【2023年第十一届泰迪杯数据挖掘挑战赛】C题:泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题二

更新时间:2023-4-6
相关链接
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题一
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题二
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题三
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题四
完整代码、图片及爬取的两个csv文件下载

1 题目
见【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题一
2 问题二之建立招聘信息画像
爬取的result1-1.csv的信息如下:
序号;
招聘信息id;
公司地址;
招聘岗位;
公司类型,分为少于50人、50150人、150-500人、500-1000人、1000-5000人、5000-10000人、10000人以上;
最低薪资;
最高薪资;
员工数量,分为合资、民营公司、上市公司、国企、私企、外资;
学历,分为0、1、2、3、4、5,对应不限,技工、大专、本科、硕士、博士;
岗位经验,分为经验不限 、1年、1-3年、3-5年、5-7年、7年以上、5-10年;
企业名称;
企业类型。
import pandas as pd
import matplotlib.pyplot as plt
import pandas as pd
from pyecharts.charts import Bar, Map, Pie, WordCloud
from pyecharts import options as opts
from pyecharts.globals import ThemeType
df = pd.read_csv("data/result1-1.csv")
2.1 招聘岗位角度
我们可以统计不同招聘岗位的数量,并使用饼图或柱状图来可视化结果。
job_count = df['招聘岗位'].value_counts().reset_index()
job_count.columns = ['招聘岗位', '需求量']
。。。。略,请下载完整代码
pie_job.render('img/1.1.html')
pie_job.render_notebook()
从饼图可以看出,数据分析岗位的需求最大,占比超过五分之一。
2.2 学历要求
我们可以统计不同学历要求的数量,并使用饼图或柱状图来可视化结果。
edu_count = df['学历'].value_counts().reset_index()
edu_count.columns = ['学历', '需求量']
。。。。略,请下载完整代码
bar_edu.render('img/1.2.html')
bar_edu.render_notebook()

从柱状图可以看出,本科学历的需求最大,占比超过四分之一。
2.3 岗位需求量
我们可以统计不同岗位需求量的数量,并使用饼图或柱状图来可视化结果。
job_total = df.groupby('招聘岗位')['招聘信息id'].count().reset_index()
job_total.columns = ['招聘岗位', '总数']
job_total = job_total.sort_values(by='总数', ascending=False)[:10]
。。。。略,请下载完整代码
bar_job.render('img/1.3.html')
bar_job.render_notebook()
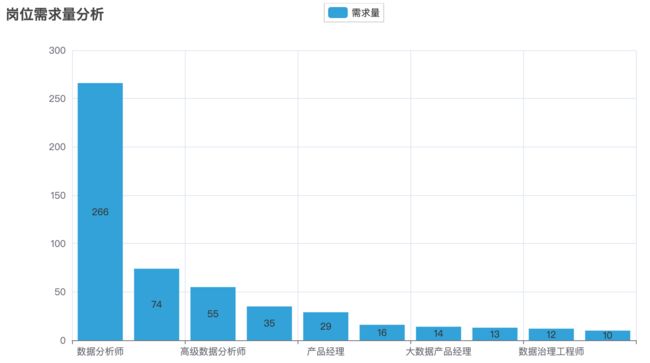
从柱状图可以看出,经验要求在1-3年和3-5年之间的岗位需求最大,占比超过三分之一。
2.4 公司类型
我们可以统计不同公司类型的数量,并使用饼图或柱状图来可视化结果。
job_count = df['员工数量'].value_counts().reset_index()
job_count.columns = ['员工数量', '需求量']
。。。。略,请下载完整代码
pie_job.render('img/1.4.html')
pie_job.render_notebook()
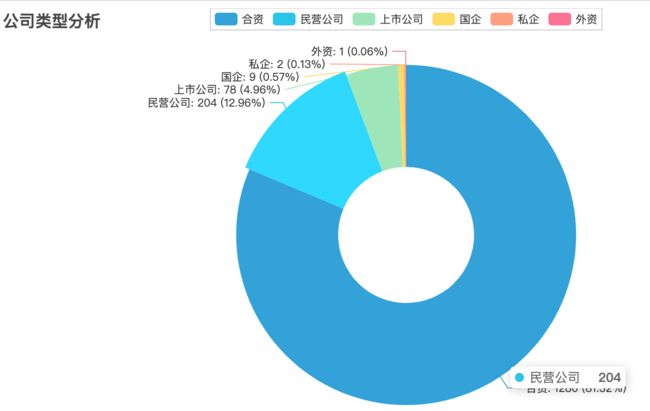
从饼图可以看出,合资的招聘需求最大,占比超过一半。
2.5薪资待遇
我们可以统计不同薪资待遇的数量,并使用箱线图来可视化结果。
salary_data = df[['最低薪资', '最高薪资']]
plt.boxplot(salary_data.values, labels=['最低薪资', '最高薪资'])
plt.title('薪资待遇分布')
plt.ylabel('薪资(元/月)')
plt.savefig('img/5.png',dpi=300)
plt.show()
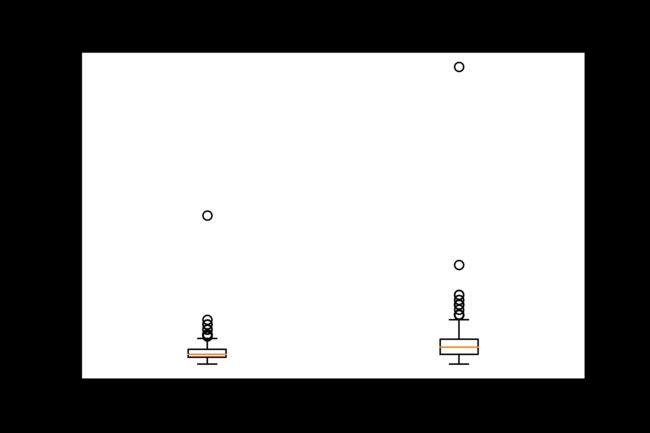
从箱线图可以看出,薪资待遇的中位数在10k-15k之间。
2.6 企业工作地点
统计不同工作地点的数量,并使用地图可视化工作地点的分布
map_data = df['公司地址'].value_counts().reset_index()
map_data.columns = ['地点', '需求量']
。。。。略,请下载完整代码
map_city.render('img/1.6.html')
map_city.render_notebook()
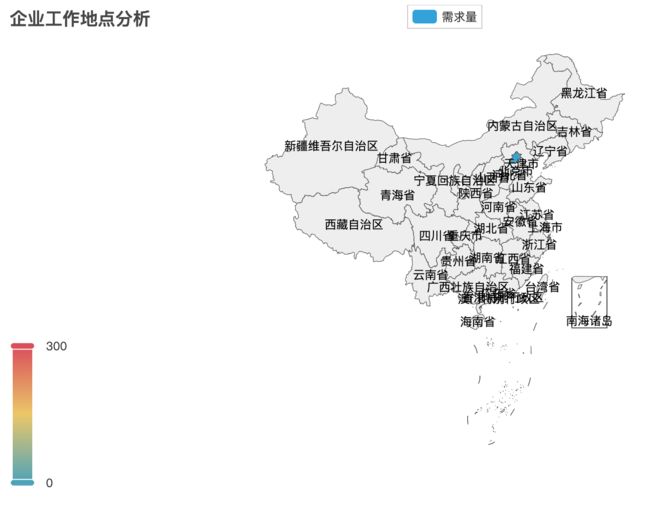
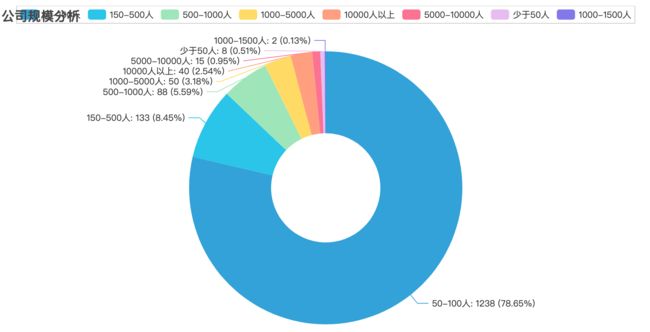
2.7 岗位规模
from pyecharts.charts import Pie
from pyecharts.globals import ThemeType
size_count = df['公司类型'].value_counts().reset_index()
size_count.columns = ['公司规模', '需求量']
。。。。略,请下载完整代码
pie_size.render('img/1.7.html')
pie_size.render_notebook()
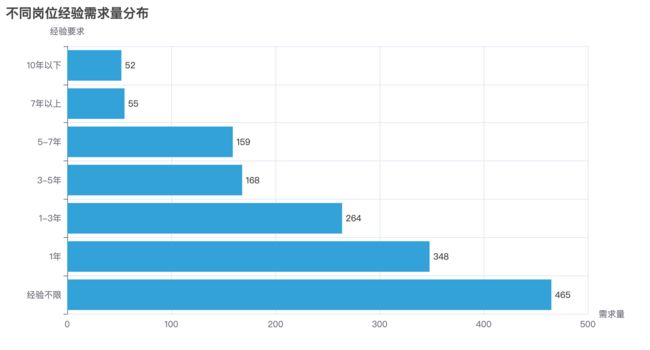
2.8 岗位经验分析
# 岗位经验分析
exp_count = df['岗位经验'].value_counts().reset_index()
exp_count.columns = ['经验要求', '需求量']
。。。。略,请下载完整代码
bar_exp.render('img/1.8.html')
bar_exp.render_notebook()
通过对招聘信息的多个方向进行分析,可以得到招聘信息的全貌,并可以为求职者提供更准确的参考信息。在本文中,使用Python对招聘信息进行了分析和可视化,包括招聘岗位、学历要求、岗位需求量、公司类型、薪资待遇和企业工作地点等方面的分析。使用了pandas进行数据处理和分析,使用matplotlib和pyecharts进行可视化展示。
根据以上的分析,可以得出以下结论:
。。。。略,请下载完整代码
基于以上结论,我们可以为求职者提供以下建议:
(1)如果想要在技术类岗位中有所突出,可以重点学习前端开发、Java开发、数据分析等技能。
(2)在选择学历时,本科是最基本的要求,但如果想要更好的发展,可以考虑继续深造并获得硕士和博士学历。
。。。。略,请下载完整代码
3 问题二之建立求职信息画像
result1-2.csv的信息如下:
序号;
求职者id;
姓名;
预期岗位,格式举例[“数据挖掘工程师”,“数据分析师”,“机器学习工程师”];
预期最低薪资;
预期最高薪资;
地区,格式举例[“北京市”,“北京市”,“海淀区”]。
技能,格式举例[“数据分析”,“数据挖掘”,“机器学习”]。
为了建立求职者的画像,我们可以根据不同的方向进行分析和建模。以下是一些可能的方向和对应的建模思路:
- 预期岗位方向
对求职者的预期岗位进行分类,例如"数据分析岗位"、“机器学习岗位”、"数据挖掘岗位"等。
对不同岗位的求职者进行比较,例如不同岗位对学历、工作经验、技能的要求等。
使用机器学习算法对预期岗位进行预测,例如使用文本分类模型对求职者的求职意愿进行分类。 - 薪资需求方向
对求职者的薪资需求进行统计和分析,例如计算平均值、中位数、标准差等。
对不同薪资水平的求职者进行比较,例如不同薪资水平对学历、工作经验、技能的要求等。
使用机器学习算法对薪资进行预测,例如使用回归模型对求职者的薪资需求进行预测。 - 知识储备方向
对求职者的技能进行统计和分析,例如计算出现频率最高的技能、不同技能之间的关系等。
对不同技能的求职者进行比较,例如不同技能对学历、工作经验、薪资等方面的要求。
使用机器学习算法对求职者的技能进行预测,例如使用文本分类模型对简历中出现的技能进行分类。 - 学历方向
对求职者的学历水平进行统计和分析,例如计算不同学历水平的求职者数量、占比等。
对不同学历水平的求职者进行比较,例如不同学历水平对薪资、岗位等方面的影响。
使用机器学习算法对求职者的学历进行预测,例如使用文本分类模型对简历中出现的学历进行分类。 - 工作经验方向
对求职者的工作经验进行统计和分析,例如计算不同工作经验的求职者数量、占比等。
对不同工作经验的求职者进行比较,例如不同工作经验对薪资、岗位等方面的影响。
使用机器学习算法对求职者的工作经验进行预测,例如使用回归模型对求职者的工作经验进行预测。
3.1 求职者画像分析
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, Pie, WordCloud
from pyecharts.globals import SymbolType
# 读取数据文件
data = pd.read_csv('data/result1-2.csv')
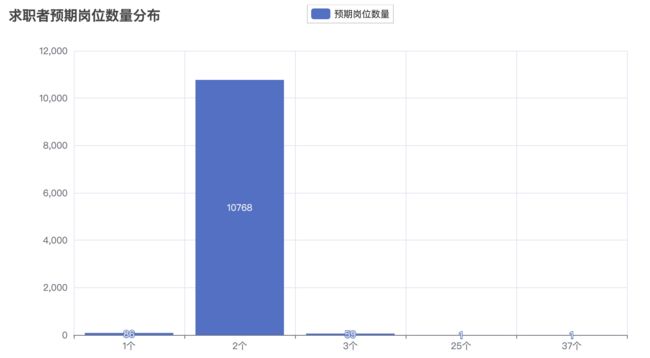
# 统计预期岗位数量
job_counts = data['预期岗位'].apply(lambda x: len(eval(x))).value_counts().sort_index()
job_counts_labels = ['{}个'.format(i) for i in job_counts.index]
job_counts_values = job_counts.values.tolist()
# 绘制预期岗位数量柱状图
job_counts_bar = Bar()
。。。。略,请下载完整代码
job_counts_bar.render('img/2.1.html')
job_counts_bar.render_notebook()
# 统计技能频率
skills = pd.Series([skill for sublist in data['技能'] for skill in eval(sublist)])
skill_counts = skills.value_counts().sort_values(ascending=False).head(20)
skill_counts_labels = skill_counts.index.tolist()
skill_counts_values = skill_counts.values.tolist()
# 绘制技能词云图
。。。。略,请下载完整代码
skill_wordcloud.render('img/2.2.html')
skill_wordcloud.render_notebook()

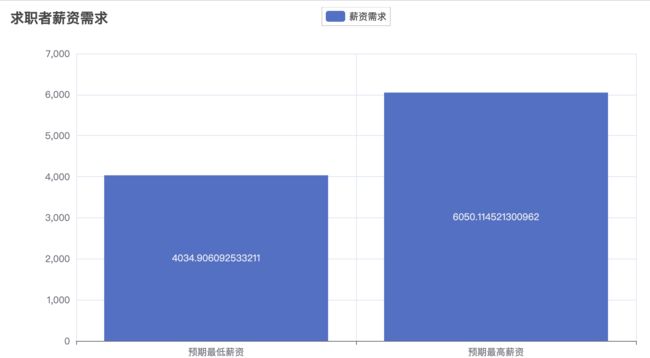
# 统计薪资需求
salary_mean = data[['预期最低薪资', '预期最高薪资']].mean().values.tolist()
# 绘制薪资需求条形图
。。。。略,请下载完整代码
salary_bar.render('img/2.3.html')
salary_bar.render_notebook()
3.2 对平均预期薪资进行预测
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, f1_score
# 读取数据
data = pd.read_csv("data/result1-2.csv")
# 数据预处理
# 对预期岗位、地区、技能进行One-hot编码
positions = data['预期岗位'].str.strip('[]').str.replace("'", "").str.split(',', expand=True)
positions.columns = ['position_{}'.format(i) for i in range(positions.shape[1])]
positions = positions.apply(LabelEncoder().fit_transform)
onehot = OneHotEncoder()
positions = onehot.fit_transform(positions)
regions = data['地区'].str.strip('[]').str.replace("'", "").str.split(',', expand=True)
regions.columns = ['region_{}'.format(i) for i in range(regions.shape[1])]
regions = regions.apply(LabelEncoder().fit_transform)
onehot = OneHotEncoder()
regions = onehot.fit_transform(regions)
skills = data['技能'].str.strip('[]').str.replace("'", "").str.split(',', expand=True)
skills.columns = ['skill_{}'.format(i) for i in range(skills.shape[1])]
skills = skills.apply(LabelEncoder().fit_transform)
onehot = OneHotEncoder()
skills = onehot.fit_transform(skills)
from scipy.sparse import hstack,vstack
# 合并数据
。。。。略,请下载完整代码
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X,Y, test_size=0.3, random_state=42)
# 建立决策树模型
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 模型评估
print("Accuracy Score:", accuracy_score(y_test, y_pred))
print("F1 Score:", f1_score(y_test, y_pred, average='macro'))
Accuracy Score: 0.9838167938931298
F1 Score: 0.06426220590235279
以上代码中,我们首先使用pandas库读取result1-2.csv文件,并对预期岗位、地区、技能等属性进行One-hot编码处理,然后划分为训练集和测试集,标签为预期薪资的均值,使用决策树算法建立模型,并对模型进行评估。其中,我们使用了sklearn库中的LabelEncoder、OneHotEncoder、DecisionTreeClassifier等模块,简化了特征处理和模型建立的过程。