Java详解LeetCode1~300题之003无重复字符的最长子串

题目描述
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。

来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/longest-substring-without-repeating-characters
解法一 穷举
简单粗暴些,找一个最长子串,那么我们用两个循环穷举所有子串,然后再用一个函数判断该子串中有 没有重复的字符。
public int lengthOfLongestSubstring(String s) {
int n = s.length();
int ans = 0;
for (int i = 0; i < n; i++)
for (int j = i + 1; j <= n; j++)
if (allUnique(s, i, j)) ans = Math.max(ans, j - i);
return ans;
}
public boolean allUnique(String s, int start, int end) {
Set set = new HashSet<>();
for (int i = start; i < end; i++) {
Character ch = s.charAt(i);
if (set.contains(ch)) return false;
set.add(ch);
}
return true;
} 时间复杂度:两个循环,加上判断子串满足不满足条件的函数中的循环,O(n³)。 空间复杂度:使用了一个 set,判断子串中有没有重复的字符。由于 set 中没有重复的字符,所以最 长就是整个字符集,假设字符集的大小为 m ,那么 set 最长就是 m 。另一方面,如果字符串的长 度小于 m ,是 n 。那么 set 最长也就是 n 了。综上,空间复杂度为 O(min(m,n))。
解法二 滑动窗口
遗憾的是上边的算法没有通过 leetCode,时间复杂度太大,造成了超时。我们怎么来优化一下呢?
上边的算法中,我们假设当 i 取 0 的时候,
j 取 1,判断字符串 str[0,1) 中有没有重复的字符。
j 取 2,判断字符串 str[0,2) 中有没有重复的字符。
j 取 3,判断字符串 str[0,3) 中有没有重复的字符。
j 取 4,判断字符串 str[0,4) 中有没有重复的字符。
做了很多重复的工作,因为如果 str[0,3) 中没有重复的字符,我们不需要再判断整个字符串 str[0,4) 中有没有重复的字符,而只需要判断 str[3] 在不在 str[0,3) 中,不在的话,就表明 str[0,4) 中没有重复的字符。
如果在的话,那么 str[0,5) ,str[0,6) ,str[0,7) 一定有重复的字符,所以此时后边的 j 也不需要继续增加了。i ++ 进入下次的循环就可以了。
此外,我们的 j 也不需要取 j + 1,而只需要从当前的 j 开始就可以了。
综上,其实整个关于 j 的循环我们完全可以去掉了,此时可以理解变成了一个「滑动窗口」。
判断一个字符在不在字符串中,我们需要可以遍历整个字符串,遍历需要的时间复杂度就是 O(n), 加上最外层的 i 的循环,总体复杂度就是 O(n²)。我们可以继续优化,判断字符在不在一个字符 串,我们可以将已有的字符串存到 Hash 里,这样的时间复杂度是 O(1),总的时间复杂度就变成了 O(n)。
public class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length();
Set set = new HashSet<>();
int ans = 0, i = 0, j = 0;
while (i < n && j < n) {
if (!set.contains(s.charAt(j))){
set.add(s.charAt(j++));
ans = Math.max(ans, j - i);
}
else {
set.remove(s.charAt(i++));
}
}
return ans;
}
}
时间复杂度:在最坏的情况下,while 循环中的语句会执行 2n 次,例如 abcdefgg,开始的时候 j 一直后移直到到达第二个 g 的时候固定不变 ,然后 i 开始一直后移直到 n ,所以总共执行了 2n 次,时间复杂度为 O(n)。
空间复杂度:和上边的类似,需要一个 Hash 保存子串,所以是 O(min(m,n))。
解法三 Map
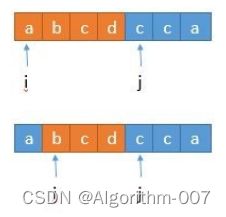
当 j 指向的 c 存在于前边的子串 abcd 中,此时 i 向前移到 b ,此时子串中仍然含有 c,还得 继续移动,所以这里其实可以优化。我们可以一步到位,直接移动到子串 c 的位置的下一位!
实现这样的话,我们将 set 改为 map ,将字符存为 key ,将对应的下标存到 value 里就实现 了。
public class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length(), ans = 0;
Map map = new HashMap<>();
for (int j = 0, i = 0; j < n; j++) {
if (map.containsKey(s.charAt(j))) {
i = Math.max(map.get(s.charAt(j)), i);
}
ans = Math.max(ans, j - i + 1);
map.put(s.charAt(j), j + 1);
}
return ans;
}
} 与解法二相比
由于采取了 i 跳跃的形式,所以 map 之前存的字符没有进行 remove ,所以 if 语句中进行了 Math.max ( map.get ( s.charAt ( j ) ) , i ),要确认得到的下标不是 i 前边的。
还有个不同之处是 j 每次循环都进行了自加 1 ,因为 i 的跳跃已经保证了 str[ i , j] 内没有重复的字符串,所以 j 直接可以加 1 。
而解法二中,要保持 j 的位置不变,因为不知道和 j 重复 的字符在哪个位置。
最后个不同之处是, ans 在每次循环中都进行更新,因为 ans 更新前 i 都进行了更新,已经保证 了当前的子串符合条件,所以可以更新 ans 。
而解法二中,只有当当前的子串不包含当前的字符时, 才进行更新。
时间复杂度:我们将 2n 优化到了 n ,但最终还是和之前一样,O(n)。
空间复杂度:也是一样的,O(min(m,n))。
解法四 巧用ASCLL码
和解法三思路一样,区别的地方在于,我们不用 Hash ,而是直接用数组,字符的 ASCII 码值作为 数组的下标,数组存储该字符所在字符串的位置。
适用于字符集比较小的情况,因为我们会直接开辟和 字符集等大的数组。
public class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length(), ans = 0;
int[] index = new int[128];
for (int j = 0, i = 0; j < n; j++) {
i = Math.max(index[s.charAt(j)], i);
ans = Math.max(ans, j - i + 1);
index[s.charAt(j)] = j + 1;
}
return ans;
}
}和解法 3 不同的地方在于,没有了 if 的判断,因为如果 index[ s.charAt ( j ) ] 不存在的 话,它的值会是 0 ,对最终结果不会影响。
时间复杂度:O(n)。
空间复杂度:O(m),m 代表字符集的大小。这次不论原字符串多小,都会利用这么大的空间。