人工智能中的卷积神经网络的入门概念
一、对人工智能、机器学习、深度学习、卷积神经网络的认识:
1. 人工智能
人工智能是计算机科学的一个分支,是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
2. 机器学习
机器学习是人工智能的一种实现手段,它是一类算法的总称,最基本的做法是从数据中挖掘出隐含的规律没然后对真实世界中的时间做出决策和预测。 机器学习大家族按照任务类型的角度,可以分为以下类别: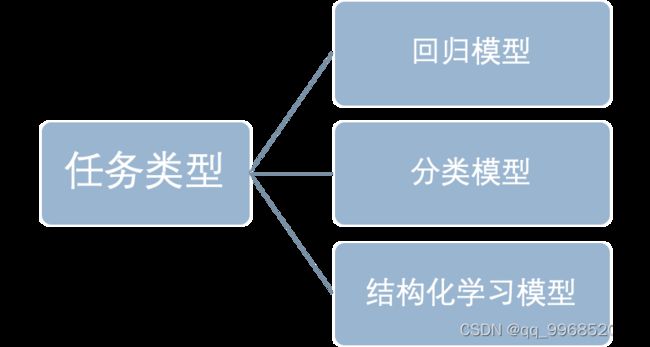 按照学习方式,可分为:
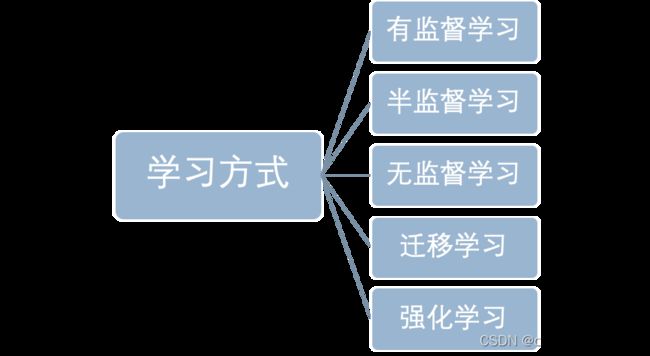
按照学习方式,可分为:
3. 深度学习
深度学习是机器学习的一个分支,源于人工神经网络的研究,模拟人脑进行分析,学习样本数据的内在规律和表示层次。深度学习解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
技术原理:
- 构建一个网络并且随机出实话所有连接的权重。
- 将大量的样本输入到这个网络中。
- 网络处理这些动作并且进行学习。
- 学习完成之后,即得到训练的模型。
4. 卷积神经网络
卷积神经网络是一类包含卷积计算且具有深度解构的潜亏神经网络,是深度学习比较典型的算法。在图像识别、自然语言处理等方向,有很好的表现。
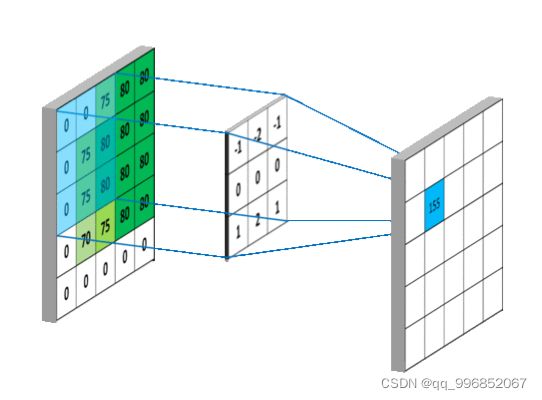
卷积运算示例:
二、神经网络的基础概念
1. 感知机
感知机可以看作是神经网络的起源算法,通过熟悉感知机,从基础去认识神经网络和深度学习。感知机接收多个输入,给出一个输出,不够输出只可能有两个值,0或者1.从物理的角度去看,可以理解成感知机是一个转换系统,接收多个输入信号,输出一个信号,这个输出信号也是只有两种可能,有信号和无信号。
可以通过下图直观理解下: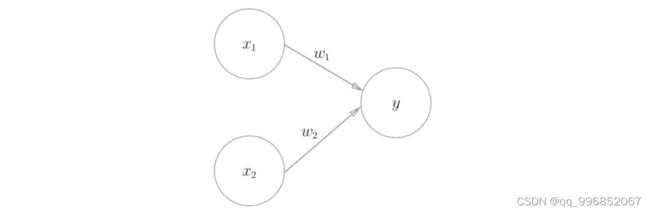
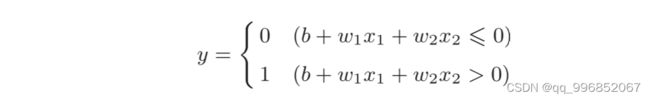
圆形节点就是神经元,图示的感知机有两个输入信号,x1和x2,y是输出信号,w1和w2是权重,b称为偏置,代表神经元容易被激活的程度。输入信号从神经元经过,乘以各自的权重再汇总就到了输出节点y,只有当汇总值超过某个临界值时,y输出1,否则y输出0.输出1的情况下,我们称为神经元被激活,显然,神经元是否容易被激活,很大程度上依赖权重。
从数学角度去看,感知机像是多元函数,显然单层感知机能够解决的问题是线性的,而对于非线性问题,单层感知机是无法解决的。如何利用感知机去解决非线性问题呢?一种是通过多层感知机,上一层的输出作为下一层的输入,对于复杂任务,人工确定权重是非常庞大的任务。我们通过另外一种方式,通过激活函数。
2. 激活函数
激活函数是连接感知机和神经网络的桥梁。刚才感知机的概念时,提到如果输出是1,我们就称为神经元被激活。激活函数就是针对输出的一种处理,让经过线性计算得到的a值,不直接决定输出,而是先经过一个函数h()的处理,再作为输出y,计算过程如下: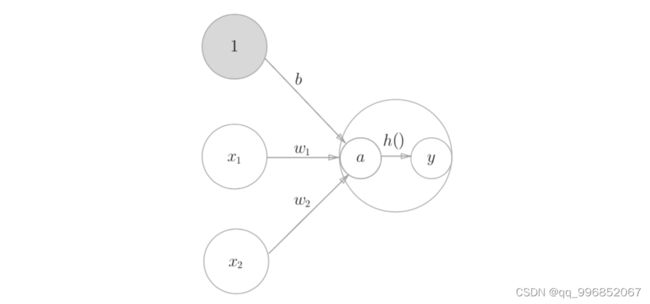
可以这样理解,上面提到的单层感知机使用的激活函数是阶跃函数,而在神经网络中,常用sigmoid函数作为激活函数,表示为: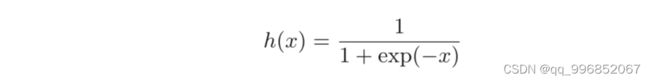
python的实现:
def sigmoid(x):
return 1/(1+np.exp(-x))
感受下阶跃函数和sigmoid函数的图形,虚线是阶跃函数,实线是sigmoid函数: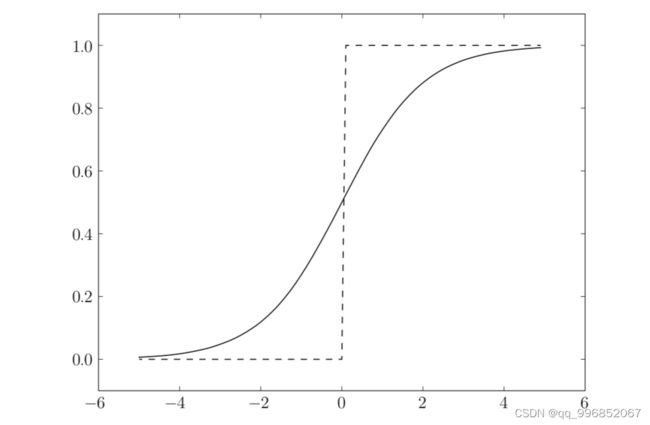
二者相同的是,函数的趋势大体相似,信号值大时输出值倾向于大,而且都在0和1之间。不同的是,使用阶跃函数的感知机只能返回0或1的二元信号,使用sigmoid函数作为激活函数的神经网络中,流动的是连续的实数值信号。
另一个比较流行的激活函数ReLU,在输入大于0时,直接输出该值,在输入小于0时,输出0.ReLU是一个简单的函数,计算效率比较高。
3. 神经网络中的层
对照下图来说明,x1,x2构成了输入层,y1和y2构成输出层,中间的层称为隐藏层,神经网络的隐藏层可以有很多,本图有两个隐藏层,输入层一般不算进层数,算上输出层,一共3层,所以,下图可以看作一个三层的神经网络。对于层数的定义和理解,根据个人偏好可以有不同的叫法和使用。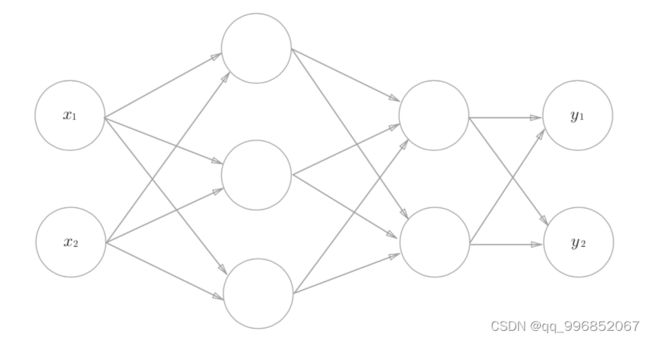
4. 输出层的设计
神经网络可以用在回归问题和分类问题上,要根据问题的性质来选取最后一个隐藏层(输出层的前一层)的激活函数,一般回归问题用恒等函数,分类问题用softmax函数。 输出层的神经元数量,需要根据要解决的问题来决定。对于分类问题梦一般设定为类别数量。
5. 矩阵计算
不同层的神经元之间的数据流动,通过使用NumPy来执行计算,是一种高效的方式。NumPy的广播功能非常强大,相比于单个节点的计算,NumPy可以很方便的对矩阵中的数据进行批量计算。
比如下面的例子:
可以看出,NumPy的array中的元素,每一项都进行了+1的操作。这对神经网络的计算是有很大的效率提升的,借助NumPy的庞大数值计算能力,对于同一层的神经元,可以以一个array的方式执行一次计算即可,不用每个节点单独计算。
6. 神经网络的学习
神经网络的特征就是可以从数据中学习,所谓“从数据中学习”,是指可以由数据自动决定权重参数的值。数据是机器学习的根源,从数据中寻找答案、从数据中发现模式。 以手写数字的识别为例,对比下不同的方式,得出结论的过程。
- 1)如果是人自己去识别数字,通过人的大脑这一黑盒去思考,直接给出答案,可以看成是端到端的识别。
- 2)如果是通过机器学习的方式去实现,在输入数字图像后,首先要经过特征量去抽象,然后再通过机器学习的决策树等算法去给出识别决策,再给出结果。
- 3)如果是用神经网络去解决,和人脑的识别类似,也是经过一个黑盒的“思考”,然后给出答案,也可以看成端到端的过程。
7. 训练数据和测试数据
首先使用训练数据进行学习,寻找最优的参数;然后使用测试数据去评价训练得到的模型的实际能力。我们将数据分为训练数据和测试数据,目的是追求模型的泛化能力。否则,对于训练过的数据,模型的预测结果比较好,但是对于模型没见过的数据,预测的能力就比较差,这显然不是我们想要的结果,我们希望模型在学习了已知的数据之后,去解决未知的问题。
8. 泛化能力
泛化能力是指处理未被观察过的数据(不包含在训练数据中)的能力。获得泛化能力是机器学习的最终目标。比如手写体识别,这里的目标不是识别特定的某个人写的特定的文字,而是任意一个人写的任意文字,如果系统只能正确的识别已有的训练数据,那有可能是只学习到了训练数据中的个人的习惯写法。
9. 过拟合
只对某个数据集过度拟合的状态称为过拟合,避免过拟合也是机器学习的一个重要课题,如果仅仅用一个数据集去学习和评价参数,那么就可能发生可以顺利处理某个数据集,但是无法处理其他数据集情况。
10. 损失函数
神经网络以某个指标为线索,寻找最优的权重参数,这个指标称为损失函数,损失函数是表示神经网络性能优劣的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。
为什么不使用识别精度而是使用损失函数的方式,去评价模型的性能呢?原因在于,精度对微小的参数变化基本上没有什么反应,即便有反应,它的值也是突然的、不连续的变化,神经网络的学习无法进行。也就是说,仅仅微调参数,是无法改善识别精度的。即便识别精度有所改变,他的值也不会连续变化,而是变为不连续的、离散的值。而如果把损失函数作为指标,则当前损失函数的值,可以表示为连续的实数,参数稍微有改变,损失函数都可以该感知到。 损失函数一般选取均方误差,或交叉熵误差函数。
至此,我们把神经网络的训练问题,抽象成了寻找损失函数的最小值问题。寻找最小值,在数学上的解决方案,借助于梯度。
11. 梯度
理解梯度的概念,先从导数的概念开始,导数体现了函数在某个点处,变化的趋势和速率。相对于函数的值受到一个变量影响的情况,如果函数的值受到多个变量的影响,那么在某一点处,每个变量的变化,对函数值的变化趋势的影响程度是不一样的,把函数值对每个变量求导,会得到每个变量的偏导数,由全部变量的偏导数汇总而成的向量,成为梯度。梯度指示的方向是函数值减小最多的方向,如果要找到函数的最小值,就需要沿着梯度的方向去更新参数,最终找到使损失函数最小的参数集合,对于简单函数这在理论上可以行得,但是对于复杂的情况,对于某些局部,梯度方向不一定会引导向全局的最小值,这就需要其他的方式,跳出局部的限制,力求寻找到全局最优解。