python包--pandas的用法(最全pandas的用法--数据处理十分有用,后面会一直更新)
文章目录
-
- 1. pandas简介
- 2. pandas 用法
-
- 2.1 pandas的数据格式
- 2.2 数据的导入和自生成数据
- pandas的行列数据的获取
- pandas 条件筛选数据
- pandas数据的数据处理
- pandas 缺失值,重复(异常值)等的处理
-
- 缺失值的处理
- 补充(数据相关性的计算)以及显著性检验
1. pandas简介
pandas是一个是一个python包,可以很大程度上加快我们对数据的处理。花费时间把这个包平常经常用到的函数整理一下,方便大家,也方便自己使用。
2. pandas 用法
2.1 pandas的数据格式
在使用pandas前需要了解pandas的两种数据格式:
pandas的处理主要包含两种数据格式series和dataFrame。
- series的用法
- dataFrame的用法
2.2 数据的导入和自生成数据
- 从excel中读取数据(当然也可以从其他格式的文件中读入数据)
import pandas as pd #导入pandas库
excel_file = './try.xlsx' #导入excel数据
data = pd.read_excel(excel_file, index_col='姓名')
#这个的index_col就是index,可以选择任意字段作为索引index,读入数据
print(data.loc['李四'])
- 自生成数据(用于测试), 接下来这个数据就用来测试
# 先构建一个dataFrame
f = {'one': [1, 2, 3, 4], "two": [4, 5, 6, 7]}
df = pd.DataFrame(f, index=["a", "b", "c", "d"])
数据如下:

- 使用numpy生成数据
numpy生成数据
pandas的行列数据的获取
# pd.columns 获取行数据
# pd.index 获取列数据
# pd.loc 条件筛选
#pandas 获取行列数据
# 获取行数据
print(df)
print(list(df.loc["a"]))
# 获取列数据
print(list(df.one))
print(df["one"])
# 获取指定行列的值 (行,列)
print(df.loc["a", "one"]) # 这种好用一点
print(df.loc["a"].one) # 获取('a', 'one')对应的值
# iloc 用数字获取行列值
print(df.iloc[:, 0]) # 获取第一列的数据
print(df.iloc[0, :]) # 获取第一行的数据
print(df.iloc[0:2, 0:2]) # 获取第一二行,第一二列的数据
# 获取特定的行列数据
print(df.loc[:, ['one','two']) # 获取one 和two的两列数据
print(df.loc[['a', 'c'], :]) # 获取'a'和 'c'的两行数据
pandas 条件筛选数据
&: 表示和, |: 表示或
# 行筛选------
# 单一条件筛选
big_2 = df[df.one > 1] # 筛选出‘one’ 这一列大于1 ----之后的dataFrame
# 多条件筛选
among_ = df[(df.one > 1) & (df['two'] < 6)] # 筛选出‘one’ 这一列大于1, 并且‘two’列小于6 -----之后的dataFrame
# 列筛选
df_T = df.T # 转置dataFrame
# 将dataFrame 进项转置之后按照行的筛选方式就可以了
pandas数据的数据处理
- 数据求平均值、和
#求行的平均值、和
print(df.mean(axis=1))
df["平均值"] = df.apply(lambda x: x.mean(), axis=1) # 或者直接在dataFrame上修改,添加行平均值
df["总和"] = df.apply(lambda x: x.sum(), axis=1) # 或者直接在dataFrame上修改,添加行和
# 求列的平均值、和
print(df.mean(axis=0))
df.loc["列总和"] =df_pt.apply(lambda x:x.mean()) # 或者直接在dataFrame上修改,添加列平均值
df.loc["列总和"] =df_pt.apply(lambda x:x.sum()) # 或者直接在dataFrame上修改,添加列和
数据融合
pandas 缺失值,重复(异常值)等的处理
缺失值的处理
df.dropna(): 删除dataFrame的缺失值, 其重要参数如下
- axis: axis=0时,过滤所有为NaN的行, axis=1时过滤所有为NaN的列, 默认axis=0
- how:(any,all) any: 只要行或者列出现了一个NaN值,则该行或列全部过滤掉; all: 该行或列,全部为NaN值时,才过滤该行或列。 默认为any
- inplace:(bool值)inplace=True,在原数据上直接做更改; 默认为false
# 给原始的dataframe设置NaN值 (记得导入numpy的包)
import numpy as np
df.loc['a', 'one'] = np.NaN
df.loc['a', 'two'] = np.NaN
df.loc['d', 'two'] = np.NaN
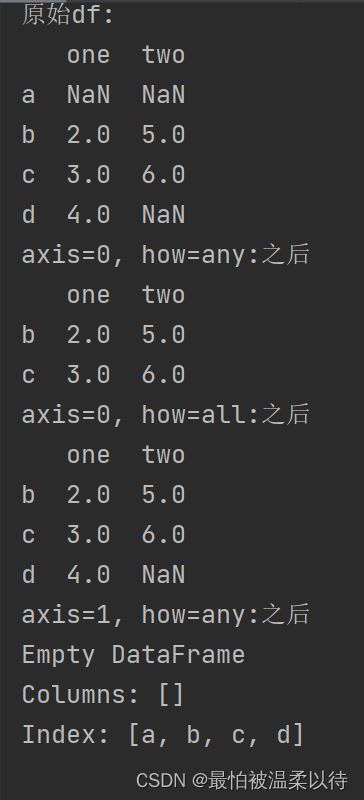
df_1 = df.dropna(axis=0, how='any')
print('axis=0, how=any:之后')
print(df_1)
df_2 = df.dropna(axis=0, how='all')
print('axis=0, how=all:之后')
print(df_2)
df_3 = df.dropna(axis=1, how='any')
print('axis=1, how=any:之后')
print(df_3)
输出结果对应如下图:
补充(数据相关性的计算)以及显著性检验
在计算相关性和显著性检验时候,method有三个参数: pearson, kendall, spearman。
# 计算某两列或者多列之间的相关性
corr = df.loc[:, ['one', 'two'].corr(method="spearman") # 计算某两列数据的相关性, 如果是多组数据,在列表中添加值就可以了
# 计算整个表的相关性
corr = pd.DataFrame.corr(df, method="spearman")
# 显著性检验 ()
x = [1,2,3,4,5,6]
y = [2,2,2,2,3,4]
correlation, p-value = scipy.stats.pearsonr(x, y)
correlation, p-value = scipy.stats.spearmanr(x, y)
correlation, p-value = scipy.stats.kendalltau(x, y)