数据结构算法-哈希表技术点
引言
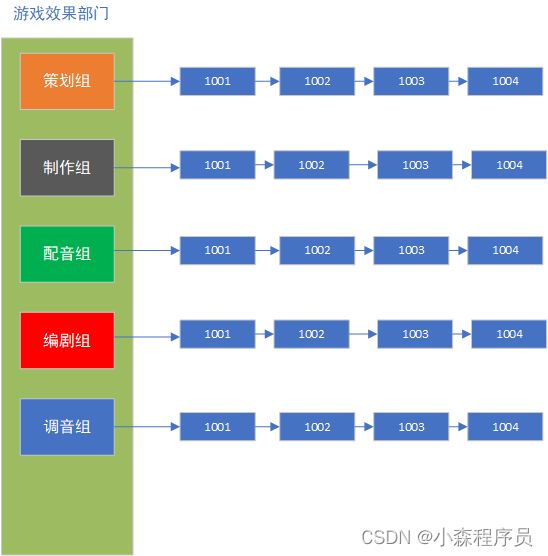
小森是一名 “ikun科技大制作创作者” 但有自己的团队 团队有20个人, 4个人为一组 ,一共有五组
分别为 策划组, 制作组, 配音组 ,编剧组, 调音组
为了方便就为每一个组的人就起了编号 以后方便"考察每个人是否工作"
可以看到效率大大的提高工作效率 ,当然真ikun 是真的为爱发电做出来:第一个 “科你太美PV”" 来致敬科比,
当然由于科技含量,最大化 最终真正出来"科技小森寻找科比"这个"游戏"
接下来 “科技小森寻找科比” 可能还得扩展到"鹰酱",并且在文化和科技反复碾压",让他们非常服
突然"科技小森工作室"宣布和"米啊游"合并 并且打造 “ikun文化” 让"ikun 文化名扬万朽"
在这不愧是"我森哥的格局最大"
从这里让人明白了一个关键点: 分散的重要性 就是非常好查找数据
肯定某个组有人因为薪资问题离开,这就恰到好处,无论是哪个组哪个人都会有编号
比如说"配音组里的1002 因为薪资问题.未能得到解决",那只好辞退Ta 并且赔偿一些费用
非常快速把ta从数字存储引擎把Ta的个人档案销毁
以下这种情景,我想一定能撬开阁下的嘴(,哈哈哈,笑不活了)
好了 该到打退骚针的时候 那么 这算不算是本文章的主题?
当然算,不然我怎么可能会说出来呢 (注意看 这个作者 有点骚 需打一针 ,退骚针就好了)![]()
哈希表原理
哈希表也称之为散列表
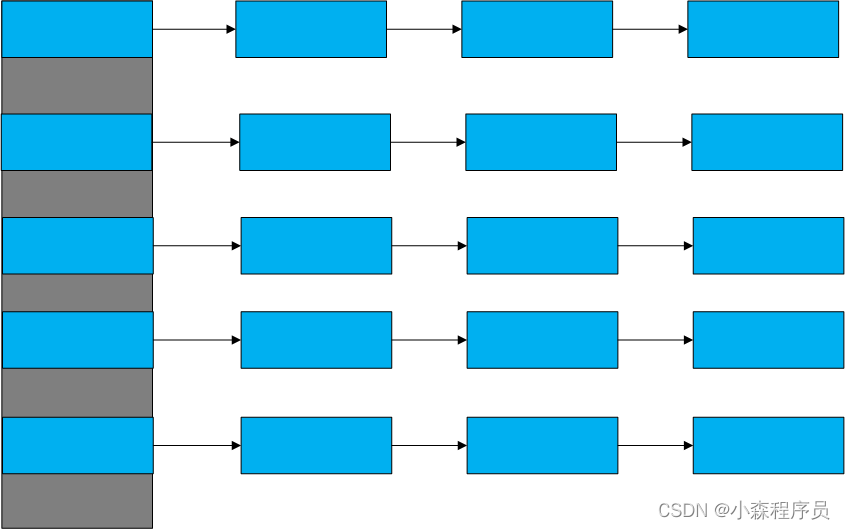
顺序表和链表的结合体 重温 一下 顺序表 的优点 :可控范围随机访问 链表的优点 :插入非常快 删除非常快
所以说链表和顺序表是互补的,
将二者合二为一 就变成 哈希表
可以看到,这就是一个指针数组 维护一大堆的链表
你需要知道的是: 数据如何插入和删除
难道顺着插入?
要是这样的话 还不如用链表
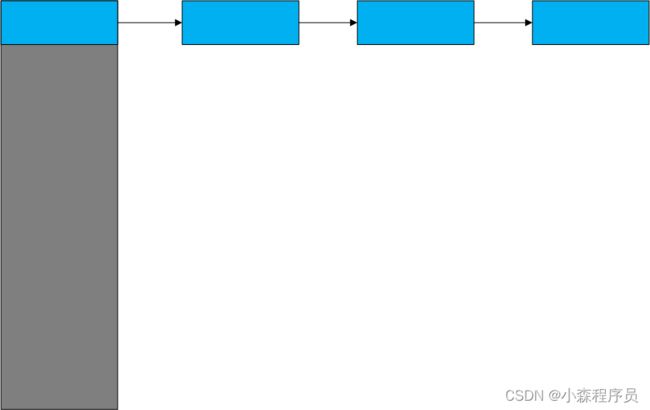
所以引用 “哈希函数”
“哈希函数”: 将数据转化为数字 映射到哈希表里的一种函数 也就是说 将数据转化为序号,最后插入到哈希表
哈希函数 可以多种多样 最多用的是取余
这对于通用的数据来采取的方式
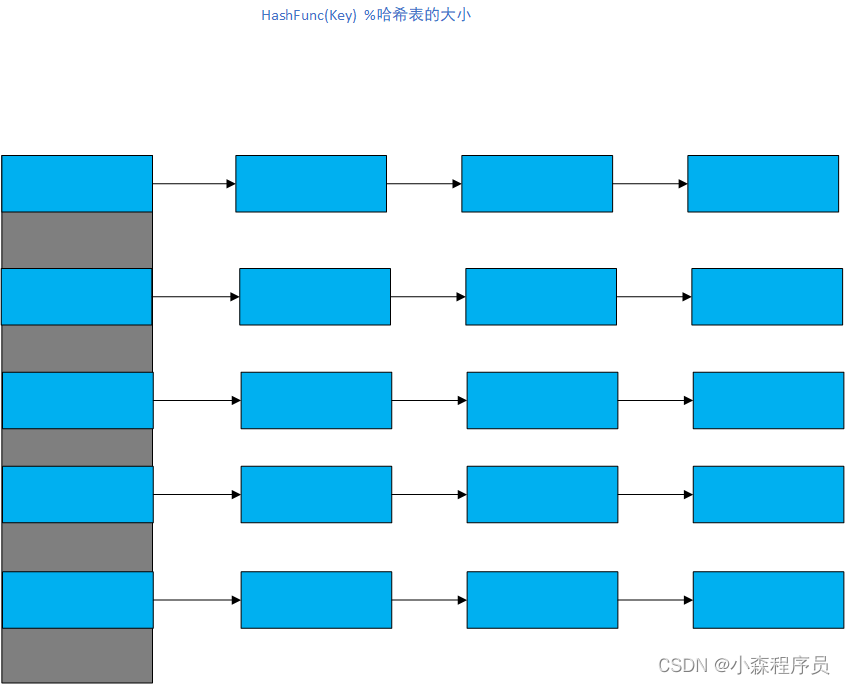
哈希桶:存放链表的数组 或者 顺序表的数组
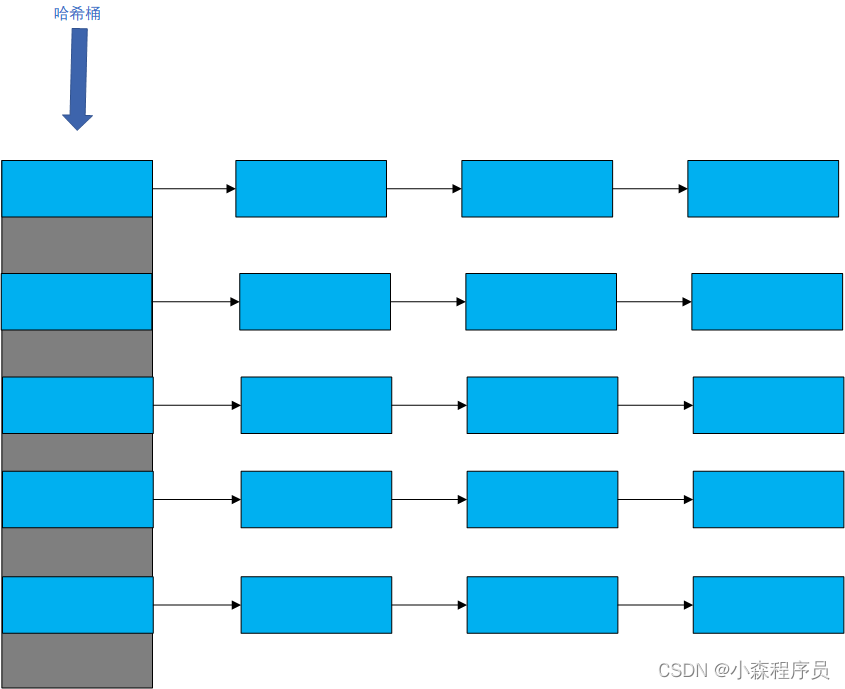
数据:采用键值(key/value)对的方式,键是哈希桶的编号 值是对应的数据,
这种非常神奇神奇到忽略不计去 哈哈
这种方式可能非常快速的找到对应的数据
通过上面的引言都知道 组就是键,数据是员工编号
我们的指纹识别就是用了这样的哈希表原理
音乐的听歌识曲也用了底层算法,所以现在知道为啥第一次办理身份证的时候就录入指纹 只要你一旦犯罪 人民警察会通过指纹快速查找到犯罪嫌疑人
哈希表算法实现
哈希链表定义
- 数据的定义
using Key = int;
using Value = use define;
//哈希数据
struct HashValue{
Key key;
Value value;
};
struct LinkNode{
HashValue MyHashValue;
LinkNode*Next;
};
//哈希表元素类型
using HashElement=LinkNode*;
哈希表定义
//默认桶空间容量
const int default_BucketSpaceSize = 16;
//哈希桶
using HashBucket = HashElement*;
//哈希表
struct HashTable{
HashBucket BucketSpace;//桶空间
size_t BucketSpaceSize;//桶空间大小
};
哈希链表创建算法
bool CreateHashTable(HashTable& HashTable, int BucketSpaceSize) {
BucketSpaceSize = BucketSpaceSize <= 0 ? default_BucketSpaceSize : (BucketSpaceSize > default_BucketSpaceSize ? BucketSpaceSize : default_BucketSpaceSize);
HashBucket BucketSpace = HashTable.BucketSpace = (HashElement*)malloc(sizeof(HashBucket) * (HashTable.BucketSpaceSize = BucketSpaceSize));
if (BucketSpace) {
for (size_t i = 0; i < BucketSpaceSize; i++) {
BucketSpace[i] = (HashElement)malloc(sizeof(HashElement));
*BucketSpace[i] = { };
}
return true;
}
return false;
}




哈希链表插入算法
首先 我们需要数据 那么得需要创建 按照我以前的骚操作文章,肯定得用创建哈希数据函数
创建哈希数据
//创建哈希数值类型
HashValue CreateHashValue(Key key, Value value){
return { key,value };
}
创建哈希数据 之后该插入了
bool HashTableInsert(HashTable& HashTable, HashValue &&Val){
HashBucket BucketSpace = HashTable.BucketSpace;
//查找哈希表里的key是否能找到
HashElement Find = HashTablFind(HashTable, Val.key);
if (Find){
RunNotFound(__func__, std::string("调用出现了问题! 问题的 \n") + "原因是" + std::to_string(Val.key) + "存在");
return false;
}
int HashIndex = Hash(Val, HashTable);
HashElement elementList = BucketSpace[HashIndex];
HashElement Newelement = CreateHashElement(Val, elementList->Next);
//采用前面插入
elementList->Next = Newelement;
return true;
}
首先 查找不用看 一开始有数据可查? 并没有吧 这里就跳过 不要在意这些细节
int HashIndex = Hash(Val, HashTable);
从哈希函数提取哈希表 的 索引
int Hash(const HashValue& hashValue, const HashTable& HashTable){
return hashValue.key % HashTable.BucketSpaceSize;
}
获取哈希表的元素(当然你们也知道,就不必要介绍这些骚操作)
HashElement elementList = BucketSpace[HashIndex];
你们都懂 就没必要可说的
HashElement Newelement = CreateHashElement(Val, elementList->Next);
//声明 Next默认是空指针
static HashElement CreateHashElement(HashValue& val, LinkNode* Next = nullptr);
static HashElement CreateHashElement(HashValue& val, LinkNode*Next){
HashElement Element = (LinkNode*)malloc(sizeof(LinkNode));
if (Element){
*Element = { val ,Next };
}
else{
std::cout << (std::string(__func__) + "调用失败! 原因是分配内存失败") << std::endl;
abort();
}
return Element;
}
优化 创建哈希表函数
bool CreateHashTable(HashTable& HashTable, int BucketSpaceSize) {
BucketSpaceSize = BucketSpaceSize <= 0 ? default_BucketSpaceSize : (BucketSpaceSize > default_BucketSpaceSize ? BucketSpaceSize : default_BucketSpaceSize);
HashTable.BucketSpace = CreateHashBucket((HashTable.BucketSpaceSize = BucketSpaceSize));
if (HashTable.BucketSpace){
return true;
}
HashTable.BucketSpaceSize = 0;
return false;
}
增加 CreateHashBucket函数
static HashBucket CreateHashBucket(size_t& BucketSpaceSize) {
//分配哈希桶空间
HashBucket BucketSpace = (HashElement*)malloc(sizeof(HashBucket) * ( BucketSpaceSize));
HashValue TempVal = {};//创建临时值
if (BucketSpace) {
//创建哈希元素并且保存到哈希桶空间内
//初始化哈希桶空间
for (size_t i = 0; i < B ucketSpaceSize; i++) {
BucketSpace[i]= CreateHashElement(TempVal);
}
}
return BucketSpace;
}
此操作只是优化 并不代表没有什么,保持原来的就好了
头部插入最简单高效的办法

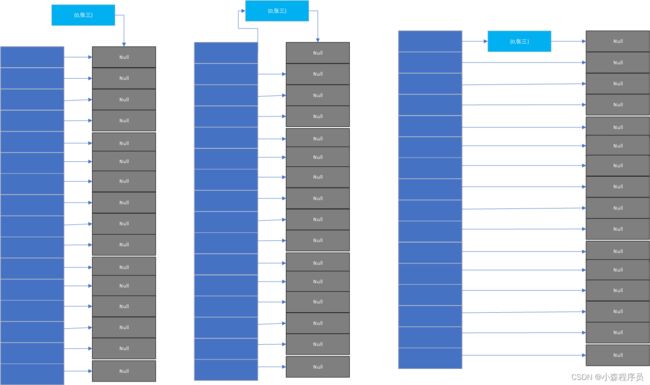
在这里不考虑扩大,哈希桶的容量
哈希链表查找算法
通过key对应的哈希元素
HashElement HashTablFind(const HashTable& HashTable, Key key){
HashBucket BucketSpace = HashTable.BucketSpace;
int HashIndex = Hash({ key }, HashTable);
HashElement HashElementList = BucketSpace[HashIndex];
HashElementList = HashElementList->Next;
while (HashElementList && HashElementList->MyValue.key!=key){
HashElementList = HashElementList->Next;
}
return HashElementList;
}
通过key找到对应的value
Value HashTableKeyToValue(const HashTable& HashTable, Key key){
HashElement Element = HashTablFind(HashTable, key);
if (!Element) {
RunNotFound(__func__, (std::string(" 函数 出错误 :没有这个键值为: ") + std::to_string(key) + " 的数据"));
//记住销毁哈希表
abort();
}
return Element->MyValue.value;
}
哈希表删除算法
//查找key的元素前驱结点 带删除的结点
static HashElement HashTablFindElementNodePrev(const HashTable& HashTable, Key key,LinkNode*&Node) {
HashBucket BucketSpace = HashTable.BucketSpace;
int HashIndex = Hash({ key }, HashTable);
HashElement HashElementList = BucketSpace[HashIndex];
HashElement Prev = HashElementList;
HashElementList = HashElementList->Next;
Node = nullptr;
while (HashElementList && HashElementList->MyValue.key != key) {
Prev = HashElementList;
HashElementList = HashElementList->Next;
}
Node = HashElementList;
return Prev;
}
//哈希表删除算法
void HashTableDelete(HashTable& HashTable, Key key) {
HashElement DeleteNode;
HashElement DeleteNodePrev = HashTableFindElementNodePrev(HashTable, key, DeleteNode);
if (DeleteNode) {
DeleteNodePrev->Next = DeleteNode->Next;
free(DeleteNode);
}
}
哈希表销毁算法
//
static void HashElementDestroy(HashElement& HashElementList);
void HashTableDestroy(HashTable& HashTable){
if (HashTable.BucketSpace ) {
for (size_t i = 0; i < HashTable.BucketSpaceSize; i++) {
HashElementDestroy(HashTable.BucketSpace[i]);
}
free(HashTable.BucketSpace);
HashTable = {};
}
}
void HashElementDestroy(HashElement& HashElementList) {
while (HashElementList) {
LinkNode* Next = HashElementList->Next;
free(HashElementList);
HashElementList = Next;
}
}
哈希顺序表算法实现
虽然链表方式最骚的实现,但插入和删除效率极高 我也无法反驳 但放松了一个月的我来说:虽然 效率不高但实现起来也并不复杂,但我一直没找到,虽然有二分查找法但用了之后的…就没法展开,所以停顿了一段时间,
(好吧,其实我是玩GPT 还有new Bing 虽然说可能没啥可建议的 但也有点帮助)
总之这一个月.我啥也没干[]
哈希顺序表定义
数据定义
using Key = int;
using Value = use define;
//哈希数据
struct Hashvalue {
Key key;
Value value;
};
//顺序表
struct SeqList {
Hashvalue *ValueSpace;
int capacity;
int size;
};
哈希表定义
//哈希表元素类型
using HashElement = Hashvalue*;
//默认桶空间容量
const int default_BucketSpaceSize = 16;
//哈希桶
using HashBucket = SeqList*;
//哈希顺序表
struct HashSeqTable {
HashBucket BucketSpace;//桶空间
size_t HashTableSize;//桶空间大小
};
哈希顺序表创建算法
//创建顺序表
static bool CreateSeqList(SeqList* HashBucket, int capacity) {
if (capacity > 0) {
HashBucket->ValueSpace = (Hashvalue*)malloc(sizeof(Hashvalue) * capacity);
HashBucket->capacity = capacity;
HashBucket->size = 0;
return true;
}
return false;
}
//创建哈希表
bool CreateHashTable(HashSeqTable& HashTable, int BucketSpaceSize) {
bool ret = 0;
BucketSpaceSize = BucketSpaceSize <= 0 ? default_BucketSpaceSize : (BucketSpaceSize > default_BucketSpaceSize ? BucketSpaceSize : default_BucketSpaceSize);
int HashTableSize = HashTable.HashTableSize = BucketSpaceSize;
SeqList* Bucket = (HashBucket)malloc(sizeof(HashBucket) * HashTableSize);
if (Bucket) {
for (size_t i = 0; i < HashTableSize; i++) {
CreateSeqList(Bucket + i, HashTableSize);
}
ret = true;
HashTable.BucketSpace = Bucket;
}
return ret;
}
哈希顺序表插入算法
bool ListAppend(SeqList& list, const Hashvalue& val) noexcept(true) {
bool ret = false;
if (list.size >= list.capacity) {
return ret;
}
int& size = list.size;
list.ValueSpace[size] = (val);
ret = ++size;
return ret;
}
void HashTableInsertUpdate(HashSeqTable& hashTable, const Hashvalue& value) {
SeqList* List(hashTable.BucketSpace + Hash(value.key, hashTable));
ListAppend(*List, value);
}
bool HashTableInsert(HashSeqTable& HashTable, const Hashvalue& value) {
bool ret = false;
const HashSeqTable& const_HashTable = HashTable;
HashElement find = HashTableFind(const_HashTable, value.key);
if (!find) {
HashTableInsertUpdate(HashTable, value);
ret = !ret;
}
return ret;
}
哈希顺序表查找算法
Hashvalue* IndexFind(const HashSeqTable& HashTable, int HashCode, const HashKey& value){
SeqList* list = HashTable.BucketSpace + HashCode;
Hashvalue* dataTable = list->ValueSpace;
int dataSize = list->size;
int capacity = list->capacity;
int index = 0;
Hashvalue* v = nullptr;
if (dataSize > 0) {
while (index != HashCode && dataTable[index].key != value) {
index = (++index) % capacity;
}
v = dataTable[index].key != value ? v : dataTable + index;
}
return v;
}
Hashvalue* HashTableFind(const HashSeqTable& hashTable, const HashKey &value) {
int HashCode = Hash(value , hashTable);
return IndexFind(hashTable, HashCode, value);
}
通过key找到对应的value
// 通过key找到对应的value
HashValue HashTableKeyToValue(const HashSeqTable& HashTable, HashKey key) {
Hashvalue* Hashvalue = HashTableFind(HashTable, key);
if (Hashvalue) {
return Hashvalue->value;
}
return (HashValue)Hashvalue;
}
哈希表删除算法
// 从顺序表中删除目标元素
static void Remove(SeqList& List, Hashvalue* Target) {
// 找到顺序表中最后一个元素
Hashvalue* Last=List.ValueSpace + List.size;
// 将目标元素后面的元素向前移动一个位置
HashElement first = Target + 1;
while (first !=Last){
*Target = *first;
++Target;
++first;
}
// 顺序表的大小减1
--List.size;
}
void HashTableDelete(HashSeqTable& HashTable,const HashKey& key){
SeqList* List = GetHashBucketElement(HashTable, key);
const HashSeqTable& const_HashTable = HashTable;
HashElement deleteHashElement = HashTableFind(const_HashTable, key);
if (deleteHashElement){
Remove(*List, deleteHashElement);
}
}
哈希顺序表销毁算法
//销毁顺序表
static void DestroySeqList(SeqList& list) {
free(list.ValueSpace);
list.ValueSpace = nullptr;
list.capacity = 0;
list.size = 0;
}
void HashTableDestroy(HashSeqTable& HashTable){
for (int i = 0; i < HashTable.HashTableSize; i++){
// 调用销毁顺序表函数销毁每个哈希桶中的顺序表
DestroySeqList(*(HashTable.BucketSpace + i));
}
free(HashTable.BucketSpace);
HashTable = {};
}