【大数据Hive3.x数仓开发】窗口函数案例:连续N次登录的用户;级联累加求和;分组TopN
文章目录
-
- 1 统计连续N次登录的用户(N>=2)
-
- 自连接过滤实现
- 窗口函数lead()实现
- 2 级联累加求和
-
- 自连接
- 窗口函数sum()实现
- 3 分组TopN问题
对窗口函数的讲解part见:【大数据Hive3.x数仓开发】函数–窗口函数
1 统计连续N次登录的用户(N>=2)

自连接过滤实现
连续两天登陆的用户ID:
select
distinct a_userid
from tb_login_tmp
where a.user_id = b.user_id
and cast(substr(a_logintime,9,2) as int) -1 = cast(substr(b_logintime,9,2)as int);
窗口函数lead()实现
功能:用于从当前数据中基于当前行的数据向后偏移取值
语法:lead(colName,N,defautValue)
colName:取哪一列的值
N:向后偏移N行
defaultValue:如果取不到返回的默认值
分析:
我们可以基于用户的登陆信息,找到如下规律:
连续两天登陆:用户下次登陆时间 =本次登陆以后的第二天
连续三天登陆:用户下下次登陆时间=本次登陆以后的第三天
我们可以对用户ID进行分区,按照登陆时间进行排序,通过lead函数计算出用户下次登陆时间
通过日期函数计算出登陆以后第二天的日期,如果相等即为连续两天登录。
select
userid
,logintime
--本次登陆日期的第二天
,date_add(logintime,1) as nextday
--按照用户id分区,按照登录日期排序,取下一次登录时间,取不到就为0
,lead(logintime,1,0) over (partition by userid order by logintime) as nextlogin
from tb_login;

select
uiserid
,logintime
--本次登陆日期的第三天
,date_add(login_time,2) as nextday
--按照用户id分区,按照登陆日期排序,取下下一次登录时间,取不到为0
,lead(logintime,2,0)over (partition by userid order by logintime) as nextlogin
from tb_login;
select
userid
,logintime
,date_add(login_time,N-1) as nextday
--按照用户id分区,按照登陆日期排序,取下下一次登录时间,取不到为0
,lead(logintime,N-1,0)over (partition by userid order by logintime) as nextlogin
from tb_login;
2 级联累加求和
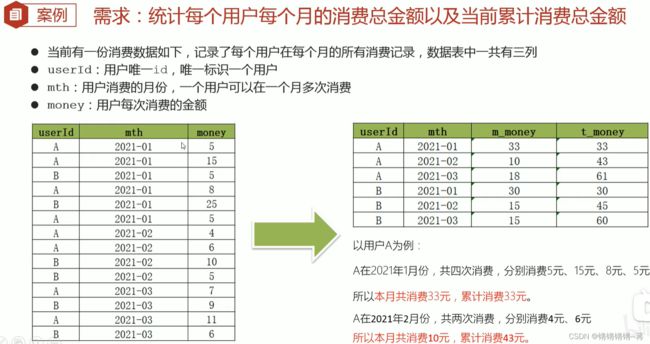
自连接
方案一:分组统计每个用户每个月的消费金额,然后构建自连接,根据条件分组聚合;
select
a.*,b.*
from tb_money_mth a join tb_mponey_mth b on a.ueserid=b.userid;
小tips:使用on a.ueserid=b.userid避免很多不必要的自连接!仔细观察笛卡尔积之后的数据,便于理解:
where b.mth <a.mth --图中是排过序的
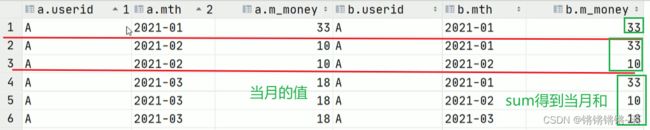
所以,最后自连接这样写:
--同个用户 同一个月的数据分到同一组 再根据用户、月份排序
select
a.userid
,a.mth
,max(a.m_money) as current)_mth_money--当月花费
,sum(b.m_money) as accumulate_money--累计花费
from tb_money_mtn a join tb_money_mtn b on a.userid=b.userid
where b.mth<=a.mth
group by a.userid,a.mth
order by a.userid,a.mth;
可以看到代码很复杂,而且代码提前创建了tb_money_mtn 这个临时表,不然代码要实现嵌套查询。

窗口函数sum()实现
方案二:分组统计每个用户每个月的消费金额,然后使用窗口聚合函数实现。
--统计每个用户每个月消费金额及累计总金额
select
userid
,mth
,m_money
,sum(m_money) over (partition by userid order by mth) as t_money
from tb_money_mtn;
Q:如何实现只计算最近三个月的累计消费金额呢?
—使用rows between 来控制累积的行范围。
比如向前一行到向后两行:(partition by userid order by mth rows between 1 preceding and 2 following)
3 分组TopN问题

基于row_number实现,按照部门分区,每个部门内部按照薪水降序排序。
select
empno
,ename
,salary
,deptno
,row_number() over (partition by deptno order by salary desc) as rn
from tb_emp;
然后取rn<3的即可。