yolov7运行自己的VOC格式数据集
yolov7运行VOC格式数据集
- 代码下载
- 测试开发环境
- 使用自己的VOC格式数据集训练
-
- 修改配置文件yolov7.yaml
- 修改配置文件voc.yaml
- VOC格式数据集转换COCO格式
- 开始训练
-
- 重头开始
- fine-train
- BUG
-
- wandb模块
- 常见报错1
- 常见报错2
- 常见报错3
- 常见报错 4
- 成功训练网络
- 评价指标
- 可视化
代码下载
地址:yolov7
测试开发环境
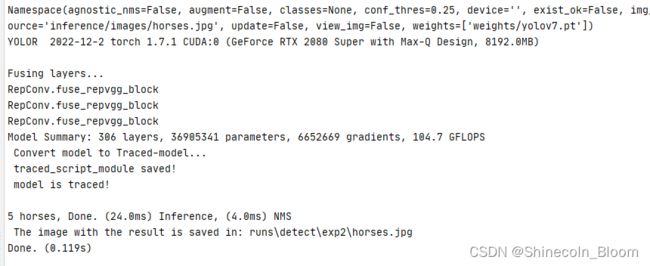
去官网下载yolov7的权重文件,放入weights目录下,运行detec.py文件测试是否安装成功,官网地址:权重下载
python detect.py --weights weights/yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg

使用自己的VOC格式数据集训练
修改配置文件yolov7.yaml
首先修改cfg下training下的yolov7.yaml文件。
修改修改nc并设置为自己训练的类别个数

修改配置文件voc.yaml

关键点在于,这得是一个文件夹的路径,不能是txt文件的路径。。。。。。
如果设置txt文件的路径,很容易报BUG:
assertionerror:no labels found in //*/JPEGImages.cache can not train without labels
这个BUG搞了我很久
因为v7结构和原始的v5一样,v5官方就是给的文件夹:
v5的coco.yaml文件如下
# download command/URL (optional)
download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../coco/images/train2017/
val: ../coco/images/train2017/
# number of classes
nc: 80
# class names
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
可以看出,yaml文件中的训练集和验证集数据地址都是为一个装图像数据的文件夹(…/coco/images/train2017/ …/coco/images/train2017/),而不是我之前使用VOC2yolo代码转换生成的train.txt和val.txt。
VOC格式数据集转换COCO格式
官方代码是COCO格式的,就涉及到VOC数据集格式转COCO格式问题。
(这个.sh代码是项目找不到数据集的时候,就会调用他下载COCO…一定要把他注释掉。。。)
voc2yolov7.py代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
# 根据自己的数据标签修改
classes=["tumor"]
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
if(probo < 80): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
出处
运行结束

执行后的项目结构:
放图片的
放标签的:
开始训练

parser.add_argument('--weights', type=str, default='./weights/v7.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='./cfg/training/yolov7.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/voc.yaml', help='data.yaml path')
重头开始
单gpu
python train.py --workers 1 --device 0 --batch-size 8 --data data/liver.yaml --img 640 640 --cfg cfg/training/yolov7-MY.yaml --weights 'weights/yolov7.pt' --name yolo
v7 --hyp data/hyp.scratch.p5.yaml
fine-train
权重下载地址:V7各种权重
python train.py --workers 8 --device 0 --batch-size 32 --data data/liver.yaml --img 512 512 --cfg cfg/training/yolov7-my.yaml --weights 'yolov7_training.pt' --name yolov7-fine-train --hyp data/hyp.scratch.p5.yaml
BUG
wandb模块
关于这个问题,见这篇博客wandb问题解决
常见报错1
subprocess.CalledProcessError: Command ‘git tag’ returned non-zero exit status 1.
出现这种情况大概率是传参有问题,参数缺失或者参数错误
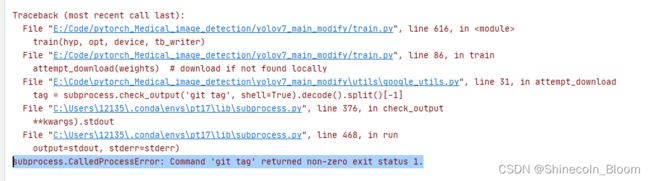
这个问题最终是因为找不到yolov7.pt权重文件所以去下载了,但是其实我是有的。可能是因为编码问题。我把我下载 的yolov7.pt重命名(自己手动输一遍)就解决了
常见报错2

这是数据集找不到,执行scirpts/.sh脚本去下载数据集了。。。
liver.yaml中:修改

又报错

查看txt文件
改成绝对路径
在吧后面lable信息删除
就最终报错到,显示没有标签。。。。。。(用我上面的代码这个问题就解决了)
常见报错3
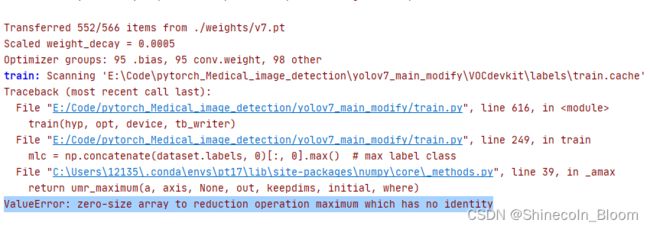
检查训练数据和验证数据是否包含所有标签。
检查标签的个数和标签名是否相同。
如果用了模型结构的配置文件,检查里面标签个数改没改
常见报错 4
RuntimeError: cuDNN error: CUDNN_STATUS_INTERNAL_ERROR
torch.backends.cudnn.benchmark=True
加在开头
成功训练网络
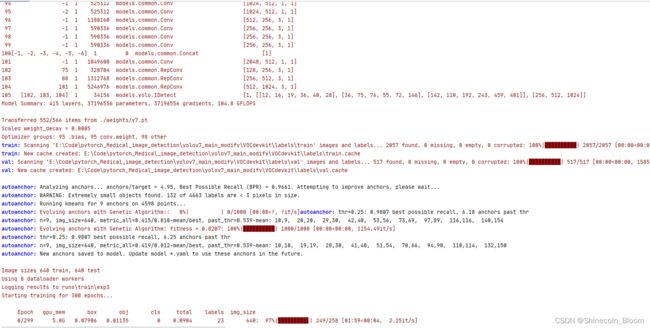
评价指标
python test.py --data data/voc.yaml --img 512 --batch 32 --conf 0.001 --iou 0.65 --device 0 --weights runs/train/exp4/weights/best.pt --name yolov7_640_val

可视化
python detect.py --weights runs/train/exp4/weights/best.pt --conf 0.25 --img-size 512 --source inference/images/a.jpg
