PP-YOLO: 基于YOLOv3改进,超过YOLOv4,速度与精度齐飞的目标检测器
论文地址:https://arxiv.org/pdf/2007.12099.pdf
GitHub: https://github.com/PaddlePaddle/PaddleDetection
1、动机
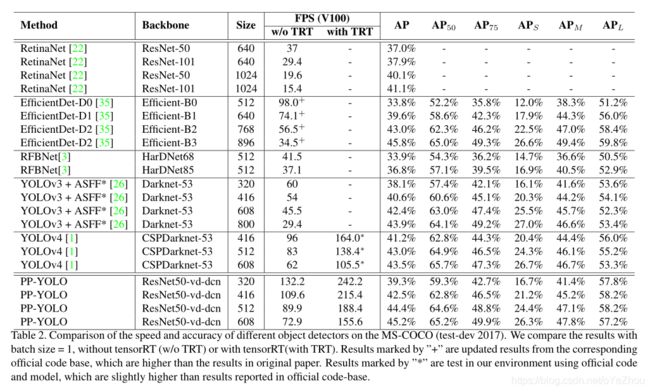
一直以来,目标检测器都难以兼顾速度和精度,常常为了在有限的硬件设备上运行而将模型阉割,虽然换来了速度的提升,但精度或多或少都会受到影响。基于这种动机,百度提出了PP-YOLO——一种基于YOLOv3+各种先进tricks改造而来的检测器,达到了不错的速度-精度trade off。这种做法与YOLOv4很像,虽没有什么明显的创新,但通过各种trick加身,得到一个更优的模型。与YOLOv4不同的是,PP-YOLO没有尝试各种backbone以及数据增强方法,仅仅使用一些几乎不增加推理代价的tricks,且其重点在于如何将这些tricks缝合到YOLOv3。PP-YOLO与各流行检测器的对比见上面的图1。
2、方法
网络由backbone+neck+head组成,整体结构如图2所示:

2.1、整体架构
Backbone:PP-YOLO使用改进后的ResNet50-vd替换了原YOLOv3中的DarkNet-53,并在最后一个stage将3*3卷积替换为DCN,从而形成 ResNet50-vd-dcn这个backbone。
Detection Neck:使用FPN构建特征金字塔。
Detection Head:head仍沿用YOLOv3的形式,一个3*3卷积+一个1*1卷积。输出的通道长度为3(K+5),K为类别数;预测map中每个位置预测三个anchor尺寸的目标,每个anchor前K个通道为K个类别的概率,接着4个通道为预测边框坐标,最后一个通道为前景-背景目标得分;交叉熵和L1损失分别用作分类和回归的loss函数;一个前景-背景损失来监督是否为前景。
2.2、所用到的tricks
PP-YOLO所用到的tricks都是已存在的,由于直接用于YOLOv3并不合适,所以这里做了一些适应性调整。
(1)Larger Batch Size
使用了更大的batch size,因为可以提高训练稳定性且得到的结果更好。同时,也对训练策略和学习率调度进行了相应的调整。
(2)EMA(指数移动平均)
在训练时,对参数进行了移动平均,这使得最终的评估效果好上很多。EMA使用指数衰减的速率对参数W进行移动平均(衰减率 设为0.9998):
设为0.9998):
![]() (1)
(1)
(3)DropBlock
这是dropout的一种形式,其将一块连续神经元一起drop掉。这里没有将DropBlock放在backbone,而是放在了FPN,因为作者发现放在backbone会导致性能下降。具体放的位置间图2 FPN中的三角形所标示的地方。
(4)IoULoss
在YOLOv3中,进行边框回归时使用的是L1 loss,而mAP的计算严重依赖IoU,所以这里使用IOU Loss来进行边框回归。与YOLOv4不同的是,没有直接替换掉原来的L1 Loss,而是增加了一个额外的分支,也即边框回归用的loss是L1+IOU。
(5)IoU Aware
在原YOLOv3中,分类概率和前景-背景得分通过相乘得到最终检测置信度,这没有考虑到定位是否准确,于是这里加了一个IOU预测分支,来对定位精度进行改进。训练时,IOU aware用在IOU预测分支上,在推理时,将预测的IoU乘到分类概率及前景-背景得分上。IoU Aware会稍微增加计算代价:参数量增加0.01%,FLOPs增加0.0001%,这代价小到可以忽略不计。
(6)Grid Sensitive
Grid Sensitive是YOLOv4中使用的一个trick。在原YOLOv3中,中心点坐标分解后的形式为:
![]()
可以看出,所得的坐标不等于 s · g 或s · (g + 1),这将使得模型很难准确预测位于网格边界上的点。这里将其该为如下形式:
![]()
这使得模型更容易预测精确位于网格边界上的边界框中心。该操作增加的FLOPS同样很小,可以忽略。
(7)Matrix NMS
Matrix NMS是受到Soft-NMS启发而开发的。Soft-NMS将其他检测得分衰减为重叠区域的单吊牌降低函数,但这种方法和传统贪婪的NMS一样是顺序执行的,不能并行处理。而Matrix NMS则可以并行处理,因此这加快了推理速度。
(8)CoordConv
其原理在于增加一个额外的坐标通道,使得卷积可以学习其位置坐标。这将允许网络可以全部学习平移不变性也可以学习不同程度的平移依赖。由于CoordConv会增加两个通道,这会增大FLOPS,所以作者没有改变backbone中的卷积,而只是改变了FPN中的1*1卷积和head中的第一个卷积层,如图2中的方块所标示的地方。
(9)SPP
使用SPP可以增加感受野,作者将其用于FPN的最上层,见图2五角星所标示的地方。SPP本身不增加参数量,但其后续卷积层的输入通道会增加,约增加了2%的参数量和1%的FLOPS。
(10)Better Pretrain Model
这里用的是百度改进后的分类准确率更高的ResNet50-vd,且不影响检测器的效率。
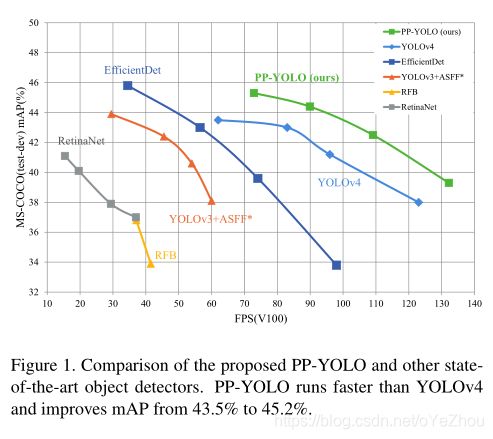
3、实验结果