【SpringCloud】Dubbo中分布式事务Seata解决方案
背景
目前开发的项目是分布式架构的,数据库也是分开的,各个子工程之间是通过dubbo调用,由于没有考虑分布式事务的问题,导致接口出错回滚时,调用端正常回滚了但是被调用端却不能回滚,产生了很多垃圾数据。
演示场景

这里创建三个模块,消费者,暴露接口,提供者。
暴露接口

用户服务更新积分
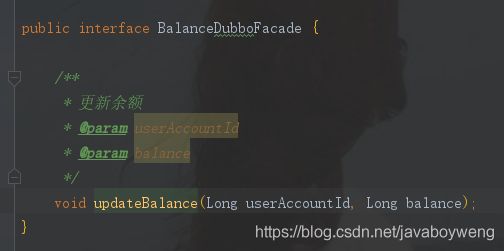
余额服务更新余额
提供者
2个方法的具体实现。
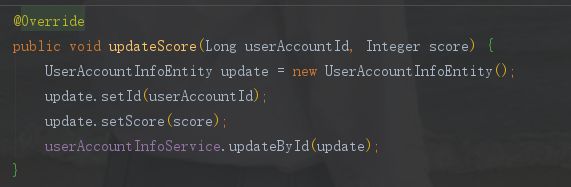

消费者
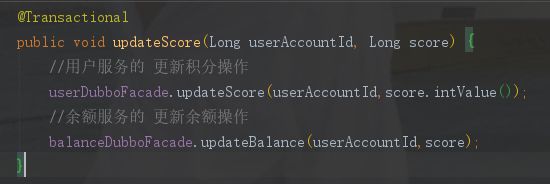
这个就是发起服务之间调用的边界,所以要在这注入关键注解 @GlobalTransactional。
访问
- 正常情况

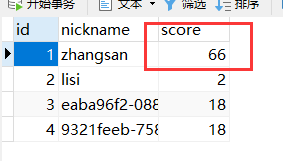

在正常情况下,更新score,用户表和余额表都有变化,这是没问题的达到了我们预期效果。
-
异常情况
根据上面的代码,我们score写成100就可以触发那个by/zero的异常。
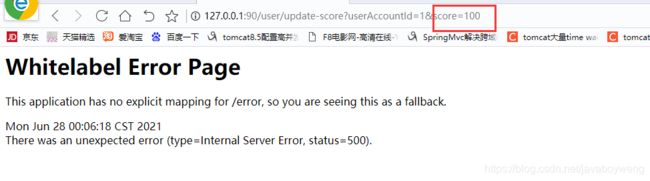

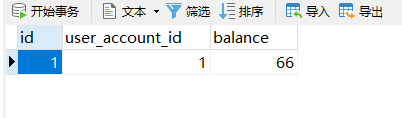
不出意外,调用接口后,系统抛异常了,我们正常思维应该是数据不能被插入到数据库中。但是很显然,数据依然存进了数据库,出现了脏数据。
所以这就是我们在分布式系统中一定要考虑的一个问题,分布式事务。
当然我们讨论的是数据强一致性的问题,如果说因为网络问题或者服务宕机导致数据不一致,是允许的,那无所谓了。
Seata
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和容易易用的分布式事务服务。Seata 于2019.1正式对外开源,前身是阿里巴巴2014年诞生的 TXC(Taobao Transaction Constructor)。以下是Seata官网介绍的特色服务:Seata 将为用户提供了 AT、TCC 和 XA 事务模式,为用户打造一站式的分布式解决方案。更多关于Seata的介绍,可参考其官网。
言而总之,总而言之,就是一句话,这玩意就是来解决咋们问题的,其他不想那么多,以后慢慢了解,咋们关心的是怎么用。能让上面在抛异常的时候,数据不进入数据库。
为啥选Seata,楼主就觉得他香,配置又简单,对于我这种手残党来说福音好吧。
官网地址
http://seata.io/zh-cn/
官网说的可以说是非常详细了,这里呢,我只是把重要的安装的几个方面拿出来说一下,这里用的版本是1.13.0版本。
1.SEATA AT 模式需要 UNDO_LOG 表
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2.启动服务
先下载1.13.0版本的seata服务端,也就是事务协调器,来管理全局事务用的。
从 https://github.com/seata/seata/releases,下载服务器软件包,将其解压缩。
-
registry.conf (负责指定注册中心在哪里)
registry { # file 、nacos 、eureka、redis、zk、consul、etcd3、sofa # 把这里的类型改成 nacos就可以了 type = "nacos" nacos { application = "seata-server" serverAddr = "127.0.0.1:8848" group = "SEATA_GROUP" namespace = "" cluster = "default" } eureka { serviceUrl = "http://localhost:8761/eureka" application = "default" weight = "1" } redis { serverAddr = "localhost:6379" db = 0 password = "" cluster = "default" timeout = 0 } zk { cluster = "default" serverAddr = "127.0.0.1:2181" sessionTimeout = 6000 connectTimeout = 2000 username = "" password = "" } consul { cluster = "default" serverAddr = "127.0.0.1:8500" } etcd3 { cluster = "default" serverAddr = "http://localhost:2379" } sofa { serverAddr = "127.0.0.1:9603" application = "default" region = "DEFAULT_ZONE" datacenter = "DefaultDataCenter" cluster = "default" group = "SEATA_GROUP" addressWaitTime = "3000" } file { name = "file.conf" } } config { # file、nacos 、apollo、zk、consul、etcd3 type = "file" nacos { serverAddr = "127.0.0.1:8848" namespace = "" group = "SEATA_GROUP" username = "" password = "" } consul { serverAddr = "127.0.0.1:8500" } apollo { appId = "seata-server" apolloMeta = "http://192.168.1.204:8801" namespace = "application" } zk { serverAddr = "127.0.0.1:2181" sessionTimeout = 6000 connectTimeout = 2000 username = "" password = "" } etcd3 { serverAddr = "http://localhost:2379" } file { name = "file.conf" } } -
file.conf (负责数据存储的位置)
这里为了演示demo而已,所以会用到这个file.conf文件,是否使用这个文件取决于registry.conf 的config区域的type是不是file,默认是file。正常你也可以配置nacos,因为nacos既是注册中心也可以是配置中心,反正很强大。
## transaction log store, only used in seata-server
store {
## store mode: file、db、redis
mode = "file"
## file store property
file {
## store location dir
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
maxBranchSessionSize = 16384
# globe session size , if exceeded throws exceptions
maxGlobalSessionSize = 512
# file buffer size , if exceeded allocate new buffer
fileWriteBufferCacheSize = 16384
# when recover batch read size
sessionReloadReadSize = 100
# async, sync
flushDiskMode = async
}
#加了一个默认的事务分组名称,vgroupMapping.后面的这个东西是要自己定义的,无论你怎么定义,切记项目里面的名字也必须跟这个是一样,不然会提示找不到。
service {
vgroupMapping.my_test_tx_group = "default"
default.grouplist = "127.0.0.1:8091"
}
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp)/HikariDataSource(hikari) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "mysql"
password = "mysql"
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
## redis store property
redis {
host = "127.0.0.1"
port = "6379"
password = ""
database = "0"
minConn = 1
maxConn = 10
queryLimit = 100
}
}
这里我是默认用mode=file没有动,正常生产环境应该会选择mode=db的形式,具体如何配置官网也说的非常清楚,后续也会出一个用mode=db的简单说明的文章给大家。
这里重点说一下分组事务名称,很多人都挂在这一步,项目跟seata一直关联不到一起。
service {
vgroupMapping.my_test_tx_group = "default"
default.grouplist = "127.0.0.1:8091"
}
vgroupMapping.my_test_tx_group中的my_test_tx_group 要自己想好一个,你可以叫vgroupMapping.xxx,也可以叫vgroupMapping.yyy 但是你项目的事务名称也得叫 xxx或者yyy。
然后设置好了之后就可以找到bin目录下的seata-server.bat 双击启动。
3.项目的依赖
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.4.RELEASEversion>
<relativePath/>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-aopartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>org.apache.dubbogroupId>
<artifactId>dubbo-spring-boot-starterartifactId>
<version>2.7.3version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
dependency>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discoveryartifactId>
dependency>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-seataartifactId>
<exclusions>
<exclusion>
<groupId>io.seatagroupId>
<artifactId>seata-spring-boot-starterartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>io.seatagroupId>
<artifactId>seata-spring-boot-starterartifactId>
<version>1.3.0version>
dependency>
dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-alibaba-dependenciesartifactId>
<version>2.2.1.RELEASEversion>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
建议最好SpringBoot版本不要太新,有时候Seata都跟不上,出一些莫名其妙的问题不好。 我是用SpringBoot 2.3.x版本 、 alibaba版本是2.2.1、Seata是1.13.0。
4.项目的配置
seata:
registry:
type: nacos
nacos:
application: seata-server
server-addr: 127.0.0.1:8848
group : "SEATA_GROUP"
namespace: ""
username: "nacos"
password: "nacos"
application-id: ${spring.application.name}
enabled: true
tx-service-group: my_test_tx_group #这里的名字一定要跟服务端里配置的vgroupMapping.后面那个东西长一样,不然会出问题
不管是服务的提供者还是消费者,seata都是这个配法。 如果我这里为了体现出分布式事务的效果,都采用默认,会用nacos的童鞋,如果有配置namespace的,要把id设置一下,默认是public。
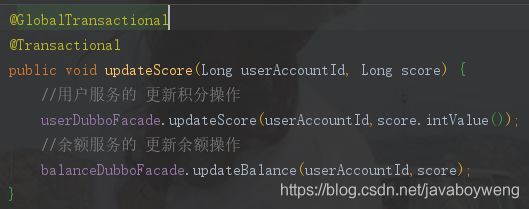
5.全局事务注解
在消费者端,也就是调用服务的业务方法上面加一个@GlobalTransactional
6.最后效果

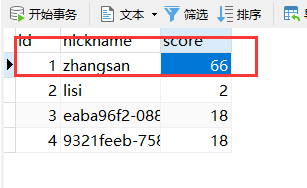
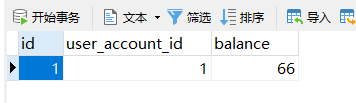
可以看到数据被回滚了,这样我们也达到了服务与服务之间分布式调用事务回滚的目的。
7.证明服务跟seata连接上了
![]()
日志中会有一行这样的信息
i.s.core.rpc.netty.NettyPoolableFactory : NettyPool create channel to transactionRole:TMROLE,address:169.254.21.224:8091,msg:< RegisterTMRequest{applicationId='dubbo-consumer', transactionServiceGroup='my_test_tx_group'} >