【Pytorch基础教程37】Glove词向量训练及TSNE可视化
note
- Glove模型目标:词的向量化表示,使得向量之间尽可能多蕴含语义和语法信息。首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。
- 对词向量计算相似度可以用cos相似度、spearman相关系数、pearson相关系数;预训练词向量可以直接用于下游任务,也可作为模型参数在下游任务的训练过程中进行精调(fine-tuning);很多使用如情感分析、词性标注任务中,我们的NLP模型使用了随机初始化的词向量层(将离散词embedding化)
文章目录
- note
- 一、GLove词向量
- 二、结合代码看Glove模型
-
- 2.1 数据处理
- 2.2 模型部分
- 2.3 模型训练
- 三、将训练好的glove词向量可视化
- 四、词向量评估与应用
- Reference
一、GLove词向量
- w2v这类词向量训练方法是利用词与局部上下文的中的共现信息作为自监督学习信息;还有一类是基于矩阵分解的方法,如潜在语义分析:
- 对预料进行统计分析,获得含有全局统计信息的”词-上下文“共现矩阵
- 利用SVD对矩阵进行降维,得到词的低维表示
- 基于矩阵分解+NN的思想,提出了Glove模型
- Glove模型:
- 构建共现矩阵 M \boldsymbol{M} M, 其中 M w , c M_{w, c} Mw,c 表示词 w w w 与上下文 c c c 在窗口大小内的共现次数。并且用加权方式计算共现距离(分母 d i ( w , c ) d_i(w, c) di(w,c) 表示在第 i i i 次共现发生时, w w w 与 c c c 之间的距离): M w , c = ∑ i 1 d i ( w , c ) M_{w, c}=\sum_i \frac{1}{d_i(w, c)} Mw,c=i∑di(w,c)1
- 利用词与上下文向量embedding对M共现矩阵中的元素进行回归计算(b是偏置项): v w ⊤ v c ′ + b w + b c ′ = log M w , c \boldsymbol{v}_w^{\top} \boldsymbol{v}_c^{\prime}+b_w+b_c^{\prime}=\log M_{w, c} vw⊤vc′+bw+bc′=logMw,c
- 官方github:https://github.com/stanfordnlp/GloVe
Count based vs. direct prediction:
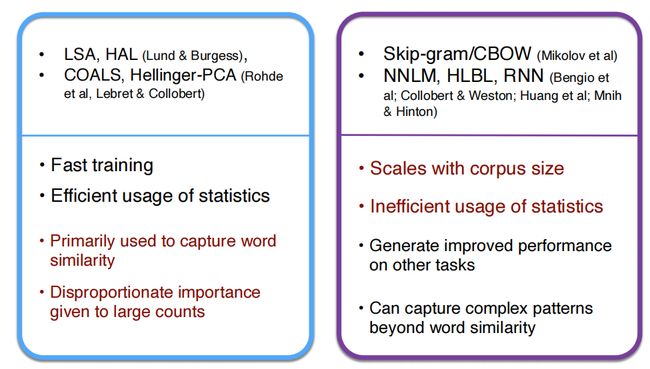
栗子:比如有一个语料库:
i love you but you love him i am sad
现在窗口为5,即中心词左右两边有2个单词组成的统计窗口,窗口0、1长度小于5是因为中心词左侧内容少于2个,同理窗口8、9长度也小于5。窗口内容如下:
| 窗口标号 | 中心词 | 窗口内容 |
|---|---|---|
| 0 | i | i love you |
| 1 | love | i love you but |
| 2 | you | i love you but you |
| 3 | but | love you but you love |
| 4 | you | you but you love him |
| 5 | love | but you love him i |
| 6 | him | you love him i am |
| 7 | i | love him i am sad |
| 8 | am | him i am sad |
| 9 | sad | i am sad |
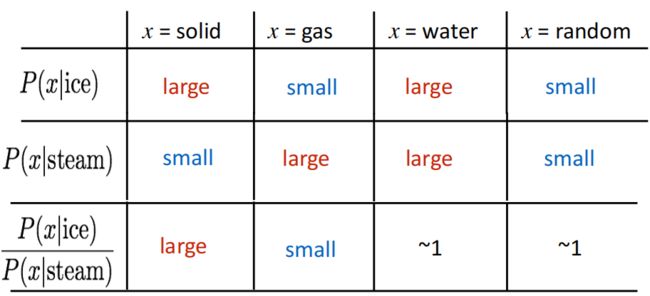
算出对应的比例数值:
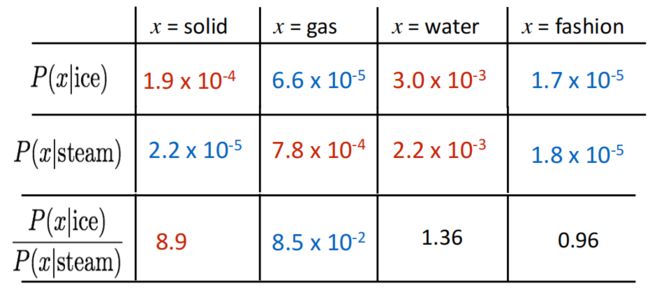
一个问题:

二、结合代码看Glove模型
2.1 数据处理
需要定义继承Dataset的GloveDataset类(对训练预料处理、构建词表),同时共现矩阵的构建和存取。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequence
from tqdm.auto import tqdm
from utils import BOS_TOKEN, EOS_TOKEN, PAD_TOKEN
from utils import load_reuters, save_pretrained, get_loader, init_weights
from collections import defaultdict
class GloveDataset(Dataset):
def __init__(self, corpus, vocab, context_size=2):
# 记录词与上下文在给定语料中的共现次数
self.cooccur_counts = defaultdict(float)
self.bos = vocab[BOS_TOKEN] # 句首标记
self.eos = vocab[EOS_TOKEN] # 句尾标记
for sentence in tqdm(corpus, desc="Dataset Construction"):
sentence = [self.bos] + sentence + [self.eos]
for i in range(1, len(sentence)-1):
w = sentence[i]
left_contexts = sentence[max(0, i - context_size):i]
right_contexts = sentence[i+1:min(len(sentence), i + context_size)+1]
# 共现次数随距离衰减: 1/d(w, c)
for k, c in enumerate(left_contexts[::-1]):
self.cooccur_counts[(w, c)] += 1 / (k + 1)
for k, c in enumerate(right_contexts):
self.cooccur_counts[(w, c)] += 1 / (k + 1)
self.data = [(w, c, count) for (w, c), count in self.cooccur_counts.items()]
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
def collate_fn(self, examples):
words = torch.tensor([ex[0] for ex in examples])
contexts = torch.tensor([ex[1] for ex in examples])
counts = torch.tensor([ex[2] for ex in examples])
return (words, contexts, counts)
2.2 模型部分
Glove比负采样的skip-gram模型增加两个偏置变量w_biased和c_biases变量。
class GloveModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(GloveModel, self).__init__()
# 词嵌入及偏置向量
self.w_embeddings = nn.Embedding(vocab_size, embedding_dim)
self.w_biases = nn.Embedding(vocab_size, 1)
# 上下文嵌入及偏置向量
self.c_embeddings = nn.Embedding(vocab_size, embedding_dim)
self.c_biases = nn.Embedding(vocab_size, 1)
def forward_w(self, words):
w_embeds = self.w_embeddings(words)
w_biases = self.w_biases(words)
return w_embeds, w_biases
def forward_c(self, contexts):
# 上下文embedding和偏置向量
c_embeds = self.c_embeddings(contexts)
c_biases = self.c_biases(contexts)
return c_embeds, c_biases
2.3 模型训练
- 这里负采样我们采用构建数据时batch内生成负样本,效率较高
- 优化加权回归损失函数: L ( θ ; M ) = ∑ ( w , c ) ∈ D f ( M w , c ) ( v w ⊤ v c ′ + b w + b c ′ − log M w , c ) 2 \mathcal{L}(\boldsymbol{\theta} ; \boldsymbol{M})=\sum_{(w, c) \in \mathbb{D}} f\left(M_{w, c}\right)\left(\boldsymbol{v}_w^{\top} \boldsymbol{v}_c^{\prime}+b_w+b_c^{\prime}-\log M_{w, c}\right)^2 L(θ;M)=(w,c)∈D∑f(Mw,c)(vw⊤vc′+bw+bc′−logMw,c)2
其中符号表示: - θ = { E , E ′ , b , b ′ } \boldsymbol{\theta}=\left\{\boldsymbol{E}, \boldsymbol{E}^{\prime}, \boldsymbol{b}, \boldsymbol{b}^{\prime}\right\} θ={E,E′,b,b′} 表示 GloVe 模型中所有可学习的参数
- D表示训练预料中所有共现 ( w , c ) (w,c) (w,c)的样本集合
- f ( M w , c ) f\left(M_{w, c}\right) f(Mw,c) 表示每一个 ( w , c ) (w, c) (w,c) 样本的权重;共现次数很少的样本含有较大噪声,权重低,但是高频共现的样本也不会权重过高,加权的分段函数: f ( M w , c ) = { ( M w , c / m max ) α , 如果 M w , c ⩽ m max 1 , 否则 f\left(M_{w, c}\right)=\left\{\begin{array}{cl} \left(M_{w, c} / m^{\max }\right)^\alpha, & \text { 如果 } M_{w, c} \leqslant m^{\max } \\ 1, & \text { 否则 } \end{array}\right. f(Mw,c)={(Mw,c/mmax)α,1, 如果 Mw,c⩽mmax 否则
# 用以控制样本权重的超参数
m_max = 100
alpha = 0.75
# 从文本数据中构建GloVe训练数据集
corpus, vocab = load_reuters()
dataset = GloveDataset(
corpus,
vocab,
context_size=context_size
)
def get_loader(dataset, batch_size, shuffle=True):
data_loader = DataLoader(
dataset,
batch_size=batch_size,
collate_fn=dataset.collate_fn,
shuffle=shuffle
)
return data_loader
data_loader = get_loader(dataset, batch_size)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = GloveModel(len(vocab), embedding_dim)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.train()
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):
words, contexts, counts = [x.to(device) for x in batch]
# 提取batch内词、上下文的向量表示及偏置
word_embeds, word_biases = model.forward_w(words)
context_embeds, context_biases = model.forward_c(contexts)
# 回归目标值:必要时可以使用log(counts+1)进行平滑
log_counts = torch.log(counts)
# 样本权重
weight_factor = torch.clamp(torch.pow(counts / m_max, alpha), max=1.0)
optimizer.zero_grad()
# 计算batch内每个样本的L2损失
loss = (torch.sum(word_embeds * context_embeds, dim=1) + word_biases + context_biases - log_counts) ** 2
# 样本加权损失
wavg_loss = (weight_factor * loss).mean()
wavg_loss.backward()
optimizer.step()
total_loss += wavg_loss.item()
print(f"Loss: {total_loss:.2f}")
# 合并词嵌入矩阵与上下文嵌入矩阵,作为最终的预训练词向量
combined_embeds = model.w_embeddings.weight + model.c_embeddings.weight
save_pretrained(vocab, combined_embeds.data, "glove.vec")
三、将训练好的glove词向量可视化
glove.vec读取到字典里,单词为key,embedding作为value;选了几个单词的词向量进行降维,然后将降维后的数据转为dataframe格式,绘制散点图进行可视化。- 可以直接使用
sklearn.manifold的TSNE:perplexity参数用于控制 t-SNE 算法的困惑度,n_components参数用于指定降维后的维度数,init参数用于指定初始化方式,n_iter参数用于指定迭代次数,random_state参数用于指定随机数种子。
ax.annotate(word, pos, fontsize = 40)可以在每个节点位置加上对应词向量的key。
# !/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.manifold import TSNE
import pandas as pd
import matplotlib.pyplot as plt
# 加载训练好的词向量
embeddings_index = {}
with open('/glove.vec', encoding='utf-8') as f:
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
# 选择部分词向量进行降维可视化
# words = ['apple', 'banana', 'orange', 'pear', 'grape', 'watermelon']
words = ['good', 'well', 'many', 'fears', 'american', 'analyst', 'china']
# embeddings_index_selected = {word: embeddings_index[word] for word in words}
embeddings_index_selected = np.array([embeddings_index[word] for word in words])
# 对词向量进行降维
tsne_model = TSNE(perplexity=5, n_components=2, init='pca', n_iter=2500, random_state=23)
# tsne_values = tsne_model.fit_transform(list(embeddings_index_selected.values()))
tsne_values = tsne_model.fit_transform(embeddings_index_selected)
# 将降维后的数据转换为 DataFrame 格式
df = pd.DataFrame(tsne_values, index=words, columns=['x', 'y'])
# 绘制散点图
fig, ax = plt.subplots(figsize=(15, 15))
ax.scatter(df['x'], df['y'])
for word, pos in df.iterrows():
ax.annotate(word, pos, fontsize = 40)
plt.savefig("glove_embedding_tsne.jpg")
plt.show()
结果如下图,可以看到good单词和well单词还是很靠近,说明glove训练出来的词向量还是靠谱的哈哈。
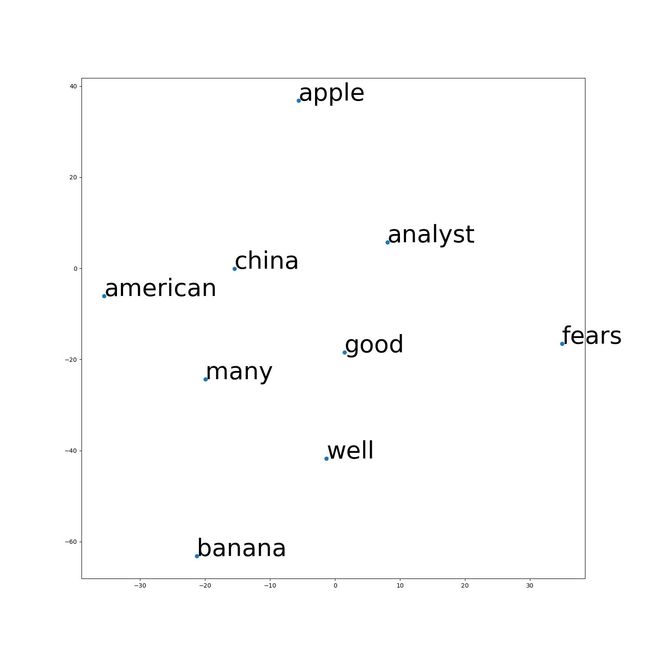
四、词向量评估与应用
- 如上面的可视化对词向量可视化肉眼比较
- 对词向量计算cos相似度、spearman相关系数、pearson相关系数等
- 预训练词向量可以直接用于下游任务,也可作为模型参数在下游任务的训练过程中进行精调(fine-tuning)
- 很多使用如情感分析、词性标注任务中,我们的NLP模型使用了随机初始化的词向量层(将离散词embedding化),我们其实也可以使用上面预训练好的词向量,一般能加速模型收敛、提升模型准确度
- 下游任务的训练数据的词表和预训练的词表一般不同,所以可以只初始化在预训练词表中存在的词,其他词仍是随机初始化向量,后续fine-tuning;其他词也可以统一用
- 有的任务中可以通过
requires_gradient=False冻结词向量参数,即词向量作为特征使用 - 词向量的最近邻topK检索可以用如下的knn,也可以用gpu加速的faiss
def load_pretrained(load_path):
with open(load_path, "r") as fin:
# Optional: depending on the specific format of pretrained vector file
n, d = map(int, fin.readline().split())
tokens = []
embeds = []
for line in fin:
line = line.rstrip().split(' ')
token, embed = line[0], list(map(float, line[1:]))
tokens.append(token)
embeds.append(embed)
vocab = Vocab(tokens)
embeds = torch.tensor(embeds, dtype=torch.float)
return vocab, embeds
def knn(W, x, k):
similarities = torch.matmul(x, W.transpose(1, 0)) / (torch.norm(W, dim=1) * torch.norm(x) + 1e-9)
knn = similarities.topk(k=k)
return knn.values.tolist(), knn.indices.tolist()
# 在词向量空间中进行近义词检索(这里我们用到我们之前glove.py训练好的glove.vec,预训练词向量)
def find_similar_words(embeds, vocab, query, k=10):
knn_values, knn_indices = knn(embeds, embeds[vocab[query]], k + 1)
knn_words = vocab.convert_ids_to_tokens(knn_indices)
print(f">>> Query word: {query}")
for i in range(k):
print(f"cosine similarity={knn_values[i + 1]:.4f}: {knn_words[i + 1]}")
word_sim_queries = ['good', 'well', 'many', 'fears', 'american', \
'analyst', 'china', 'apple', 'banana', 'orange', 'grape', 'watermelon']
vocab, embeds = load_pretrained("glove.vec")
for w in word_sim_queries:
find_similar_words(embeds, vocab, w)
print("=======test========")
Reference
[1] 语言模型(LM)介绍及实操
[2] 利用t-SNE可视化Glove向量
[3] 李沐动手学dl:自然语言推断:微调BERT
[4] 自然语言处理.基于预训练模型的方法
[5] 论文:Encoding meaning components in vector differences
[Pennington, Socher, and Manning, EMNLP 2014]
[6] Encoding meaning in vector differences
[Pennington, Socher, and Manning, EMNLP 2014]
[7] Word2Vec词向量—本质、思想、推导、中文维基百科词向量训练&可视化实战