hadoop3.2.4伪分布式环境搭建
大数据
文章目录
- 前言
- 一、下载安装包
- 二、安装步骤
-
- 2.1.解压hadoop安装包
- 2.2修改环境变量
- 2.3 本地免密登录
-
- 2.3.1 执行一下命令
- 2.3.2 测试是否生效
- 2.4 修改配置文件
-
- 2.4.1 修改/root/tools/hadoop-3.2.4/etc/hadoop目录下的core-site.xml
- 2.4.2 修改/root/tools/hadoop-3.2.4/etc/hadoop目录hdfs-site.xml的文件内容
- 2.5 启动hdfs
-
- 2.5.1 格式化本地文件,进入/root/tools/hadoop-3.2.4目录
- 2.5.2 启动hdfs
- 2.5.3 执行后在浏览器输入
- 三 测试demo例子
-
- 3.1 创建执行目录
- 3.2 拷贝输入文件
- 3.3 执行MapReduce jar
- 3.4 拷贝执行结果,并且查看执行结果
- 四、以yarn方式执行计算
-
- 4.1 修改配置文件
-
- 4.1.1 配置文件etc/hadoop/mapred-site.xml
-
- 4.1.2 etc/hadoop/yarn-site.xml
- 4.2 启动yarn
- 4.3 执行计算
- 4.4 重启hdfs重新执行计算jar命令
- 4.5 重新执行jar命令
- 总结
前言
大数据hadoop学习,看官网,hadoop搭建有三种方式,
- 单机
- 伪分布式
- 集群部署
这里是伪分布式部署,即必须程序都在一台机器上完成部署。作为学习使用是最简单的方式。hadoop主要的程序有1.hdfs,分布式文件系统,启动后会有两个java程序,一个是datanode,一个是namenode。
2,yarn yarn是对集群任务的分发控制,主要程序有nodemanage,resourcemanage两个程序。mapreduce只是计算的程序,不是这个框架本身启动的服务。
一、下载安装包
下载安装包地址为:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
前置条件,安装好jdk8,这里就不展开了,很多教程。
二、安装步骤
2.1.解压hadoop安装包
拷贝安装包到你需要安装的目录,我这里是新建了一个安装目录
/root/tools
执行命令
tar –zxvf hadoop-3.2.4.tar.gz
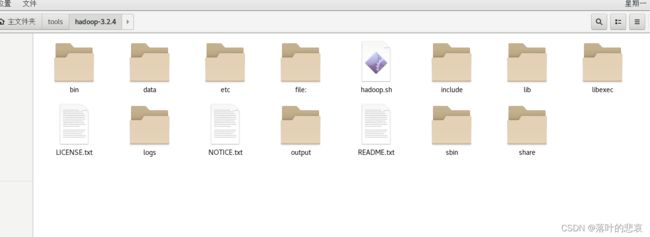
解压后得到如下图目录
/root/tools/hadoop-3.2.4
2.2修改环境变量
vi /etc/profile
在文件末尾添加:
export JAVA_HOME=/root/tools/jdk/jdk1.8.0_144
export HADOOP_HOME=/root/tools/hadoop-3.2.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=/root/tools/hadoop-3.2.4/etc/Hadoop
这里我安装hadoop的路径为/root/tools/hadoop-3.2.4
jdk的安装路径为 /root/tools/jdk/jdk1.8.0_144
编辑完后保存,执行命令 如下,让刚刚的修改生效。
source /etc/profile
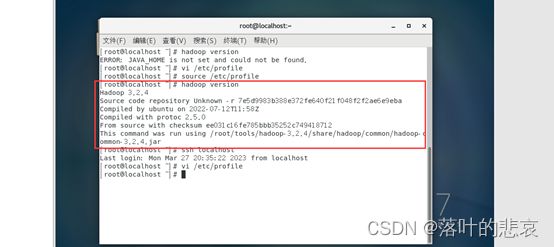
执行命令
hadoop version
2.3 本地免密登录
2.3.1 执行一下命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
2.3.2 测试是否生效
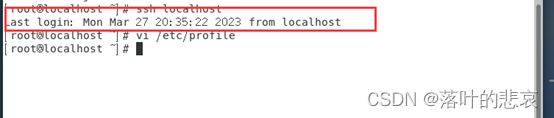
执行后输入ssh localhost正常的输出如下
ssh localhost
2.4 修改配置文件
2.4.1 修改/root/tools/hadoop-3.2.4/etc/hadoop目录下的core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2.4.2 修改/root/tools/hadoop-3.2.4/etc/hadoop目录hdfs-site.xml的文件内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
2.5 启动hdfs
2.5.1 格式化本地文件,进入/root/tools/hadoop-3.2.4目录
第一次启动需要执行命令
bin/hdfs namenode –format
报错如下:
[root@localhost hadoop-3.2.4]# bin/hdfs namenode –format
ERROR: JAVA_HOME is not set and could not be found.
解决办法:
修改解压后目录的 etc/Hadoop/hadoop-env.sh
修改java_home路径,
export JAVA_HOME=/root/tools/jdk/jdk1.8.0_144
如果不知道路径,可以用 vi /etc/profile查看java_home路径。,
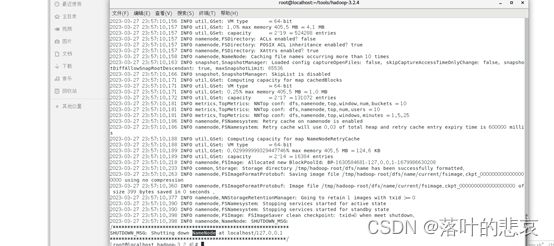
执行结果如下
解决了报错后,执行format指令的结果如下图所示
2.5.2 启动hdfs
执行命令
./sbin/start-dfs.sh
报错如下
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation
解决:
在etc/Hadoop/hadoop-env.sh 文件添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2.5.3 执行后在浏览器输入
http://localhost:9870/ namenode web地址
结果如下能看到如下界面启动成功
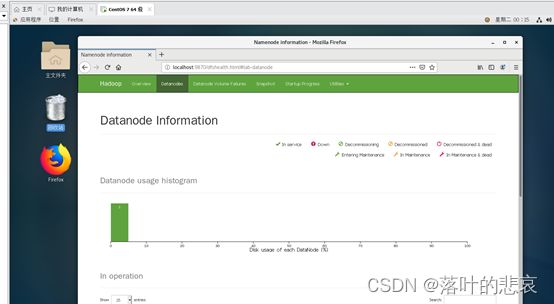
三 测试demo例子
3.1 创建执行目录
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/root
3.2 拷贝输入文件
bin/hdfs dfs -mkdir input
bin/hdfs dfs -put etc/hadoop/*.xml input
3.3 执行MapReduce jar
执行一下命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar grep input output 'dfs[a-z.]+'
执行结果如下图所示
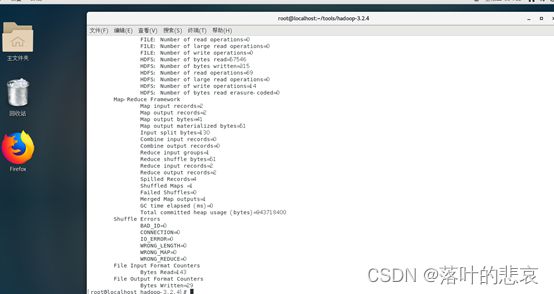
3.4 拷贝执行结果,并且查看执行结果
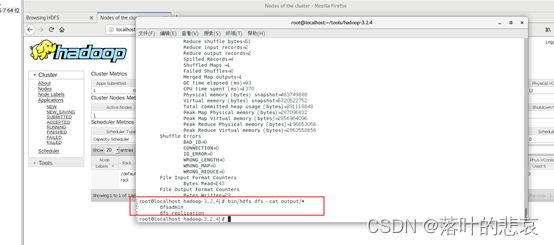
bin/hdfs dfs -get output output
cat output/*
结果如下图
四、以yarn方式执行计算
yarn方式计算也是要启动hdfs为前提的,上面的步骤依然要执行。
4.1 修改配置文件
4.1.1 配置文件etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
4.1.2 etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
4.2 启动yarn
sbin/start-yarn.sh
浏览器输入以下地址,ResourceManager 页面:
http://localhost:8088/
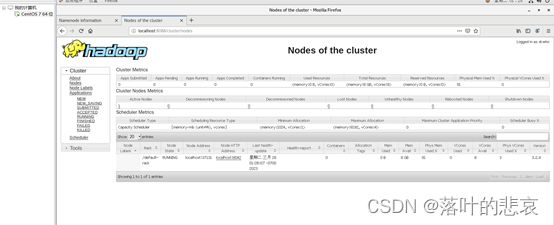
4.3 执行计算
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar grep input output 'dfs[a-z.]+'
报错如下
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot delete /user/root/grep-temp-1038537
解决:
hdfs-site.xml文件中添加
<property>
<name>dfs.safemode.threshold.pct</name>
<value>0f</value>
<description>
Specifies the percentage of blocks that should satisfy
the minimal replication requirement defined by dfs.replication.min.
Values less than or equal to 0 mean not to wait for any particular
percentage of blocks before exiting safemode.
Values greater than 1 will make safe mode permanent.
</description>
</property>
4.4 重启hdfs重新执行计算jar命令
报错如下
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/roo
解决:删除输出目录
./bin/hdfs dfs -rm -r output
4.5 重新执行jar命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar grep input output 'dfs[a-z.]+'
查看输出结果,执行命令bin/hdfs dfs -cat output/*
如下图
Hdfs启动有SecondaryNameNode,namenode,datanode,yarn启动有NodeManager ResourceManager
总结
本文是根据官网上面的案例进行实践的,过程中遇到的问题也记录下来了,如果本文对你有帮助,点个赞吧,不对的地方也欢迎指出。