基于条件随机场(CRF)对中文案件语料进行命名实体识别(NER)

环境要求
numpy==1.15.4
python-crfsuite==0.9.6
scikit-learn==0.20.1
scipy==1.1.0
six==1.11.0
sklearn==0.0
sklearn-crfsuite==0.3.6
tabulate==0.8.2
tqdm==4.28.1
## 文件组织
- **corpus.py**
语料类
- **model.py**
模型类
- **utils.py**
工具函数、映射、配置
- **data**
语料
- **requirements.txt**
依赖
## 运行main
```
pip install -r requireme
nts.txt
python main.py
```
即可
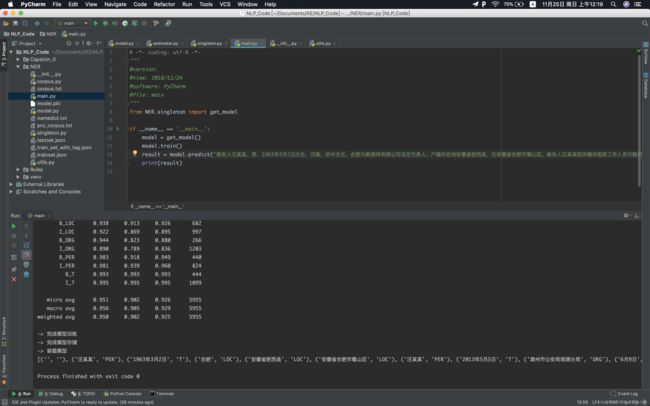
## 效果
中间结果
预测结果
**corpus.py** 语料类
# -*- coding: utf-8 -*-
"""
@version:
@time: 2018/11/24
@software: PyCharm
@file: Corpus
"""
import codecs
import re
from utils import q_2_b, tag_mean_map
__corpus = None
class Corpus(object):
def __init__(self):
self.origin_corpus = self.read_corpus("./data/corpus.txt")#读取语料库
self.pro_corpus = self.pre_process(self.origin_corpus)
self.save_pro_corpus(self.pro_corpus)
self.word_seq = []#文本列表
self.pos_seq = []#POS(Part-of-Speech)标注
self.tag_seq = []#标签
def read_corpus(self, path):#读取训练集数据
with open(path, encoding='utf-8') as f:
corpus = f.readlines()
print("-> 完成训练集{0}的读入".format(path))
return corpus
def save_pro_corpus(self, pro_corpus):#保存写入预处理数据
with codecs.open("./data/pro_corpus.txt", 'w', encoding='utf-8') as f:#w:打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
for line in pro_corpus:
f.write(line)#写入文件
f.write("\n")
print("-> 保存预处理数据")
def pre_process(self, origin_corpus):#数据预处理
pro_corpus = []#先创建一个list列表
for line in origin_corpus:
words = q_2_b(line.strip("")).split(' ')#移除字符串头尾得”“,然后split进行分割
pro_words = self.process_big_seq(words)
pro_words = self.process_nr(pro_words)
pro_words = self.process_t(pro_words)
pro_corpus.append(' '.join(pro_words[1:]))#从第二个开始添加,每个成员符号用空格隔开
print("-> 完成数据预处理")
return pro_corpus
def process_nr(self, words):#对nr进行处理
pro_words = []
index = 0
while True:
word = words[index] if index < len(words) else ''
if '/nr' in word:#word列表是现在的单词,words是整个句子列表
next_index = index + 1
#如果说在句子中向下检索单词长度是小于总句子长度而且是'/nr'的时候
if next_index < len(words) and '/nr' in words[next_index]:
#把所有的'/nr'全都替换掉然后把检索的整个句子中的现在的下一个单词压入
pro_words.append(word.replace('/nr', '') + words[next_index])
index = next_index
else:
pro_words.append(word)
elif word:
pro_words.append(word)
else:
break
index += 1
return pro_words
def process_t(self, words):#对_t进行处理
pro_words = []
index = 0
temp = ''
while True:
word = words[index] if index < len(words) else ''
if '/t' in word:
temp = temp.replace('/t', '') + word
elif temp:
pro_words.append(temp)
pro_words.append(word)
temp = ''
elif word:
pro_words.append(word)
else:
break
index += 1
return pro_words
def process_big_seq(self, words):#数据序列发生器
pro_words = []
index = 0
temp = ''
while True:
word = words[index] if index < len(words) else ''
if '[' in word:
temp += re.sub(pattern='/[a-zA-Z]*', repl='', string=word.replace('[', ''))
elif ']' in word:
w = word.split(']')
temp += re.sub(pattern='/[a-zA-Z]*', repl='', string=w[0])
pro_words.append(temp + '/' + w[1])
temp = ''
elif temp:
temp += re.sub(pattern='/[a-zA-Z]*', repl='', string=word)
elif word:
pro_words.append(word)
else:
break
index += 1
return pro_words
def initialize(self):#初始化
pro_corpus = self.read_corpus("./data/pro_corpus.txt")
corpus_list = [line.strip().split(' ') for line in pro_corpus if line.strip()]
del pro_corpus
self.init_sequence(corpus_list)
def init_sequence(self, corpus_list):#字序列、词性序列、标记序列的初始化
words_seq = [[word.split('/')[0] for word in words] for words in corpus_list]
pos_seq = [[word.split('/')[1] for word in words] for words in corpus_list]
tag_seq = [[self.pos_2_tag(p) for p in pos] for pos in pos_seq]
self.pos_seq = [[[pos_seq[index][i] for _ in range(len(words_seq[index][i]))]
for i in range(len(pos_seq[index]))] for index in range(len(pos_seq))]
self.tag_seq = [[[self.perform_tag(tag_seq[index][i], w) for w in range(len(words_seq[index][i]))]
for i in range(len(tag_seq[index]))] for index in range(len(tag_seq))]
self.pos_seq = [['un'] + [self.perform_pos(p) for pos in pos_seq for p in pos] + ['un'] for pos_seq in
self.pos_seq]
self.tag_seq = [[t for tag in tag_seq for t in tag] for tag_seq in self.tag_seq]
self.word_seq = [[''] + [w for word in word_seq for w in word] + [''] for word_seq in words_seq]
print("-> 完成字序列、词性序列、标记序列的初始化")
def pos_2_tag(self, pos):#对"nr", "PER"进行处理
return tag_mean_map[pos] if pos in tag_mean_map else '0'
def perform_tag(self, tag, index):#进行标签化BIO处理
if index == 0 and tag != '0':
return 'B_{}'.format(tag)
elif tag != '0':
return 'I_{}'.format(tag)
else:
return tag
def perform_pos(self, pos):
if pos in tag_mean_map.keys() and pos != 't':
return 'n'
else:
return pos
def generator(self):#根据特征模板,提取特征
print("-> 以 {0} 的窗口大小,分割字序列".format(3))
word_grams = [self.segment_by_window(word_list) for word_list in self.word_seq]
print("-> 根据特征模板,提取特征")
features = self.feature_extractor(word_grams)
return features, self.tag_seq
def segment_by_window(self, word_list=None, window_size=3):#窗口部分
all_posible_words = []
begin, end = 0, window_size
for _ in range(1, len(word_list)):
if end > len(word_list):
break
all_posible_words.append(word_list[begin:end])
begin += 1
end += 1
return all_posible_words
def feature_extractor(self, word_grams):#特征提取器
features, features_list = [], []
for index in range(len(word_grams)):
for i in range(len(word_grams[index])):#一个字一个字得进行分析
word_gram = word_grams[index][i]
feature = {
"w-1": word_gram[0],
"w": word_gram[1],
"w+1": word_gram[2],
"w-1:w": word_gram[0] + word_gram[1],
"w:w+1": word_gram[1] + word_gram[2],
"bias": 1.0
}
features.append(feature)
features_list.append(features)
features = []
return features_list
def get_corpus():#获取语料库
global __corpus
if not __corpus:
__corpus = Corpus()
return __corpus
if __name__ == '__main__':
c = Corpus()
c.initialize()
line.strip().split(‘,‘)含义:
strip()用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
split(‘ ’): 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串。eg:
words = q_2_b(line.strip("")).split(' ')
#移除字符串头尾得”“,然后split进行分割
Python中的 .join()用法
这个函数展开来写应该是str.join(item),join函数是一个字符串操作函数
str表示字符串(字符),item表示一个成员,注意括号里必须只能有一个成员,比如','.join('a','b')这种写法是行不通的
举个例子:
','.join('abc')上面代码的含义是“将字符串abc中的每个成员以字符','分隔开再拼接成一个字符串”,输出结果为:
'a,b,c'
python字符串替换replace函数
replace(old, new, count)
- old,旧字符或字符串
- new,新字符或字符串
- count,最大替换数量,从起始位置开始计数,默认替换所有
- 注意:replace函数替换字符串,不影响原字符串
python 中del 的用法
python中的del用法比较特殊,新手学习往往产生误解,弄清del的用法,可以帮助深入理解python的内存方面的问题。
python的del不同于C的free和C++的delete。
由于python都是引用,而python有GC机制,所以,del语句作用在变量上,而不是数据对象上。
if __name__=='__main__': a=1 # 对象 1 被 变量a引用,对象1的引用计数器为1 b=a # 对象1 被变量b引用,对象1的引用计数器加1 c=a #1对象1 被变量c引用,对象1的引用计数器加1 del a #删除变量a,解除a对1的引用 del b #删除变量b,解除b对1的引用 print(c) #最终变量c仍然引用1del删除的是变量,而不是数据。
另外。关于list。
if __name__=='__main__': li=[1,2,3,4,5] #列表本身不包含数据1,2,3,4,5,而是包含变量:li[0] li[1] li[2] li[3] li[4] first=li[0] #拷贝列表,也不会有数据对象的复制,而是创建新的变量引用 del li[0] print(li) #输出[2, 3, 4, 5] print(first) #输出 1
pyhton (for in if)用法
带有if语句
我们可以在
for语句后面跟上一个if判断语句,用于过滤掉那些不满足条件的结果项。例如,我想去除列表中所有的偶数项,保留奇数项,可以这么写:
>>> L = [1, 2, 3, 4, 5, 6] >>> L = [x for x in L if x % 2 != 0] >>> L [1, 3, 5]带有for嵌套
在复杂一点的列表推导式中,可以嵌套有多个
for语句。按照从左至右的顺序,分别是外层循环到内层循环。例如:
>>> [x + y for x in 'ab' for y in 'jk'] ['aj', 'ak', 'bj', 'bk'参考资料python 循环高级用法 [expression for x in X [if condition] for y in Y [if condition] ... for n in N [if condition] ]按照从左至右的顺序,分别是外层循环到内层循环 - bonelee - 博客园
[word.split('/')[0] for word in words]
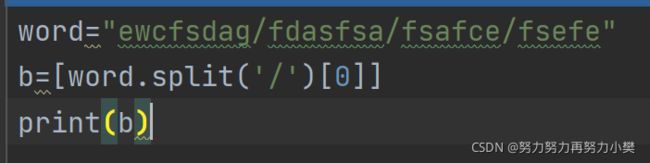
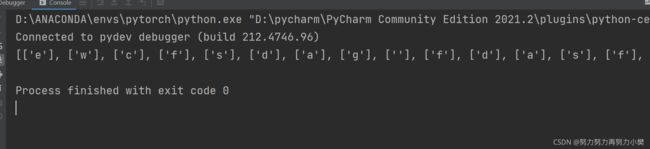
python中for _ in range () 中'_'的意思
以斐波那契数列为例
#求前20项的斐波那契数 a = 0 b = 1 for _ in range(20): (a, b) = (b, a + b) print(a, end=' ')其中’_’ 是一个循环标志,也可以用i,j 等其他字母代替,下面的循环中不会用到,起到的是循环此数的作用
就像C语言中for (int i ; i<100 ; i++){ 代码块; }其中的’i’在下面并不会用到,起到的只是控制循环此数的作用
python中global用法
Python中定义函数时,若想在函数内部对函数外的变量进行操作,就需要在函数内部声明其为global。
x = 1 def func(): x = 2 func() print(x)输出:1
在func函数中并未在x前面加global,所以func函数无法将x赋为2,无法改变x的值
例子2x = 1 def func(): global x x = 2 func() print(x)输出:2
加了global,则可以在函数内部对函数外的对象进行操作了,也可以改变它的值了例子3
global x x = 1 def func(): x = 2 func() print(x)输出:1
global需要在函数内部声明,若在函数外声明,则函数依然无法操作x
re.sub()用法的详细介绍
上面
re.sub(r'[A-Za-z]+', ' ', s)这句话则表示匹配多个连续的字母,并将多个连续的字母替换为一个' '号 。参考链接:re.sub()用法的详细介绍_jack的博客-CSDN博客
**utils.py** 工具函数、映射、配置
# -*- coding: utf-8 -*-
"""
@version:
@time: 2018/11/24
@software: PyCharm
@file: Corpus
"""
import re
# 定义测试集section名的映射
document = "文书"
_section_map = (
("head", "首部"),
("party_info", "当事人信息"),
("case_info", "案件基本情况"),
("judge_principle", "裁判原则"),
("judgment", "判决结果"),
("ending", "尾部"),
("apply_record", "上诉记录")
)
section_map = dict(_section_map)
# 定义训练集目标实体名映射
entity = "实体"
_entity_map = (
("BIR", "出生信息"),
("NAT", "名族"),
("LOC", "居住地"),
("SEX", "性别"),
("HJ", "户籍"),
("EDU", "文化背景"),
("JOB", "职务"),
("ORG", "单位"),
("POL", "政治面貌"),
("PER", "被告人姓名"),
("T", "犯罪时间"),
("MON", "涉案金额")
)
entity_map = dict(_entity_map)
_tag_mean_map = (
("nr", "PER"),
("ns", "LOC"),
("nt", "ORG"),
("t", "T")
)
tag_mean_map = dict(_tag_mean_map)
_model_config = (
("algorithm", "lbfgs"),
("c1", "0.1"),
("c2", "0.1"),
("max_iterations", 100),
("model_path", "{}.pkl")
)
model_config = dict(_model_config)
_test_config = (#配置文件
("test_path", "./data/{}.json"),
("output_path", "{}.json")
)
test_config = dict(_test_config)
_regex_map = (#正则表达map
("edu", "文化"),
("pol", "中共党员"),
("nat", "族"),
("curator", "检察院"),
("money", "元")
)
regex_map = dict(_regex_map)
regex_pattern = "[0-9]+(.[0-9]+)?([百千万]*)(余?)元"
def expand_list(nested_list):
"""
将高维list转换为一维list
"""
for item in nested_list:
if isinstance(item, list):
for sub_item in expand_list(item):
yield sub_item
else:
yield item
def b_2_q(b_str):
"""
半角转全角
"""
q_str = ""
for uchar in b_str:
inside_code = ord(uchar)
if inside_code == 32:
inside_code = 12288
elif 126 >= inside_code >= 32:
inside_code += 65248
q_str += chr(inside_code)
return q_str
def q_2_b(q_str):
"""
全角转半角
"""
b_str = ""
for uchar in q_str:
inside_code = ord(uchar)
if inside_code == 12288: # 全角空格
inside_code = 32
elif 65374 >= inside_code >= 65281:
inside_code -= 65248
b_str += chr(inside_code)
return b_str
def deal_with_entity(entity_list, sentence, flag):
obj = dict()
if flag == 0:
for index in range(len(entity_list)):
if entity_list[index][1] == "PER":
obj[entity_map["PER"]] = entity_list[index][0]
if entity_list[index][1] == "LOC":
if obj.get(entity_map["LOC"], None) is None:
obj[entity_map["LOC"]] = entity_list[index][0]
else:
obj[entity_map["HJ"]] = entity_list[index][0]
if entity_list[index][1] == 'T':
obj[entity_map['BIR']] = entity_list[index][0]
if entity_list[index][1] == 'ORG' and regex_map["curator"] not in entity_list[index][0]:
obj[entity_map['ORG']] = entity_list[index][0]
sentence = sentence.replace("。", ",")
sentence_list = sentence.split(",")
for index in range(len(sentence_list)):
if regex_map["edu"] in sentence_list[index]:
if obj.get(entity_map["EDU"], None) is None:
obj[entity_map["EDU"]] = sentence_list[index]
if regex_map["pol"] in sentence_list[index]:
if obj.get(entity_map["POL"], None) is None:
obj[entity_map["POL"]] = sentence_list[index]
if regex_map["nat"] in sentence_list[index]:
if obj.get(entity_map["NAT"], None) is None:
obj[entity_map["NAT"]] = sentence_list[index]
if flag == 1:
for index in range(len(entity_list)):
if entity_list[index][1] == 'T':
obj[entity_map['T']] = entity_list[index][0]
sentence = sentence.replace("。", ",")
sentence_list = sentence.split(",")
for index in range(len(sentence_list)):
if re.search(regex_pattern, sentence_list[index]) is not None:
obj[entity_map['MON']] = re.search(regex_pattern, sentence_list[index]).group()
return obj
Python中isinstance用法
Isinstance的用法是用来判断一个量是否是相应的类型,接受的参数一个是对象加一种类型。示范代码如下:
a = 1
print(isinstance(a,int))
print(isinstance(a,float))
返回 True False
yield关键词
def fy(count): c=count while c>0: c=c-1 yield c f=fy(4) print(f.__next__()) print(f.__next__()) print(f.__next__()) print(f.__next__())上面的这个例子,让人感觉莫名其妙:fy表面上看起来是一个函数,f不过是一个函数对象而已,怎么会突然冒出一个成员函数__next__出来?
这一切都是因为fy中的一句yield c,原本仅仅是一个函数fy,由于yield的存在,变得完全不同。yield在这里起到的作用就是把一个普通的函数变成了一个生成器。所谓生成器,简单理解就是:迭代器+协程。也就是说yield有两重作用。
yield的第一重作用是把一个普通函数变成了一个迭代器。既然是迭代器,就得具有__next__函数,所以yield会给这个生成器加一个__next__函数,而这个__next__函数的具体实现,就相对于原来的函数体。我们先把fy函数变成一个迭代器,伪代码如下:
class fy_generator(object): def __init__(self,count): self.count=count def __iter__(self): return self def __next__(self): c=self.count while c>0: c=c-1 yield c这个迭代器的__next__函数中,仍然具有yield这个关键词,因为它已经把一个普通函数变成了一个迭代器,所以此时的yield将只会具有第二层作用,把__next__函数变成一个协程。yield的第二层作用,具体描述如下:
1 当__next__函数被调用,执行到yield时,首先相对于return c。
2 但是yield c又不是完全等价于return c,否则函数就退出了。所以,yield的第2个功能相对于保存了当时运行的上下文,把函数挂起。
3 既然把函数挂起,就相对于该协程让出程序执行权(让出上下文,由另外的协程来运行)。
4 当这个__next__函数再次被调用,它是从当初挂起的地方继续执行,直到再次执行yield c那句函数,然后又开始从第1点开始循环。
5 __next__函数可能这样一直循环下去,也可能在某种情况下没有执行到yield c,就函数退出了,那么此时__next__函数会抛出一个异常:raise StopIteration。
综上,关于yield两重作用的描述,重新解释一下所举的例子,如下表:
Neutron使用yield关键词编程,实际上还是属于用户(编程者/应用程序)自己对协程进行调度(函数挂起,让渡给别的函数执行)。
原文链接:Python中yield分析_实践求真知-CSDN博客_python yield

将高维list转换为一维list
def list_app(old_list, new_list = list()): """#isinstance去判断遍历的l是不是还是一个list如果还是list,用递归继续反复遍历""" for l in old_list: if isinstance(l, list): list_app(l) # 调用递归 else: # 如果不是,把l添加进一个新的list new_list.append(l) return new_list本案例代码中
def expand_list(nested_list): """ 将高维list转换为一维list """ for item in nested_list: if isinstance(item, list): for sub_item in expand_list(item): yield sub_item else: yield item
python 中的ord()函数和chr()函数
需要对字符进行转换时使用 其中ord函数可以将字符转化为你所需要的ASCII码,chr函数可以将0-255中的任一整数转化为你所需要的字符。
通过这样的转化 你可以方便的完成字符与数字之间的转换操作,更好使用for循环以及if判断等常用操作。
示例代码如下:
print(ord("a")) print(ord("b")) print(ord("A")) print(ord("B")) print(chr(97)) print(chr(98))运行结果为:
97
98
65
66
a
b
python实现全角半角的相互转换
转换说明
全角半角转换说明
有规律(不含空格):全角字符unicode编码从65281~65374 (十六进制 0xFF01 ~ 0xFF5E)
半角字符unicode编码从33~126 (十六进制 0x21~ 0x7E)特例:
空格比较特殊,全角为 12288(0x3000),半角为 32(0x20)除空格外,全角/半角按unicode编码排序在顺序上是对应的(半角 + 0x7e= 全角),所以可以直接通过用+-法来处理非空格数据,对空格单独处理。
注:
1. 中文文字永远是全角,只有英文字母、数字键、符号键才有全角半角的概念,一个字母或数字占一个汉字的位置叫全角,占半个汉字的位置叫半角。
2. 引号在中英文、全半角情况下是不同的


Python字典-dict.get()的用法
dict_name.get(key, default = None) # key: 要设置默认值的Key # default: 要返回key的值,可以是任何值,如整形、字符串、列表、字典等 # return: 如果字典中key本来有值,那么返回的是字典中Key所对应的值,如果没有,那么返回“default”中的值。例子
dict = {'1': 1, '2': 2} print ("Value : %s" % dict.get('1')) print ("Value : %s" % dict.get('2')) print ("Value : %s" % dict.get('3', 0)) #输出 Value : 1 Value : 2 value : 0
Python3 re.search()方法
re.search()方法扫描整个字符串,并返回第一个成功的匹配。如果匹配失败,则返回None。
与re.match()方法不同,re.match()方法要求必须从字符串的开头进行匹配,如果字符串的开头不匹配,整个匹配就失败了;
re.search()并不要求必须从字符串的开头进行匹配,也就是说,正则表达式可以是字符串的一部分。
re.search(pattern, string, flags=0)
- pattern : 正则中的模式字符串。
- string : 要被查找替换的原始字符串。
- flags : 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
eg:
import re a = "123abc456" print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,返回整体 print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123 print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456正则表达式中的三组括号把匹配结果分成三组
- group() 同group(0)就是匹配正则表达式整体结果
- group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。
没有匹配成功的,re.search()返回None
**model.py** 模型类
# -*- coding: utf-8 -*-
"""
@version:
@time: 2018/11/24
@software: PyCharm
@file: Model
"""
import sklearn_crfsuite
import joblib
from sklearn_crfsuite import metrics
from corpus import get_corpus
from utils import model_config, q_2_b, deal_with_entity
class NerModel(object):
def __init__(self):
self.corpus = get_corpus()
self.corpus.initialize()
self.model = None
def initialize_model(self):#自己写一个初始化模型方法
algorithm = model_config.get("algorithm")
c1 = float(model_config.get("c1"))
c2 = float(model_config.get("c2"))
max_iterations = int(model_config.get("max_iterations"))
self.model = sklearn_crfsuite.CRF(algorithm=algorithm,#采用sklearn_crfsuite的方法训练模型
c1=c1,
c2=c2,
max_iterations=max_iterations,
all_possible_transitions=True)
print("-> 完成模型初始化")
def train(self):#训练模型
self.initialize_model()
x, y = self.corpus.generator()#提取的特征设置x,y
x_train, y_train = x[500:], y[500:]#划分训练集
x_fix, y_fix = x[:500], y[:500]
print("-> 开始训练模型")
self.model.fit(x_train, y_train)#调用模型训练
labels = list(self.model.classes_)
labels.remove('0')#把0标签移除,因为没啥用
y_predict = self.model.predict(x_fix)#根据训练的模型预测
print("-> 调整模型")
metrics.flat_f1_score(y_fix, y_predict, average='weighted', labels=labels)#评估
# sorted_labels = sorted(labels, key=lambda name: (name[1:], name[0]))
# print(metrics.flat_classification_report(y_fix, y_predict, labels=sorted_labels, digits=3))
print("-> 完成模型训练")
self.save_model()
def save_model(self, name="model"):#存储成为kpl文件
model_path = model_config.get("model_path").format(name)
joblib.dump(self.model, model_path)
print("-> 完成模型存储")
def predict(self, sentence, section_flag):
self.load_model()#个字符串
x = q_2_b(sentence)#转换全——》半角返回一
word_lists = [[''] + [c for c in x] + ['']]
word_grams = [self.corpus.segment_by_window(word_list) for word_list in word_lists]
features = self.corpus.feature_extractor(word_grams)
y_predict = self.model.predict(features)
entity = ''
entity_list = []
tag = ""
entity_tag = ["B_PER", "B_LOC", "B_ORG", "B_T", "I_LOC", "I_PER", "I_ORG", "I_T"]#实体标记
for index in range(len(y_predict[0])):
if y_predict[0][index] == '0':#检测那些预测出来啥都不是的东西
if index == 0:
continue
elif index > 0 and y_predict[0][index - 1] != '0' and x[index] == x[index - 1]:
tag = y_predict[0][index - 1][2:]
entity += x[index]
else:
if index == 0:
entity += x[index]#不是废物标签的话就安排到实体上
elif index > 0 and y_predict[0][index][-1] == y_predict[0][index - 1][-1]:
entity += x[index]
tag = y_predict[0][index][2:]
elif index > 0 and y_predict[0][index][-1] != y_predict[0][index - 1][-1]:
entity_list.append((entity, tag))
entity = ''
tag = ''
entity += x[index]
if len(entity_list) > 0 and entity_list[0][1] == '':
entity_list.pop(0)
obj = deal_with_entity(entity_list, x, section_flag)
return obj
def load_model(self, model_name="model"):
model_path = model_config.get("model_path").format(model_name)
joblib.load(model_path)
## 运行main
# -*- coding: utf-8 -*-
"""
@version:
@time: 2018/11/24
@software: PyCharm
@file: main
"""
import json
from singleton import get_model
from utils import test_config, document, entity, section_map
import codecs
if __name__ == '__main__':
model = get_model()
model.train()
with open(test_config.get("test_path").format("testset"), encoding='utf-8') as f:
content = f.read()
testset = json.loads(content)
entity_list = []
for obj in testset:
sentence_0 = obj.get(document, {}).get(section_map["party_info"])
if len(list(sentence_0.keys())) == 0:
sentence_0 = ""
elif len(list(sentence_0.keys())) == 1:
sentence_0 = obj.get(document, {}).get(section_map["party_info"])["0"]
else:
sentence_0 = obj.get(document, {}).get(section_map["party_info"])["1"]
sentence_1 = obj.get(document, {}).get(section_map["case_info"])
if len(list(sentence_1.keys())) == 0:
sentence_1 = ""
else:
sentence_1 = obj.get(document, {}).get(section_map["case_info"])["0"]
entity_0 = model.predict(sentence_0, 0)
entity_1 = model.predict(sentence_1, 1)
entity_obj = entity_0.copy()
entity_obj.update(entity_1)
print("--> ", entity_obj)
entity_list.append({entity: entity_obj})
with codecs.open(test_config.get("output_path").format("output"), 'w', encoding='utf-8') as f:
content = json.dumps(entity_list, indent=4, ensure_ascii=False)
f.write(content)
with open(...) as ...
open() close() with open(...) as ...
看以下示例就能了解 Python 的 open() 及 close() 函数。这边调用 read()方法可以一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示,具体使用参见下文。
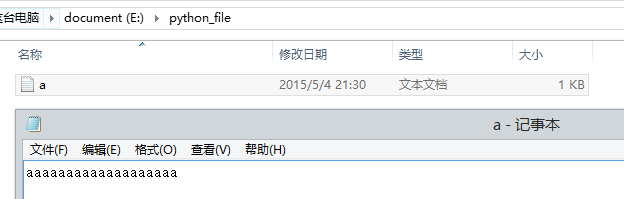
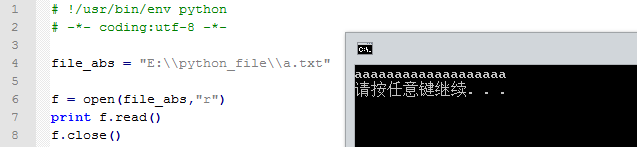
在 E 盘 python_file 文件夹下新建一 a.txt,输入随意,如下:
Python 操作 打开及关闭方式 如下:
注意 open() 之后 一定要 close()。但由于文件读写时都可能产生IOError,为了保证无论是否出错都能正确地关闭文件,我们用 try ... finally 来实现:
python 简化了改写法,即用 with open(...) as ... ; 建议之后文件读写都用该写法:
上面,你肯定注意到了参数 "r";该参数决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
参考文章:Python学习(九)IO 编程 —— 文件读写 - feesland - 博客园


codecs.open 和一般的open 区别~
总结一下:文件读尽量用codecs.open方法,一般不会出现编码的问题。至于用第二种方法有什么缺点,我没有研究过。。
open时,我们常常用:
>>> fr = open('test.txt','a')
>>> line1 = "我爱祖国"
>>> fr.write(line1)OK的~~!!!
但是,我们爬虫或者其他方式得到一些数据写入文件时会有编码不统一的问题,会常常:----decode-----> unicode -------encode------> output文件(gbk, utf-8...)
而使用codecs.open,可以轻松解决:
>>> import codecs
>>> fw = codecs.open('test1.txt','a','utf-8')
>>> fw.write(line2)