【数据分析实战】基于python对Airbnb房源进行数据分析

文章目录
- 引言
- 数据加载以及基本观察
-
- 缺失值观察及处理
-
- 缺失值观察以及可视化
- 缺失值处理
- 异常值观察及处理
- 数据探索
-
- 哪个区域的房源最受欢迎?
- 哪种房型最受欢迎?它们的价格怎么样?
- 最受欢迎的房源和最不受欢迎的房源有什么特征?
- 总结与展望
引言
♂️作者简介:生鱼同学,大数据科学与技术专业硕士在读,曾获得华为杯数学建模国家二等奖,MathorCup 数学建模竞赛国家二等奖,亚太数学建模国家二等奖。
✍️研究方向:复杂网络科学
兴趣方向:利用python进行数据分析与机器学习,数学建模竞赛经验交流,网络爬虫等。
自2008年以来,客人和房东利用Airbnb扩大了旅行的可能性,并提出了一种更独特、个性化的体验世界的方式。
通过Airbnb提供的数百万个房源的数据分析是该公司的一个关键因素。这些数以百万计的房源产生了大量的数据其可以被分析并用于安全、商业决策、了解客户和供应商(房东)在平台上的行为和表现、指导营销举措、实施创新的附加服务等等。
基于上述背景和数据,我们本次主要解决下面几个问题:
- 哪个区域的房源最受欢迎?
- 哪种房型最受欢迎?它们的价格怎么样?
- 最受欢迎的房源和最不受欢迎的房源有什么特征?
本项目中的数据来源于Kaggle开放数据New York City Airbnb Open Data链接如下:
Kaggle-New York City Airbnb Open Data
需要的小伙伴可以自行下载获取。
数据加载以及基本观察
在进行数据加载之前,我们首先对数据的各个列进行解释,具体情况如下表所示:
| 列名 | 表达含义 |
|---|---|
| id | 挂牌编号 |
| name | 挂牌名字 |
| host_id | 主人编号 |
| host_name | 主人名字 |
| neighbourhood_group | 房屋所在区域 |
| neighbourhood | 房屋具体地区 |
| latitude | 经纬度 |
| longitude | 经纬度 |
| room_type | 房间类型 |
| price | 价格 |
| minimum_nights | 最少的预定夜数 |
| number_of_reviews | 评论数 |
| last_review | 最新评论 |
| reviews_per_month | 每月评论数 |
| calculated_host_listings_count | 主人拥有房屋的数量 |
| availability_365 | 可供预订的天数 |
在开始编码之前,请先确保你已经安装了对应的包,本文所用的包如下:
import pandas as pd
import missingno as msno
import seaborn as sns
在这一步中,我们将加载数据并且调用pandas中的基本函数对数据进行初步的观察。加载数据代码如下:
data = pd.read_csv('AB_NYC_2019.csv')
data.head()
结果如下:

在加载数据过后,我们需要对数据进行初步的认识与观察,这里我们调用**info()和describe()**函数来对数据进行初步的观察。代码和结果如下:
data.info()
结果如下:
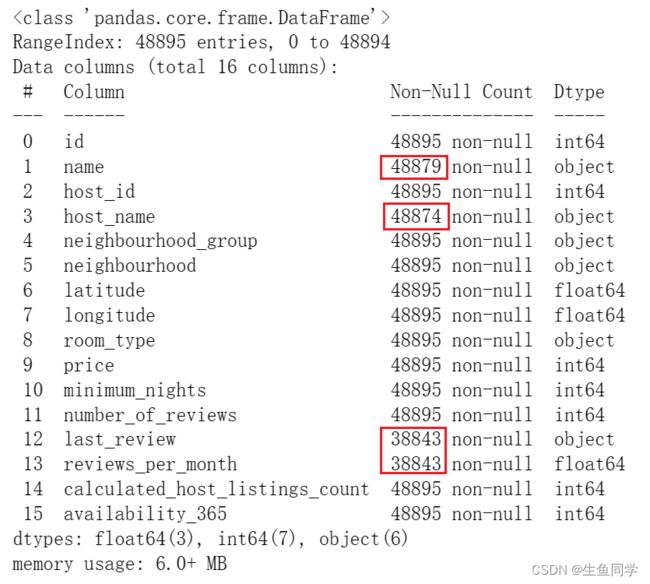
注意:在这一步中,我们观察到图中红圈标记的数据存在一定的缺失情况,这在后续的操作中需要进行处理。
接着,我们调用**describe()**进行数据的进一步观察,代码如下:
data.describe()
结果如下:
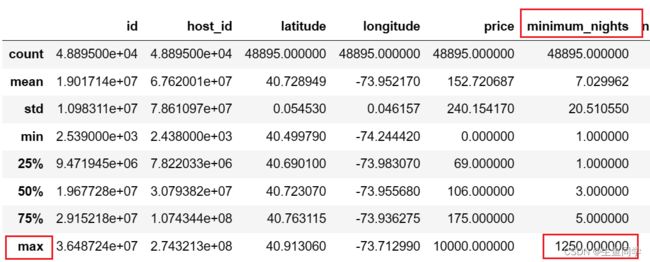
注意:在这里,我们已经发现了一个异常,这里的minimum_nights表示的是最短租赁时长。然而,它的最大值已经超过了365,我们后续需要留意。
缺失值观察及处理
缺失值观察以及可视化
在发现缺失值后,我们需要对缺失值进行有针对性的观察和处理,我们首先对其进行提取以及可视化的操作。首先提取所有缺失的列以及它们缺失的个数情况,代码如下:
missing_data = data.isnull().sum()
missing_data = missing_data[missing_data > 0]
missing_data
结果如下:

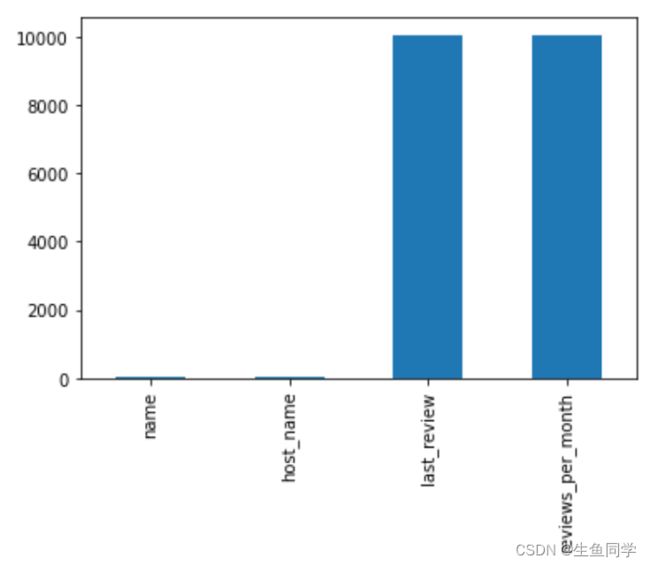
可以看到,在名字以及主人名字方面存在一定的缺失,关于评论的缺失情况比较明显且多,我们后面会进行有针对性地处理。
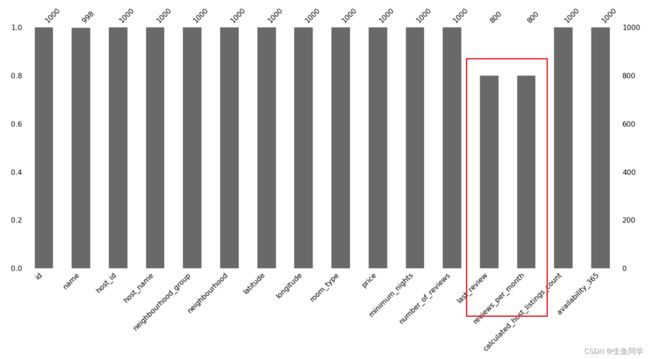
接下来我们对其进行可视化,在这里我们会使用缺失值可视化库以及柱状图来进行可视化,代码如下:
# 对数据进行采样
sample_data = data.sample(1000)
# 可视化
msno.bar(sample_data)
结果如下:
另外,我们也可以用柱状图来进行可视化,代码如下:
missing_data.plot.bar()
结果如下:
缺失值处理
在处理缺失值之前,我们首先要进行分析。
主要缺失的值有上述四列,我们对其的分析以及处理方案如下:
- name :房屋名称,无关紧要的列,准备删除。
- host_name :主人姓名,无关紧要的列,准备删除。
- last_review :最新的评论,如果该房屋不存在评论,那么这列一定为0,所以准备将其删除,保留下面的每月评论。
- reviews_per_month:保留,对缺失值填充0。
上述操作的代码如下:
# 删除了['id','host_name','last_review']三列
data.drop(['id','host_name','last_review'], axis=1, inplace=True)
# 用0填充'reviews_per_month'为Nan的数据
data.fillna({'reviews_per_month':0}, inplace=True)
异常值观察及处理
在上面的分析中,我们观察到了minimum_nights的异常情况,在这里我们使用箱线图对其进行可视化观察,代码如下:
data['minimum_nights'].plot.box()
结果如下:
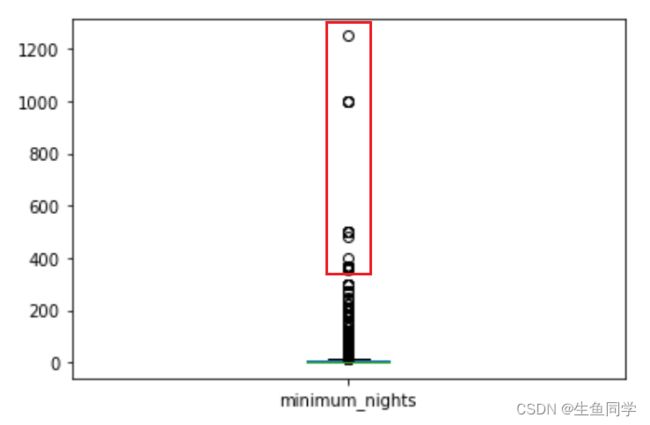
我们可以观察到,红色标记的部分即是可能的异常值,我们对其进行处理。代码如下:
# 将该列大于365的数据改为365
data.loc[data['minimum_nights'] > 365, 'minimum_nights'] = 365
数据探索
在本节中,我们将从数据出发进行合理的探索,得出一些结论。
哪个区域的房源最受欢迎?
在这个问题的探索中,我们将从两个角度考虑问题,即评论越多证明房屋的欢迎程度越高,与此同时可用天数越少证明房屋越火爆。我们首先来看看数据中有几个不同的地区,代码如下:
# 探究有几个不同的地区
data.neighbourhood_group.unique()
结果如下;
![]()
然后我们分别对针对评论数以及年度可用天数进行分组组成新的数据,代码如下:
# 根据评价对区域房源进行分析
# 评论越多越受欢迎
neighbourhood_group_reviews = data['number_of_reviews'].groupby(data['neighbourhood_group'])
neighbourhood_group_reviews_data = pd.DataFrame(neighbourhood_group_reviews.sum().sort_values(ascending = False))
neighbourhood_group_reviews_data
# 根据可用天数对区域房源进行分析
# 可用天数越小越受欢迎
neighbourhood_group_availability_365 = data['availability_365'].groupby(data['neighbourhood_group'])
neighbourhood_group_availability_365_data = pd.DataFrame(neighbourhood_group_availability_365.mean().sort_values())
neighbourhood_group_availability_365_data
两个数据所组成的新表如下:
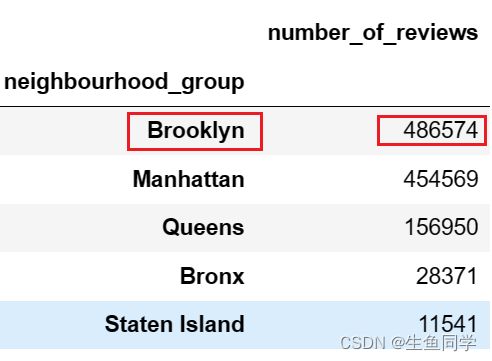
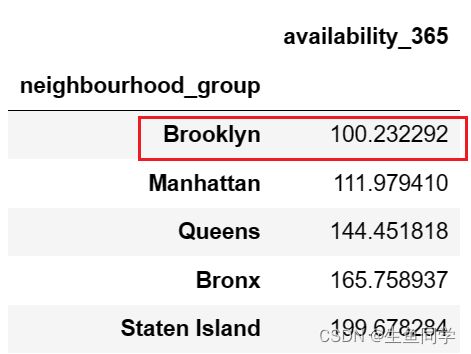
我们可以看到,不论是从年度可用天数还是评论数目来说,Brooklyn的房屋都是最受欢迎的,接下来我们利用可视化来进行更直观的观察,代码如下:
sns.barplot(x="neighbourhood_group", y="number_of_reviews", data=popular_neighbourhood_group_data, palette="RdYlBu")
sns.barplot(x="neighbourhood_group", y="availability_365", data=popular_neighbourhood_group_data, palette="RdYlBu")
结果如下:
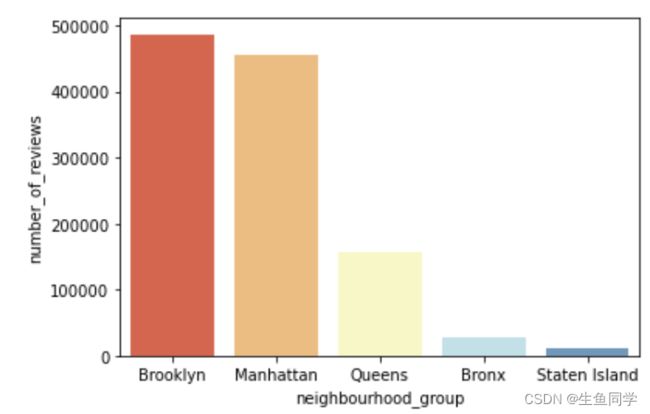
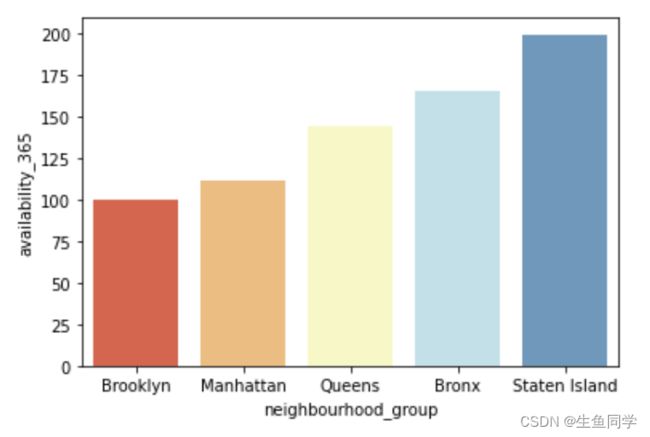
这样来看,结果就比较容易观察到了。基于上述分析,我们得出以下结论:
- Brooklyn不论是从年度可用天数还是评论数目来说,都能证明其是最受欢迎的地区。
- Brooklyn的平均年度可用天数为100左右,而其房屋评论数目的总和达到了486574的最高评论数。
- Manhattan紧随其后,受欢迎程度与Brooklyn相近,但是其不如Brooklyn受欢迎。
哪种房型最受欢迎?它们的价格怎么样?
在本节中,我们将要探索那种房子的类型最受欢迎,以及他们的价格特点。
首先,我们从全部地区的角度来观察不同房型的受欢迎程度以及其平均的价格如何。我们将要建立房型与价格、评论数目、可用天数的表格并进行可视化,代码如下:
# 建立房型与价格的表
price_room_type = data['price'].groupby(data['room_type'])
price_room_type_data = pd.DataFrame(price_room_type.mean())
# 建立房型与评论数的表
reviews_room_type = data['number_of_reviews'].groupby(data['room_type'])
reviews_room_type_data = pd.DataFrame(reviews_room_type.sum())
# 建立房型与可用天数的表
availability_365_room_type = data['availability_365'].groupby(data['room_type'])
availability_365_room_type_data = pd.DataFrame(availability_365_room_type.mean())
# 将上述表合并
popular_type_value = pd.concat([availability_365_room_type_data,reviews_room_type_data,price_room_type_data], axis=1)
popular_type_value['room_type'] = popular_type_value.index
popular_type_value.reset_index(inplace=True,drop=True)
popular_type_value
结果如下:
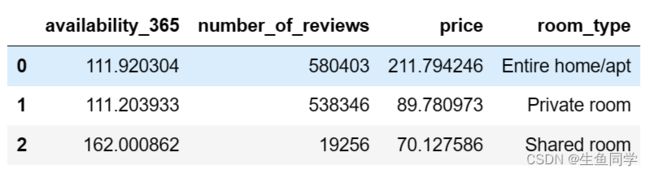
为了更直观的进行分析,我们对其进行可视化。代码如下:
sns.barplot(x="room_type", y="availability_365", data=popular_type_value, palette="RdYlBu")
sns.barplot(x="room_type", y="number_of_reviews", data=popular_type_value, palette="RdYlBu")
sns.barplot(x="room_type", y="price", data=popular_type_value, palette="RdYlBu")
结果如下:
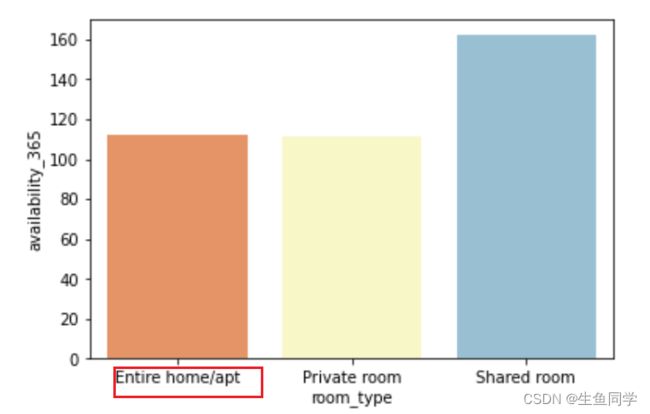
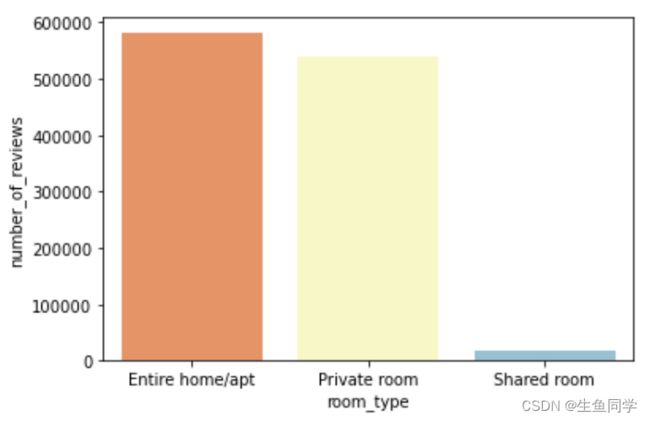
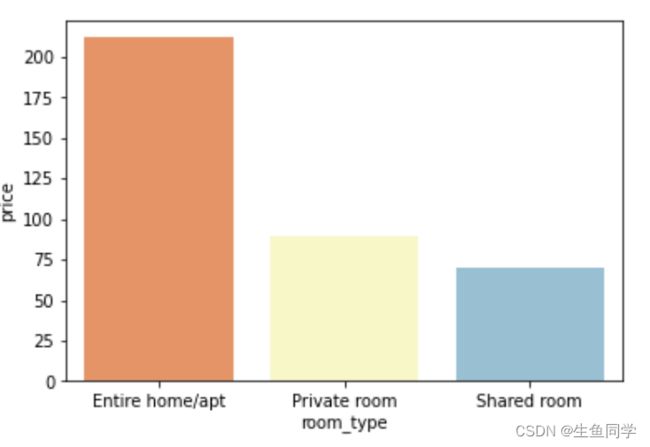
可以看出,Entire home/apt在所有的房屋类型中,所有的方面来说都是最火爆的。
接下来,我们将从不同的地区分别建立透视表进行进一步的分析与探索。
我们分别构建评论数目,地区,房间类型的透视表、年度可用天数与房间类型,地区的联系表、价格与房间类型,地区的联系表。
具体代码如下:
# 构建评论数目,地区,房间类型的透视表
sum_reviews_pivot = data.pivot_table('number_of_reviews', index='neighbourhood_group', columns='room_type', aggfunc='sum')
结果如下:
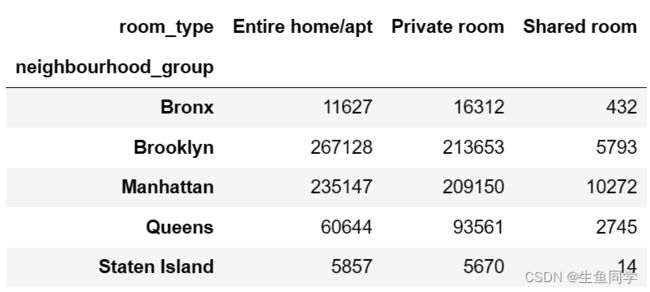
然后我们对其进行可视化,代码如下:
sum_reviews_pivot.plot.bar()
结果如下:
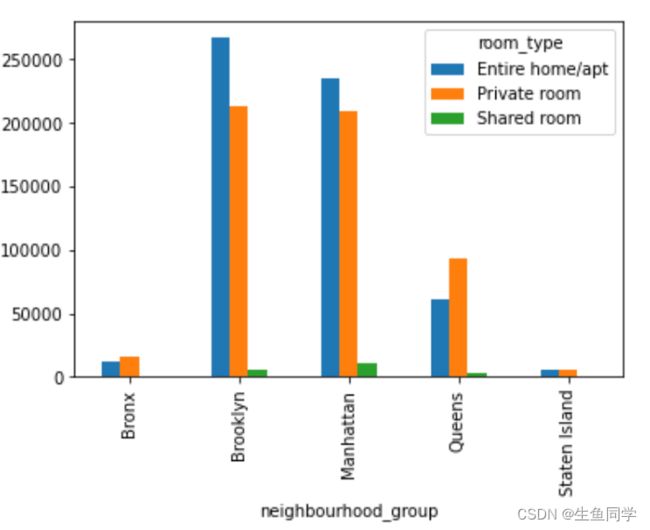
我们同样将其与年度可用天数,和价格构建透视表,然后进行可视化,代码和结果如下:
# 构建年度可用天数与房间类型,地区的联系表
mean_availability_365_pivot = data.pivot_table('availability_365', index='neighbourhood_group', columns='room_type', aggfunc='mean')
mean_availability_365_pivot.plot.bar()
# 构建价格与房间类型,地区的联系表
mean_price_pivot = data.pivot_table('price', index='neighbourhood_group', columns='room_type', aggfunc='mean')
mean_price_pivot.plot.bar()
结果如下:
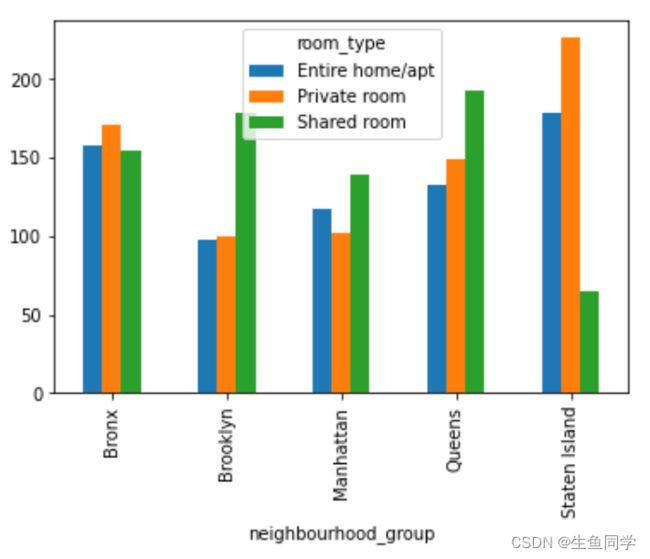
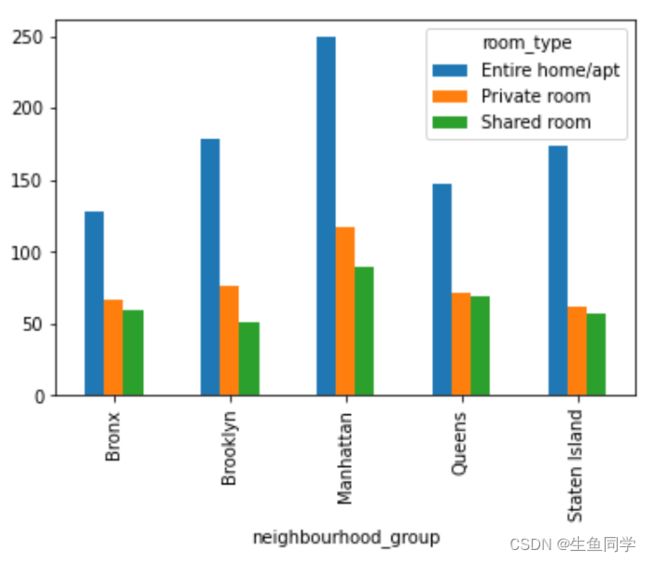
根据上述分析,我们可以得出以下结论:
- 在所有的地区总体来看,Entire home/apt都是最受欢迎的房型,但是其平均价格也是最贵的,在211左右。
- 在Brooklyn和Manhattan这两个地区,Entire home/apt都是最受欢迎的房型,但是在其他地区情况略有不同。
- 从价格来看,Manhattan的Entire home/apt是最贵的,均价在249左右。而Brooklyn相对便宜,在178左右。
最受欢迎的房源和最不受欢迎的房源有什么特征?
为了解决本节的问题,我们首先要把最受欢迎的房子和最不受欢迎的房子提取出来并且利用**describe()**查看我们所关心的信息,代码如下:
top_10 = data.sort_values(by='number_of_reviews', ascending=False).head(10)
结果如下:
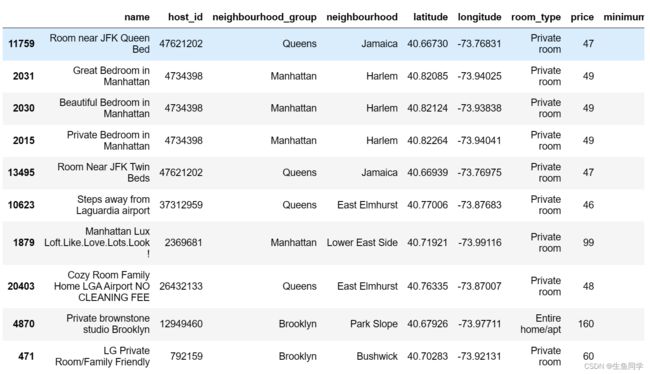
通过**describe()**进行初步观察的结果如下:
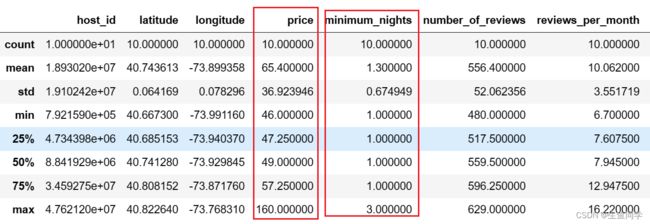
我们发现,价格数据以及最短居住时间的数据仿佛和平均值有一定的差异,我们从完整的数据取出其值并进一步对照观察。
我们先来看全局的价格平均值与最欢迎的平均值的对比,代码和结果如下:
# 全局数据各房型价格的平均值
data['price'].groupby(data['room_type']).mean()
# 最受欢迎的数据各房型价格的平均值
top_10['price'].groupby(top_10['room_type']).mean()
全局数据各房型价格平均值如下,结果如下:

最受欢迎的10个房型价格平均值如下:

我们发现最受欢迎的10个房型价格比平均值偏低。
进一步的,我们对照其最小居住时长。代码和结果如下:
data['minimum_nights'].groupby(data['room_type']).mean()
top_10['minimum_nights'].groupby(top_10['room_type']).mean()
全局数据各房型价格平均值如下,结果如下:

最受欢迎的10个房型价格平均值如下:

我们发现最受欢迎的10个房型最小居住时长比平均值偏低。
类似的,我们在最不受欢迎的十个房间中也发现了相反的情况,由于篇幅限制本文不再展示过程,感兴趣的朋友可以自己试试看。
基于上述数据,我们得出结论:
- 最受欢迎的房间,通常价格比平均价格低并且其最短居住时间会很小。
- 上述情况存在一定的可解释性,即大部分的游客或者居住者都是旅行者,其更容易接受价格实惠允许短时间居住的房间。
- 最不受欢迎的房子,通常价格比平均价格高很多,并且其最短居住时间过长。
- 基于上述内容,房子持有者可以通过下调房间价格至平均值下或者进一步减小居住时长来提高房子的居住率。
总结与展望
在本文中,我们基于Airbnb房源进行了数据分析,并从多种角度对其展开了探索性的工作。这对于养成数据分析习惯有很大的帮助,在实际工作或者学习中还需要不断练习。
感兴趣的朋友们可以自己按照上述步骤进行操作,或在评论区与我讨论。
需要源码的朋友可以私信我进行索取,我们下次再见。
