网络通信编程大作业--深度研究爬虫技术
一:什么是网络爬虫技术?
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
二:爬虫技术的分类(下面将介绍四种网络爬虫技术,并附加代码进行具体的分析)
1.聚焦网络爬虫:
聚焦网络爬虫(focused crawler)也就是主题网络爬虫。聚焦爬虫技术增加了链接评价和内容评价模块,其爬行策略实现要点就是评价页面内容以及链接的重要性。
基于链接评价的爬行策略,主要是以Web页面作为半结构化文档,其中拥有很多结构信息可用于评价链接重要性。还有一个是利用Web结构来评价链接价值的方法,也就是HITS法,其通过计算每个访问页面的Authority权重和Hub权重来决定链接访问顺序。
而基于内容评价的爬行策略,主要是将与文本相似的计算法加以应用,提出Fish-Search算法,把用户输入查询词当作主题,在算法的进一步改进下,通过Shark-Search算法就能利用空间向量模型来计算页面和主题相关度大小。
import urllib.request
# 爬虫专用的包urllib,不同版本的Python需要下载不同的爬虫专用包
import re
# 正则用来规律爬取
keyname=""
# 想要爬取的内容
key=urllib.request.quote(keyname)
# 需要将你输入的keyname解码,从而让计算机读懂
for i in range(0,5): # (0,5)数字可以自己设置,是淘宝某产品的页数
url="https://s.taobao.com/search?q="+key+"&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180815&ie=utf8&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s="+str(i*44)
# url后面加上你想爬取的网站名,然后你需要多开几个类似的网站以找到其规则
# data是你爬取到的网站所有的内容要解码要读取内容
pat='"pic_url":"//(.*?)"'
# pat使用正则表达式从网页爬取图片
# 将你爬取到的内容放在一个列表里面
print(picturelist)
# 可以不打印,也可以打印下来看看
for j in range(0,len(picturelist)):
picture=picturelist[j]
pictureurl="http://"+picture
# 将列表里的内容遍历出来,并加上http://转到高清图片
file="E:/pycharm/vscode文件/图片/"+str(i)+str(j)+".jpg"
# 再把图片逐张编号,不然重复的名字将会被覆盖掉
urllib.request.urlretrieve(pictureurl,filename=file)
# 最后保存到文件夹相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1) 对抓取目标的描述或定义;
(2) 对网页或数据的分析与过滤;
(3) 对URL的搜索策略。
2.通用网络爬虫技术:
-
第一,获取初始URL。初始URL地址可以由用户人为指定,也可以由用户指定的某个或某几个初始爬取网页决定。
-
第二,根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,需要先爬取对应URL地址中的网页,接着将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,并且将已爬取的URL地址存放到一个URL列表中,用于去重及判断爬取的进程。
-
第三,将新的URL放到URL队列中,在于第二步内获取下一个新的URL地址之后,会将新的URL地址放到URL队列中。
-
第四,从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新的网页中获取新的URL并重复上述的爬取过程。
-
第五,满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫便会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。
比如:通过爬虫技术实现读取京东商品的信息
'''
爬取京东商品信息:
请求url:https://www.jd.com/
提取商品信息:
1.商品详情页
2.商品名称
3.商品价格
4.评价人数
5.商品商家
'''
from selenium import webdriver # 引入selenium中的webdriver
from selenium.webdriver.common.keys import Keys
import time
def get_good(driver):
try:
# 通过JS控制滚轮滑动获取所有商品信息
js_code = '''
window.scrollTo(0,5000);
'''
driver.execute_script(js_code) # 执行js代码
# 等待数据加载
time.sleep(2)
# 查找所有商品div
# good_div = driver.find_element_by_id('J_goodsList')
good_list = driver.find_elements_by_class_name('gl-item')
n = 1
for good in good_list:
# 根据属性选择器查找
# 商品链接
good_url = good.find_element_by_css_selector(
'.p-img a').get_attribute('href')
# 商品名称
good_name = good.find_element_by_css_selector(
'.p-name em').text.replace("\n", "--")
# 商品价格
good_price = good.find_element_by_class_name(
'p-price').text.replace("\n", ":")
# 评价人数
good_commit = good.find_element_by_class_name(
'p-commit').text.replace("\n", " ")
good_content = f'''
商品链接: {good_url}
商品名称: {good_name}
商品价格: {good_price}
评价人数: {good_commit}
\n
'''
print(good_content)
with open('jd.txt', 'a', encoding='utf-8') as f:
f.write(good_content)
next_tag = driver.find_element_by_class_name('pn-next')
next_tag.click()
time.sleep(2)
# 递归调用函数
get_good(driver)
time.sleep(10)
finally:
driver.close()
if __name__ == '__main__':
good_name = input('请输入爬取商品信息:').strip()
driver = webdriver.Chrome()
driver.implicitly_wait(10)
# 往京东主页发送请求
driver.get('https://www.jd.com/')
# 输入商品名称,并回车搜索
input_tag = driver.find_element_by_id('key')
input_tag.send_keys(good_name)
input_tag.send_keys(Keys.ENTER)
time.sleep(2)
get_good(driver)3.增量爬虫技术:
某些网站会定时在原有网页数据的基础上更新一批数据。例如某电影网站会实时更新一批最近热门的电影,小说网站会根据作者创作的进度实时更新最新的章节数据等。在遇到类似的场景时,我们便可以采用增量式爬虫。
增量爬虫技术(incremental Web crawler)就是通过爬虫程序监测某网站数据更新的情况,以便可以爬取到该网站更新后的新数据。
关于如何进行增量式的爬取工作,以下给出三种检测重复数据的思路:
-
在发送请求之前判断这个URL是否曾爬取过;
-
在解析内容后判断这部分内容是否曾爬取过;
-
写入存储介质时判断内容是否已存在于介质中。
-
第一种思路适合不断有新页面出现的网站,比如小说的新章节、每天的实时新闻等;
-
第二种思路则适合页面内容会定时更新的网站;
-
第三种思路则相当于最后一道防线。这样做可以最大限度地达到去重的目的。
不难发现,实现增量爬取的核心是去重。目前存在两种去重方法。
-
第一,对爬取过程中产生的URL进行存储,存储在Redis的set中。当下次进行数据爬取时,首先在存储URL的set中对即将发起的请求所对应的URL进行判断,如果存在则不进行请求,否则才进行请求。
-
第二,对爬取到的网页内容进行唯一标识的制定(数据指纹),然后将该唯一标识存储至Redis的set中。当下次爬取到网页数据的时候,在进行持久化存储之前,可以先判断该数据的唯一标识在Redis的set中是否存在,从而决定是否进行持久化存储。
关于增量爬虫的使用方法示例如下所示。
爬取4567tv网站中所有的电影详情数据
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from redis import Redis
from incrementPro.items import IncrementproItem
class MovieSpider(CrawlSpider):
name = 'movie'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.4567tv.tv/frim/index7-11.html']
rules = (
Rule(LinkExtractor(allow=r'/frim/index7-\d+\.html'), callback='parse_item', follow=True),
)
# 创建Redis链接对象
conn = Redis(host='127.0.0.1', port=6379)
def parse_item(self, response):
li_list = response.xpath('//li[@class="p1 m1"]')
for li in li_list:
# 获取详情页的url
detail_url = 'http://www.4567tv.tv' + li.xpath('./a/@href').extract_first()
# 将详情页的url存入Redis的set中
ex = self.conn.sadd('urls', detail_url)
if ex == 1:
print('该url没有被爬取过,可以进行数据的爬取')
yield scrapy.Request(url=detail_url, callback=self.parst_detail)
else:
print('数据还没有更新,暂无新数据可爬取!')
# 解析详情页中的电影名称和类型,进行持久化存储
def parst_detail(self, response):
item = IncrementproItem()
item['name'] = response.xpath('//dt[@class="name"]/text()').extract_first()
item['kind'] = response.xpath('//div[@class="ct-c"]/dl/dt[4]//text()').extract()
item['kind'] = ''.join(item['kind'])
yield it管道文件:
from redis import Redis
class IncrementproPipeline(object):
conn = None
def open_spider(self,spider):
self.conn = Redis(host='127.0.0.1',port=6379)
def process_item(self, item, spider):
dic = {
'name':item['name'],
'kind':item['kind']
}
print(dic)
self.conn.push('movieData',dic)
# 如果push不进去,那么dic变成str(dic)或者改变redis版本
pip install -U redis==2.10.6
return item4.深层网络爬虫技术:
在互联网中,网页按存在方式可以分为表层网页和深层网页两类。
所谓的表层网页,指的是不需要提交表单,使用静态的链接就能够到达的静态页面;而深层网页则隐藏在表单后面,不能通过静态链接直接获取,是需要提交一定的关键词后才能够获取到的页面,深层网络爬虫(deep Web crawler)最重要的部分即为表单填写部分。
在互联网中,深层网页的数量往往要比表层网页的数量多很多,故而,我们需要想办法爬取深层网页。
深层网络爬虫的基本构成:URL列表、LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器。
深层网络爬虫的表单填写有两种类型:
-
基于领域知识的表单填写(建立一个填写表单的关键词库,在需要的时候,根据语义分析选择对应的关键词进行填写);
-
基于网页结构分析的表单填写(一般在领域知识有限的情况下使用,这种方式会根据网页结构进行分析,并自动地进行表单填写)。
三:网络爬虫原理:
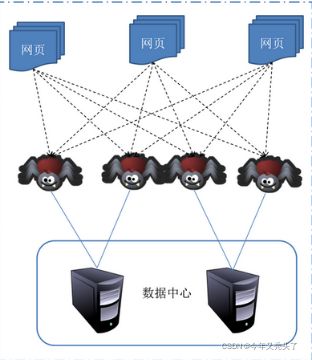
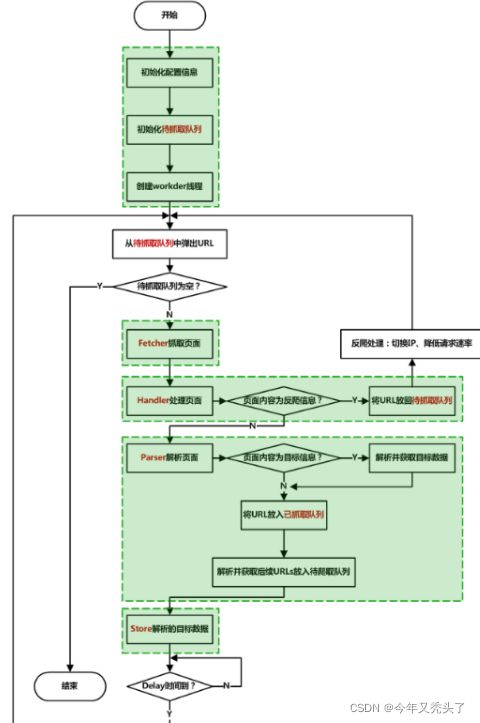
1.Web网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据来源。很多大型的网络搜索引擎系统都被称为基于 Web数据采集的搜索引擎系统,比如 Google、Baidu。由此可见Web 网络爬虫系统在搜索引擎中的重要性。网页中除了包含供用户阅读的文字信息外,还包含一些超链接信息。Web网络爬虫系统正是通过网页中的超连接信息不断获得网络上的其它网页.
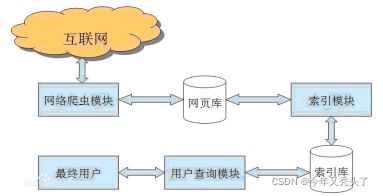
2.网络爬虫的工作原理:
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、Sql Server等。
Web网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。网络爬虫系统以这些种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的 URL会得到一些新的 URL,可以把网页之间的指向结构视为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。这样,Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先搜索算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此一般采用广度优先搜索算法采集网页。Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
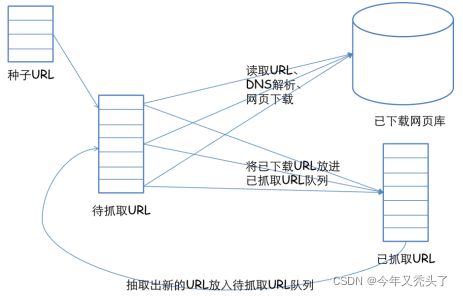
3.网络爬虫的基本工作流程如下:
a.首先选取一部分精心挑选的种子URL;
b.将这些URL放入待抓取URL队列;
c.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
d.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
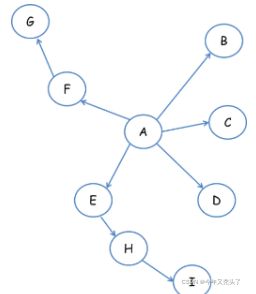
4.爬虫技术策略分析总结归纳:
抓取策略:
a:深度优先遍历策略:
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-G E-H-I B C D
b:宽度优先遍历策略:
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-F G H I
c:反向链接数策略:
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
四:爬虫的分类:
开发网络爬虫应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?上面说的爬虫,基本可以分3类:
(1)分布式爬虫:Nutch
(2)JAVA爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
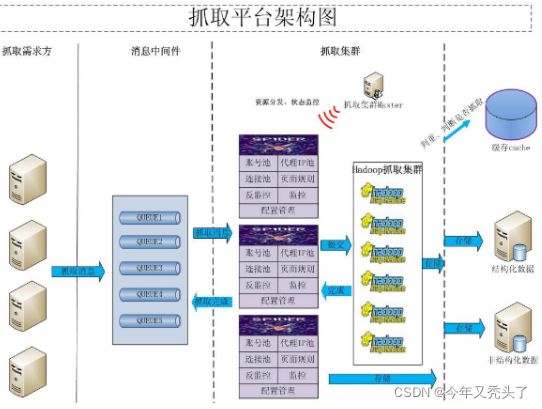
4.1:分布式爬虫:
爬虫使用分布式,主要是解决两个问题:
1)海量URL管理
2)网速
4.2:JAVA爬虫:
4.3:非JAVA爬虫:
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这里单独提取出来作为一类,并不是针对爬虫本身的质量进行讨论,而是针对larbin、scrapy这类爬虫,对开发成本的影响。
先说python爬虫,python可以用30行代码,完成JAVA 50行代码干的任务。python写代码的确快,但是在调试代码的阶段,python代码的调试往往会耗费远远多于编码阶段省下的时间。使用python开发,要保证程序的正确性和稳定性,就需要写更多的测试模块。当然如果爬取规模不大、爬取业务不复杂,使用scrapy这种爬虫也是蛮不错的,可以轻松完成爬取任务。
五:利用爬虫获取淘宝网上所有的商品分类以及关键属性 销售属性 非关键属性数据
5.1:顶级分类数据category-top.csv文件的内容定义如下:
0|{"itemcats_get_response":{"item_cats":{"item_cat":[
{"cid":16,"is_parent":true,"name":"女装/女士精品","parent_cid":0,"status":"normal"},
{"cid":120886001,"is_parent":true,"name":"公益","parent_cid":0,"status":"normal"},
{"cid":98,"is_parent":true,"name":"包装","parent_cid":0,"status":"normal"},
{"cid":120950002,"is_parent":true,"name":"天猫点券","parent_cid":0,"status":"normal"},
{"cid":50802001,"is_parent":true,"name":"数字阅读","parent_cid":0,"status":"normal"},
{"cid":120894001,"is_parent":true,"name":"淘女郎","parent_cid":0,"status":"normal"},
{"cid":50023722,"is_parent":true,"name":"隐形眼镜/护理液","parent_cid":0,"status":"normal"},
{"cid":50026555,"is_parent":true,"name":"购物提货券","parent_cid":0,"status":"normal"},
{"cid":50026523,"is_parent":true,"name":"休闲娱乐","parent_cid":0,"status":"normal"},
{"cid":50008075,"is_parent":true,"name":"餐饮美食卡券","parent_cid":0,"status":"normal"},
{"cid":50019095,"is_parent":true,"name":"消费卡","parent_cid":0,"status":"normal"},
{"cid":50014927,"is_parent":true,"name":"教育培训","parent_cid":0,"status":"normal"},
{"cid":26,"is_parent":true,"name":"汽车/用品/配件/改装","parent_cid":0,"status":"normal"},
{"cid":50020808,"is_parent":true,"name":"家居饰品","parent_cid":0,"status":"normal"},
{"cid":50020857,"is_parent":true,"name":"特色手工艺","parent_cid":0,"status":"normal"},
{"cid":50025707,"is_parent":true,"name":"度假线路/签证送关/旅游服务","parent_cid":0,"status":"normal"},
{"cid":50024099,"is_parent":true,"name":"电子元器件市场","parent_cid":0,"status":"normal"},
{"cid":30,"is_parent":true,"name":"男装","parent_cid":0,"status":"normal"},
{"cid":50008164,"is_parent":true,"name":"住宅家具","parent_cid":0,"status":"normal"},
{"cid":50020611,"is_parent":true,"name":"商业/办公家具","parent_cid":0,"status":"normal"},
{"cid":50010788,"is_parent":true,"name":"彩妆/香水/美妆工具","parent_cid":0,"status":"normal"},
{"cid":1801,"is_parent":true,"name":"美容护肤/美体/精油","parent_cid":0,"status":"normal"},
{"cid":50023282,"is_parent":true,"name":"美发护发/假发","parent_cid":0,"status":"normal"},
{"cid":1512,"is_parent":false,"name":"手机","parent_cid":0,"status":"normal"},
{"cid":14,"is_parent":true,"name":"数码相机/单反相机/摄像机","parent_cid":0,"status":"normal"},
{"cid":1201,"is_parent":false,"name":"MP3/MP4/iPod/录音笔","parent_cid":0,"status":"normal"},
{"cid":1101,"is_parent":false,"name":"笔记本电脑","parent_cid":0,"status":"normal"},
{"cid":50019780,"is_parent":false,"name":"平板电脑/MID","parent_cid":0,"status":"normal"},
{"cid":50018222,"is_parent":true,"name":"DIY电脑","parent_cid":0,"status":"normal"},
{"cid":11,"is_parent":true,"name":"电脑硬件/显示器/电脑周边","parent_cid":0,"status":"normal"},
{"cid":50018264,"is_parent":true,"name":"网络设备/网络相关","parent_cid":0,"status":"normal"},
{"cid":50008090,"is_parent":true,"name":"3C数码配件","parent_cid":0,"status":"normal"},
{"cid":50012164,"is_parent":true,"name":"闪存卡/U盘/存储/移动硬盘","parent_cid":0,"status":"normal"},
{"cid":50007218,"is_parent":true,"name":"办公设备/耗材/相关服务","parent_cid":0,"status":"normal"},
{"cid":50018004,"is_parent":true,"name":"电子词典/电纸书/文化用品","parent_cid":0,"status":"normal"},
{"cid":20,"is_parent":true,"name":"电玩/配件/游戏/攻略","parent_cid":0,"status":"normal"},
{"cid":50022703,"is_parent":true,"name":"大家电","parent_cid":0,"status":"normal"},
{"cid":50011972,"is_parent":true,"name":"影音电器","parent_cid":0,"status":"normal"},
{"cid":50012100,"is_parent":true,"name":"生活电器","parent_cid":0,"status":"normal"},
{"cid":50012082,"is_parent":true,"name":"厨房电器","parent_cid":0,"status":"normal"},
{"cid":50002768,"is_parent":true,"name":"个人护理/保健/按摩器材","parent_cid":0,"status":"normal"},
{"cid":27,"is_parent":true,"name":"家装主材","parent_cid":0,"status":"normal"},
{"cid":124912001,"is_parent":false,"name":"合约机","parent_cid":0,"status":"normal"},
{"cid":50020332,"is_parent":true,"name":"基础建材","parent_cid":0,"status":"normal"},
{"cid":50020485,"is_parent":true,"name":"五金/工具","parent_cid":0,"status":"normal"},
{"cid":50026535,"is_parent":true,"name":"医疗及健康服务","parent_cid":0,"status":"normal"},
{"cid":50020579,"is_parent":true,"name":"电子/电工","parent_cid":0,"status":"normal"},
{"cid":50050471,"is_parent":true,"name":"婚庆/摄影/摄像服务","parent_cid":0,"status":"normal"},
{"cid":50011949,"is_parent":true,"name":"特价酒店/特色客栈/公寓旅馆","parent_cid":0,"status":"normal"},
{"cid":21,"is_parent":true,"name":"居家日用","parent_cid":0,"status":"normal"},
{"cid":50016349,"is_parent":true,"name":"厨房/烹饪用具","parent_cid":0,"status":"normal"},
{"cid":50016348,"is_parent":true,"name":"家庭/个人清洁工具","parent_cid":0,"status":"normal"},
{"cid":50008163,"is_parent":true,"name":"床上用品","parent_cid":0,"status":"normal"},
{"cid":35,"is_parent":true,"name":"奶粉/辅食/营养品/零食","parent_cid":0,"status":"normal"},
{"cid":50014812,"is_parent":true,"name":"尿片/洗护/喂哺/推车床","parent_cid":0,"status":"normal"},
{"cid":50022517,"is_parent":true,"name":"孕妇装/孕产妇用品/营养","parent_cid":0,"status":"normal"},
{"cid":50008165,"is_parent":true,"name":"童装/婴儿装/亲子装","parent_cid":0,"status":"normal"},
{"cid":50020275,"is_parent":true,"name":"传统滋补营养品","parent_cid":0,"status":"normal"},
{"cid":50002766,"is_parent":true,"name":"零食/坚果/特产","parent_cid":0,"status":"normal"},
{"cid":50016422,"is_parent":true,"name":"粮油米面/南北干货/调味品","parent_cid":0,"status":"normal"},
{"cid":121380001,"is_parent":true,"name":"国内机票/国际机票/增值服务","parent_cid":0,"status":"normal"},
{"cid":121536003,"is_parent":true,"name":"数字娱乐","parent_cid":0,"status":"normal"},
{"cid":121536007,"is_parent":true,"name":"全球购代购市场","parent_cid":0,"status":"normal"},
{"cid":40,"is_parent":true,"name":"腾讯QQ专区","parent_cid":0,"status":"normal"},
{"cid":50010728,"is_parent":true,"name":"运动/瑜伽/健身/球迷用品","parent_cid":0,"status":"normal"},
{"cid":50013886,"is_parent":true,"name":"户外/登山/野营/旅行用品","parent_cid":0,"status":"normal"},
{"cid":50011699,"is_parent":true,"name":"运动服/休闲服装","parent_cid":0,"status":"normal"},
{"cid":25,"is_parent":true,"name":"玩具/童车/益智/积木/模型","parent_cid":0,"status":"normal"},
{"cid":50011665,"is_parent":true,"name":"网游装备/游戏币/帐号/代练","parent_cid":0,"status":"normal"},
{"cid":50008907,"is_parent":true,"name":"手机号码/套餐/增值业务","parent_cid":0,"status":"normal"},
{"cid":99,"is_parent":true,"name":"网络游戏点卡","parent_cid":0,"status":"normal"},
{"cid":23,"is_parent":true,"name":"古董/邮币/字画/收藏","parent_cid":0,"status":"normal"},
{"cid":50007216,"is_parent":true,"name":"鲜花速递/花卉仿真/绿植园艺","parent_cid":0,"status":"normal"},
{"cid":50004958,"is_parent":true,"name":"移动/联通/电信充值中心","parent_cid":0,"status":"normal"},
{"cid":50011740,"is_parent":true,"name":"流行男鞋","parent_cid":0,"status":"normal"},
{"cid":50006843,"is_parent":true,"name":"女鞋","parent_cid":0,"status":"normal"},
{"cid":50006842,"is_parent":true,"name":"箱包皮具/热销女包/男包","parent_cid":0,"status":"normal"},
{"cid":1625,"is_parent":true,"name":"女士内衣/男士内衣/家居服","parent_cid":0,"status":"normal"},
{"cid":50010404,"is_parent":true,"name":"服饰配件/皮带/帽子/围巾","parent_cid":0,"status":"normal"},
{"cid":50011397,"is_parent":true,"name":"珠宝/钻石/翡翠/黄金","parent_cid":0,"status":"normal"},
{"cid":28,"is_parent":true,"name":"ZIPPO/瑞士军刀/眼镜","parent_cid":0,"status":"normal"},
{"cid":33,"is_parent":true,"name":"书/杂志/报纸","parent_cid":0,"status":"normal"},
{"cid":34,"is_parent":true,"name":"音乐/影视/明星/音像","parent_cid":0,"status":"normal"},
{"cid":50017300,"is_parent":true,"name":"乐器/吉他/钢琴/配件","parent_cid":0,"status":"normal"},
{"cid":29,"is_parent":true,"name":"宠物/宠物食品及用品","parent_cid":0,"status":"normal"},
{"cid":2813,"is_parent":true,"name":"成人用品/情趣用品","parent_cid":0,"status":"normal"},
{"cid":50012029,"is_parent":true,"name":"运动鞋new","parent_cid":0,"status":"normal"},
{"cid":50013864,"is_parent":true,"name":"饰品/流行首饰/时尚饰品新","parent_cid":0,"status":"normal"},
{"cid":50014811,"is_parent":true,"name":"网店/网络服务/软件","parent_cid":0,"status":"normal"},
{"cid":50023724,"is_parent":true,"name":"其他","parent_cid":0,"status":"normal"},
{"cid":50017652,"is_parent":true,"name":"TP服务商大类","parent_cid":0,"status":"normal"},
{"cid":50023575,"is_parent":true,"name":"房产/租房/新房/二手房/委托服务","parent_cid":0,"status":"normal"},
{"cid":50023717,"is_parent":true,"name":"OTC药品/医疗器械/计生用品","parent_cid":0,"status":"normal"},
{"cid":50023878,"is_parent":true,"name":"自用闲置转让","parent_cid":0,"status":"normal"},
{"cid":50024186,"is_parent":true,"name":"保险","parent_cid":0,"status":"normal"},
{"cid":50024612,"is_parent":true,"name":"阿里健康送药服务","parent_cid":0,"status":"normal"},
{"cid":50024971,"is_parent":true,"name":"新车/二手车","parent_cid":0,"status":"normal"},
{"cid":50025004,"is_parent":true,"name":"个性定制/设计服务/DIY","parent_cid":0,"status":"normal"},
{"cid":50025110,"is_parent":true,"name":"电影/演出/体育赛事","parent_cid":0,"status":"normal"},
{"cid":50025618,"is_parent":true,"name":"理财","parent_cid":0,"status":"normal"},
{"cid":50025705,"is_parent":true,"name":"洗护清洁剂/卫生巾/纸/香薰","parent_cid":0,"status":"normal"},
{"cid":50025968,"is_parent":true,"name":"司法拍卖拍品专用","parent_cid":0,"status":"normal"},
{"cid":50026316,"is_parent":true,"name":"咖啡/麦片/冲饮","parent_cid":0,"status":"normal"},
{"cid":50023804,"is_parent":true,"name":"装修设计/施工/监理","parent_cid":0,"status":"normal"},
{"cid":50026800,"is_parent":true,"name":"保健食品/膳食营养补充食品","parent_cid":0,"status":"normal"},
{"cid":50050359,"is_parent":true,"name":"水产肉类/新鲜蔬果/熟食","parent_cid":0,"status":"normal"},
{"cid":50074001,"is_parent":true,"name":"摩托车/装备/配件","parent_cid":0,"status":"normal"},
{"cid":50158001,"is_parent":true,"name":"网络店铺代金/优惠券","parent_cid":0,"status":"normal"},
{"cid":50230002,"is_parent":true,"name":"服务商品","parent_cid":0,"status":"normal"},
{"cid":50454031,"is_parent":true,"name":"景点门票/演艺演出/周边游","parent_cid":0,"status":"normal"},
{"cid":50468001,"is_parent":true,"name":"手表","parent_cid":0,"status":"normal"},
{"cid":50510002,"is_parent":true,"name":"运动包/户外包/配件","parent_cid":0,"status":"normal"},
{"cid":50008141,"is_parent":true,"name":"酒类","parent_cid":0,"status":"normal"},
{"cid":50734010,"is_parent":true,"name":"资产","parent_cid":0,"status":"normal"},
{"cid":50025111,"is_parent":true,"name":"本地化生活服务","parent_cid":0,"status":"normal"},
{"cid":121938001,"is_parent":false,"name":"淘点点预定点菜","parent_cid":0,"status":"normal"},
{"cid":121940001,"is_parent":false,"name":"淘点点现金券","parent_cid":0,"status":"normal"},
{"cid":122650005,"is_parent":true,"name":"童鞋/婴儿鞋/亲子鞋","parent_cid":0,"status":"normal"},
{"cid":122684003,"is_parent":true,"name":"自行车/骑行装备/零配件","parent_cid":0,"status":"normal"},
{"cid":122718004,"is_parent":true,"name":"家庭保健","parent_cid":0,"status":"normal"},
{"cid":122852001,"is_parent":true,"name":"居家布艺","parent_cid":0,"status":"normal"},
{"cid":122950001,"is_parent":true,"name":"节庆用品/礼品","parent_cid":0,"status":"normal"},
{"cid":122952001,"is_parent":true,"name":"餐饮具","parent_cid":0,"status":"normal"},
{"cid":122928002,"is_parent":true,"name":"收纳整理","parent_cid":0,"status":"normal"},
{"cid":122966004,"is_parent":true,"name":"处方药","parent_cid":0,"status":"normal"},
{"cid":123536002,"is_parent":true,"name":"阿里通信专属类目","parent_cid":0,"status":"normal"},
{"cid":123500005,"is_parent":true,"name":"资产(政府类专用)","parent_cid":0,"status":"normal"},
{"cid":123690003,"is_parent":true,"name":"精制中药材","parent_cid":0,"status":"normal"},
{"cid":124024001,"is_parent":true,"name":"农业生产资料(农村淘宝专用)","parent_cid":0,"status":"normal"},
{"cid":124044001,"is_parent":true,"name":"品牌台机/品牌一体机/服务器","parent_cid":0,"status":"normal"},
{"cid":124050001,"is_parent":true,"name":"全屋定制","parent_cid":0,"status":"normal"},
{"cid":124242008,"is_parent":true,"name":"智能设备","parent_cid":0,"status":"normal"},
{"cid":124354002,"is_parent":true,"name":"电动车/配件/交通工具","parent_cid":0,"status":"normal"},
{"cid":124466001,"is_parent":true,"name":"农用物资","parent_cid":0,"status":"normal"},
{"cid":124468001,"is_parent":true,"name":"农机/农具/农膜","parent_cid":0,"status":"normal"},
{"cid":124470001,"is_parent":true,"name":"畜牧/养殖物资","parent_cid":0,"status":"normal"},
{"cid":124470006,"is_parent":true,"name":"整车(经销商)","parent_cid":0,"status":"normal"},
{"cid":124484008,"is_parent":true,"name":"模玩/动漫/周边/cos/桌游","parent_cid":0,"status":"normal"},
{"cid":124458005,"is_parent":true,"name":"茶","parent_cid":0,"status":"normal"},
{"cid":124568010,"is_parent":true,"name":"室内设计师","parent_cid":0,"status":"normal"},
{"cid":124750013,"is_parent":true,"name":"俪人购(俪人购专用)","parent_cid":0,"status":"normal"},
{"cid":124698018,"is_parent":true,"name":"装修服务","parent_cid":0,"status":"normal"},
{"cid":124844002,"is_parent":true,"name":"拍卖会专用","parent_cid":0,"status":"normal"},
{"cid":124868003,"is_parent":true,"name":"盒马","parent_cid":0,"status":"normal"},
{"cid":124852003,"is_parent":true,"name":"二手数码","parent_cid":0,"status":"normal"},
{"cid":125102006,"is_parent":true,"name":"到家业务","parent_cid":0,"status":"normal"},
{"cid":125406001,"is_parent":true,"name":"享淘卡","parent_cid":0,"status":"normal"},
{"cid":126040001,"is_parent":true,"name":"橙运","parent_cid":0,"status":"normal"},
{"cid":126252002,"is_parent":true,"name":"门店O2O","parent_cid":0,"status":"normal"},
{"cid":126488005,"is_parent":true,"name":"天猫零售O2O","parent_cid":0,"status":"normal"},
{"cid":126488008,"is_parent":true,"name":"阿里健康B2B平台","parent_cid":0,"status":"normal"},
{"cid":126602002,"is_parent":true,"name":"生活娱乐充值","parent_cid":0,"status":"normal"},
{"cid":126700003,"is_parent":true,"name":"家装灯饰光源","parent_cid":0,"status":"normal"},
{"cid":126762001,"is_parent":true,"name":"美容美体仪器","parent_cid":0,"status":"normal"},
{"cid":127076003,"is_parent":true,"name":"平台充值活动(仅内部店铺)","parent_cid":0,"status":"normal"},
{"cid":127492006,"is_parent":true,"name":"标准件/零部件/工业耗材","parent_cid":0,"status":"normal"},
{"cid":127484003,"is_parent":true,"name":"润滑/胶粘/试剂/实验室耗材","parent_cid":0,"status":"normal"},
{"cid":127508003,"is_parent":true,"name":"机械设备","parent_cid":0,"status":"normal"},
{"cid":127458007,"is_parent":true,"name":"搬运/仓储/物流设备","parent_cid":0,"status":"normal"},
{"cid":127442006,"is_parent":true,"name":"纺织面料/辅料/配套","parent_cid":0,"status":"normal"},
{"cid":127450004,"is_parent":true,"name":"金属材料及制品","parent_cid":0,"status":"normal"},
{"cid":127452002,"is_parent":true,"name":"橡塑材料及制品","parent_cid":0,"status":"normal"},
{"cid":127588002,"is_parent":true,"name":"阿里云云市场","parent_cid":0,"status":"normal"},
{"cid":127878006,"is_parent":true,"name":"新制造","parent_cid":0,"status":"normal"},
{"cid":127924022,"is_parent":true,"name":"零售通","parent_cid":0,"status":"normal"}
]},"request_id":"s82mq3r0hshh"}}|0
如果像上面那样定义顶级分类数据category-top.csv文件内容的话,爬虫代码的运行时间会很长,可能代码运行过程中会返回很多限速消息,返回数据不完整解析数据格式时出现的致命错误,或者其它网络错误,这样爬取数据我们自己不好控制,所以就不要那么贪心啦,我们让上面的165条顶级分类数据分成165次分别爬取,也就是说,我们需要像下面这样重新定义category-top.csv文件的内容,注意文件格式要定义成3行
调试爬虫代码,顶级分类 ------ 女装/女士精品会按照以下递归次序从淘宝服务器上获得以下数据:
顶级分类:
{"cid":16,"is_parent":true,"name":"女装/女士精品","parent_cid":0,"status":"normal"}
女装/女士精品:
[{u'status': u'normal', u'parent_cid': 16, u'name': u'连衣裙', u'is_parent': False, u'cid': 50010850},
{u'status': u'normal', u'parent_cid': 16, u'name': u'T恤', u'is_parent': False, u'cid': 50000671},
{u'status': u'normal', u'parent_cid': 16, u'name': u'衬衫', u'is_parent': False, u'cid': 162104},
{u'status': u'normal', u'parent_cid': 16, u'name': u'裤子', u'is_parent': True, u'cid': 1622},
{u'status': u'normal', u'parent_cid': 16, u'name': u'牛仔裤', u'is_parent': False, u'cid': 162205},
{u'status': u'normal', u'parent_cid': 16, u'name': u'半身裙', u'is_parent': False, u'cid': 1623},
{u'status': u'normal', u'parent_cid': 16, u'name': u'马夹', u'is_parent': False, u'cid': 50013196},
{u'status': u'normal', u'parent_cid': 16, u'name': u'蕾丝衫/雪纺衫', u'is_parent': False, u'cid': 162116},
{u'status': u'normal', u'parent_cid': 16, u'name': u'毛针织衫', u'is_parent': False, u'cid': 50000697},
{u'status': u'normal', u'parent_cid': 16, u'name': u'短外套', u'is_parent': False, u'cid': 50011277},
{u'status': u'normal', u'parent_cid': 16, u'name': u'西装', u'is_parent': False, u'cid': 50008897},
{u'status': u'normal', u'parent_cid': 16, u'name': u'卫衣/绒衫', u'is_parent': False, u'cid': 50008898},
{u'status': u'normal', u'parent_cid': 16, u'name': u'毛衣', u'is_parent': False, u'cid': 162103},
{u'status': u'normal', u'parent_cid': 16, u'name': u'风衣', u'is_parent': False, u'cid': 50008901},
{u'status': u'normal', u'parent_cid': 16, u'name': u'毛呢外套', u'is_parent': False, u'cid': 50013194},
{u'status': u'normal', u'parent_cid': 16, u'name': u'棉衣/棉服', u'is_parent': False, u'cid': 50008900},
{u'status': u'normal', u'parent_cid': 16, u'name': u'羽绒服', u'is_parent': False, u'cid': 50008899},
{u'status': u'normal', u'parent_cid': 16, u'name': u'皮衣', u'is_parent': False, u'cid': 50008904},
{u'status': u'normal', u'parent_cid': 16, u'name': u'皮草', u'is_parent': False, u'cid': 50008905},
{u'status': u'normal', u'parent_cid': 16, u'name': u'中老年女装', u'is_parent': False, u'cid': 50000852},
{u'status': u'normal', u'parent_cid': 16, u'name': u'大码女装', u'is_parent': False, u'cid': 1629},
{u'status': u'normal', u'parent_cid': 16, u'name': u'套装/学生校服/工作制服', u'is_parent': True, u'cid': 1624},
{u'status': u'normal', u'parent_cid': 16, u'name': u'婚纱/旗袍/礼服', u'is_parent': True, u'cid': 50011404},
{u'status': u'normal', u'parent_cid': 16, u'name': u'唐装/民族服装/舞台服装', u'is_parent': True, u'cid': 50008906},
{u'status': u'normal', u'parent_cid': 16, u'name': u'背心吊带', u'is_parent': False, u'cid': 121412004},
{u'status': u'normal', u'parent_cid': 16, u'name': u'抹胸', u'is_parent': False, u'cid': 121434004}]
裤子:
[{u'status': u'normal', u'parent_cid': 1622, u'name': u'休闲裤', u'is_parent': False, u'cid': 162201},
{u'status': u'normal', u'parent_cid': 1622, u'name': u'西装裤/正装裤', u'is_parent': False, u'cid': 50022566},
{u'status': u'normal', u'parent_cid': 1622, u'name': u'打底裤', u'is_parent': False, u'cid': 50007068},
{u'status': u'normal', u'parent_cid': 1622, u'name': u'棉裤/羽绒裤', u'is_parent': False, u'cid': 50026651}]
套装/学生校服/工作制服:
[{u'status': u'normal', u'parent_cid': 1624, u'name': u'学生校服', u'is_parent': False, u'cid': 50008903},
{u'status': u'normal', u'parent_cid': 1624, u'name': u'职业女裙套装', u'is_parent': False, u'cid': 162401},
{u'status': u'normal', u'parent_cid': 1624, u'name': u'职业女裤套装', u'is_parent': False, u'cid': 162402},
{u'status': u'normal', u'parent_cid': 1624, u'name': u'休闲运动套装', u'is_parent': False, u'cid': 162404},
{u'status': u'normal', u'parent_cid': 1624, u'name': u'其它制服/套装', u'is_parent': False, u'cid': 162403},
{u'status': u'normal', u'parent_cid': 1624, u'name': u'医护制服', u'is_parent': False, u'cid': 50011411},
{u'status': u'normal', u'parent_cid': 1624, u'name': u'酒店工作制服', u'is_parent': False, u'cid': 50011412},
{u'status': u'normal', u'parent_cid': 1624, u'name': u'时尚套装', u'is_parent': False, u'cid': 123216004}]
婚纱/旗袍/礼服:
[{"cid":162701,"is_parent":false,"name":"婚纱","parent_cid":50011404,"status":"normal"},
{"cid":50005065,"is_parent":false,"name":"旗袍","parent_cid":50011404,"status":"normal"},
{"cid":162702,"is_parent":false,"name":"礼服\/晚装","parent_cid":50011404,"status":"normal"}]
唐装/民族服装/舞台服装:
[{u'status': u'normal', u'parent_cid': 50008906, u'name': u'民族服装/舞台装', u'is_parent': False, u'cid': 162703},
{u'status': u'normal', u'parent_cid': 50008906, u'name': u'唐装/中式服装', u'is_parent': True, u'cid': 1636}]
唐装/中式服装:
[{u'status': u'normal', u'parent_cid': 1636, u'name': u'上衣', u'is_parent': False, u'cid': 50003509},
{u'status': u'normal', u'parent_cid': 1636, u'name': u'裤子', u'is_parent': False, u'cid': 50003510},
{u'status': u'normal', u'parent_cid': 1636, u'name': u'裙子', u'is_parent': False, u'cid': 50003511}]
————————————————
版权声明:本文为CSDN博主「zhengzizhi」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhengzizhi/article/details/807166085.2: 爬虫代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
import sys
import json
reload(sys)
sys.setdefaultencoding('utf-8')
session = requests.Session()
f = open('category-top.csv','r')
data = list()
for line in open('category-top.csv'):
line = f.readline().strip(',\n')
data.append(line)
cidStr = ''.join(data)
f.close()
def createCidSelect(cidStr):
cidArr = cidStr.split("|")
cid = cidArr[0]
spanId = cidArr[2]
if '' == cid:
return False
cidArr = json.loads(cidArr[1])['itemcats_get_response']
cidArr = cidArr['item_cats']
cidArr = cidArr['item_cat']
count = len(cidArr)
file = open('category-all.csv', 'a')
list1 = list()
for i in range(count):
if cidArr[i]['status'] == 'normal':
file.write('{0},{1},{2},{3},{4};\n'.format(cidArr[i]['status'],cidArr[i]['parent_cid'],cidArr[i]['name'],int(cidArr[i]['is_parent']),cidArr[i]['cid']))
list1.append(cidArr[i])
file.close()
parentId = cid
for item in list1:
childCidList(item,parentId)
def childCidList(item,parentId):
cid = 0
try:
cid = item['cid']
if item['is_parent'] == False:
loadScript(cid)
return
url = 'http://open.taobao.com/apitools/ajax_props.do?_tb_token_=3365b5d353fed&cid='+ str(cid) +'&act=childCid&restBool=false&ua=090%23qCQXNTXpXOVXPvi0XXXXXQkOIr77HU0hzDlo3e5rAGB2zoPlhnG5%2ByiUIr7ejGmnfjLiXXfbC7NK%2BvQXaKZdRva2jrbsXmLiXXfbC7NK24QXrpehnTFfoVM3eeu8iGliXX5dtRJXExTEMiwtXvXQsVW8ZxDiXXF2mp%2F9vQjBXvXzbc9P9lqAxgLAq6anQgwoWawOSBLiXajeGXriHnepAFhnPIj3Ho39h9kvXP73IzgeG%2FXXHYVmV6hnD6u3HoPsH4QXaPjPiq2d7D7bPvQXiHDow1Qg%2FrliXXfMhTQ%2F%2BvQXaKZWvPXMjrY0VBViXi2oemXumVM3oMavtXFjQ7%2Ba2T%3D%3D'
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en-US,en;q=0.9",
"Connection": "keep-alive",
"Cookie": "t=bbb6c14edb1c8d0e65996158979a8027; cna=I0NFEysmiWkCAQ6cyYxll3kh; tg=0; lgc=mycarting; tracknick=mycarting; mt=np=; v=0; cookie2=3253fc64aa52d22785ce4a3f5af722d2; _tb_token_=3365b5d353fed; dnk=mycarting; JSESSIONID=B94DBA871F64C03C095830C238F218A9; uc1=cookie14=UoTeNzVRvRsWPg%3D%3D&lng=zh_CN&cookie16=W5iHLLyFPlMGbLDwA%2BdvAGZqLg%3D%3D&existShop=false&cookie21=VFC%2FuZ9ajCbF99I65Qm9gQ%3D%3D&tag=8&cookie15=Vq8l%2BKCLz3%2F65A%3D%3D&pas=0; uc3=nk2=DkmnuVZqM291&id2=UU8OcO9lI45Clg%3D%3D&vt3=F8dBzr2Fa6i4%2Fc9OIz8%3D&lg2=UtASsssmOIJ0bQ%3D%3D; existShop=MTUyOTIxODk0Nw%3D%3D; sg=g43; csg=c98ee665; cookie1=VTrg90saGzeX9ovigm2mqTr%2Fu6w0vPNLI3IgZ0vhu9E%3D; unb=2761447894; skt=ed11d5f665cdb5a8; _cc_=W5iHLLyFfA%3D%3D; _l_g_=Ug%3D%3D; _nk_=mycarting; cookie17=UU8OcO9lI45Clg%3D%3D; apushdf188ec636caeab174aad0f3441beb09=%7B%22ts%22%3A1529221047670%2C%22parentId%22%3A1529220867224%7D; isg=BP7-BDyyKY-LxH2pSg1zscaeTx2Al8izHjVx9qgGccE8S58lEM-zyUVtxx-H87rR",
"Host": "open.taobao.com",
"Referer": "http://open.taobao.com/apitools/apiPropTools.htm?spm=0.0.0.0.mlPbbQ",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36",
}
res = session.get(url, headers=headers)
if (res.text != '' and res.text.find('{"itemcats_get_response":{"item_cats":{"item_cat":') > 0):
cidStr = str(cid) + '|'+ res.text + '|' + str(parentId)
createCidSelect(cidStr)
else:
print 'childCidList: ' + res.text
except Exception as err:
print "cid : " + str(cid)
print "parentId : " + str(parentId)
print err
def loadScript(cid):
try:
url = 'http://open.taobao.com/apitools/ajax_props.do?_tb_token_=3365b5d353fed&act=props&cid='+ str(cid) +'&restBool=false&ua=090%23qCQXc4XpXODXPXi0XXXXXQkOIr77HUR5flY73eg3AGB3fzQocPf5Aw1OIruEk0Rs24QXQczccXFFoVM3VUVTihPz9JPWqaLiXXB%2B0ydC24QXrpec2XdDoVM3VUpKijLiXXB%2B0ydC24QXrpec2vzsoVM3ebpQinDiXXF2mp%2F9vQjBXvXUM%2Ben9l8BvNoGriLiXajeGXrfHnepFehnPIj3Ho39h9kvXP73IzgeG%2FXXHYVmV6hnD6u3HoPsH4QXaOXTsEIXgwYSPvQXit2CqnY8PmLiXXB%2B0ydC3vQXiPR22amsXvXqzwE6XkFGOYnqq4QXius%2BSbQ%3D'
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en-US,en;q=0.9",
"Connection": "keep-alive",
"Cookie": "t=bbb6c14edb1c8d0e65996158979a8027; cna=I0NFEysmiWkCAQ6cyYxll3kh; tg=0; lgc=mycarting; tracknick=mycarting; mt=np=; v=0; cookie2=3253fc64aa52d22785ce4a3f5af722d2; _tb_token_=3365b5d353fed; dnk=mycarting; JSESSIONID=B94DBA871F64C03C095830C238F218A9; uc1=cookie14=UoTeNzVRvRsWPg%3D%3D&lng=zh_CN&cookie16=W5iHLLyFPlMGbLDwA%2BdvAGZqLg%3D%3D&existShop=false&cookie21=VFC%2FuZ9ajCbF99I65Qm9gQ%3D%3D&tag=8&cookie15=Vq8l%2BKCLz3%2F65A%3D%3D&pas=0; uc3=nk2=DkmnuVZqM291&id2=UU8OcO9lI45Clg%3D%3D&vt3=F8dBzr2Fa6i4%2Fc9OIz8%3D&lg2=UtASsssmOIJ0bQ%3D%3D; existShop=MTUyOTIxODk0Nw%3D%3D; sg=g43; csg=c98ee665; cookie1=VTrg90saGzeX9ovigm2mqTr%2Fu6w0vPNLI3IgZ0vhu9E%3D; unb=2761447894; skt=ed11d5f665cdb5a8; _cc_=W5iHLLyFfA%3D%3D; _l_g_=Ug%3D%3D; _nk_=mycarting; cookie17=UU8OcO9lI45Clg%3D%3D; isg=BJubr7m9RASWA7jy73KOygu5KvbF2KV447J0TY3ZbBqxbLlOFUA_wrmuAsRizAdq; apushdf188ec636caeab174aad0f3441beb09=%7B%22ts%22%3A1529221231139%2C%22parentId%22%3A1529220867224%7D",
"Host": "open.taobao.com",
"Referer": "http://open.taobao.com/apitools/apiPropTools.htm?spm=0.0.0.0.mlPbbQ",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36",
}
res = session.get(url, headers=headers)
outArr = res.text.split(";")
if len(outArr) == 3:
if (outArr[0] != '' and outArr[0].find('var props={"itemprops_get_response":{"item_props":{"item_prop":') > 1):
file1 = open('props.csv', 'a')
file1.write('{0}\n'.format(outArr[0]))
file1.close()
else:
print str(cid) + " : " + outArr[0]
if (outArr[1] != '' and outArr[1].find('var propvalues={"itempropvalues_get_response":{"last_modified":') > 1):
file2 = open('propvalues.csv', 'a')
file2.write('{0}\n'.format(outArr[1]))
file2.close()
else:
print str(cid) + " : " + outArr[1]
else:
print outArr
except Exception as err:
print cid
print err
createCidSelect(cidStr)5.3:运行测试爬虫:
1.登录 淘宝开放平台 http://open.taobao.com/apitools/apiPropTools.htm?spm=0.0.0.0.mlPbbQ
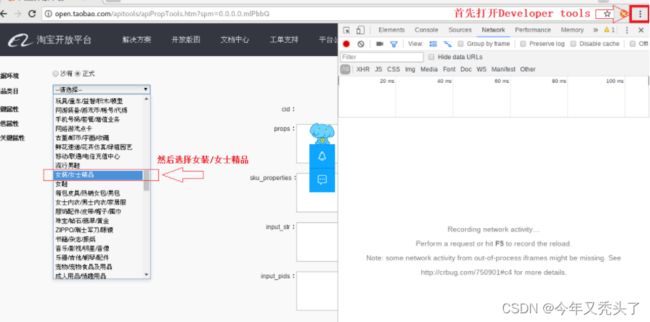

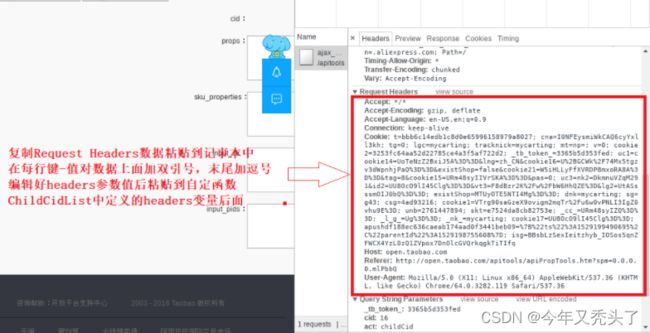 最后需要再一次确认以下地址能够成功返回数据,必须在上面已经登录google浏览器上发送下面这个地址:
最后需要再一次确认以下地址能够成功返回数据,必须在上面已经登录google浏览器上发送下面这个地址:
Request URL:http://open.taobao.com/apitools/ajax_props.do?_tb_token_=3365b5d353fed&cid=16&act=childCid&restBool=false&ua=090%23qCQXU4XvXpXXPXi0XXXXXQkOIr7EkU9szQ4bI%2B5rAGB3fovZcnGnGDkIOrgyTU5nq4QXi6W21dwWXvXBV7Vhihc3oVMCx5QuYk3G4k9sXvXq2CCyOmlXKotK%2BvQXaBVRozUEXudBmmLiXXfbC7NK24QXrpecvTFfoVM3ecgeijLiXXfbC7NKH4QXaOXTsEO4%2FBDGPvQXit2CqnY8PCLiXajeGXriHYVCOFhnDXa3HoUmh9kvXP73IzgeG%2FXXHYVmV6hnDXa3Ho64wvQXib%2Fc2viqUjp%2FXvXuCVHkRwiP3vQXi3e7PUasXvXq2C9LOMVXKym324QXQW3c6vF6oVM37RMEihPz9JPRq4QXi6W21dw%3D

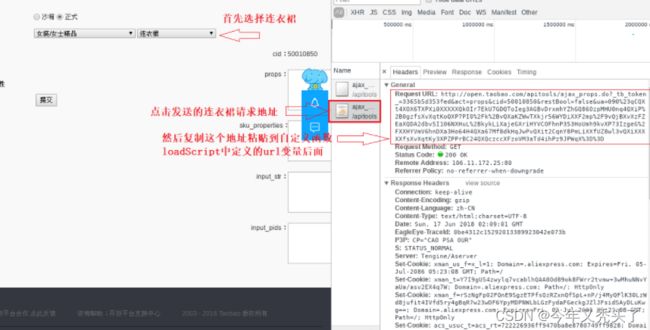

启动爬虫代码:
[myth@contoso ~]$ cd /home/myth/taobao
[myth@contoso taobao]$ python taobao.py
实时输出已经爬下来的数据:
tail -f /home/myth/taobao/category-all.csv
tail -f /home/myth/taobao/props.csv
tail -f /home/myth/taobao/propvalues.csv
为了继续爬顶级分类数据,我们可能要把category-top.csv,props.csv还有propvalues.csv分别另存为
category-top1.csv,props1.csv和propvalues1.csv最后清空已经爬下来的全部数据cat /dev/null > /home/myth/taobao/category-all.csv && cat /dev/null > /home/myth/taobao/props.csv && cat /dev/null > /home/myth/taobao/propvalues.csv
我们可以手动把category-top.csv文件中定义的第1条顶级分类数据------"女装/女士精品"换成
{"cid":16,"is_parent":true,"name":"女装/女士精品","parent_cid":0,"status":"normal"},
如下这条顶级数据分类
{"cid":120886001,"is_parent":true,"name":"公益","parent_cid":0,"status":"normal"},
继续爬取第2条顶级分类数据 -------"公益",依次类推,这样我们就可以爬完整个淘宝网站上的
商品分类数据,关键属性数据,销售属性数据,还有非关键性属性数据。
举例子2:利用爬虫技术读取淘宝页面:
代码展示:
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
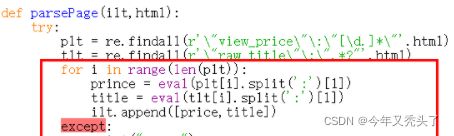
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count,g[0],g[1]))
def main():
goods = '书包'
depth = 2
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
运行结果:
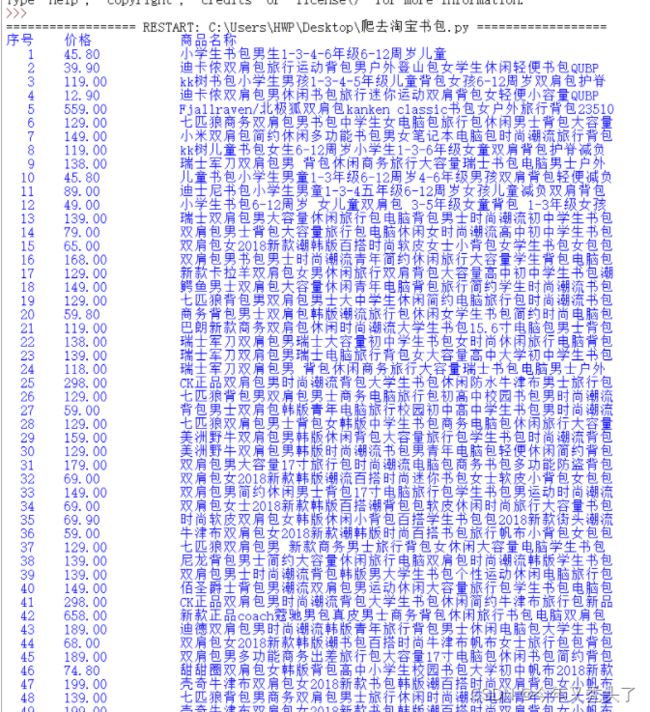
注意:爬取网页需要查看robots协议:
User-agent: *
Disallow: /

查看源代码:价格在view_prince里
要注意对齐的方式,这样就没错误:

否则报错:
六:个人总结:
通过这次深度学习,自己对网络爬虫技术了解的更加深刻了,自己之前只是对爬虫技术有个大概模糊不清的认知。我们在网络上看见的任何东西都可以称之为资源,一个网站可能就是一段html+css,一张图片可能就是某个地址下的XXX.jpg文件,我们则可以通过地址来访问资源,具体的大致思路如下:用户在浏览器中输入访问地址,浏览器向服务器发送HTTP请求。服务器接收到了这些请求之后找到对应的资源返回给浏览器,再经过浏览器的解析,最终呈现在用户面前。爬虫其实就是一段程序代码,相当于我们用户自动浏览并保存网络上的数据,大部分的爬虫都是爬取网页信息,这对于信息的检索给我们带来了巨大的方便。自己这次通过在网上阅览资料以及爬虫的相关视频学习后,总结出学习爬虫的一些经验:1.在刚拿到一个网页时,先确立自己要爬取的数据,记下来,方便一步步完成.2.不要使用一个请求头过多次数,可以适当的加一些。3.根据url拿到页面元素是很重要的一点,每次拿到都要输出,对比页面源代码是否正确。当然,自己现在的学习之路还不能停止,仍需要进一步的研究问题,对于爬虫,如果是遇到的静态爬虫,那么遇到的问题并不会太多,因为静态爬取不需要登陆,也不需要分析请求,自己的学习之路还很漫长,仍需要继续努力!