4.无监督算法 SimCLR
有点像词向量预训练模型,这个框架可以作为很多视觉相关的任务的预训练模型,可以在少量标注样本的情况下,拿到比较好的结果。
结果
该研究一次就把无监督学习(学习后再用于分类等后续任务)的指标提升了 7-10%,甚至可以媲美有监督学习的效果。在这篇论文中,研究者发现[4]:
- 多个数据增强方法组合对于对比预测任务产生有效表示非常重要。此外,与有监督学习相比,数据增强对于无监督学习更加有用;
- 在表示和对比损失之间引入一个可学习的非线性变换(MLP)可以大幅提高模型学到的表示的质量;
- 与监督学习相比,对比学习得益于更大的批量和更多的训练步骤。
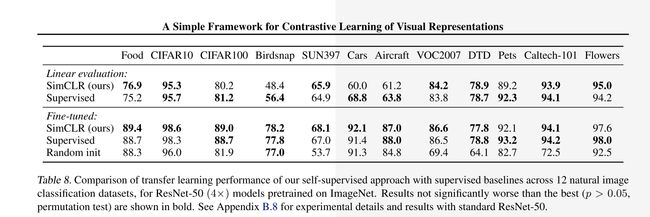
基于这些发现,他们在 ImageNet ILSVRC-2012 数据集上实现了一种新的半监督、自监督学习 SOTA 方法——SimCLR。在线性评估方面,SimCLR 实现了 76.5% 的 top-1 准确率,比之前的 SOTA 提升了 7%。在仅使用 1% 的 ImageNet 标签进行微调时,SimCLR 实现了 85.8% 的 top-5 准确率,比之前的 SOTA 方法提升了 10%。在 12 个其他自然图像分类数据集上进行微调时,SimCLR 在 10 个数据集上表现出了与强监督学习基线相当或更好的性能。

自监督情况下
固定特征提取层, 使用所有数据训练softmax分类器

小数据集fineturn
所有参数微调

迁移学习
所有数据
The Illustrated SimCLR Framework
Published March 04, 2020 in illustration
https://amitness.com/2020/03/illustrated-simclr/
近年来,众多的自我监督学习方法被提出用于学习图像表示,每一种方法都比前一种更好。但是,他们的表现仍然低于有监督的方法。当Chen等人在他们的研究论文“SimCLR:A Simple Framework for Contrastive Learning of Visual Representations”中提出一个新的框架时,这种情况改变了。SimCLR论文不仅改进了现有的自监督学习方法,而且在ImageNet分类上也超越了监督学习方法。在这篇文章中,我将用图解的方式来解释研究论文中提出的框架的关键思想。
来自儿时的直觉
当我还是个孩子的时候,我记得我们需要在课本上解决这些难题。

孩子们解决这个问题的方法是通过看左边动物的图片,知道它是一只猫,然后寻找右边的猫。
 “这样的练习是为了让孩子能够识别一个物体,并将其与其他物体进行对比。我们能用类似的方式教机器吗?”
“这样的练习是为了让孩子能够识别一个物体,并将其与其他物体进行对比。我们能用类似的方式教机器吗?”
事实证明,我们可以通过一种叫做对比学习的方法来学习。它试图教会机器区分相似和不同的东西。

对机器进行问题公式化
要为机器而不是孩子来对上述练习进行建模,我们需要做三件事:
1、相似和不同图像的样本
我们需要相似和不同的图像样本对来训练模型。
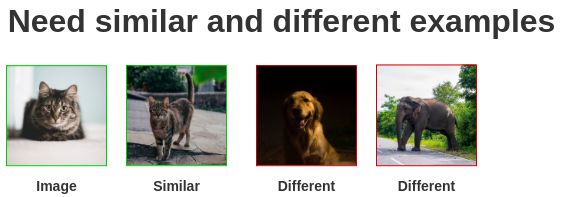
监督学习的思想学派需要人类手工创造这样的配对。为了实现自动化,我们可以利用自监督学习。但是我们如何表示它呢?

2、了解图像所表示的内容的能力
我们需要某种机制来得到能让机器理解图像的表示。

3、量化两个图像是否相似的能力
我们需要一些机制来计算两个图像的相似性。

SimCLR框架的方法
本文提出了一个框架“SimCLR”来对上述问题进行自监督建模。它将“对比学习”的概念与一些新颖的想法混合在一起,在没有人类监督的情况下学习视觉的表示。
SimCLR框架
SimCLR框架,正如全文所示,非常简单。取一幅图像,对其进行随机变换,得到一对增广图像x_i和x_j。该对中的每个图像都通过编码器以获得图像的表示。然后用一个非线性全连通层来获得图像表示z,其任务是最大化相同图像的z_i和z_j两种表征之间的相似性。

手把手的例子
让我们通过一个示例来研究SimCLR框架的各个组件。假设我们有一个包含数百万未标记图像的训练库。

1.自监督的公式 [数据增强]
首先,我们从原始图像生成批大小为N的batch。为了简单起见,我们取一批大小为N = 2的数据。在论文中,他们使用了8192的大batch。

2.论文中定义了一个随机变换函数T
该函数取一幅图像并应用 random (crop + flip + color jitter + grayscale).

对于这个batch中的每一幅图像,使用随机变换函数得到一对图像。因此,对于batch大小为2的情况,我们得到2N = 4张总图像。

2、得到图像的表示 [基础编码器]
每一对中的增强过的图像都通过一个编码器来获得图像表示。所使用的编码器是通用的,可与其他架构替换。下面显示的两个编码器有共享的权值,我们得到向量h_i和h_j。

在本文中,作者使用ResNet-50架构作为ConvNet编码器。输出是一个2048维的向量h。

3、投影头
两个增强过的图像的h_i和h_j表示经过一系列非线性Dense -> Relu -> Dense层应用非线性变换,并将其投影到z_i和z_j中。本文用g(.)表示,称为投影头。

4. 模型调优: [把相似图像的拉的更近一些]
因此,对于batch中的每个增强过的图像,我们得到其嵌入向量z。

从这些嵌入,我们计算损失的步骤如下:
a. 计算余弦相似性
现在,用余弦相似度计算图像的两个增强的图像之间的相似度。对于两个增强的图像x_i和x_j,在其投影表示z_i和z_j上计算余弦相似度。

其中
- τ是可调参数。它可以缩放输入,并扩大余弦相似度的范围[- 1,1]。
- |z_i||是该矢量的模
使用上述公式计算batch中每个增强图像之间的两两余弦相似度。如图所示,在理想情况下,增强后的猫的图像之间的相似度会很高,而猫和大象图像之间的相似度会较低。

b. 损失的计算
SimCLR使用了一种对比损失,称为“NT-Xent损失”(归一化温度-尺度交叉熵损失)。让我们直观地看看它是如何工作的。
首先,将batch的增强对逐个取出。

这个softmax计算等价于第二个增强的猫图像与图像对中的第一个猫图像最相似的概率。这里,batch中所有剩余的图像都被采样为不相似的图像(负样本对)。

然后,通过取上述计算的对数的负数来计算这一对图像的损失。这个公式就是噪声对比估计(NCE)损失:

在图像位置互换的情况下,我们再次计算同一对图像的损失。

最后,我们计算Batch size N=2的所有配对的损失并取平均值。
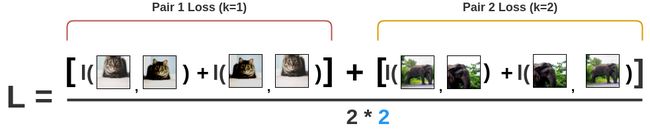
基于这种损失,编码器和投影头表示法会随着时间的推移而改进,所获得的表示法会将相似的图像放在空间中更相近的位置。
下游任务
一旦SimCLR模型被训练在对比学习任务上,它就可以用于迁移学习。为此,使用来自编码器的表示,而不是从投影头获得的表示。这些表示可以用于像ImageNet分类这样的下游任务。

目标结果
SimCLR比以前ImageNet上的自监督方法更好。下图显示了在ImageNet上使用不同自监督方法学习表示的训练线性分类器的top-1精度。灰色的十字架是有监督的ResNet50,SimCLR以粗体显示。

- 在ImageNet ilsvvc -2012上,实现了76.5%的top-1准确率,比之前的SOTA自监督方法Contrastive Predictive Coding提高了7%,与有监督的ResNet50持平。
- 当训练1%的标签时,它达到85.8%的top-5精度,超过了AlexNet,但使用带标签的数据少了100倍。
SimCLR的代码
本文作者在Tensorflow中对SimCLR的正式实现可以在GitHub上找到:https://github.com/googl-research/simclr。他们还为使用Tensorflow Hub的ResNet50架构的1倍、2倍和3倍变体提供了预训练模型:https://github.com/googresearch/simclr#。
有各种非官方的SimCLR PyTorch实现,它们已经在小型数据集上测试过,比如CIFAR-10:https://github.com/leftthomas/SimCLR和STL-10:https://github.com/Spijkervet/SimCLR。
我们还以平方根学习率缩放为基础,以更大的批次大小(最大32K)和更长的时间(最大3200个纪元)进行训练。如图B.2所示,批处理大小为8192,性能似乎已达到饱和,而训练更长的时间仍然可以显着改善

总结
因此,SimCLR为这一方向的进一步研究和改善计算机视觉的自监督学习状态提供了一个强有力的框架。
简单得讲,这篇文章最大的特点就是两个字“暴力”。
作者用了128块GPU/TPU,来处理每个minibatch 9000个以上样本,并完成1000轮的训练。
过去一年来,相继有cpc, cmc, moco出来,想要解决的共同一个问题就是,如何提高softmax中negatives的数量。其中cpc用了patch based方法,cmc用了一个memory buffer,moco用了momentum update去keep一个negative sample queue。这篇文章告诉大家,只要机子够多,batch size够大,每个batch中除了positive以外的都当negatives就已经足够了。