【强化学习】时间差分法(TD)
引用 知乎专栏 天津包子馅儿的知乎
1、前言
之前的强化学习分类中介绍了几种强化学习方法的分类,今天就说一下其中重要的算法思想时间差分法,TD与蒙特卡罗法主要是在值函数的更新上有所差异,我们可以先看下图

动态规划法:
需要一个完全已知的环境,需要状态之间的转换概率,并且V(S)状态值函数的估计是自举的(bootstrapping),即当前状态值函数的更新依赖于已知的其他状态值函数,也就是使用bellman方程求解值函数。
V ( s ) ← E π [ R t + 1 + γ V ( s ′ ) ] V(s)←E_\pi[R_{t+1}+\gamma V(s')] V(s)←Eπ[Rt+1+γV(s′)]
此处有一个概念:值函数的计算用到了bootstapping的方法。所谓bootstrpping本意是指自举,此处是指当前值函数的计算用到了后继状态的值函数。即用后继状态的值函数计算当前值函数。
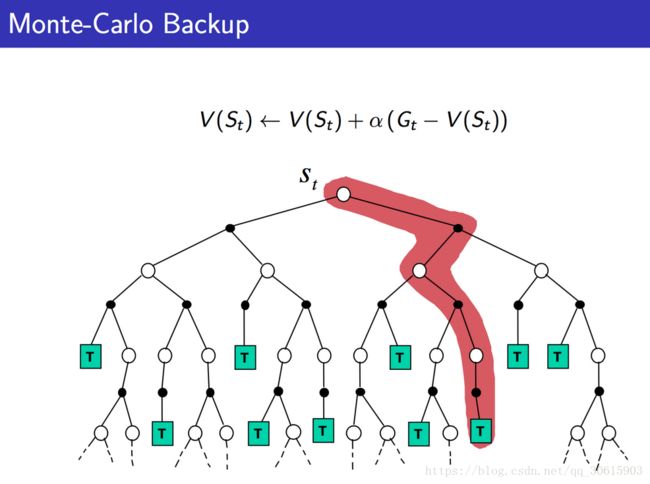
蒙特卡罗法:
我们之前在PolicyGradient中使用到了这种方法,他可以应用在model-free的算法中,但是他需要执行完整的一个episode的才可以进行估计。注意此处的 G t G_t Gt是利用经验平均估计状态的值函数所计算出来的。
V ( s ) ← V ( s ) + α ( G t − V ( s ) ) V(s)←V(s)+\alpha (G_t-V(s)) V(s)←V(s)+α(Gt−V(s))
所以可以看出使用蒙特卡罗法需要回合结束才能更新,结合以上两者的优势就得到了TD算法
2、时间差分法TD
时间差分方法结合了蒙特卡罗的采样方法和动态规划方法的bootstrapping(利用后继状态的值函数估计当前值函数)使得他可以适用于model-free的算法并且是单步更新,速度更快。值函数计算方式如下
V ( s ) ← V ( s ) + α ( R t + 1 + γ V ( s ′ ) − V ( s ) ) V(s)←V(s)+\alpha (R_{t+1}+\gamma V(s')-V(s)) V(s)←V(s)+α(Rt+1+γV(s′)−V(s))
其中 R t + 1 + γ V ( s ′ ) R_{t+1}+\gamma V(s') Rt+1+γV(s′)被称为TD目标, δ t = R t + 1 + γ V ( s ′ ) − V ( s ) \delta_t=R_{t+1}+\gamma V(s')-V(s) δt=Rt+1+γV(s′)−V(s) 称为TD偏差。
我们可以发现其实就是把蒙特卡罗法中估计的 G t G_t Gt替换成了TD目标,因为TD目标使用了bootstrapping方法估计当前值函数,所以这样就结合了动态规划的优点避免了回合更新的尴尬。
TD(0)的估计方式如下

TD(λ)可以通过在TD-target再根据bellman方程展开,就可扩展成n-step的形式,将每步求和取平均然后分别计算,并且赋予系数(系数加和为1)。

G t λ = ( 1 − λ ) ∑ n = 1 ∞ λ n − 1 G t ( n ) G_t^\lambda = (1-\lambda)\sum_{n=1}^∞\lambda^{n-1}G_t^{(n)} Gtλ=(1−λ)∑n=1∞λn−1Gt(n)
其中 G t ( n ) = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . . . . γ n − 1 R t + n + γ n V ( S t + n ) G_t^{(n)}=R_{t+1}+\gamma R_{t+2}+\gamma ^2 R_{t+3}+......\gamma ^{n-1}R_{t+n}+\gamma ^{n}V(S_{t+n}) Gt(n)=Rt+1+γRt+2+γ2Rt+3+......γn−1Rt+n+γnV(St+n)
T D ( λ ) TD\left(\lambda\right) TD(λ)更新过程为:
- 首先计算当前状态的TD偏差: δ t = R t + 1 + γ V ( S t + 1 ) − V ( S t ) \delta_t=R_{t+1}+\gamma V\left(S_{t+1}\right)-V\left(S_t\right) δt=Rt+1+γV(St+1)−V(St)
2)更新适合度轨迹 E t ( s ) = { γ λ E t − 1 , i f s ≠ s t γ λ E t − 1 + 1 , i f s = s t E_t\left(s\right)=\left\{\begin{array}{l}\gamma\lambda E_{t-1},\ if\ s\ne s_t\\\gamma\lambda E_{t-1}+1,\ if\ s=s_t\\\end{array}\right. Et(s)={γλEt−1, if s̸=stγλEt−1+1, if s=st
3)对于状态空间中的每个状态 s, 更新值函数: V ( s ) ← V ( s ) + α δ t E t ( s ) V\left(s\right)\gets V\left(s\right)+\alpha\delta_tE_t\left(s\right) V(s)←V(s)+αδtEt(s)
其中 E t ( s ) E_t\left(s\right) Et(s)称为适合度轨迹
首先,当 λ = 0 \lambda =0 λ=0 时,只有当前状态值更新,此时等价于之前说的TD方法。所以TD方法又称为TD(0)方法.
其次,当 λ = 1 \lambda =1 λ=1时,状态s值函数总的更新与蒙特卡罗方法相同: δ t + γ δ t + 1 + γ 2 δ t + 2 + ⋯ + γ T − 1 − t δ T − 1 = R t + 1 + γ V ( S t + 1 ) − V ( S t ) + γ R t + 2 + γ 2 V ( S t + 2 ) − γ V ( S t + 1 ) + γ 2 R t + 3 + γ 3 V ( S t + 3 ) − γ 2 V ( S t + 2 ) ⋮ + γ T − 1 − t R T + γ T − t V ( S T ) − γ T − 1 − t V ( S T − 1 ) \begin{array}{l}\delta_t+\gamma\delta_{t+1}+\gamma^2\delta_{t+2}+\cdots +\gamma^{T-1-t}\delta_{T-1}\\=R_{t+1}+\gamma V\left(S_{t+1}\right)-V\left(S_t\right)\\+\gamma R_{t+2}+\gamma^2V\left(S_{t+2}\right)-\gamma V\left(S_{t+1}\right)\\+\gamma^2R_{t+3}+\gamma^3V\left(S_{t+3}\right)-\gamma^2V\left(S_{t+2}\right)\\\vdots\\+\gamma^{T-1-t}R_T+\gamma^{T-t}V\left(S_T\right)-\gamma^{T-1-t}V\left(S_{T-1}\right)\\\end{array} δt+γδt+1+γ2δt+2+⋯+γT−1−tδT−1=Rt+1+γV(St+1)−V(St)+γRt+2+γ2V(St+2)−γV(St+1)+γ2Rt+3+γ3V(St+3)−γ2V(St+2)⋮+γT−1−tRT+γT−tV(ST)−γT−1−tV(ST−1)
对于一般的\lambda,前向观点等于后向观点: G t λ − V ( S t ) = − V ( S t ) + ( 1 − λ ) λ 0 ( R t + 1 + γ V ( S t + 1 ) ) + ( 1 − λ ) λ 1 ( R t + 1 + γ R t + 2 + γ 2 V ( S t + 2 ) ) + ( 1 − λ ) λ 2 ( R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 V ( S t + 2 ) ) + ⋯ \begin{array}{l}G_t^\lambda - V\left( {{S_t}} \right) = \\ - V\left( {{S_t}} \right) + \left( {1 - \lambda } \right){\lambda ^0}\left( {{R_{t + 1}} + \gamma V\left( {{S_{t + 1}}} \right)} \right)\\ + \left( {1 - \lambda } \right){\lambda ^1}\left( {{R_{t + 1}} + \gamma {R_{t + 2}} + {\gamma ^2}V\left( {{S_{t + 2}}} \right)} \right)\\ + \left( {1 - \lambda } \right){\lambda ^2}\left( {{R_{t + 1}} + \gamma {R_{t + 2}} + {\gamma ^2}{R_{t + 3}} + {\gamma ^3}V\left( {{S_{t + 2}}} \right)} \right) + \cdots \end{array} Gtλ−V(St)=−V(St)+(1−λ)λ0(Rt+1+γV(St+1))+(1−λ)λ1(Rt+1+γRt+2+γ2V(St+2))+(1−λ)λ2(Rt+1+γRt+2+γ2Rt+3+γ3V(St+2))+⋯
= − V ( S t ) + ( γ λ ) 0 ( R t + 1 + γ V ( S t + 1 ) − γ λ V ( S t + 1 ) ) + ( γ λ ) 1 ( R t + 2 + γ V ( S t + 2 ) − γ λ V ( S t + 2 ) ) + ( γ λ ) 2 ( R t + 3 + γ V ( S t + 3 ) − γ λ V ( S t + 3 ) ) + ⋯ = ( γ λ ) 0 ( R t + 1 + γ V ( S t + 1 ) − V ( S t ) ) + ( γ λ ) 1 ( R t + 2 + γ V ( S t + 2 ) − V ( S t + 1 ) ) + ( γ λ ) 2 ( R t + 3 + γ V ( S t + 3 ) − V ( S t + 2 ) ) + ⋯ \begin{array}{l}{\rm{ = }} - V\left( {{S_t}} \right) + {\left( {\gamma \lambda } \right)^0}\left( {{R_{t + 1}} + \gamma V\left( {{S_{t + 1}}} \right) - \gamma \lambda V\left( {{S_{t + 1}}} \right)} \right)\\ + {\left( {\gamma \lambda } \right)^1}\left( {{R_{t + 2}} + \gamma V\left( {{S_{t + 2}}} \right) - \gamma \lambda V\left( {{S_{t + 2}}} \right)} \right)\\ + {\left( {\gamma \lambda } \right)^2}\left( {{R_{t + 3}} + \gamma V\left( {{S_{t + 3}}} \right) - \gamma \lambda V\left( {{S_{t + 3}}} \right)} \right) + \cdots \end{array} \begin{array}{l}{\rm{ = }}{\left( {\gamma \lambda } \right)^0}\left( {{R_{t + 1}} + \gamma V\left( {{S_{t + 1}}} \right) - V\left( {{S_t}} \right)} \right)\\{\rm{ + }}{\left( {\gamma \lambda } \right)^1}\left( {{R_{t + 2}} + \gamma V\left( {{S_{t + 2}}} \right) - V\left( {{S_{t + 1}}} \right)} \right)\\{\rm{ + }}{\left( {\gamma \lambda } \right)^2}\left( {{R_{t + 3}} + \gamma V\left( {{S_{t + 3}}} \right) - V\left( {{S_{t + 2}}} \right)} \right) + \cdots \end{array} =−V(St)+(γλ)0(Rt+1+γV(St+1)−γλV(St+1))+(γλ)1(Rt+2+γV(St+2)−γλV(St+2))+(γλ)2(Rt+3+γV(St+3)−γλV(St+3))+⋯=(γλ)0(Rt+1+γV(St+1)−V(St))+(γλ)1(Rt+2+γV(St+2)−V(St+1))+(γλ)2(Rt+3+γV(St+3)−V(St+2))+⋯
= δ t + γ λ δ t + 1 + ( γ λ ) 2 δ t + 2 + ⋯ {\rm{ = }}{\delta _t} + \gamma \lambda {\delta _{t + 1}} + {\left( {\gamma \lambda } \right)^2}{\delta _{t + 2}} + \cdots =δt+γλδt+1+(γλ)2δt+2+⋯
注意,所谓等价是指更新总量相等。
是不是觉得有点像Sarsa与Sarse( λ \lambda λ),它其实就是来自于这个原始思想
3、算法对比
对比MC算法与TD算法的特点
**MC:**无偏估计;容易收敛;可以使用函数拟合;初值不敏感;理解简单容易使用
**TD:**估计值有误差;通常情况笔MC更有效;TD(0)收敛于 V π ( s ) V_\pi(s) Vπ(s);初值敏感
接下来引用Sliver的PPT中的图来帮助区分这三种算法