新一代数据库技术在双11中的黑科技
12月13-14日,由云栖社区与阿里巴巴技术协会共同主办的《2017阿里巴巴双11技术十二讲》顺利结束,集中为大家分享了2017双11背后的黑科技。本文是《新一代数据库技术在双11中的应用》演讲整理,本文主要从数据库上云和弹性调度开始谈起,重点分享了新一代数据库以及其在双11中的应用,包括X-DB、X-KV和ESDB等。内容如下。
分享嘉宾:

张瑞:阿里巴巴研究员,阿里集团数据库技术团队负责人,经历阿里数据库技术变革历程,连续六年作为数据库总负责人参与双11备战工作。
双11是一场技术大练兵,是互联网界的超级工程。需要做到支撑尽可能高的零点峰值,给用户最好的体验;也要做到成本尽可能低,要求极致的弹性能力;还要做到整体系统的稳定。
数据库如何实现极致弹性能力
数据库上云
数据库实现弹性是比较难的,数据库对性能要求非常高,因此,必须实现数据库上云,但是如何上云呢?
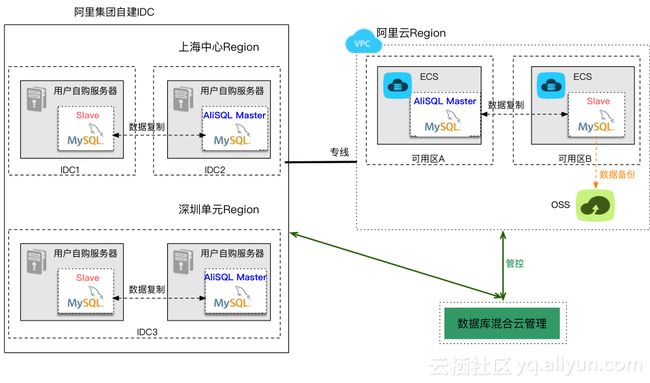
数据库上云面临以下几个难点:
1. 数据库如何上云,并快速构建混合云?
2. 如何降低虚拟化带来的性能损耗?
3. 公有云环境和内部网络的互通问题。
经过几年的探索,这些难点都已得到解决。第一,高性能ECS可以和物理机性能一样,主要使用了SPDK、DPDK技术和NVMe存储,让虚拟化损耗非常小,接近物理机;第二,数据库弹性混合云问题得到解决,可以同时管理云上和云下环境,用户可以在双11前把混合云构建起来,支撑双十一峰值。
数据库弹性调度
只有上云是远远不够的,还要进行离在线混布。而数据库实现弹性调度的两大基础条件是容器化和计算存储分离。容器性能需要与物理机持平,存储计算分离依赖于硬件的发展,25G网络和高性能分布式存储盘古让其成为可能。
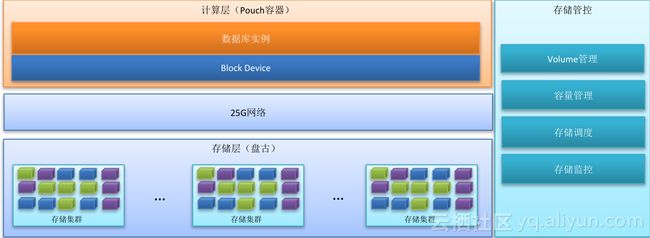
数据库存储计算分离架构如图,包括存储层、网络层和计算层,存储使用阿里自研分布式存储系统-盘古,数据库计算节点则部署在阿里自研容器(Pouch)中,除此以外,还有存储管控系统。
为了实现存储和计算分离,我们在存储上做了许多工作,包括:
- 二三异步:第三个副本异步完成,平均延时降低10%以上,4个9 latency降低3-4倍;
- QoS流控:根据前台业务负载情况控制后台IO流量,保证写入性能;
- 快速Failover:存储集群单机FO优化为5s,达到业界领先水平;
- 高可用部署:单集群四Rack部署,将数据可靠性提升到10个9。
在数据库方面我们也做了大量优化,最重要的是降低网络吞吐,以此来降低网络延迟对于数据库性能的影响。比如:redo sync优化,吞吐提升100%;由于盘古存储支持原子写,所以我们关闭Double Write Buffer,高压力下吞吐提升20%,带宽节省100%。
双11数据库混布技术
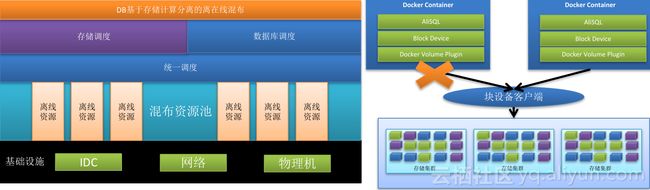
容器化和存储计算分离,使得数据库无状态化,具备调度能力。在双11高峰,通过将共享存储挂载到不同的计算集群(离线集群),实现数据库的快速弹性。
阿里新一代数据库技术
阿里最早是商业数据库,然后我们做去IOE,研发出阿里MySQL分支AliSQL和分布式中间件TDDL。2016年,我们开始思考新一代数据库技术X-DB,X代表追求极限性能,挑战无限可能的含义。
阿里的业务场景对于数据库有很高的要求:
- 数据要可扩展;
- 持续可用、数据要强一致;
- 数据量大、重要程度高;
- 数据有明显的生命周期特性,冷热数据特点鲜明;
- 交易、库存,支付等业务,操作逻辑简单,要求高性能。
因此,定义新一代数据库就要包含几个重要特点:具备数据强一致、全球部署能力;内置分布式、高性能、高可用能力;具备自动数据生命周期管理能力。
X-DB架构图
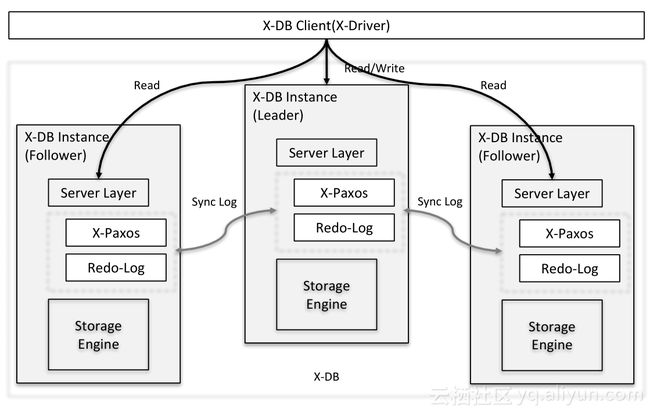
X-DB架构如图,引入Paxos分布式一致性协议解决问题;可异地部署,虽然网络延时增加,但能够保持高性能(吞吐),在同城三节点部署模式下,性能与单机持平,同时具备网络抖动的高容忍性。
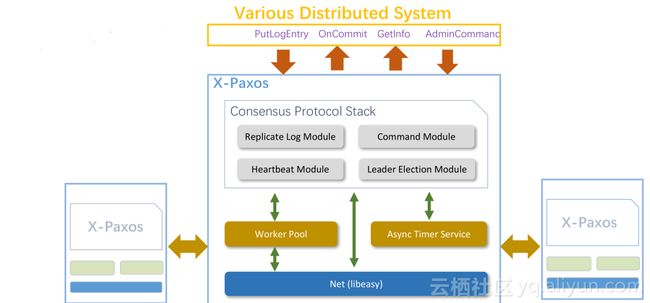
X-DB核心技术之一:高性能Paxos基础库X-Paxos是实现三节点能力的核心,可实现跨AZ、Region的数据强一致能力,实现5个9以上的持续可用率。
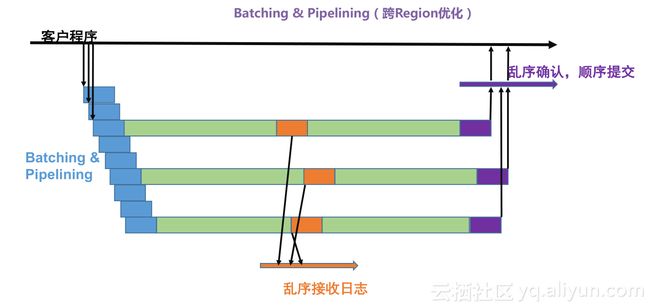
X-DB核心技术之二:Batching & Pipelining。X-DB在事务提交时,必须保证日志在数据库节点的多数派收到并提交,这是保证数据强一致基础,由于事务在提交时必须需要跨网络,这一定会导致延时增加,要保证高延时下的吞吐是非常困难的。Batching & Pipelining技术保证尽可能批量提交,数据可以乱序接收和确认,最终保证日志顺序提交。可以在高延时的情况下,保持很高的吞吐能力。
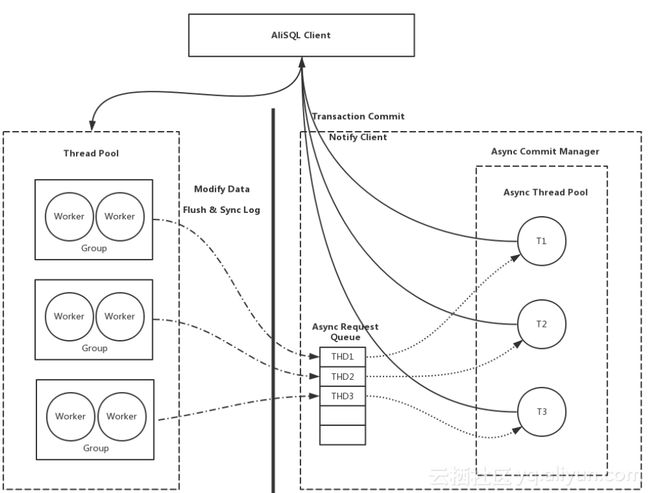
X-DB核心技术之三:异步化提交,数据库线程池在提交时会等待,为了最大程度提升性能,我们采用了异步化提交技术,最大可能保证数据库线程池可以高效工作。通过这些技术保证X-DB在三节点模式下的高吞吐量。
X-DB与MySQL Group Replication的对比测试
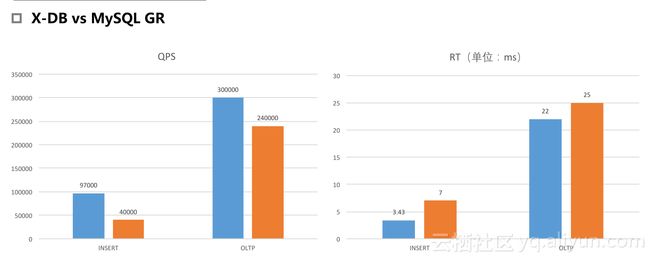
我们与Oracle官方的Group Replication作对比。在三节点同IDC部署模式下,sysbench标准化测试。Insert场景,我们可以做到MySQL官方的2.4倍,响应时间比官方低。
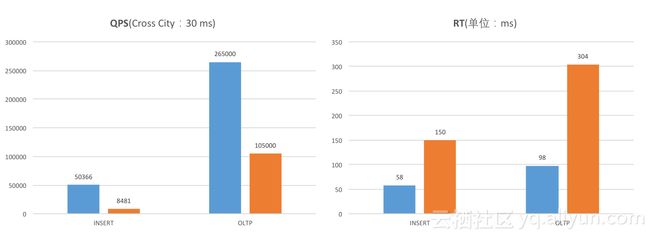
在三节点三地部署模式下,sysbench标准化测试。Insert场景,X-DB(5.04万)性能优势特别明显,是MySQL GR(0.85万)的5.94倍,响应延时X-DB(58ms)是MySQL GR(150ms)的38%。
典型应用场景
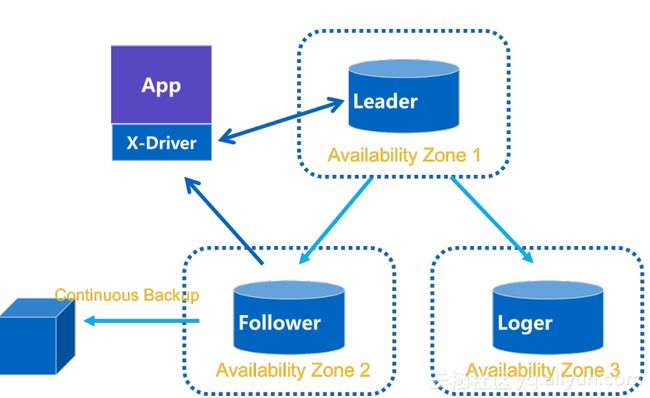
同城跨AZ部署替代传统主备模式,我们把原来主备模式变成三节点,解决跨AZ数据质量问题和高可用问题。跨AZ数据强一致,单AZ不可用数据零丢失、单AZ不可用秒级切换、切换自封闭,无第三方组件。相对主备模式零成本增加。
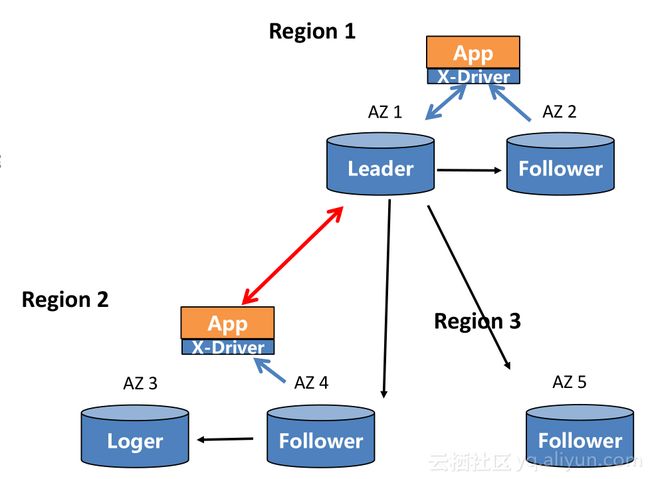
跨Region部署,用更底层的数据库技术解决异地多活问题,三地六副本(主备模式)降低为三地四副本(三地五节点四数据),对于业务来说,可以享受跨Region数据强一致,单个Region不可用零数据丢失;跨Region强同步下依然保持高性能;切换策略灵活,可以优先切换同Region,也可定制跨Region切换顺序。
数据库在双11中的黑科技
X-KV在双11中的应用
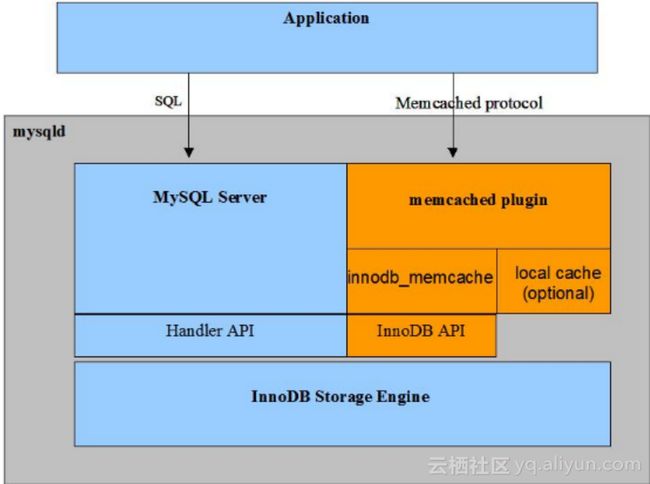
X-KV是基于MySQL Memcached plugin的增强,今年我们做了大幅度的改进,支持更多数据类型,支持非唯一索引、组合索引,支持Multi get 功能,支持Online Schema change,最大变化是通过TDDL支持SQL转换。对于业务方,X-KV优势是超高读取性能,数据强一致;减少应用响应时间,降低成本;同时支持SQL,应用可以透明迁移。
TDDL for X-KV优化如下:
- 独立KV连接池:SQL和KV连接池相互独立;变更时,两套连接池保持协同一致;应用可以快速在两套接口之间切换。
- 优化的KV通信协议:不再需要分隔符,协议实现。
- 结果集自动类型转换:字符串自动转换为MySQL类型。
交易卖家库的性能瓶颈解决方案
随着双11交易量增长,近两年交易卖家库的同步延时一直比较大,导致商户不能及时处理双11订单;且卖家库有大量复杂的查询,性能差。我们曾经通过为大卖家设置独立队列、同步链路合并操作和卖家库限流等进行优化,但仍然没有完全解决问题。
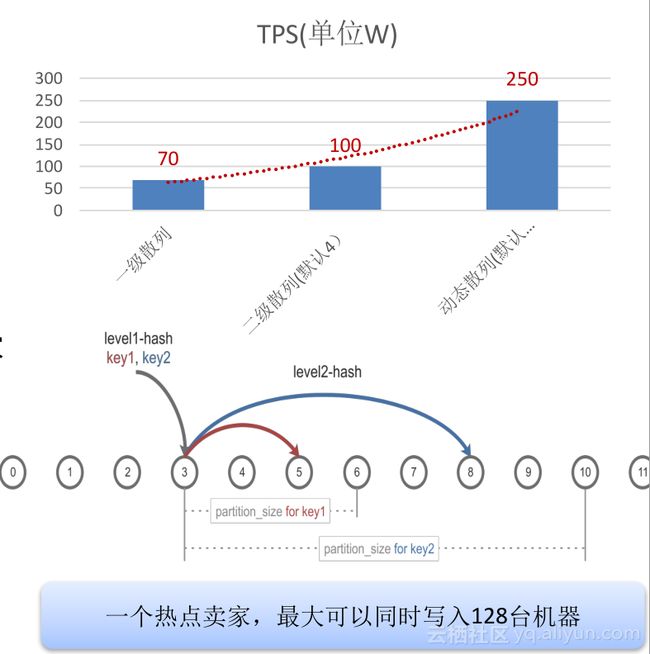
ESDB是基于ES打造的分布式文档数据库,我们在ES的基础上,支持了SQL接口,应用可以从MySQL无缝迁移到ESDB;针对大卖家,提供动态二级散列功能,解决大卖家同步的性能瓶颈。同时还做了大量的性能优化和限流保护等功能。
数据库监控系统演进
数据库秒级监控的技术挑战有很多,具体有以下四点:
1. 海量数据:平均每秒处理1000万项监控指标,峰值1400万;
2. 复杂的聚合逻辑:地域、机房、单元、业务集群、数据库主备等多维度数据聚合;
3. 实时性要求高:监控盯屏需要立即看到上一秒的监控数值;
4. 计算资源:占用尽可能少的资源进行采集和计算。
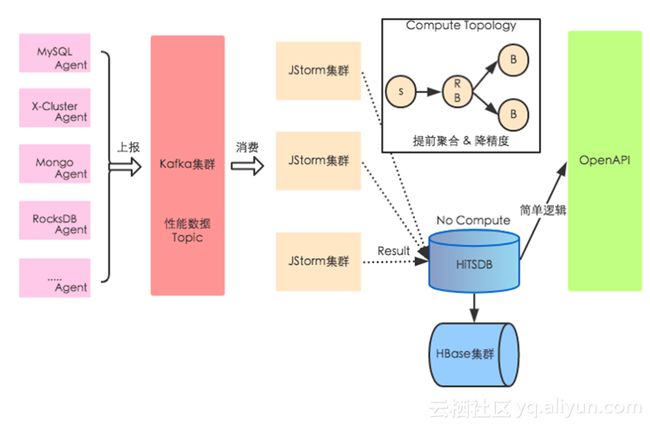
整个链路经历三代架构:第一代,Agent + MySQL;第二代,Agent + datahub + 分布式NoSQL;第三代,Agent + 实时计算引擎 + HiTSDB。
HiTSDB是阿里自研的时序数据库,通过实时计算引擎将秒级性能数据、全量SQL运行状况进行预先处理后,存储在HiTSDB中。通过第三代架构,实现了双11高峰不降低的秒级监控能力,这对我们了解系统运行状况、诊断问题是非常有帮助的。
CloudDBA在双11中的应用
阿里拥有业界最富有经验的DBA,海量的性能诊断数据。我们的目标是把阿里DBA的经验、大数据和机器智能技术结合起来,目标是三年后不再需要DBA做数据库诊断、优化等工作,而是让机器来完成数据库的智能化管理。我们认为自诊断、自优化、自运维是未来数据库技术发展的重要方向。
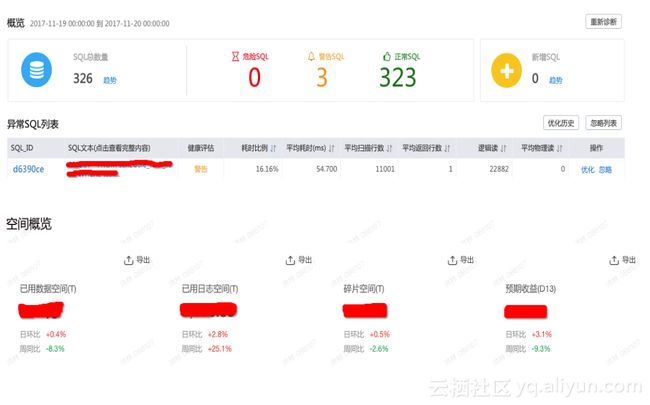
CloudDBA在今年双11也做了一些探索,通过对全量SQL以及监控数据的分析,我们实现了SQL自动优化(慢SQL调优)、空间优化(无用表无用索引分析)、访问模型优化(SQL和KV)和存储空间增长预测等功能。
展望明年双11,Higher,Faster,Smarter
更高:更高交易创建峰值;
更快:高性能数据库、高性能存储;
更智能:CloudDBA发挥更大价值。
《2017阿里巴巴双11技术十二讲》全部讲师直播回顾&资料下载,请点击进入:
https://yq.aliyun.com/articles/280798
本文由云栖社区志愿者小组云迹九州整理,王殿进校审,编辑:刁云怡。