详解 七大经典排序算法
文章目录
-
- 概念
- 代码
-
- 一、插入排序
-
- 直接插入排序
- 希尔排序
- 二、选择排序
-
- 选择排序
- 堆排序
- 三、交换排序
-
- 冒泡排序
- 快速排序
- 四、归并排序
-
- 归并排序递归
- 归并排序非递归
-
- 法一
- 法二
- 五、非比较排序
-
- 计数排序
- 排序算法总结
-
- 复杂度和稳定性
- 效率测试
概念
主要介绍7种排序算法,都以升序为例
图片
代码
一、插入排序
直接插入排序
思路:
先进行单趟排序:记录数组的首元素和后一位元素,比较大小并进行交换。
即实现[0, end]范围内的有序
再用一层循环使end向后移,实现全部元素排序
void InsertSort(int *a, int n)
{
//2.用一层循环进行所有元素排序
for (int i = 0; i < n - 1; i++)
{
int end = i;//有序序列的最后一位元素下标
int tmp = a[end + 1];//存储end后一位元素,便于最后实现交换
//1.单趟排序
while (end >= 0)//while循环实现[0, end]范围内的有序
{
if (a[end] > tmp)//前大于后,end--
{
a[end + 1] = a[end];
end--;
}
else//前小于后则有序
{
break;
}
}
a[end + 1] = tmp;//实现元素交换(end因为向前移了一位所以使用end+1)
}
}
直接插入排序的特性总结:
- 元素集合越接近有序,直接插入排序算法的时间效率越高
- 时间复杂度:O(N^2)
- 空间复杂度:O(1),是一种稳定的排序算法
- 稳定性:稳定
希尔排序
思路:
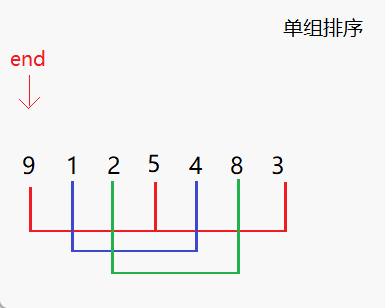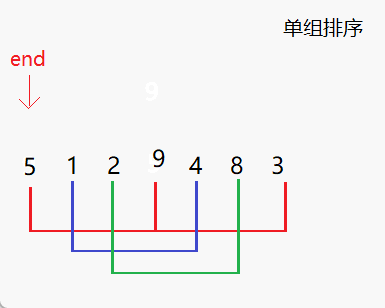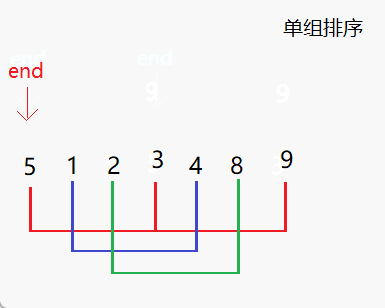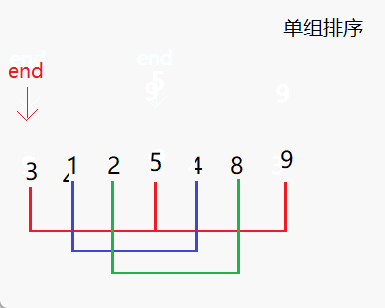
- 设置间距(步长)gap,将待排序序列分为若干组,对每个组进行插入排序。
- 进行两个for循环,内层循环进行单组的排序,外层循环控制end的位置,即进行多组排序。
- 内层循环从j开始,每次将下标加上步长gap,对应到一个新的组中。
- 记录当前组的最后一个元素的下标end,并将最后一个元素的值保存到x中。
- 按照插入排序的方式,将该元素与前面的元素依次进行比较,并向后移动。当找到第一个比它小的元素时,就把它插入到该元素后面。
- 在插入排序完成后,再将内层循环的下标加上步长gap,切换到下一个组进行排序,直到所有的组都排好序。
- 重复执行步骤2到步骤6,直到整个序列都排好序。
void ShellSort(int* a, int n)
{
int gap = 3; // 初始化步长为3
for (int j = 0; j < gap; ++j) // 外层循环,控制步长
{
for (int i = j; i < n - gap; i += gap) // 内层循环,进行插入排序
{
int end = i; // 记录当前数组中的最后一个元素的下标
int x = a[end + gap]; // 记录需要插入的元素的值
while (end >= 0) // 插入排序:如果前面的元素比x大,就将它后移动
{
if (a[end] > x)
{
a[end + gap] = a[end];
end -= gap;
}
else // 如果前面的元素已经排好序了,就跳出循环
{
break;
}
}
a[end + gap] = x; // 将x插入到正确的位置
}
}
}
优化
void ShellSort(int* a, int n)
{
//进行多次预排序直到gap==1
int gap = n;
while (gap > 1)
{
gap /= 2;//gap每次减少一倍
for (int i = 0; i < n - gap; i++)
{
//单趟
int end = i;
int temp = a[end + gap];
while (end >= 0)
{
if (a[end] > temp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = temp;//交换位置
}
}
}
希尔排序的特性总结:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就 会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
- 希尔排序的时间复杂度并不容易直接计算,因为它的具体时间复杂度取决于所使用的步长序列。一般来说,希尔排序的时间复杂度介于 O(n) 和 O(n^2) 之间 对于第一种写法,时间复杂度可以看为O(n^2) 优化后的写法近似看为O(n^(1.5))
- 稳定性:不稳定
二、选择排序
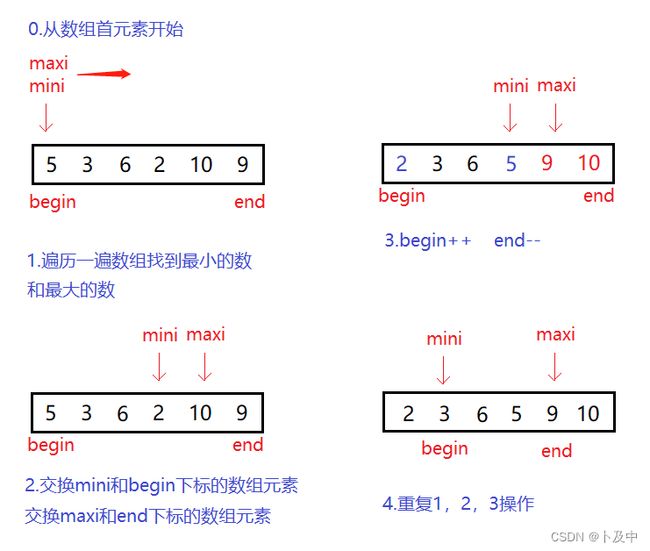
选择排序
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p1 = tmp;
}
void SelectSort(int* a, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int mini = begin, maxi = begin;
//找出最大最小的元素数组下标
for (int i = begin; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
//把数组最小元素放到首位
Swap(&a[mini], &a[begin]);
//当最大元素在数组首位的时候,由于数组已经把首位元素与a[mini]交换,所以先把maxi放在mini位置
if (maxi == begin)
maxi = mini;
Swap(&a[maxi], &a[end]);
begin++;
end--;
}
}
直接选择排序的特性总结:
- 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:不稳定
堆排序
- 构建初始大根堆:首先从最后一个非叶子节点开始进行“向下调整”,将当前节点及其子树构成的二叉树调整为大根堆。重复该过程,直到整个数组成为大根堆。
- 取出堆顶元素:将大根堆的堆顶元素(即数组的第一个元素)与堆底元素交换,并将堆底元素排除在本次排序之外,即已排序好的元素。
- 维护大根堆:将新的堆顶元素向下调整,使其与剩余的堆中的元素重新构成一个大根堆。
- 重复步骤2~3,直到所有元素都被排序。
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
// 选出左右孩子中小的那一个
if (child + 1 < n && a[child + 1] > a[child])
{
++child;
}
// 如果小的孩子小于父亲,则交换,并继续向下调整
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
// 堆排序 -- O(N*logN)
void HeapSort(int* a, int n)
{
// O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
// O(N*logN)
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}
有关堆排序的详细解释↓
堆相关问题(堆排序)
直接选择排序的特性总结:
- 堆排序使用堆来选数,效率就高了很多。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(1)
- 稳定性:不稳定
三、交换排序
基本思想:
所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
冒泡排序
冒泡排序这里提供常规写法以及优化
常规写法:
思路:
冒泡排序应该是大多数人首先写过的排序算法,相对容易理解。
用两层for循环,里层循环进行遍历数组交换,每次把最大的数放到末尾
外层循环让遍历持续进行,使得里层循环每次少遍历一个数(即遍历n-i次)
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n; i++)
{
for (int j = 1; j < n - i; j++)
{
if (a[j - 1] > a[j])
Swap(&a[j], &a[j - 1]);
}
}
}
优化:
定义一个变量用于检测是否发生元素交换,如果没有发生交换则直接返回(已有序),同时用定义end变量赋值n(数组大小),每次循环过后end–
优化后的代码在序列已有序后不再进行遍历,效率更高
void BubbleSort(int* a, int n)
{
//end作为数组最后一位,每交换一次end--
int end = n;
while (end > 0)
{
int flag = 0;
for (int i = 0; i < end - 1; i++)
{
if (a[i] > a[i+1])
{
flag = 1;
Swap(&a[i + 1], &a[i]);
}
}
end--;
//如果flag为零证明没有元素交换,即已有序
if (flag == 0)
{
break;
}
}
}
冒泡排序的特性总结:
- 冒泡排序是一种非常容易理解的排序
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
快速排序
有关快速排序的详细解释在这里:
快速排序
四、归并排序
归并排序递归
下面动图演示:
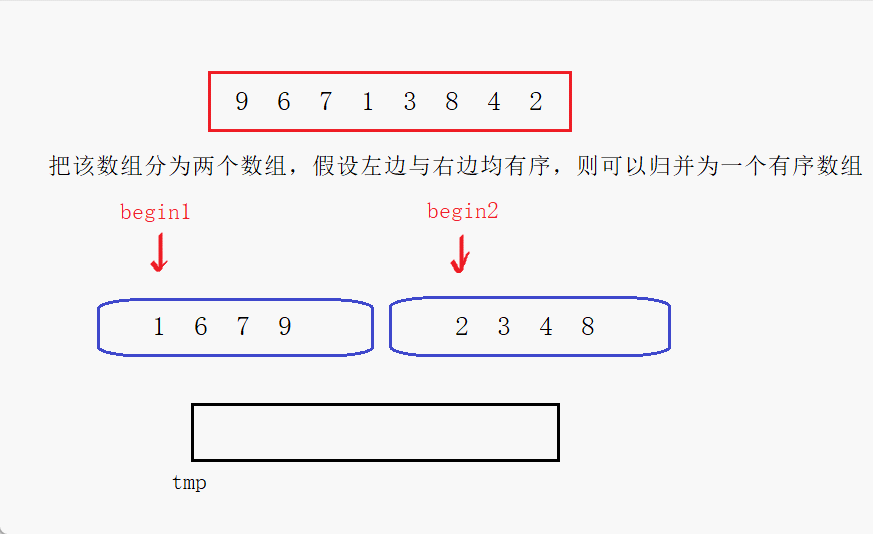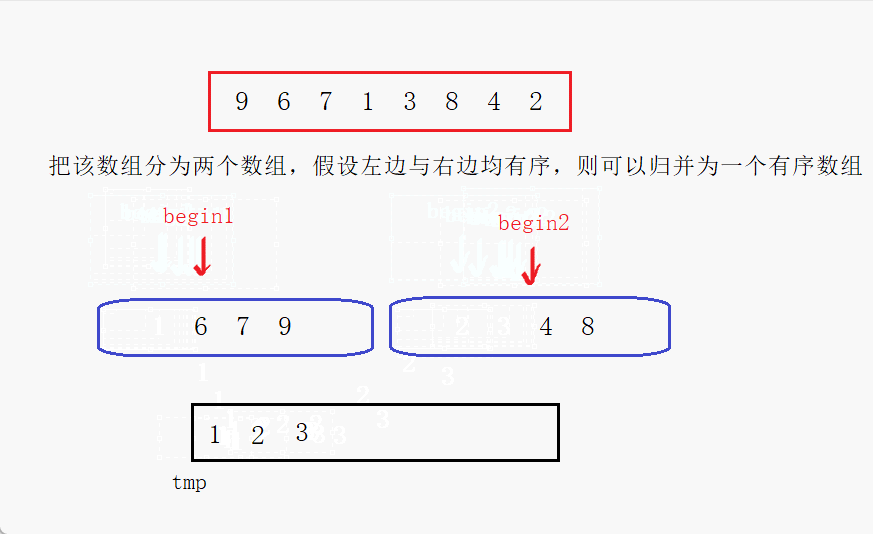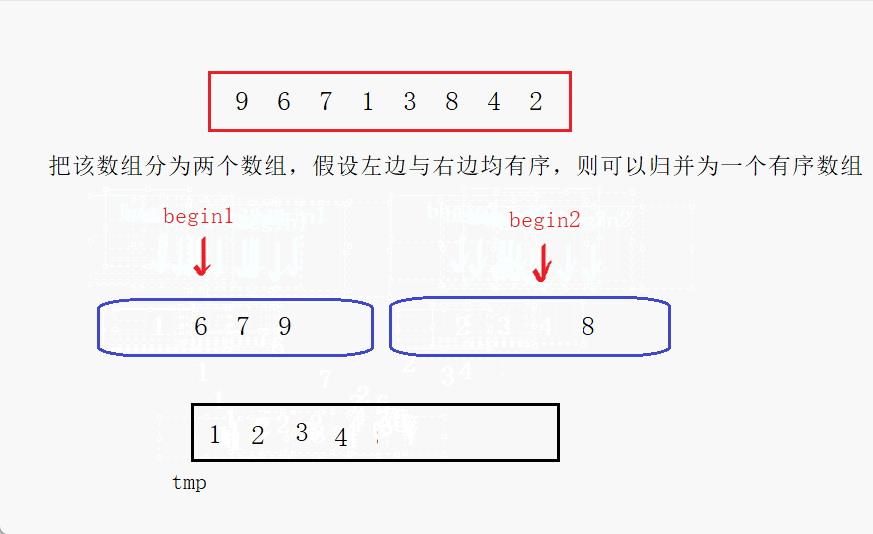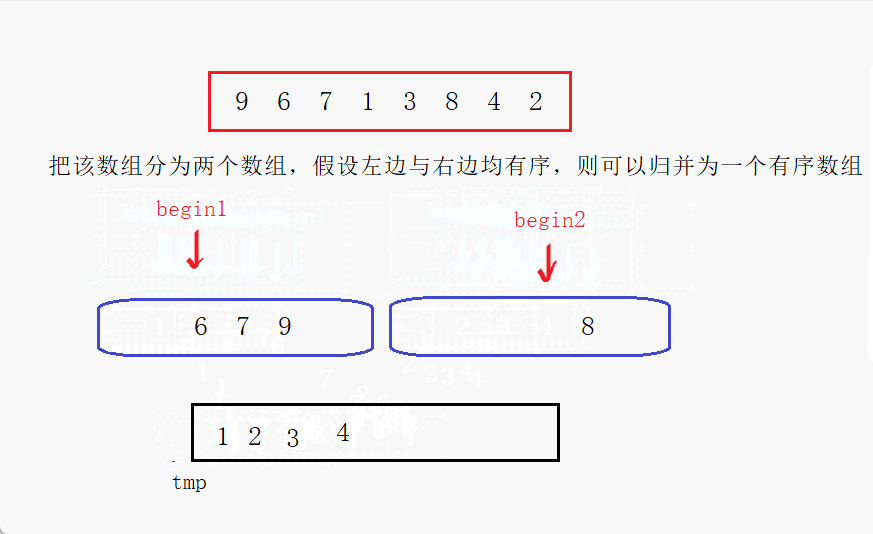
比较begin1与begin2处的元素,将小的放到tmp中,然后该下标位置继续向后走,循环往复直到一个数组全部放入tmp中,最后将另一个数组拷贝进tmp中
- 实际实现需要先将数组逐渐分解再合并,可以使用递归实现
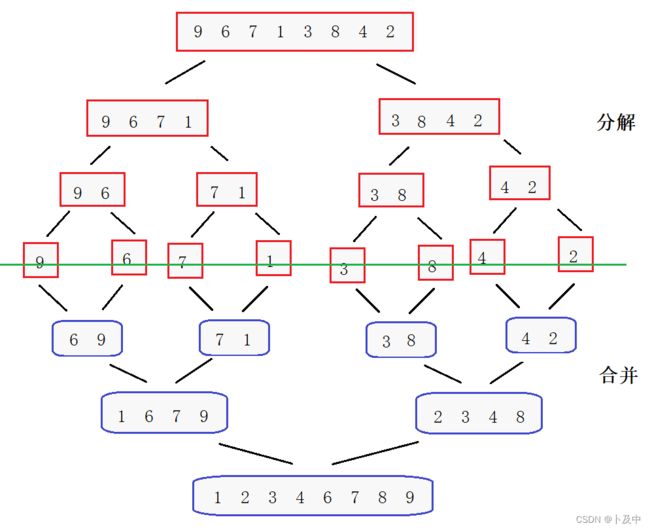
void _MergeSort(int* a, int left, int right, int* tmp)
{
if (left >= right)
return;
int mid = (left + right) / 2;
// [left, mid] [mid+1, right] 有序
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
// a[left, mid] a[mid+1, right] 归并到tmp数组
// 数组被分为[left, mid] [mid+1, right]
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int i = left;
while (begin1 <= end1 && begin2 <= end2)
{
//左右两边哪个元素更小,就放到tmp中并读到下一位
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
//出循环则证明一组元素以及完全入tmp
//再将另一组元素拷贝进tmp中
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
// 最后将tmp数组拷贝回a
for (int j = left; j <= right; ++j)
{
a[j] = tmp[j];
}
}
void MergeSort(int* a, int n)
{
//tmp动态开辟空间
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
tmp = NULL;
}
归并排序非递归
法一
归并排序非递归仍然可以用栈和队列的方式做,不妨使用循环尝试
下面用图片介绍思路/清醒

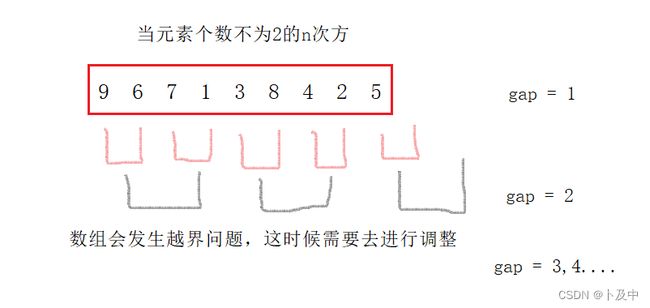
当出现越界后,由于最后需要将tmp中的所有元素拷回a中,所有需要进行元素修正;
比如当end1>=n,此时end=n-1,后续end1便可以拷贝到tmp中,最后拷贝tmp到a中也不会差错。
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(-1);
}
//定义间隔
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//作为下标将元素存进tmp
int index = i;
// [i,i+gap-1] [i+gap,i+2*gap-1] - 用该下标实现分组
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//处理越界问题
//end1越界,[begin2, end2]不存在
if (end1 >= n)
{
end1 = n - 1;
}
//[begin1, end1]存在 [begin2, end2]不存在
if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;//不会进入下面的循环
}
if (end2 >= n)
{
end2 = n - 1;
}
//同于递归的思路
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
//将另一组拷贝给tmp
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
}
//把归并后的数据拷贝回原数组
for (int j = 0; j < n; j++)
{
a[j] = tmp[j];
}
gap *= 2;//gap扩大一倍
}
free(tmp);
tmp = NULL;
}
法二
当end1/begin2越界时,实际并没有必要继续归并(后面的所有元素都越界),break即可;
当end2越界时,直接修正即可(后面无元素)。
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
// [i,i+gap-1] [i+gap,i+2*gap-1]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//end1、begin2、end2都有可能越界
// end1越界 或者 begin2 越界都不需要归并(后面元素均越界)
if (end1 >= n || begin2 >= n)
{
break;
}
// end2越界,需要归并,修正end2
if (end2 >= n)
{
end2 = n - 1;
}
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
// 把归并小区间拷贝回原数组
for (int j = i; j <= end2; ++j)
{
a[j] = tmp[j];
}
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}
归并排序的特性总结:
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
五、非比较排序
计数排序
作为非比较排序,计数排序在排序过程中没有进行大小比较,思路为下
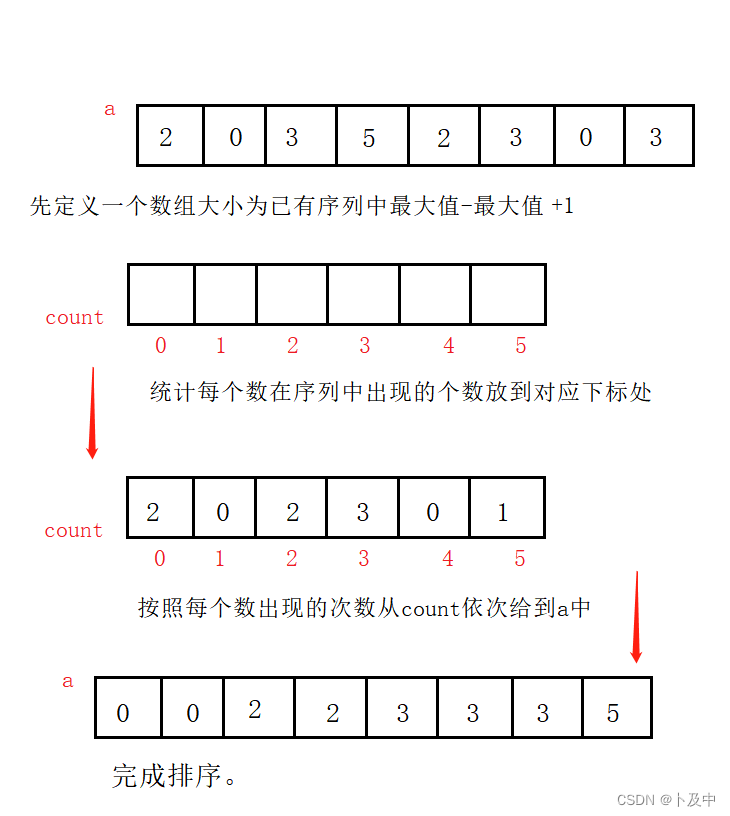
void CountSort(int* a, int n)
{
int min = a[0], max = a[0];
//找到最大值最小值
for (int i = 1; i < n; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
//定义数组大小范围
int range = max - min + 1;
int* count = (int*)malloc(sizeof(int) * range);
memset(count, 0, sizeof(int) * range);
if (count == NULL)
{
perror("malloc fail\n");
exit(-1);
}
//统计每个数字出现的次数
for (int i = 0; i < n; i++)
{
count[a[i] - min]++;//- min因为需要对应count的范围
}
//根据次数进行排序
int index = 0;
for (int i = 0; i < range; i++)
{
while (count[i]--)
{
a[index++] = i + min;
}
}
}
计数排序在以下情况下效率最低:
取值范围过大:计数排序需要创建一个计数数组,其大小为待排序元素的最大值,当待排序元素的取值范围过大时,计数数组也会变得很大,这会导致内存占用过高。如果无法分配足够的内存空间,则会导致程序崩溃或者运行缓慢。
待排序元素重复较多:当待排序元素重复较多时,计数数组中很多元素的值都是0,而且计数排序需要频繁地访问和修改计数数组,这可能会导致CPU缓存失效和内存频繁读写,从而影响排序的效率。
待排序元素分布不均匀:如果待排序元素分布不均匀,即有些元素出现的次数很少,有些元素出现的次数很多,这会导致计数数组中有很多无用的元素,浪费了内存空间,同时也会增加访问和修改计数数组的次数,从而降低了排序的效率。
计数排序的特性总结:
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,范围))
- 空间复杂度:O(范围)
- 稳定性:稳定
排序算法总结
复杂度和稳定性
| 排序算法 | 时间复杂度(平均) | 空间复杂度 | 稳定性 |
|---|---|---|---|
| 冒泡排序 | O(n^2) | O(1) | 稳定 |
| 选择排序 | O(n^2) | O(1) | 不稳定 |
| 直接插入排序 | O(n*logn) ~ O(n^2) | O(1) | 稳定 |
| 希尔排序 | O(n*logn) | O(1) | 不稳定 |
| 堆排序 | O(n*logn) | O(1) | 不稳定 |
| 归并排序 | O(n*logn) | O(n) | 稳定 |
| 快速排序 | O(n*logn) | O(logn) ~ O(n) | 不稳定 |
效率测试
用下面的函数测试以上排序在面对不同数量数据时的处理速率(单位:毫秒)
void TestSpeed()
{
srand(time(0));
const int N = 1000000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
int* a8 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N - 1);
int end5 = clock();
int begin6 = clock();
MergeSort(a6, N);
int end6 = clock();
int begin7 = clock();
CountSort(a7, N);
int end7 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
printf("CountSort:%d\n", end7 - begin7);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
free(a7);
}
以下为不同元素个数时的运行结果:
元素个数:10000
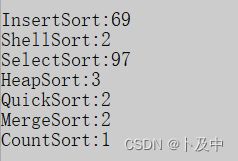
元素个数:1000000
由于前三个排序效率太低,进行了屏蔽后结果为0:
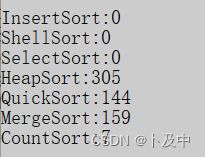
综上由于计数排序在部分情况下效率很低;而堆排序不适合数据规模较小的情况;归并排序有一定的空间消耗;相比下快排的总体性能是比较好的。