、.sed命令 文件内增,删,替换
一、概述:什么是正则表达式
正则表达式用来在文件中匹配符合条件的字符串,通配符用来匹配符合条件的文件名。其实这种区别只在shell中适用,因为用来在文件当中搜索字符串的命令,如grep、awk、sed等命令可以支持正则表达式,而在系统当中搜索文件的命令,如:ls、find、cp这些命令不支持正则表达式,所以只能使用shell自己的通配符来进行匹配了。
二、基础正侧表达式
| 元字符 |
作用 |
| . |
匹配除换行符以外的任意一个字符 |
| * |
前一个字符匹配0或任意多次 |
| ^ |
匹配行首。例:^hello会匹配以hello开头的行 |
| $ |
匹配行尾。例:hello$会匹配以hello结尾的行 |
| [] |
匹配中括号中指定的任意一个字符,只匹配一个字符。例:[aeiou]匹配任意一个元音字母。[0-9]会匹配任意一位数字。[a-z][0-9]匹配小写字和一位数字构成的两位字符。 |
| [^] |
匹配除中括号的字符以外的任意一个字符。例:[^0-9]匹配任意一位非数字字符。 |
| \ |
转义符。用于取消,将特殊符号的含义取消。 |
| \{n\} |
表示其前面一个字符恰好出现n次。例:[0-9]\{4\} 匹配4位数字。 [1][3-8][0-9]\{9\}匹配手机号 |
| \{n,\} |
表示其前面一个字符出现不小于n次。例:[0-9]\{2,\}匹配2位及以上的数字。 |
| \{n,m\} |
表示前面的一个字符至少出现n次,最多出现m次。例:[a-z]\{6,8\}匹配6-8位的小写字母。 |
在~/.bashrc文件中添加别名:
【】# vim .bashrc
alias grep='grep --color=auto'
【】# source /root/.bashrc
1..(点)
用于匹配除换行符以外的任意一个字符。例如r.t可以匹配rat、rbt。但不能匹配root。

2.*:
用于匹配前一个字符零次或任意多次,比如ab*就会匹配a、ab、abbbb等。*还可以和.组合使用。比如“.*”代表任意长度不包含换行符的匹配。
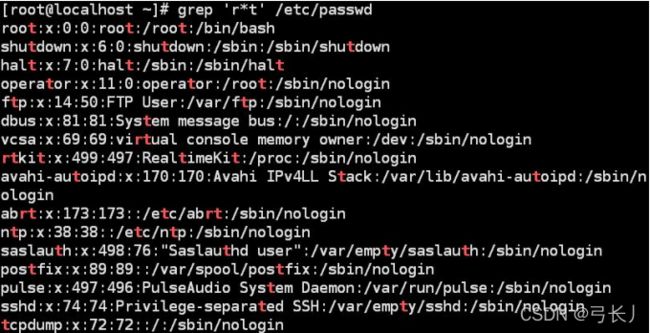
(上面例子试图找到连续的r字符紧跟t的行。因为*会匹配前一个字符零次或多次,所以出现了只找到t的情况。)
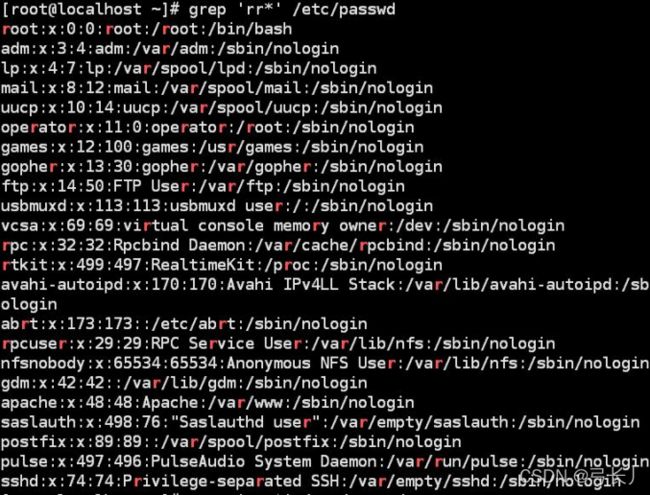
(如果是rr*代表这行字符一定要有一个r,但后边有没有r都可以,至少会匹配包含有一个r的行)

(正则是rrr*的时候会匹配最少包含两个连续r的字符串)
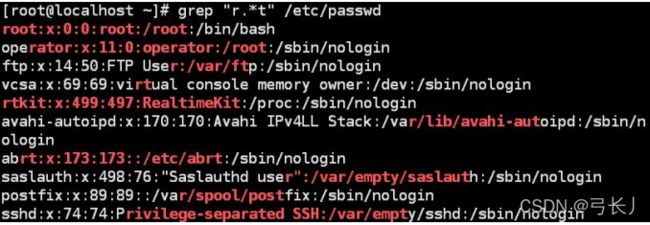
(如果把r*t换成r.*t代表查找包含字母r,后面紧跟任意长度的字符,再跟一个字母t的行)
3.^符号
称为尖角号。用于匹配开头的字符:

(匹配以root开头的行)
4.和上边^相对$
匹配的是尾部。比如:abc$匹配的就是以abc结尾的行:

(在/etc/passwd中匹配以bash结尾的行)
![]()
(匹配了以r开头,中间有一串任意字符,以h结尾的行)
5.\{n,m\}符号:
使用此符号可以更加灵活的控制字符的重复次数。
\{n\} :
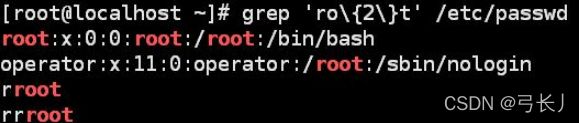
(匹配前面一个字符n次。上面匹配了包含root的行)
\{n,\} :
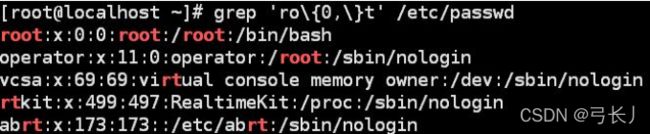
(匹配前面的一个字符至少n次以上,含n次)
6.\{n,m\} :

(匹配前面的一个字符n到m次)
7.[]符号
用于匹配方括号内出现的任意字符。比如单项选择题的选项A、B、C、D,用正则表达就是[ABCD]。如果遇到较大的范围就是[A-Z],会任意大写字母。[A-Za-z]匹配所有字母。“-”做范围限定。如果要匹配不是大写字母的字符的话需要用到“^(尖角号)”在之前的学习中^代表匹配开头的意思。但是尖角号出现在[]中。含义就是取反。[^A-Z](不是大写字母)。下面举例匹配手机号:

(首先,在文件中写入几串数字。其中有符合手机号条件的字符串。)

(想要匹配手机号,要知道手机号是11位连续的数字。第一位一定是1,所以表示为^1。第二位可能是3(移动)或8(联通),表示为[38]。后面连续9个任意数字表示为[0-9]\{9\}。)
![]()
(在匹配的结尾加上一个$符号,指定结尾为0-9九位数字结尾。否则只会匹配前面11位数字,至于之后的数字或字母并不限制。)
8.\符号
我们之前了解到.*代表的是任意长度的不包含换行的重复字符。但是如果想匹配任意长度.的时候。就需要用到\了。
例:先在/etc/passwd中插入...和..

(在/etc/passwd中查找至少有一个.的行)
9. \<符号和\>符号:
这两个符号分别用于界定左边界和右边界。比如\

(匹配hello成功。helloworld匹配失败,没有输出。)
三、扩展正则表达
顾名思义,扩展正则表达式一定是针对基础正则表达式的一些补充。扩展正则表达式比基础正则表达式多了几个重要的符号。不过在使用这些扩展符号的时候需要使用egrep命令。
| 扩展元字符 |
作用 |
| + |
前一个字符匹配1次或任意多次。例:go+gle会匹配gogle、google或gooole如果有更多个o也会匹配。 |
| ? |
前一个字符匹配0次或1次。 如colou?r可以匹配colour或color。 |
| | |
匹配两个或多个分支选择。 如was|his会匹配包含was的行,也会匹配包含his的行。 |
| () |
匹配其整体为一个字符,可以理解为由多个单个字符组成的 大字符。 如(dog)+会匹配dog、dogdog、dogdogdog等,因为被()包含的字符会当成 一个整体。 但hello (world | earth ) 会匹配hello world 及 hello earth |
1.()括号模式单元的使用:
【】# cat test
love is lover
like is liker
love is liker
like is lover
【】# egrep --color=auto "(l..e).*(l..e)" ./test
love is lover
like is liker
love is liker
like is lover
【】# egrep --color=auto "(l..e).*(\1)" ./test
#可用(\1)表示引用第一个模式单元,也就是第一次匹配第一行(l..e)在匹配到love的时候,就确定了l和e之间的..为o和v,在之后(\1)引用的时候也只会匹配love的字符串。
第二行like同理。第二行匹配时..变成了ik,所以匹配到了后边like字符串,而不能匹配love字符串。
love is lover
like is liker
四、字符截命令和替换命令
1.cut列提取命令:
子选项:-f 列号 #提取第几列
-d 分隔符 #按照指定分隔符分割列
-c 字符范围 #不依赖分隔符来区分列,而是通过字符范围(行首为0)来进行字段提取。
“n-”表示从第n个字符到行尾:“n-m”从第n个字符到第m个字符:“-m”表示从第1个字符到第m个字符。
cut命令的默认分隔符是制表符。
首先建立一个测试文件:
【】# cat cj.txt
ID Name gender Mark
1 zhaosan M 87
2 lisi M 90
3 wangwu M 9
[root@localhost ~]# cut -f 2 cj.txt #提取第二列内容
Name
zhaosan
lisi
wangwu
如果想要提取多列的时候,只要将列号用“,”分开:
【】# cut -f 2,3 cj.txt
Name gender
zhaosan M
lisi M
wangwu M
cut可以按照字符进行提取,需要注意的是“8-”代表的是提取所有行的第八个字符开始到行尾。而“10-20”代表提取所有行的第十个字符到第二十个字符。“-8”代表的是提取所有行从行首到第八个字符:
【】# cut -c -8 cj.txt
ID Name
1 zhaosa
2 lisi M
3 wangwu
(提取开头到第八个字符。结果格式还是比较乱的。因为每行字符个数不相等)
【】# cut -d ":" -f 1,3 /etc/passwd
root:0
bin:1
daemon:2adm:3
lp:4
sync:5
shutdown:6
halt:7
mail:8
(以:为分隔符,提取/etc/passwd文件的第一列和第三列)
如果想用cut命令截取df命令的第一列和第三列,格式如下:
【】# df -h | cut -d " " -f 1
Filesystem
/dev/sda3
tmpfs
/dev/sda1
/dev/sr0
(但是cut命令不够智能,因为在截取1列之后。如果继续截取2,3,4,5.....都会返回为空。因为df -h 的返回值空格太多了)
2.文本处理工具awk
1)awk是基于列的文本处理工具,awk认为文件都是结构化的,也就是说都是由单词和各种空白字符组成的,这里的“空白字符”包括空格、TAB以及连续的空格和TAB等。每个非空白的部分叫做“域”从左到右依次是第一个域第二个域等。$1、$2分别用于表示域,$0则表示全部域。
-F “” 指定分割符
$NF 最后一列
3.printf格式化输出:
print和printf区别:
使用printf 需要指定字段格式
使用print 默认输出格式
格式:printf ‘输出类型输出格式’ 输出内容
输出类型:
%ns:输出字符串。n是数字指左对齐的情况下格式宽度“%-ns表示左对齐”。
%ni:输出整数。n是数字指右对齐的情况下格式宽度“%-ni表示左对齐”。
%m.nf:输出浮点数。m和n是数字,指代输出的整数位和小数位。但整数位并不会受限。小数位四舍五入
输出格式:输出格式要加双引号
\n #换行。
\t #水平输出退格键,也就是tab键。
我们继续用cj.txt文件演示printf命令:
【】# printf '%s' $(cat ./cj.txt)
IDNamegenderMark1zhaosanM872lisiM903wangwuM89
【】#
【】#
(在使用printf命令时,如果不指定格式就会把所有输出内容连在一起。在我们使用cat等文本输出命令之所以可以按照格式输出,是因为cat命令已经设定了输出格式。那么,为了用printf输出合理的格式,应该进行如下操作)
【】# printf '%s\t%s\t%s\t%s\t\n' $(cat ./cj.txt)
ID Name gender Mark
1 zhaosan M 87
2 lisi M 90
3 wangwu M 89
(注意:在printf命令的单引号中,只能识别格式输出符号,而手工输入的空格是无效的)
如果不想把成绩当成字符串输出,二十按照整数和浮点型输出则需要进行如下操作:
【】# cat ./cj.txt
ID Name gender Mark
1 zhaosan M 87.12
2 lisi M 90.123
3 wangwu M 89.1233322
(为了测试浮点型的作用首先修改cj.txt文件)
【】# printf '%i\t%s\t%s\t%8.2f\t\n' $(cat cj.txt | grep -v Name)
1 zhaosan M 87.12
2 lisi M 90.12
3 wangwu M 89.12
(成功输出了文件内信息,浮点型只输出小数点后两位。)
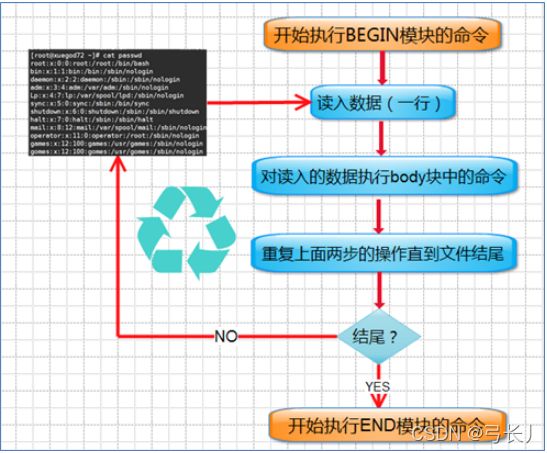
4.awk基本使用
awk使用格式:awk ‘条件1{动作1} 条件2{动作2}....’ 文件名
条件(Pattern):
一半使用关系表达式作为条件。这些关系表达式非常多。
例如:x>10 判断变量x是否大于10
x == y 判断变量x是否等于y
A !~ B 判断字符串A是否不包含能匹配B表达式的字符串
动作(Action):
格式化输出
流程控制语句
我们首先学习awk基本用法,也就是只看看格式化输出动作的作用是什么。条件类型和流程控制语句我们在后面再详细介绍:
-F “” 指定分割符
$NF 最后一列
awk的保留字:
| 条件 |
条件 |
| BEGIN |
在awk程序一开始时,尚未读取任何数据之前执行BEGIN后的动作只在程序开始执行一次 |
| END |
在awk程序处理完所有数据,即将结束时执行。 END后的动作只在程序结束时执行一次。 |
关系运算符:
关系运算符如果查找字符的话,要加双引号。
| 条件 |
说明 |
| > |
大于 |
| < |
小于 |
| >= |
大于等于 |
| <= |
小于等于 |
| == |
等于。用于判断两个值是否相等,如果是变量赋值请使用“=”号 |
| != |
不等于 |
| ~ |
判断字符串A中是否包含能匹配B表达式的字符串 |
| !~ |
判断字符串A中 是否不包含能匹配B表达式的字符串 |
正则表达式:
| /正则表达式/ |
如果在“//”中可以写入字符,也可以支持正则表达式 |
awk内置变量
| awk内置变量 |
作用 |
| $0 |
代表目前awk所读入的整行数据。我们已知awk是一行一行读入数据的,$0就代表当前读入行的整行数据。 |
| $n |
代表目前读入行的第n个字段。 |
| NF |
当前行拥有的字段(列)总数。 |
| NR |
当前awk所处理的行,是总数据的第几行。 |
| FS |
用户定义分隔符。awk的默认分隔符是空格。如果想要使用其他分隔符需要FS变量定义。 可以使用FS定义分隔符但是要制定条件为BEGIN否则第一行不生效。 |
【】# awk '{printf $2 "\t" $3 "\n"}' cj.txt #awk后的的格式要加单引号
Name gender
zhaosan M
lisi M
wangwu M
#列出第二列和第六列
在之前用cut截取df命令的结果时,结果并不尽如人意。那么试试awk命令:
【】# df -h | awk '{print $1 "\t" $3}'
Filesystem
Used
/dev/sda3 3.8G
tmpfs 224K
/dev/sda 130M
/dev/sr0 4.2G
通过awk命令可以截取指定的列,但是会发现格式并不是很规范,awk也是有命令可以调整截取后列的格式的左右对齐:
【】# df -h | awk '{printf "%-30s %-30s\n",$1,$5}'
文件系统 已用%
devtmpfs 0%
tmpfs 0%
tmpfs 1%
tmpfs 0%
/dev/mapper/cl-root 10%
/dev/sda1 14%
tmpfs 1%
tmpfs 1%
例1:显示时使用10个字符串右对齐显示。如果要是显示字符串不够10个宽度,以字符串的左边自动添加。一个字符占一个宽度,默认是右对齐。
【】# awk -F ":" '{printf "%10s\n",$1}' /etc/passwd
root
bin
daemon
adm
例2:使用10个宽度,左对齐显示:
【】# awk -F ":" '{printf "%-10s\n",$1}' /etc/passwd
rootbin
daemon
adm
例3:第1列使用15个字符宽度左对齐输出,最后一列($NF)使用15个字符宽度右对齐输出
[root@xuegod63 ~]# awk -F: '{printf "USERNAME: %-15s %15s\n",$1,$NF}'
/etc/passwd
USERNAME: root /bin/bash
USERNAME: bin /sbin/nologin
-
awk的条件
不写BEGIN每次对每行执行每个动作
BEGIN 在开头执行一次
END在结尾执行一次
awk的保留字:
| 条件 |
条件 |
| BEGIN |
在awk程序一开始时,尚未读取任何数据之前执行BEGIN后的动作只在程序开始执行一次 |
| END |
在awk程序处理完所有数据,即将结束时执行。 END后的动作只在程序结束时执行一次。 |
如果有多个BEGIN或END语句,awk会按照他们出现在程序当中的顺序来执行。
关系运算符:
关系运算符如果查找字符的话,要加双引号。
| 条件 |
说明 |
| > |
大于 |
| < |
小于 |
| >= |
大于等于 |
| <= |
小于等于 |
| == |
等于。用于判断两个值是否相等,如果是变量赋值请使用“=”号 |
| != |
不等于 |
| ~ |
判断字符串A中是否包含能匹配B表达式的字符串 |
| !~ |
判断字符串A中 是否不包含能匹配B表达式的字符串 |
正则表达式:
| /正则表达式/ |
如果在“//”中可以写入字符,也可以支持正则表达式 |
BEGIN:awk的保留字,是一种特殊的文件类型。BEGIN的执行时机是“在awk程序一开始时,尚未读取任何数据之前执行。”一旦BEGIN后的动作执行一次,当awk开始从文件中读入数据,BEGIN的条件就不再成立,所以BEGIN定义的动作只能被执行一次。
例:
【】# awk '{printf "This is a cj \n"} {printf $2 "\t" $6 "\n"}' cj.txt
This is a cj
Name
This is a cj
zhaosan
This is a cj
lisi
This is a cj
wangwu
(首先如果不加BEGIN的话,this is a cj 会在每行后打印)
【】# awk 'BEGIN {printf "This is a cj \n"} {printf $2 "\t" $4
"\n"}' cj.txt
This is a cj
Name
Mark
zhaosan 87.12
lisi
90.123wangwu 89.1233322
(添加BEGIN,让this is a cj在程序开始时执行)
END:也是awk的保留字,不过刚好和BEGIN相反。END是在awk程序处理完所有数据,即将结束时执行。END后的动作只在程序结束时执行一次。
例:
【】# awk 'END {printf "The END \n"} {printf $2 "\t" $4 "\n"}'
cj.txt
Name Mark
zhaosan 87.12
lisi 90.123
wangwu 89.1233322
The END
(在输出结尾输出“the end”这并不是文档本身的内容,而且只会执行一次。)
所有BEGIN应该放在起始处,而END语句应该放在结尾。
关系运算符:
举例来说,加入想要查找成绩大89分的学员,就可以进行如下操作:
【】# cat cj.txt | grep -v Name | awk '$4 >= 89 {printf $2 "\n"}'
lisi
wangwu
加入了条件之后,只有条件成立动作才会执行,如果条件不满足,则动作不运行。通过这个
实验大家可以发现,虽然awk是列提取命令,但是也要按行来读入的。
例:想查找用户lisi的成绩:
【】# cat cj.txt
ID Name gender Mark
1 zhaosan M 87.12
2 lisi M 90.123
3 wangwu M 89.1233322
【】# awk '$2~ /lisi/ {printf $4 "\n"}' cj.txt
90.123
(注:在awk中使用//包含的字符串,awk命令才会查找。也就是说字符串必须使用//包含,
awk命令才能正确识别。)
※正则表达式:如果想要让awk识别字符串,必须使用//包含。
例:
【】# awk '/wangwu/ {print}' cj.txt
3
wangwu M
89.1233322
#打印wangwu的成绩
(awk中如果输出字符的话,有两种处理方式。print和printf。两种方式的区别在于:
printf:可以自定义输出的模式,另外输出内容之后不自动换行,print:输出内容之后自动换行。print 中不能使用%s ,%d 或%c。)
当使用df命令查看分区使用情况时,如果只想查看真正的系统分区的使用情况,而不想查看光盘和临时分区的使用情况时:
【】# df -h | awk '/sda[0-9]/ {printf $1 "\t" $5 "\n"}'
/dev/sda3 23%
/dev/sda1 16%
(查询包含有sda数字的行,并打印第一字段和第五字段。)
5)awk内置变量
| awk内置变量 |
作用 |
| $0 |
代表目前awk所读入的整行数据。我们已知awk是一行一行读入数据的,$0就代表当前读入行的整行数据。 |
| $n |
代表目前读入行的第n个字段。 |
| NF |
当前行拥有的字段(列)总数。 |
| NR |
当前awk所处理的行,是总数据的第几行。 |
| FS |
用户定义分隔符。awk的默认分隔符是空格。如果想要使用其他分隔符需要FS变量定义。 |
例:
[root@localhost ~]# cat /etc/passwd | grep "/bin/bash" | awk '{FS=":"} {printf $1 "\t" $3 "\n"}'
root:x:0:0:root:/root:/bin/bash
(这里“:”生效了。但是并没有把第一列和第三列截取出来,继续用BEGIN命令试试)
[root@localhost ~]# cat /etc/passwd | grep "/bin/bash" | awk 'BEGIN{FS=":"} {printf $1 "\t" $3 "\n"}'
root 0
(成功截取第一和第三字段的内容)
cat /etc/passwd | grep "/bin/bash" | awk 'BEGIN {FS=":"} {printf $1 "\t" $3"\t" NR
"\t"NF"\n"}'
root 0 1 7
(分隔符是“:” 输出第一字段和第三字段 输出行号(NR) 字段数(NF))
如果只想查看sshd这个伪用户的相关信息需要:cat /etc/passwd | awk 'BEGIN {FS=":"} $1=="sshd" {printf $1 "\t" $3 "\t" NR "\t" NF "\n"}'
sshd 74 32 7
(可以看到sshd伪用户的UID是74,是/etc/passwd文件的第32行,共有7个字段)
6.awk流程控制
我们继续用cj.txt文件做练习。首先看一下文件内容:
【】# cat /root/cj.txt
ID Name gender Mark
1 zhaosan M 87.12
2 lisi M 90.123
3 wangwu M 89.1233322
假设想要统计本次成绩的总分,那么我们应该:
【】# awk 'NR==2{cj1=$4}
> NR==3{cj2=$4}
> NR==4{cj3=$4;totle=cj1+cj2+cj3;print "totle cj is" totle}' cj.txt
totle cj is266.366
接下来,演示如何实现流程控制,假设如果成绩大于90,就是goodboy:
【】# awk '{if (NR>=2) {if ($4>=90) print $2 " is a good boy \n"}}' cj.txt
lisi is a good boy
7.awk中调用脚本
例:
【】# cat pass.awk
BEGIN {FS=":"}
{print$1"\t"$3}
【】# awk -f pass.awk /etc/passwd
#用-f选项来调用这个脚
本。
root 0
bin 1
daemon 2
(此脚本可以用于/etc/passwd、/etc/shadow、/etc/group等以:为分隔符文件的查看)
五、.sed命令 文件内增,删,替换
sed主要是用来将数据进行选取,替换,删除,新增的命令。sed通过一次仅读取一行内容来对某些指令进行处理后输出。首先sed通过文件或管道读取文件内容,但sed默认并不输出直接修改源文件,而是将读入的内容复制到缓冲区域中,称之为模式空间。
其语法如下:sed [选项] ‘[动作]’ 文件名
选项:
-n 一般sed命令会把所有数据都输出到屏幕,如果加入此选项,则只会把经过sed命令处理的行输出到屏幕。
-e 允许对输入数据应用多条sed命令编辑。
-f 脚本文件名 从sed脚本中读入sed操作。和awk命令的-f非常相似。
-r 在sed中支持扩展正则表达式。
-i 用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出动作。
a 追加,在当前行后添加一行或多行。添加多行时,除最后一行外,每行末尾需要用\代表数据未完结。
c 行替换,用c后面的字符串替换原数据行。替换多行时,除
最后一行外,每行末尾需要用\代表数据未完结。
i 插入,在当前行前插入一行或多行。插入多行时,除最后一
行外,每行末尾需要用\代表数据为完结。
d 删除,删除指定的行。
p 打印,输出指定的行。
s 字符串替换,用一个字符串替换另外一个字符串。格式
为“行范围s/旧字串/新字串/g”(和vim中替换格式类似)
例:
行数据操作:
【】# sed '2p' cj.txt
ID Name gender Mark
1 zhaosan M 87.12
1 zhaosan M 87.12
2 lisi M 90.123
3 wangwu M 89.1233322
(查看cj.txt文件中第二行。p选项的确输出了第二行数据,但是sed命令还是会把所有数据都输出一次,这时就会显示为上边的效果。如果想要指定输出某行数据,就需要添加-n选项了。)
【】# sed -n '2p' cj.txt
1 zhaosan M 87.12
(添加-n选项,只输出了cj.txt中的第二行。)
如何删除文件中数据?[root@localhost ~]# sed '1,3d' cj.txt
#删除第一行到第三行的数据。
3 wangwu M 89.1233322
【】# cat cj.txt
#但是文件本身并没有进行
删除。
ID Name gender Mark
1 zhaosan M 87.12
2 lisi M 90.123
3 wangwu M 89.1233322
如何在文件中追加数据?
【】# sed '4a hello' cj.txt
#在第四行后加入hello。
ID Name gender Mark
1 zhaosan M 87.12
2 lisi M 90.123
3 wangwu M 89.1233322
hello
(“a”会在指定行后面追加数据,如果想要在指定行前面插入数据,则需要使用“i”。)
【】# sed '2i hello \
> world' cj.txt
ID Name gender Mark
hello
world
#在第二行前面插入两行数
据。
1 zhaosan M 87.12
2 lisi M 90.123
3 wangwu M 89.1233322
(如果是想追加或插入多行数据,除最后一行外,每行的末尾都要加入“\”代表数据未完结。)
【】# sed -n '2i hello \
world' cj.txt
hello
world
(还可以加入-n选项,只查看sed命令的操作)
数据替换:假设lisi成绩太好了,想要把他的成绩进行替换:
【】# cat cj.txt | sed '3c No such preson'ID
1 zhaosan M 87.12
2 lisi M 90.123
NO such preson
3 wangwu M 89.1233322
sed命令默认情况是不修改文件内容的,在确定要让sed命令直接处理文件的内容的情况下,可以使用-i选项。
例:
【】# sed -i '3c No such preson' cj.txt
【】# cat cj.txt
1
zhaosan M 1 zhaosan M 87.12
2 lisi M 90.123
No such preson
3 wangwu M 89.1233322
字符串替换:
“c”动作是进行整行替换的,如果仅仅想替换行中的部分数据,就要使用“s”动作了。
s动作的格式是:sed ‘s/旧字串/新字串/g’ 文件名
比如:
sed '5s/lod/new/2' ./test.txt
#表示替换第五行中出现的第二个old为new。
例如将wangwu的分数进行替换:
[root@localhost ~]# sed '4s/89.1233322/90/g' cj.txt
#在第四行中,把
89...换成90。
ID
1 zhaosan M 87.12
2 lisi M 90.123
3 wangwu M 90
(如果要修改的字符串是唯一的,那么可以不指定行号。但如果一个文件中存在多个相同字符的时候,不执行行号,就会替换所有旧字符为新字符。)
加入g是表示所有"旧字符串"替换成"新字符串"。如果不加入g那么会替换每行第一个查找到的"旧字符串",也就是说如果一行内出现多个"旧字符串"只替换第一个,其余不替换。g可以用数字代替表示替换某行内找到的第几个"旧字符串"。
比如:
sed '5s/lod/new/2' ./test.txt
#表示替换第五行中出现的第二个old为new。
【】# cat test.txt
hello world hello world
hello world hello worldhello world hello world
【】# sed '1s/world/linux/2' test.txt
hello world hello linux
hello world hello world
hello world hello world
替换扩展:
【】# sed '/SELINUX/ s/enforcing/xxx/g' /etc/selinux/config
#替换指定文件中含有SELINUX行中的enforcing字符串为xxx。
【】# sed '/SELINUX/ !s/enforcing/xxx/g' /etc/selinux/config
#替换指定文件中所有enforcing为xxx但是不包括含有SELINUX的行。
【】# sed '/root/,/swap/ s/xfs/ext4/g' /etc/fstab
#从含有root的行开始到含有swap的字符串结束。匹配结果中带有xfs的字符串全部替换成ext4。使用行内字符串确定替换字符串的范围。
如果想要将zhaosan成绩注释,可以进行如下操作:
【】# sed '2s/^/#/g' cj.txt
#1 zhaosan M 87.12
2 lisi M 90.123
3 wangwu M 89.1233322
(这里使用正则表达式^代表行首。)
指定范围加注释:
【】# sed '1,3s/^/#/g' cj.txt
#ID Name gender Mark
#1 zhaosan M 87.12
#2 lisi M 90.123
#3 wangwu M 89.1233322
(指定范围1-3行加#注释。)
因为在sed中只能指定范围,所以如果想要把zhaosan、wangwu注释的话。只能:
【】# sed -e 's/zhaosan//g ; s/wangwu//g' cj.txt
ID Name gender Mark
1 M 87.12
2 lisi M 90.123
3 M 89.1233322
-e选项可以同时执行多个sed动作,当然如果只执行一个动作也是可以使用-e选项的,但没什么意义。还要注意,多个动作之间要用;或回车分割。
例如还可以这么写:
【】# sed -e 's/zhaosan//g
> s/wangwu//g' cj.txt
ID Name gender Mark
1 M 87.12
2 lisi M 90.123
3 M 89.1233322
(回车后不能进行tab补全......)