语义分割实践—耕地提取(二分类)
开篇:感谢李沐老师团队为深度学习教学做出的巨大贡献,对李沐老师及团队致以深深的敬意。同时,对技术开发社区以及编程技术网站的优质创作者们(Jack_Cui等)表示深深的感谢。
一、深度学习网络中的常见概念
(一)Ground Truth
通常指人工标注目标的结果(一般认定为100%准确的标签),实际具有人为主观性。
(二)Data Augmentation(数据增强)
数据增强通常被用于小样本集训练中。由于深度学习的参数个数与任务的复杂度成正比,而足够的参数个数又需要足够多的样本支持,所以我们可以通过数据增强来获得较多的样本。目前,流行的数据增强技术有翻转(Flip)、旋转(Rotation)、缩放比例(Scale)、裁剪(Crop)、移位(Translation)和高斯噪声(Gaussian Noise)等。
对于数据增强而言,其具有阻止神经网络学习不相关的特征,从根本上提升整体性能的特点。
(三)Backbone(主干网络)
主干网络主要指提取特征的网络,其作用是提取图片中的信息以供后面的网络使用。这些网络通常使用的是ResNet、VGG等强特征提取网络,而不是我们自己设计的网络。在使用强特征提取网络作为Backbone的时候,基本为直接加载官方已经训练好的模型参数(或微调),后接我们自己的网络。
(四)Head
通常指输出结果内容的网络,该网络利用已提取出的特征进行结果输出(或预测)。
(五)BottleNeck
通常指网络输入的数据维度和输出的数据维度不一致(联系ResNet中的Skip-Connection操作)。BottleNeck通常有两种解决方法,分别为采用zero-padding增加维度和采用1×1卷积增加维度。
(六)Warm Up
通常指利用一个小的学习率预先训练一定的Epoch。若初始时便用较大的学习率,易导致随机初始化的网络参数数值不稳定。
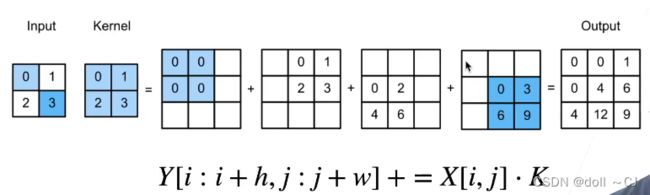
(七)转置卷积[9]
转置卷积是一种卷积,它将输入和核进行了重新排列,同卷积一般是做下采样不同,它通常用作上采样。如果卷积将输入从(h,w)变成了(h‘,w'),同样超参数下转置卷积将(h‘,w')变成(h,w)。
转置卷积可以变为对应核的矩阵乘法。转置卷积是一种变化了输入和核的卷积,来得到上采样的目的,其并不等同于数学上的反卷积概念。在深度学习中,反卷积神经网络指用了转置卷积的神经网络。
二、U-Net网络原理
(一)FCN语义分割概述
FCN(Fully Convolutional Networks for Semantic Segmentation)是语义分割领域基于深度学习算法的开山之作。FCN的特征融合方式是特征图对应像素值相加。
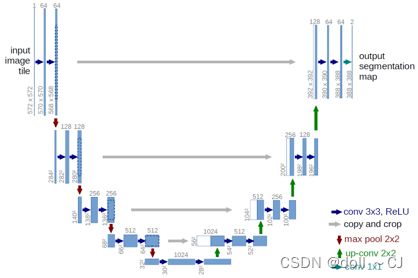
(二)U-Net语义分割原理[23][12][17]
U-Net网络属于FCN的一种变体,网络结构是对称的,形似英文字母U,它简单、高效、易懂且容易构建,可以较好满足小数据集训练。就整体而言,U-Net是一个Encoder-Decoder的结构,前半部分是主干特征提取,后半部分是加强特征提取。
U-Net网络主要解决的问题有:
I 输入图像大小的统一与跳层连接特征图大小的统一(图像Crop操作)
II 图像恢复(加强特征提取网络)的上采样方式(双线性插值或者转置卷积)
III 训练过程特征图高宽大小减半方式(最大池化或者不Padding的卷积)
IV 特征图输出与图像输入大小一致抉择(层层卷积Padding保持高宽不变,Padding一般选择reflect,因为深层的特征图边缘信息补零会对结果产生较大影响)
引自参考资料[17]:
深/浅层特征有着各自意义:网络越深,感受野越大,网络关注那些全局特征(更抽象、更本质);浅层网络则更加关注纹理等局部特征特征;
通过特征拼接来实现边缘特征的找回。通过上采样(转置卷积)固然能够得到更大尺寸的特征图,但特征图的边缘是缺少信息的。毕竟每一次下采样提取特征的同时,必然会损失一些边缘特征,而上采样并不能找回这些失去的特征。
三、网络模型主要实现代码
(一)将数据分为训练集、验证集和测试集(8:1:1)

import os
from random import shuffle
import shutil
# 1、原数据训练集、验证集、测试集分类
Ltrain = r"G:\ChanXueYan\dataset\train_val_test\Ltrain"
Lval = r"G:\ChanXueYan\dataset\train_val_test\Lval"
Ltest = r"G:\ChanXueYan\dataset\train_val_test\Ltest"
train = r"G:\ChanXueYan\dataset\train_val_test\train"
val = r"G:\ChanXueYan\dataset\train_val_test\val"
test = r"G:\ChanXueYan\dataset\train_val_test\test"
RGB = r"G:\ChanXueYan\dataset\images"
BiaoQian = r"G:\ChanXueYan\dataset\labels"
ImgName = os.listdir(RGB)
shuffle(ImgName)
# 8:1:1分配训练集、验证集和测试集
tr = ImgName[0:int(0.8*len(ImgName)):1]
va = ImgName[int(0.8*len(ImgName)):int(0.9*len(ImgName)):1]
te = ImgName[int(0.9*len(ImgName)):len(ImgName):1]
for n,L,data in [(train,Ltrain,tr),(val,Lval,va),(test,Ltest,te)]:
for i in data:
# 组合绝对路径
Opath = os.path.join(RGB,i)
shutil.move(Opath,n)
# 移动标签
lname = i.split(".")[0] + "_mask.png"
OLpath = os.path.join(BiaoQian,lname)
shutil.move(OLpath,L)
(二)训练图片—数据增强(此处仅做水平翻转和垂直翻转)
原有训练数据为16000幅,经过0.6概率的随机数据增强且数据质量筛选后增广为31239幅。

import os
import random
import cv2
import matplotlib.image as mping
import matplotlib.pyplot as plt
# 2、训练集数据增强
trainPath = r"G:\ChanXueYan\dataset\train_val_test\train"
LtrainPath = r"G:\ChanXueYan\dataset\train_val_test\Ltrain"
train_img = os.listdir(trainPath)
imgChuLi = []
for img in train_img:
# 以0.6的概率对图片进行数据增强
if random.randint(1,10) > 6:
continue
else:
aw5 = trainPath + "\\" + img
aw6 = LtrainPath + "\\" + img.split(".")[0] + "_mask.png"
i = cv2.imread(aw5)
Li = cv2.imread(aw6)
# 对数据进行上下翻转
ifilpUD = cv2.flip(i,0)
LifilpUD = cv2.flip(Li,0)
# 对数据进行左右翻转
iflipZY = cv2.flip(i,1)
LiflipZY = cv2.flip(Li,1)
# 对数据存储为无损PNG
aw1 = trainPath + "\\" + img.split(".")[0] + "sx.png"
aw2 = trainPath + "\\" + img.split(".")[0] + "zy.png"
aw3 = LtrainPath + "\\" + img.split(".")[0] + "sx_mask.png"
aw4 = LtrainPath + "\\" + img.split(".")[0] + "zy_mask.png"
cv2.imwrite(aw1, ifilpUD,[int(cv2.IMWRITE_PNG_COMPRESSION),0])
cv2.imwrite(aw2, iflipZY,[int(cv2.IMWRITE_PNG_COMPRESSION),0])
cv2.imwrite(aw3, LifilpUD,[int(cv2.IMWRITE_PNG_COMPRESSION),0])
cv2.imwrite(aw4, LiflipZY,[int(cv2.IMWRITE_PNG_COMPRESSION),0])
# 用于展示数据增强结果
imgChuLi.append((aw5,aw6,aw1,aw3,aw2,aw4))
# 绘制前三个数据增强展示
fig,ax = plt.subplots(6,3,figsize=(15,15))
imgChuLi3 = imgChuLi[0:3:1]
countRGB = 0
countMask = 1
for i in imgChuLi3:
img1p,img2p,img3p,img4p,img5p,img6p = i
img1 = mping.imread(img1p)
img2 = mping.imread(img2p)
img3 = mping.imread(img3p)
img4 = mping.imread(img4p)
img5 = mping.imread(img5p)
img6 = mping.imread(img6p)
ax[countRGB][0].imshow(img1)
ax[countRGB][1].imshow(img3)
ax[countRGB][2].imshow(img5)
ax[countMask][0].imshow(img2)
ax[countMask][1].imshow(img4)
ax[countMask][2].imshow(img6)
countRGB += 2
countMask += 2
plt.show()(三)U-Net网络模型
import torch
from torch import nn
# U-Net网络的组成部分(Part)
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
# 通过边缘镜像填补的方式,保持卷积前后图像二维大小不变
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, padding_mode="reflect"),
nn.BatchNorm2d(out_channels),
nn.Dropout2d(0.3),
nn.LeakyReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, padding_mode="reflect"),
nn.BatchNorm2d(out_channels),
nn.Dropout2d(0.3),
nn.LeakyReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
# 利用转置卷积扩增二倍二维大小
self.up = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# U-Net中的跳层连接(基于列连接)
# x实际上是一个四维的tensor,所以torch.cat()中dim=1,意在三维连接
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
# U-Net网络实体
class UNet(nn.Module):
def __init__(self, n_channels, n_classes):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
self.up1 = Up(1024, 512)
self.up2 = Up(512, 256)
self.up3 = Up(256, 128)
self.up4 = Up(128, 64)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
x = self.outc(x)
return x(四)训练代码
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
import Net_Structure
import Data_Preprocess
# RGB图像及语义分割标签数据绝对路径
trainPath = r"G:\ChanXueYan\dataset\train_val_test\train"
LtrainPath = r"G:\ChanXueYan\dataset\train_val_test\Ltrain"
valPath = r"G:\ChanXueYan\dataset\train_val_test\val"
LvalPath = r"G:\ChanXueYan\dataset\train_val_test\Lval"
# 权重参数文件存储地址
Weight_folder = r"G:\ChanXueYan\dataset\Weight"
# 超参数设置
batch_size = 5
lr = 0.0001
epochs = 100
# 学习率下降参数
step_size = 20
# 可视化损失参数—检查是否收敛
print_PiCi = 100
# GPU设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# First:训练RGB图片和标注标签读入
data_loader = DataLoader(Data_Preprocess.MyDataset(trainPath, LtrainPath), batch_size=batch_size, shuffle=True, num_workers=0)
net = Net_Structure.UNet(3, 2).to(device)
# 组合权重文件.pth路径
wp = os.path.join(Weight_folder, "U_net.pth")
if os.path.exists(wp):
net.load_state_dict(torch.load(wp))
print("Weight Successfully load!")
else:
print("NONE,please check file,if this is not first training!")
# 计算损失和创建优化器并动态调整学习率
# 权重衰减缓解过拟合
optimizer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay=1e-8)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=0.5)
# 训练
train_loss = 0
for epoch in range(epochs):
for batch_idx, (img, label) in enumerate(data_loader):
# batch_idx为批次索引
img, label = img.to(device), label.to(device, dtype=torch.long)
outputs = net(img)
loss = criterion(outputs, label)
# 单批次梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 可视化损失(可视化区间末尾)
train_loss += loss.item()
if batch_idx % print_PiCi == print_PiCi - 1:
print(f"{epoch}--{batch_idx}:train loss {train_loss / ((epoch + 1) * (batch_idx + 1))}")
scheduler.step()
# 存储训练的权重文件
if epoch % 10 == 9:
Wepoch = os.path.join(Weight_folder, f"U_net{epoch}.pth")
torch.save(net.state_dict(), Wepoch)(五)预测代码
import os
import cv2
import torch
from torchvision import transforms
import Net_Structure
# 测试文件地址
testPath = r"G:\ChanXueYan\dataset\train_val_test\test"
LtestPath = r"G:\ChanXueYan\dataset\train_val_test\Ltest"
# 分割图片存储地址
seg_savePath = r"G:\ChanXueYan\dataset\predict"
# 分割图颜色映射表
cultivateLand = 255
background = 0
# GPU设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载网络
PTH_Path = r"G:\ChanXueYan\dataset\Weight\U_net49.pth"
net = Net_Structure.UNet(3, 2).to(device)
net.load_state_dict(torch.load(PTH_Path))
# 测试模式
net.eval()
# 预测部分
count = 0
imgShow = []
transform = transforms.Compose([transforms.ToTensor()])
Test_ImgName = os.listdir(testPath)
for n in Test_ImgName:
Tname = n.split(".")[0]
test_path = os.path.join(testPath, n)
Ltest_path = os.path.join(LtestPath, Tname + "_mask.png")
# 数据读入
img = transform(cv2.imread(test_path))
# 与网络输入维度一致
img = torch.unsqueeze(img, dim=0).to(device)
# 开始预测
predict = net(img)
predict = torch.squeeze(predict)
classImg = torch.argmax(predict, dim=0)
# 还原图像对比显示
segmentation = classImg * cultivateLand
# tensor转numpy(为了使用cv2保存图片)
# GPU下的tensor不能直接转numpy
segmentation = segmentation.cpu().numpy()
# 保存语义分割图片
segImgPath = os.path.join(seg_savePath, f"{Tname}_seg.png")
cv2.imwrite(segImgPath, segmentation)
(六)MIOU计算
import cv2
import numpy as np
import os
import matplotlib.pyplot as plt
import matplotlib.image as mping
# 测试标签文件夹
Ltest_Fpath = r"G:\ChanXueYan\dataset\train_val_test\Ltest"
# 测试语义分割图文件夹
Ptest_Fpath = r"G:\ChanXueYan\dataset\predict"
# 语义分割测试集原图文件夹
test_Fpath = r"G:\ChanXueYan\dataset\train_val_test\test"
Predict_test_f = os.listdir(Ptest_Fpath)
# 对存在背景和耕地的图片独立计数
count_cultivate = 0
count_underground = 0
# iou曲线绘制存储
cultivate_iouList = []
underground_iouList = []
# 对耕地IOU进行存储(后续观察比较语义分割较好和较差的图像)
cshow_iou = []
# 计算两类的平均MIOU
cultivate_iou_total = 0
underground_iou_total = 0
count = 0
for n in Predict_test_f:
imgName = n.split("_")[0]
LimgPath = os.path.join(Ltest_Fpath, f"{imgName}_mask.png")
PimgPath = os.path.join(Ptest_Fpath, n)
imgPath = os.path.join(test_Fpath, f"{imgName}.png")
# 读取图片并将二者转为灰度图
Limg = cv2.imread(LimgPath)
Pimg = cv2.imread(PimgPath)
LG = np.array(cv2.cvtColor(Limg, cv2.COLOR_BGR2GRAY))
PG = np.array(cv2.cvtColor(Pimg, cv2.COLOR_BGR2GRAY))
# 计算耕地像素预测与标签的评价矩阵
# 仅有耕地、背景两类
TP, FP, TN, FN = 0, 0, 0, 0
# 循环计算
# 部分图片不存在耕地类别
for h in range(256):
for w in range(256):
if LG[h][w] == PG[h][w] == 255:
TP += 1
elif LG[h][w] == 255 and PG[h][w] == 0:
FN += 1
elif LG[h][w] == 0 and PG[h][w] == 255:
FP += 1
else:
TN += 1
# 计算耕地的iou
if TP + FN + FP > 0:
cultivate_iou = TP / (TP + FN + FP)
cultivate_iou_total += cultivate_iou
cultivate_iouList.append(cultivate_iou)
cshow_iou.append((cultivate_iou, imgPath, LimgPath, PimgPath))
count_cultivate += 1
# 计算背景的iou
if TN + FN + FP > 0:
underground_iou = TN / (TN + FN + FP)
underground_iou_total += underground_iou
underground_iouList.append(underground_iou)
count_underground += 1
count += 1
# 打印单幅图像进度
print(f"第{count}幅图像---已完成")
# 计算测试样本耕地种类的MEAN_IOU
cultivate_mean_iou = cultivate_iou_total / count_cultivate
underground_mean_iou = underground_iou_total / count_underground
print(f"耕地种类的平均交并比为{cultivate_mean_iou}")
print(f"背景种类的平均交并比为{underground_mean_iou}")
# 一、绘制测试样本交并比曲线
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(15, 15), layout="constrained")
# 耕地IOU曲线
cultivate_numList = [i for i in range(count_cultivate)]
cultivate_mean_iouList = [cultivate_mean_iou for i in range(count_cultivate)]
# 背景IOU曲线
underground_numList = [i for i in range(count_underground)]
underground_mean_iouList = [underground_mean_iou for i in range(count_underground)]
# 绘制IOU曲线
ax1.plot(cultivate_numList, cultivate_iouList, linewidth=0.8)
ax1.plot(cultivate_numList, cultivate_mean_iouList, linewidth=0.8)
ax2.plot(underground_numList, underground_iouList, linewidth=0.8)
ax2.plot(underground_numList, underground_mean_iouList, linewidth=0.8)
# 绘制设置
ax1.set_xlabel("Test_Num")
ax1.set_ylabel("cultivate-IOU")
ax1.set_title("The curve of Cultivate-IOU")
ax2.set_xlabel("Test_Num")
ax2.set_ylabel("underground-IOU")
ax2.set_title("The curve of underground-IOU")
plt.show()
# 二、显示高IOU和低IOU的图像对比,默认从小到大排列
cshow_iou_sorted = sorted(cshow_iou)
cshow_size = len(cshow_iou_sorted)
# 低IOU展示
ImgFig1, AX1 = plt.subplots(6, 3, figsize=(10, 10), layout="constrained")
for i in range(6):
_, timg, limg, pimg = cshow_iou_sorted[i]
print(limg)
AX1[i][0].imshow(mping.imread(timg))
AX1[i][1].imshow(mping.imread(limg))
AX1[i][2].imshow(mping.imread(pimg))
plt.show()
# 高IOU展示
ImgFig2, AX2 = plt.subplots(6, 3, figsize=(10, 10), layout="constrained")
for i in range(cshow_size-6, cshow_size):
_, timg, limg, pimg = cshow_iou_sorted[i]
print(limg)
AX2[i+6-cshow_size][0].imshow(mping.imread(timg))
AX2[i+6-cshow_size][1].imshow(mping.imread(limg))
AX2[i+6-cshow_size][2].imshow(mping.imread(pimg))
plt.show()
四、实验结果及精度评价[46]
本次测试集共1750个样本(经过数据质量筛选),耕地的MIOU为0.74.,背景的MIOU为0.72.。
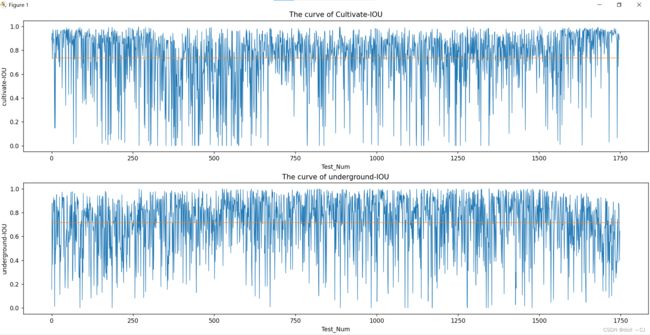
图一 测试样本耕地/背景的IOU曲线图

图二 测试样本的耕地低IOU结果图

图三 测试样本的耕地高IOU结果图
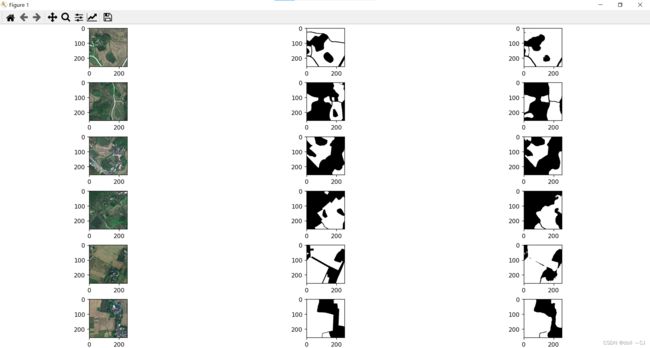
图四 灰度显示对比的耕地高IOU结果图
五、实验过程总结
(一)PNG格式和JPG格式图片压缩存储原理
PNG格式是一种便携式网络图形格式,采用的是无损数据压缩算法,在不损坏图像质量的前提下降低文件的存储大小,而且对图像的颜色没有任何影响。
JPEG压缩属于有损压缩,即把人眼不易观察的部分去掉(通常为高频部分),从而节省存储大小。
实验总结:在进行数据增强时并不需要对PNG图片进行非压缩,因为PNG无损压缩算法不改变图像颜色信息。同时,对PNG图片进行无损压缩存储可以节省存储空间(实验中压缩与非压缩空间占用相差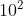 量级)。
量级)。
(二)深度学习中的训练集、验证集与测试集[22]
训练集,即用于模型拟合的数据样本,用来调试网络中的参数;
验证集,参与超参数设置训练,用于确定网络结构以及调整模型的超参数。与训练集LOSS对比可查看模型训练是否过拟合以及模型拟合好坏趋势(作为调整超参数、特征选择等算法相关的选择依据);
测试集,用来评估最终模型的泛化能力。
实验总结:在一些深度学习文献中,我们可以看到部分学者仅划分了训练集和测试集进行训练、预测。那么,我就产生了“验证集的作用是什么?”和“什么情况下,可以直接划分训练集与测试集?”两个问题。通过查阅资料,我了解到1)验证集不是必须的,如果不需要调整超参数,那么就可以不使用验证集;2)使用验证集的好处,一是可以通过LOSS曲线及时发现模型或者超参数设置问题从而及时终止训练,重新调参或调整模型,而不需要等到训练结束。二是验证模型的泛化能力,考虑模型过拟合和欠拟合问题。
(三)语义分割输入与输出[26][27]


U-Net流程图中,我们可以明显看出输入图像的大小为572×572,而输出分割图片的大小为388×388。从第一思维来说,我们认为的语义分割结果应该是对输入图像的每个像素都给予一个标签,所以输出的语义分割结果也应该为572×572大小。
U-Net流程图中,我们可以发现输入图像的channel为1,输出的语义分割图像的channel为2,这是为什么呢?前者是因为医学影像大多数为灰度图(即图像的RGB波段存储数据一致),后者是因为语义分割任务最后的输出特征图是一个三维结构,大小与原图相近,通道数就是类别数(此时仅是获得了特征图,后续还应各Channel对应像元进行argmax操作得到一幅分割图),而原始U-Net医学细胞分割模型便是为了分割出细胞边界和细胞内部两部分。
实验总结:为了使得本次实验语义分割结果输出大小与输入图片大小一致,我将通过卷积Padding使得同一层U形特征层长宽一致,最大池化缩小与转置卷积放大程度一致,从而使得语义分割结果图片大小为256×256。
本次实验,我们的目的是为了提取出耕地与非耕地(属于二分类任务),且输入的图像为RGB三通道。因此,我将设计网络输入Channel为3,输出Channel为2。
(四)损失函数的选择(非常重要)[28][29][18][36][42][43][44]
损失函数能够告诉我们当前的分类器有多好。对于数据集中的N个样本
,xi为图像,yi为标签数据,数据集总的损失是所有样本损失的平均值。
对于图像分类而言,基于神经网络的方法中,SVM分类器(SVM损失-hinge loss)和Softmax分类器(多类别逻辑回归-cross-entropy loss)是较为基础的分类器。我们通常会输入一幅图片经过神经网络前向计算出一行N列(N为分类类别数)的分数向量,然后基于特定的分类器计算损失(此处交叉熵损失最为常用-Softmax(cross-entropy loss)),然后选择合适的梯度下降算法来优化损失,计算梯度来后向传播修正权重W。
一个总共 C 类的多分类问题,我们希望测试样本的分类结果可以以一个 C 维概率向量的形式给出,其中该概率向量的第 i 个元素为测试样本属于第 i 类的概率。为了满足这一要求,在实际的分类模型中,标准的策略是让模型计算测试样本属于各类的分数( score ),由得分高低来判断样本的类别归属,得分越高的类可能性越大。这样,模型自然的为每一个测试样本生成一个由分数组成的 C 维向量。分数事实上代表了测试样本属于各类的可能性,因此也就是非归一化的概率。[42]为了得到我们最终所希望的概率,研究者提出了 softmax 函数。该函数将非归一化的 C 维向量映射为归一化的 C 维向量,以便将分数向量调整为概率向量,即nn.Softmax()。[45]
此处,重点分析nn.CrossEntropyLoss()和nn.BCEWithLogitsLoss():
【43】nn.CrossEntropyLoss()——网络输出结果是(1,N,H,W)
详见参考资料[43]。
【44】nn.BCEWithLogitsLoss()——网络输出结果是(1,1,H,W)
该损失函数的语义分割思想与本实验所使用的nn.CrossEntropyLoss()的思想具有一定差异。BCEWithLogitsLoss其实就是Sigmoid+BCELoss。nn.Sigmoid()函数将输入数据压缩到[0,1]区间,然后基于标签数据下运用BCELoss计算损失值。
该方法主要思想是基于输出的单通道图像利用阈值分割分割像素类别,具体介绍与案例详见参考资料[23][44]。

实验总结:基于图像分类的启发,我认为语义分割从一定程度上属于像素级的“图像分类”。在图像分类中,若不进行Softmax归一化,那么网络结果输出的一般为一行N列非归一化概率。而对于语义分割而言,一个像素代表一个类别,那么迁移图像分类思想,实质上我们可以输出一个(N,H,W)的特征矩阵,每个二维矩阵看似一个分类,那就回到了图像分类的处理思想。本实验基于上述操作,对类别输出特征图进行通道对应像素的torch.argmax()取最大值通道索引后形成语义分割标签图像,后对应类别颜色映射表生成最终语义分割图像。
(五)标签图像的标记设置
基于图像分类任务的经验,我们知道图像分类任务Softmax分类器运行后会对每一种类别给定一个[0,1]区间的分类概率,而我们需要取最大概率的分类作为预测结果。此时,我们通常会将评分向量中的最大分类概率对应的索引作为此类的标签,以方便计算准确率,同时也满足常用"背景+分类类别"的标签向量[0,1,2,3...n],其中n为分类数。
对于标签设置,若网络输出通道没有255,而直接使用损失函数,Pytorch可能存在计算LOSS时criterion函数的“Target 255 is out of bounds”报错。其原因在于Pytorch的损失函数的损失计算过程,它将基于标签数据里的数值取输出特征图索引进行匹配损失计算。
实验总结:本次实验,我的数据集对应标签中的耕地类为255。为了符合Pytorch损失函数的计算方式,我在标签数据读入的时候,将255像元均设置为1。
(六)语义分割评价指标[30][27][31]
IOU(Intersection Over Union)是一种用于衡量目标检测或分割模型性能的指标,而准确率(Accuracy)、召回率(Recall)和精确率(Precision)等则是广泛应用于机器学习分类任务中的指标。此处,其实可以联系混淆矩阵的用户精度、生产精度等进行对比。
召回率与精确率二者需要根据实际情况进行权衡,二者不可得兼。
TP:True Positive,分类器预测结果为正样本,实际也为正样本,即正样本被正确识别的数量。
FP:False Positive,分类器预测结果为正样本,实际为负样本,即误报的负样本数量。
TN:True Negative,分类器预测结果为负样本,实际为负样本,即负样本被正确识别的数量。
FN:False Negative,分类器预测结果为负样本,实际为正样本,即漏报的正样本数量。
IOU:计算模型预测结果和真实标签之间的交集面积与并集面积之比;
miou:各个类别IOU的平均值;
准确率:正确预测出来的数量 / 所有的样本数量,(TP+TN)/样本总数。
召回率(提升召回率是为了不漏报):TP/(TP+FN)
精确率(提升精确率是为了不错报):TP/(TP+FP)
注意事项:参考资料[27]中对TP\TN\FN\FP的解释存在些许问题,具体解释详见参考资料[31]。
(七)ImageFolder用法(与本次语义分割实验无关,仅作学习记录)
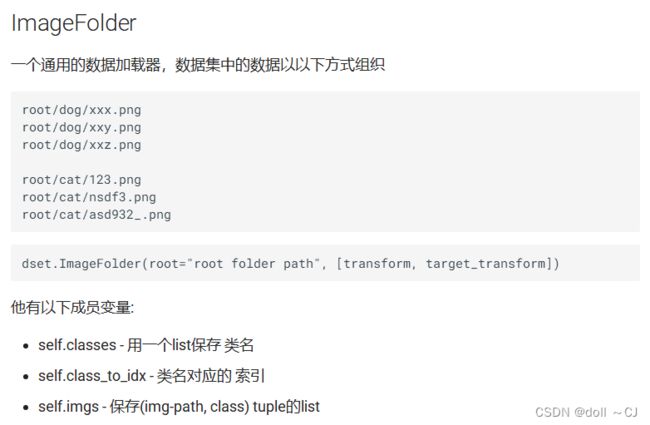


实验总结:ImageFolder函数可以使得图像分类数据读取更为简便,它能够根据一定的文件夹结构自动识别出训练图片的类名,然后将类名的索引号与输入图像组成(input,target)元组。
(八)BatchNorm和Dropout在训练阶段和测试阶段的区别—net.train()和net.eval()[39][40][16]
net.train(mode=True)—将module设置training mode,启用Dropout和BatchNormalization;
net.eval(mode=True)—将module设置evaluation mode,启用Dropout和BatchNormalization;
上述二者,仅在module中含有nn.Dropout()和nn.BatchNorm()才会产生区别。


实验总结:训练时我们输入针对的是mini_Batch,而测试时我们针对的是单张图片。为了保证在测试时网络BatchNorm不再次计算从而影响到测试结果,我们利用net.eval()禁用,从而完全使用训练出来的模型参数进行计算预测。
(九)CPU计算和GPU计算 [41]
中央处理器(Central Processing Unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。核数更少,但每个核都很快,能力更强,适合用于连续任务。
图形处理器(Graphic Processing Unit)专用于执行在计算机上渲染图象、视频和动画所需的密集计算。核数更多,但每个核都慢得多,非常适合简单的并行任务。
全球的深度学习研究人员和框架开发人员都依赖于cuDNN来实现高性能GPU加速。它使他们可以专注于训练神经网络和开发软件应用程序,而不必花时间在底层GPU性能调整上。
net.cpu(device_id=None)—将所有的模型参数(parameters)和buffers复制到CPU;
net.cuda(device_id=None)—将所有的模型参数(parameters)和buffers复制到GPU。
实验总结:Tensor可以利用Tensor_instance.numpy()转换为NumPy格式,NumPy可以利用NumPy_instance.from_numpy()转换为Tensor格式。Tensor和NumPy中的数组共享相同的内存。在GPU运算的数据需要转换到CPU中再进行数据类型转换。
(十)标签图片与预测图片的对比显示问题[48]
opencv的图片读取方式通常是BGR,同时利用plt.imshow()函数显示灰度图像其色彩并不是黑白颜色,这则涉及到通道颜色显示的原理,具体可见参考资料[48]。如果想让灰度图显示则在plt.imshow()添加参数cmap=“gray”。
参考资料:
[1] Pytorch 搭建自己的Unet语义分割平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
[2]图像分割UNet硬核讲解(带你手撸unet代码)_哔哩哔哩_bilibili
[3](数据增强包)GitHub - albumentations-team/albumentations: Fast image augmentation library and an easy-to-use wrapper around other libraries. Documentation: https://albumentations.ai/docs/ Paper about the library: https://www.mdpi.com/2078-2489/11/2/125
[4]Aston Zhang,Zachary C.Lipton,Mu li,and Alexander J.Smola.《动手学深度学习》
[5]李沐 - 知乎(深度学习论文分析/带学)
[6]https://albumentations.ai/docs/examples/example_kaggle_salt/(具体图像正则化方法)
[7]数据增强(Data Augmentation) - 知乎
[8]语义分割_哔哩哔哩_bilibili(李沐老师教学)
[9]转置卷积_哔哩哔哩_bilibili
[10]课程安排 - 动手学深度学习课程
[11]跟李沐学AI的个人空间-跟李沐学AI个人主页-哔哩哔哩视频
[12]U-Net网络结构讲解(语义分割)_哔哩哔哩_bilibili
[13]2020 CCF BDCI 地块分割Top1方案 & 语义分割trick整理 - 知乎
[14]实战 | 基于SegNet和U-Net的遥感图像语义分割 - 知乎
[15]Welcome to PyTorch Tutorials — PyTorch Tutorials 2.0.0+cu117 documentation
[16]PyTorch 中文文档
[17]UNet 浅析_跳层连接_晓野豬的博客-CSDN博客
[18]Pytorch 深度学习实战教程(三):UNet模型训练,深度解析! - 腾讯云开发者社区-腾讯云
[19]PyTorch使用预训练模型进行模型加载 - 知乎
[20]PyTorch的torch.cat_my-GRIT的博客-CSDN博客
[21]PyTorch碎片:F.pad的图文透彻理解_柚有所思的博客-CSDN博客
[22]深度学习中的【训练集】、【验证集】、【测试集】 - 知乎
[23]Pytorch深度学习实战教程(二):UNet语义分割网络
[24]https://arxiv.org/pdf/1505.04597.pdf(U-Net论文原文)
[25]数据集图片RGB颜色通道乱序实现数据集扩充_合成颜色数据集代码_Satellite_AI的博客-CSDN博客
[26]语义分割全卷机网络-FCN_fcn的输出_Tc.小浩的博客-CSDN博客
[27]什么是语义分割?原理+实现过程?_语义分割原理_AI算法小白的博客-CSDN博客
[28]常用的损失函数_夕阳之后的黑夜的博客-CSDN博客
[29]交叉熵损失函数原理详解_Cigar丶的博客-CSDN博客
[30]通俗解释机器学习中的召回率、精确率、准确率 - 知乎
[31]通俗理解TP、FP、TN、FN - 知乎
[32]【numpy】argmax参数辨析(axis=0,axis=1,axis=-1)_numpy.argmax(axis=-1)_胡侃有料的博客-CSDN博客
[33]pytorch:深入理解 reshape(), view(), transpose(), permute() 函数_pytorch的reshape_听 风、的博客-CSDN博客
[34]UNet训练及代码实现_哔哩哔哩_bilibili
[35]PyTorch模型训练梯度反向传播遇到的几个报错解决办法_loss.requires_grad_(true)_森尼嫩豆腐的博客-CSDN博客
[36]语义分割结果图_语义分割输出_翰墨大人的博客-CSDN博客
[37][轻笔记]Pytorch语义分割输出转换为图像显示
[38]【语义分割】1、语义分割超详细介绍_呆呆的猫的博客-CSDN博客
[39]Torch net.train 和 net.eval的使用 - 知乎
[40]Pytorch 中net.train() 和 net.eval()的作用和如何使用?_.train()_一枚小菜程序员的博客-CSDN博客
[41]Tensor 和 NumPy 相互转换_tensor转numpy_xzw96的博客-CSDN博客
[42]原理 |Softmax和CrossEntropy Loss - 知乎
[43]pytorch语义分割中CrossEntropyLoss()损失函数的理解与分析_北斗星辰001的博客-CSDN博客
[44]聊聊关于图像分割的损失函数 - BCEWithLogitsLoss_Henry_zhangs的博客-CSDN博客
[45]【基础知识】pytorch:nn.Softmax()_nefetaria的博客-CSDN博客
[46]MIoU(均交并比)的计算_晓野豬的博客-CSDN博客
[47]Python3 对列表按元组指定列进行排序_Xiao布_unknown的博客-CSDN博客
[48]plt.imshow()显示灰度图异常的问题及通道概念解析_plt.imshow 灰度图_GallonBeingBetter的博客-CSDN博客
JPEG压缩存储方法
音视频入门(四)-JPEG压缩算法原理_jpeg压缩原理_Chicken_Bird的博客-CSDN博客
Python内置函数一览表
Python内置函数一览表
Pytorch函数运行原理可视化
PyTorch DataLoader工作原理可视化 - 知乎
现有图像存储格式详述
BMP、GIF、TIFF、PNG、JPG和SVG格式图像的特点_bmp tiff_不脱发的程序猿的博客-CSDN博客
语义分割交互式体验Demo(lang-seg)——拓展
GitHub - isl-org/lang-seg: Language-Driven Semantic Segmentation(开源代码)
https://arxiv.org/abs/2201.03546(论文)
满满干货的技术开发社区(腾讯云开发者社区)
全部文章 - 专栏 - 腾讯云开发者社区-腾讯云