【视频分割】【深度学习】MiVOS官方Pytorch代码--Propagation模块PropagationNet网络解析
【视频分割】【深度学习】MiVOS官方Pytorch代码–Propagation模块PropagationNet网络解析
MiVOS模型将交互到掩码和掩码传播分离,从而实现更高的泛化性和更好的性能。单独训练的交互模块将用户交互转换为对象掩码,传播模块使用一种新的top-k过滤策略在读取时空存储器时进行临时传播,本博客将讲解Propagation(用户交互产生分割图)模块的深度网络代码,Propagation模块封装了PropagationNet和FusionNet模型。

文章目录
- 【视频分割】【深度学习】MiVOS官方Pytorch代码--Propagation模块PropagationNet网络解析
- 前言
- PropagationNetwork类
-
- __init__函数
- Memory Encoder
- Query Encoder
- Decoder
- EvalMemoryReader类
- Decoder类
- modules.py
-
- MaskRGBEncoder类
- RGBEncoder类
- KeyValue类
- 总结
前言
在详细解析MiVOS代码之前,首要任务是成功运行MiVOS代码【win10下参考教程】,后续学习才有意义。
本博客讲解Propagation模块的深度网络(PropagationNetwork)代码,不再复述其他功能模块代码。
MiVOS原论文中关于Propagation Module的示意图:
关键帧是用户在某一帧有交互行为,传播帧是根据这些交互行为而需要改变的帧。
PropagationNetwork类
在model/propagation/prop_net.py内
__init__函数
def __init__(self, top_k=50):
super().__init__()
# Memory Encoder过程的主干网络
self.mask_rgb_encoder = MaskRGBEncoder()
# Query Encoder过程的主干网络
self.rgb_encoder = RGBEncoder()
# 主干网络+Memory KeyValue网络=>Memory Encoder的key和value
self.kv_m_f16 = KeyValue(1024, keydim=128, valdim=512)
# 主干网络+Query KeyValue网络=>Query Encoder的key和value
self.kv_q_f16 = KeyValue(1024, keydim=128, valdim=512)
# 获得Memory Encoder中前top_k有价值的value
self.memory = EvalMemoryReader(top_k, km=None)
# 获得原始图像的注意区域
self.attn_memory = AttentionMemory(top_k)
# 上采样Decoder获得mask,正确区分背景和多个目标前景
self.decoder = Decoder()
Memory Encoder
memorize方法是Memory Encoder过程,mask_rgb_encoder是主干网络,kv_m_f16是编码网络。通过原始图片、mask以及other获得Memory key/value,mask是由S2M生成。
def memorize(self, frame, masks):
k, _, h, w = masks.shape # [k, 1, h, w]
# 扩展图片batchsize-->1到k [k,3,h,w]
frame = frame.view(1, 3, h, w).repeat(k, 1, 1, 1)
# Compute the "others" mask
if k != 1:
others = torch.cat([
torch.sum(
masks[[j for j in range(k) if i != j]], dim=0, keepdim=True) # 计算除了i以外的其他k-1个obj mask的和,并在0维拼接
for i in range(k)], 0) # [k, 1, h, w]
else:
others = torch.zeros_like(masks)
f16 = self.mask_rgb_encoder(frame, masks, others) # 数字16代表下采样后特征图为原图大小1/16
k16, v16 = self.kv_m_f16(f16) # [k, channel(k128 v512), H/16, W/16]
return k16.unsqueeze(2), v16.unsqueeze(2) # [k, channel(k128 v512), 1, h, w ]
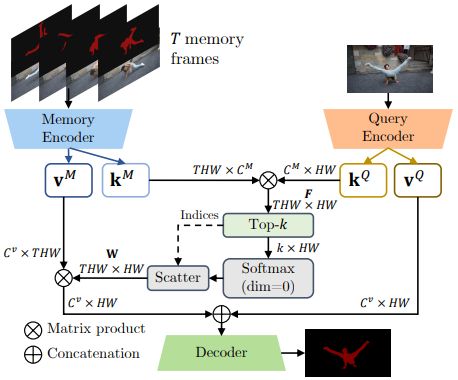
Memory Encoder过程在论文原图中所示:

T存放着所有关键帧和已传播完成帧的Memory key/value,已传播完成帧指的根据关键帧信息完成PropagationNet和FusionNet完整过程的帧。
Memory Encoder的详细过程示意图如下所示:
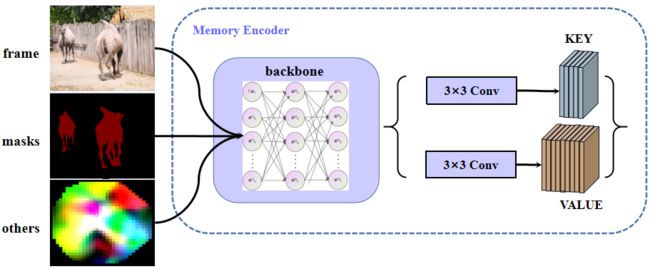
这里的other图只是随机生成的示意图,只是为了方便说明,并不是真在根据masks计算得出
Query Encoder
get_query_values方法是Query Encoder过程,rgb_encoder是主干网络,kv_q_f16是编码网络。通过原始图片获得Query key/value。
def get_query_values(self, frame):
f16, f8, f4 = self.rgb_encoder(frame)
k16, v16 = self.kv_q_f16(f16)
return f16, f8, f4, k16, v16
Query Encoder过程在论文原图中所示:
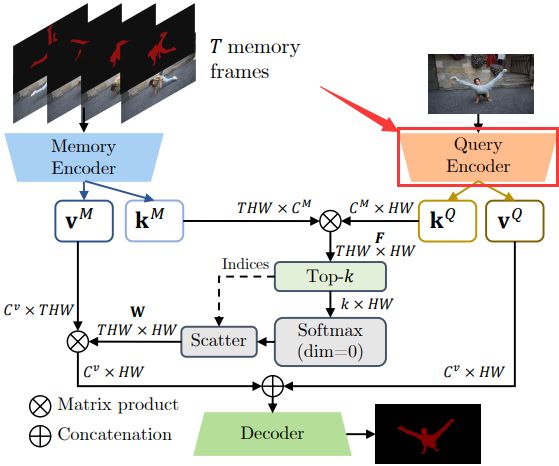
Query Encoder仅用于当前传播帧,传播完成后变为已传播完成帧,就需要Memory Encoder存到T
Query Encoder的详细过程示意图如下所示:

Query只有一个,Memory 有T个,具体请查看博文【Propagation功能模块】
Decoder
首先需要memory方法为所有目标k分别获取加权处理Memory value后有价值的特征并结合Query value,而后与rgb_encoder主干网络生成的中间浅层特征一起进行decoder解码过程获得最终的mask。
def segment_with_query(self, keys, values, f16, f8, f4, k16, v16):
k = keys.shape[0]
# Do it batch by batch to reduce memory usage
batched = 1
m4 = torch.cat([
self.memory(keys[i:i+batched], values[i:i+batched], k16) for i in range(0, k, batched)
], 0) # [k,C,H,W] C:channel
v16 = v16.expand(k, -1, -1, -1) # expand必须有一个维度的值为1
m4 = torch.cat([m4, v16], 1)
return torch.sigmoid(self.decoder(m4, f8, f4))
segment_with_query过程在论文原图中所示:
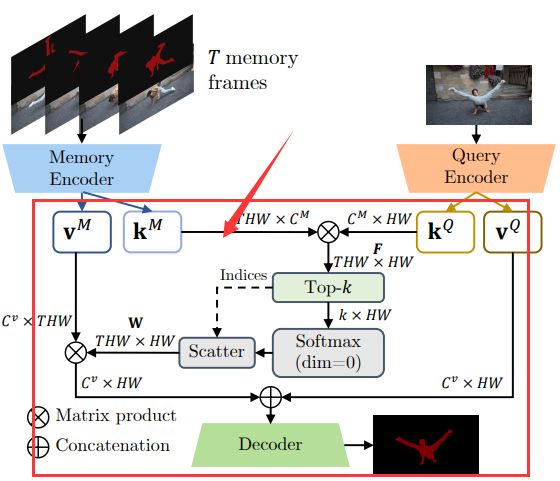
Memory value和Query value结合详细过程如下图所示:
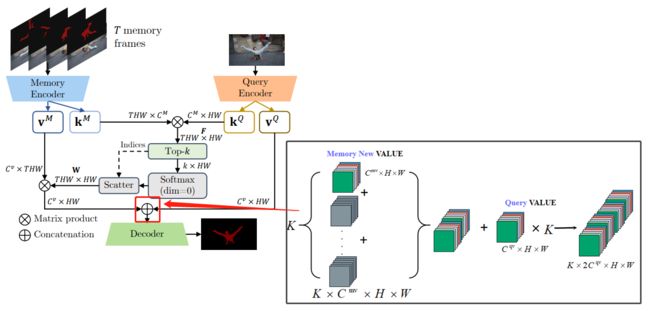
EvalMemoryReader类
通过Memory key特征和Query key特征计算得到weight map(权重图)【个人理解】,然后Memory value和weight map做加权获得新的Memory new value特征。
class EvalMemoryReader(nn.Module):
def __init__(self, top_k, km):
super().__init__()
self.top_k = top_k # 选取相似度最近的top50
self.km = km
def forward(self, mk, mv, qk):
B, CK, T, H, W = mk.shape # B是1,即当前的obj类的key/value T是memory中已存的图片数
_, CV, _, _, _ = mv.shape
mi = mk.view(B, CK, T*H*W).transpose(1, 2) # [B,THW,CK]
qi = qk.view(1, CK, H*W).expand(B, -1, -1) / math.sqrt(CK) # [B,CK,HW]
affinity = torch.bmm(mi, qi) # 矩阵相乘 [B,THW,HW] shape只能是3维
# --------源码没有使用
if self.km is not None:
# Make a bunch of Gaussian distributions
argmax_idx = affinity.max(2)[1]
y_idx, x_idx = argmax_idx//W, argmax_idx%W
g = make_gaussian(y_idx, x_idx, H, W, sigma=self.km)
g = g.view(B, T*H*W, H*W)
affinity = softmax_w_g_top(affinity, top=self.top_k, gauss=g) # [B,THW,HW]
# --------
else:
if self.top_k is not None:
affinity = softmax_w_g_top(affinity, top=self.top_k, gauss=None) # mv特征图的权重[B,THW,HW]
else:
affinity = F.softmax(affinity, dim=1)
mo = mv.view(B, CV, T*H*W) # [B,CV,THW]
mem = torch.bmm(mo, affinity) # [B, CV, HW]
mem = mem.view(B, CV, H, W)
return mem
EvalMemoryReader详细过程如下图所示:

weight map(权重图)是所有Memory key 和当前传播的帧Query key矩阵相乘计算而来,而后加权到所有Memory value获得新的Memory new value。FusionNet也有一部类似的操作,注意区分。
生成Memory value特征的weight map(权重图)的代码,权重图仅保留top-50的权重,其他置零。
def softmax_w_g_top(x, top=None, gauss=None):
# x[B,THW,HW]
if top is not None:
# ----源码未使用部分
if gauss is not None:
maxes = torch.max(x, dim=1, keepdim=True)[0]
x_exp = torch.exp(x - maxes)*gauss
x_exp, indices = torch.topk(x_exp, k=top, dim=1)
# -----
else:
values, indices = torch.topk(x, k=top, dim=1) #在THW 选择前top个的(值,索引)的元组
x_exp = torch.exp(values - values[:, 0]) # e^v
x_exp_sum = torch.sum(x_exp, dim=1, keepdim=True) # 求和之后这个dim的元素个数为1,所以要被去掉,如果要保留这个维度,则应当keepdim=True
x_exp /= x_exp_sum # x_exp 归一化
# The types should be the same already
# some people report an error here so an additional guard is added
x.zero_().scatter_(1, indices, x_exp.type(x.dtype)) # 用x_exp[B,THW,HW]
output = x
else:
maxes = torch.max(x, dim=1, keepdim=True)[0]
if gauss is not None:
x_exp = torch.exp(x-maxes)*gauss
x_exp_sum = torch.sum(x_exp, dim=1, keepdim=True)
x_exp /= x_exp_sum
output = x_exp
return output
Decoder类
Decoder通过rgb_encoder主干网络生成的中间浅层特征f8/f4,以及处理合并Memory value和Query value的特征f16共同生成mask。
Decoder
class Decoder(nn.Module):
def __init__(self):
super().__init__()
self.compress = ResBlock(1024, 512)
self.up_16_8 = UpsampleBlock(512, 512, 256) # 1/16 -> 1/8
self.up_8_4 = UpsampleBlock(256, 256, 256) # 1/8 -> 1/4
self.pred = nn.Conv2d(256, 1, kernel_size=(3, 3), padding=(1, 1), stride=1)
def forward(self, f16, f8, f4):
x = self.compress(f16)
x = self.up_16_8(f8, x)
x = self.up_8_4(f4, x)
x = self.pred(F.relu(x))
x = F.interpolate(x, scale_factor=4, mode='bilinear', align_corners=False)
return x
网络结构如下图所示:
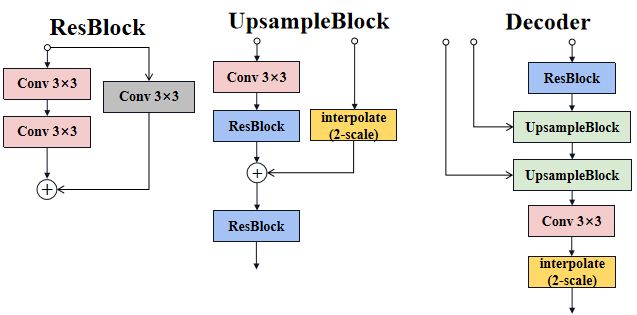
ResBlockh和UpsampleBlock代码位置model/propagation/modules.py
ResBlock模块
class ResBlock(nn.Module):
def __init__(self, indim, outdim=None):
super(ResBlock, self).__init__()
if outdim == None:
outdim = indim
if indim == outdim:
self.downsample = None
else:
self.downsample = nn.Conv2d(indim, outdim, kernel_size=3, padding=1)
self.conv1 = nn.Conv2d(indim, outdim, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(outdim, outdim, kernel_size=3, padding=1)
def forward(self, x):
r = self.conv1(F.relu(x))
r = self.conv2(F.relu(r))
if self.downsample is not None:
x = self.downsample(x)
return x + r
UpsampleBlock模块
class UpsampleBlock(nn.Module):
def __init__(self, skip_c, up_c, out_c, scale_factor=2):
super().__init__()
self.skip_conv1 = nn.Conv2d(skip_c, up_c, kernel_size=3, padding=1)
self.skip_conv2 = ResBlock(up_c, up_c)
self.out_conv = ResBlock(up_c, out_c)
self.scale_factor = scale_factor
def forward(self, skip_f, up_f):
x = self.skip_conv2(self.skip_conv1(skip_f))
x = x + F.interpolate(up_f, scale_factor=self.scale_factor, mode='bilinear', align_corners=False)
x = self.out_conv(x)
return x
modules.py
在model/propagation目录下
MaskRGBEncoder类
采用了resnet50网络,是Memory Encoder过程的主干网络。
这里的resnet50输入channels是5,不是3
class MaskRGBEncoder(nn.Module):
def __init__(self):
super().__init__()
resnet = mod_resnet.resnet50(pretrained=True, extra_chan=2)
self.conv1 = resnet.conv1
self.bn1 = resnet.bn1
self.relu = resnet.relu # 1/2, 64
self.maxpool = resnet.maxpool # 1/4, 64
self.layer1 = resnet.layer1 # 1/4, 256
self.layer2 = resnet.layer2 # 1/8, 512
self.layer3 = resnet.layer3 # 1/16, 1024
def forward(self, f, m, o):
f = torch.cat([f, m, o], 1)
x = self.conv1(f)
x = self.bn1(x)
x = self.relu(x) # 1/2, 64
x = self.maxpool(x) # 1/4, 64
x = self.layer1(x) # 1/4, 256
x = self.layer2(x) # 1/8, 512
x = self.layer3(x) # 1/16, 1024
return x
RGBEncoder类
采用了resnet50网络,是Query Encoder过程的主干网络。
class RGBEncoder(nn.Module):
def __init__(self):
super().__init__()
resnet = models.resnet50(pretrained=True)
self.conv1 = resnet.conv1
self.bn1 = resnet.bn1
self.relu = resnet.relu # 1/2, 64
self.maxpool = resnet.maxpool # 1/4, 64
self.res2 = resnet.layer1 # 1/4, 256
self.layer2 = resnet.layer2 # 1/8, 512
self.layer3 = resnet.layer3 # 1/16, 1024
def forward(self, f):
x = self.conv1(f)
x = self.bn1(x)
x = self.relu(x) # 1/2, 64
x = self.maxpool(x) # 1/4, 64
f4 = self.res2(x) # 1/4, 256
f8 = self.layer2(f4) # 1/8, 512
f16 = self.layer3(f8) # 1/16, 1024
return f16, f8, f4
KeyValue类
编码网络,key用于评估当前帧和之前帧的相似性,value用来生成最后mask精细结果信息。
class KeyValue(nn.Module):
def __init__(self, indim, keydim, valdim):
super().__init__()
self.key_proj = nn.Conv2d(indim, keydim, kernel_size=3, padding=1)
self.val_proj = nn.Conv2d(indim, valdim, kernel_size=3, padding=1)
def forward(self, x):
return self.key_proj(x), self.val_proj(x)
总结
尽可能简单、详细的介绍MiVOS中Propagation模块中PropagationNetwork网络的代码。后续会讲解Propagation中FusionNet网络代码以及MiVOS的训练。