mysql 删除重复_MySQL查询和删除重复记录
在工作中,我们经常会发现表中会存在重复数据,那么如何找出和删除这些数据呢?
下面,以一个小例子来说明:
1、创建学生表
1 CREATE TABLEstudent(2 id INT PRIMARY KEY,3 stuno VARCHAR(12) NOT NULL,4 stuname VARCHAR(30) NOT null
5 );
2、向学生表中插入数据
1 INSERT INTO student VALUES ('1','131111099','小李');2 INSERT INTO student VALUES ('2','131111100','小陈');3 INSERT INTO student VALUES ('3','131111101','小王');4 INSERT INTO student VALUES ('4','131111102','小黑');5 INSERT INTO student VALUES ('5','131111099','小曹');6 INSERT INTO student VALUES ('6','131111099','小李');
3、查找仅学号重复的记录
从插入记录上看,id为1、5、6的记录学号都是相同的,那么验证一下查询的数据是否正确
1 --学号重复
2 --先按学号进行分组,然后查询学数量 > 1的记录的学号
3 SELECT * FROM student WHERE stuno IN(4 --查找重复的学号
5 SELECT stuno FROM student GROUP BY stuno HAVING COUNT(stuno) > 1
6 );
查询结果如下:

查询结果和我们事先分析的数据一致,所以查询结果是正确的。
4、查找学号和姓名均重复的记录
从插入记录上看,只有id为1、6的记录学号和姓名是完全重复的,那么验证一下查询的数据是否正确
1 --学号和姓名均重复
2 SELECT * FROM student WHERE (stuno,stuname) --注意:此处一定要加括号,当成联合字段来处理
3 IN(4 --查找学号和姓名均重复的学生信息
5 SELECT stuno,stuname FROM student GROUP BY stuno,stuname HAVING COUNT(1) > 1
6 );
查询结果如下:

查询结果和我们事先分析的数据一致,所以查询结果是正确的。
5、删除多余的重复记录(多个字段),只保留最小id的记录
重复记录可能有多条,但是我们只希望保留id最小的那条记录,因为学号和姓名均重复的只有id为1、6的记录,保留id为1的记录,那么验证一下查询的数据是否正确
1 --删除多余的重复记录(多个字段),只保留最小id的记录
2 DELETE FROM student WHERE id IN(3 SELECT * FROM(4 SELECT id FROM student WHERE (stuno,stuname) --注意:此处一定要加括号,当成联合字段来处理
5 IN(6 --查找学号和姓名均重复的学生信息
7 SELECT stuno,stuname FROM student GROUP BY stuno,stuname HAVING COUNT(1) > 1
8 ) AND id NOT IN(9 --查询最小id的记录
10 SELECT MIN(id) FROM student GROUP BY stuno,stuname HAVING COUNT(1) > 1
11 )12 ) ASstu_repeat_copy13
14 );
查询结果如下:
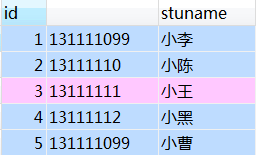
可以看出,id为6的记录已经被删除了,所以结果正确
警告:不能根据本表的查询结果来更新本表的数据
在其它的帖子中有看到如下写法来删除重复数据:
1 DELETE FROM student WHERE (stuno,stuname) --注意:此处一定要加括号,当成联合字段来处理
2 IN(3 --查找学号和姓名均重复的学生信息
4 SELECT stuno,stuname FROM student GROUP BY stuno,stuname HAVING COUNT(1) > 1
5 ) AND id NOT IN(6 --查询最小id的记录
7 SELECT MIN(id) FROM student GROUP BY stuno,stuname HAVING COUNT(1) > 1
8 );
会报如下错误:
[Err] 1093 - You can't specify target table 'student' for update in FROM clause