TreeSet详解
概述
TreeSet是一个使用你较少的一个Set容器,很多同学可能不知道它是干嘛的,它和HashSet有什么区别,它底层是如何实现的?本篇文章带你全面了解掌握TreeSet
TreeSet介绍
我们知道HashSet是没有顺序的,而TreeSet最大的特点就是一个有顺序的去重集合容器。
- 集合中的元素没有重复
- 集合中的元素不保证插入顺序,而是默认使用元素的自然排序,不过可以自定义排序器
- jdk8以后,集合中的元素不可以是null
- 集合不是线程安全
- 相对于HashSet, 性能更差
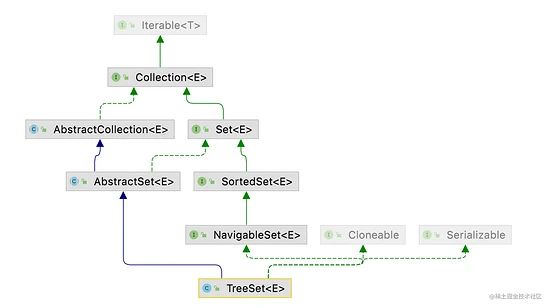
以上是TreeSet的类结构图:
- 实现了NavigableSet接口,意味着它支持一系列的导航方法。比如查找与指定目标最匹配项。
- 继承于AbstractSet,所以它是一个Set集合,具有Set的属性和方法。
- 实现了Cloneable接口,意味着它能被克隆。
- 实现了java.io.Serializable接口,意味着它支持序列化。
构造方法
- TreeSet()
说明: 构造一个空的有序set集合
- TreeSet(Comparator comparator)
说明:构造一个传入排序规则的有序Set集合
- TreeSet(Collection c)
说明:构造一个集合元素为c的有序Set集合
关键方法
Set接口的相关方法不做过多介绍,这边重点介绍下NavigableSet相关的方法。
- public Iterator iterator()
说明: 返回TreeSet的顺序排列的迭代器。因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器。
- public Iterator descendingIterator()
返回TreeSet的逆序排列的迭代器。因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器。
- public int size()
说明:返回TreeSet的大小
- public boolean isEmpty()
说明:返回TreeSet是否为空
- public boolean contains(Object o)
说明:返回TreeSet是否包含对象(o)
- public boolean add(E e)
说明:添加e到TreeSet中
- public boolean remove(Object o)
说明:删除TreeSet中的对象o
- public void clear()
说明:清空TreeSet
- public boolean addAll(Collection c)
说明:将集合c中的全部元素添加到TreeSet中
- public NavigableSet subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive)
说明:返回子Set,实际上是通过TreeMap的subMap()实现的。
- public NavigableSet headSet(E toElement, boolean inclusive)
说明:返回Set的头部,范围是:从头部到toElement,inclusive是是否包含toElement的标志。
- public NavigableSet tailSet(E fromElement, boolean inclusive)
说明:返回Set的尾部,范围是:从fromElement到结尾,inclusive是是否包含fromElement的标志。
- public SortedSet subSet(E fromElement, E toElement)
说明:返回子Set。范围是:从fromElement(包括)到toElement(不包括)。
- public SortedSet headSet(E toElement)
说明:返回Set的头部,范围是:从头部到toElement(不包括)。
- public SortedSet tailSet(E fromElement)
说明:返回Set的尾部,范围是:从fromElement到结尾(不包括)。
- public Comparator comparator()
说明:返回Set的比较器
- public E first()
说明:返回Set的第一个元素
- public E last()
说明:返回Set的最后一个元素
- public E lower(E e)
说明:返回Set中小于e的最大元素
- public E floor(E e)
说明:返回Set中小于/等于e的最大元素
- public E ceiling(E e)
说明:返回Set中大于/等于e的最小元素
- public E higher(E e)
说明:返回Set中大于e的最小元素
- public E pollFirst()
说明:获取第一个元素,并将该元素从TreeMap中删除。
- public E pollLast()
说明:获取最后一个元素,并将该元素从TreeMap中删除。
使用案例
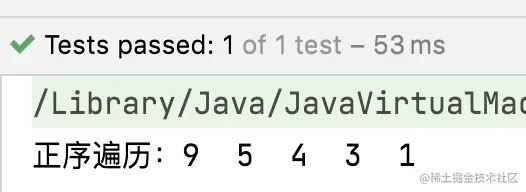
- 验证TreeSet的顺序
@Test
public void test1() {
NavigableSet set = new TreeSet<>();
set.add(5);
set.add(4);
set.add(5);
set.add(3);
set.add(1);
set.add(9);
//正顺序遍历
System.out.print("正序遍历:" );
set.forEach(item -> {
System.out.print(item + " ");
});
System.out.println();
//逆序遍历
System.out.print("逆序遍历:" );
set.descendingIterator().forEachRemaining(item -> {
System.out.print(item + " ");
});
}
复制代码 运行结果:

- 自定义排序器
@Test
public void test2() {
// 自定义排序器
NavigableSet set = new TreeSet<>((o1, o2) -> o2 - o1);
set.add(5);
set.add(4);
set.add(5);
set.add(3);
set.add(1);
set.add(9);
//正顺序遍历
System.out.print("正序遍历:" );
set.forEach(item -> {
System.out.print(item + " ");
});
System.out.println();
}
复制代码 运行结果:
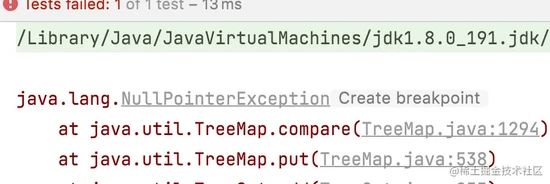
- 是否可以存入null
@Test
public void test3() {
NavigableSet set = new TreeSet<>();
set.add(null);
}
复制代码 运行结果:
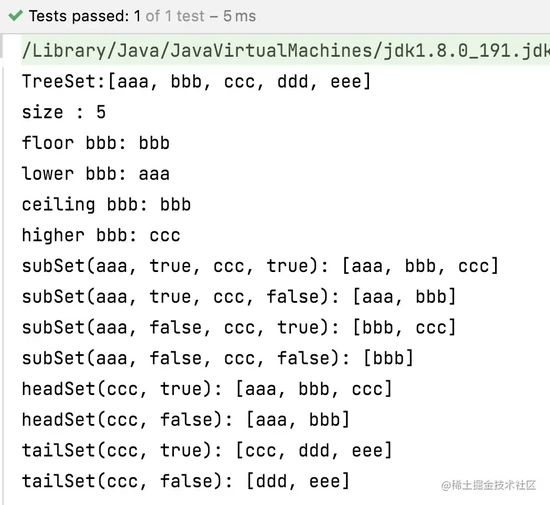
- NavigableSet基本API
@Test
public void test4() {
String val;
// 新建TreeSet
TreeSet tSet = new TreeSet();
// 将元素添加到TreeSet中
tSet.add("aaa");
// Set中不允许重复元素,所以只会保存一个“aaa”
tSet.add("aaa");
tSet.add("bbb");
tSet.add("eee");
tSet.add("ddd");
tSet.add("ccc");
System.out.println("TreeSet:" + tSet);
// 打印TreeSet的实际大小
System.out.printf("size : %d\n", tSet.size());
// 导航方法
// floor(小于、等于)
System.out.printf("floor bbb: %s\n", tSet.floor("bbb"));
// lower(小于)
System.out.printf("lower bbb: %s\n", tSet.lower("bbb"));
// ceiling(大于、等于)
System.out.printf("ceiling bbb: %s\n", tSet.ceiling("bbb"));
// higher(大于)
System.out.printf("higher bbb: %s\n", tSet.higher("bbb"));
// subSet()
System.out.printf("subSet(aaa, true, ccc, true): %s\n", tSet.subSet("aaa", true, "ccc", true));
System.out.printf("subSet(aaa, true, ccc, false): %s\n", tSet.subSet("aaa", true, "ccc", false));
System.out.printf("subSet(aaa, false, ccc, true): %s\n", tSet.subSet("aaa", false, "ccc", true));
System.out.printf("subSet(aaa, false, ccc, false): %s\n", tSet.subSet("aaa", false, "ccc", false));
// headSet()
System.out.printf("headSet(ccc, true): %s\n", tSet.headSet("ccc", true));
System.out.printf("headSet(ccc, false): %s\n", tSet.headSet("ccc", false));
// tailSet()
System.out.printf("tailSet(ccc, true): %s\n", tSet.tailSet("ccc", true));
System.out.printf("tailSet(ccc, false): %s\n", tSet.tailSet("ccc", false));
}
复制代码运行结果:
核心机制
实现机制
TreeSet实际上是TreeMap实现的,底层用到的数据结果是红黑树。当我们构造TreeSet时;若使用不带参数的构造函数,则TreeSet的使用自然比较器;若用户需要使用自定义的比较器,则需要使用带比较器的参数。
总结
与HashSet相比,TreeSet的性能稍低些。add、remove、search等操作时间复杂度为O(log n),按照存储顺序打印n个元素则耗时为O(n)。
如果我们想要按序保存条目,并且按照升序或者降序对集合进行访问和遍历,那么TreeSet就应该作为首选集合。升序方式的操作与视图性能要强于降序方式。