爬虫日常练习-艾图网单页面图片爬取
文章目录
- 爬虫练习
- 分析网站
- 代码设计
- 下载图片
- 完整代码
爬虫练习
hello,大家好。好久不见了,无聊的网友今天开始更新关于爬虫的一些日常练习。每次学习完一个新的知识后没有多的案例给自己练习真的很不舒服,希望该系列文章能够让刚刚开始学习爬虫的各位练练手。今天首先对艾图网发起挑战。链接在此: https://www.iituku.com/
分析网站
要想写好一个爬虫,最重要的就是先对要爬取的网页进行分析,只有对网页知根知底,我们才能更好地写出一个优秀的爬虫
我们可以看到这是一个多分钟类的免费图片下载网站,我们先选择旅游模块,点击后页面跳转新的界面
我们注意看此时的url,细心的xdm应该能想到,这个就是我们需要爬取的网页url。因为我们这里只是做一个简单的图片爬取,所以只需要具体的url就可以了,如果后面想要做一个自动化图片爬取程序的话就得换另一种思路,过一阶段在和xdm细说。

点击一个图片可以看到页面提供了下载功能

但xdm能满足于此吗?当然不能
 懂事的兄弟直接一套右键检查图片的组合拳下去
懂事的兄弟直接一套右键检查图片的组合拳下去
 哦呦,居然直接把图片的下载链接暴露在我们面前,这不摆明了看不起兄弟们?
哦呦,居然直接把图片的下载链接暴露在我们面前,这不摆明了看不起兄弟们?

但我不得不提醒xdm一下哈,可别轻易相信它的表面,谨慎的我选择检查页面源代码,检查一下标题在不在
 你瞧瞧,心急的兄弟得被气死,真实的页面根本没有给你图片的链接。所以说凡事要小心啊兄弟们。我们一定要以页面源代码为准,不要轻信经过页面处理的elements
你瞧瞧,心急的兄弟得被气死,真实的页面根本没有给你图片的链接。所以说凡事要小心啊兄弟们。我们一定要以页面源代码为准,不要轻信经过页面处理的elements

不信邪的我又去看来看是不是ajex加载的数据,结果也没有翻到,不对劲,十分有九分的不对劲。这个时候我灵机一动,把图片的文件名到源码中检查一下
![]()
果不其然,在源码中发现了猫腻
 缓慢往前滑动发现图片链接保存在列表嵌套的字典里
缓慢往前滑动发现图片链接保存在列表嵌套的字典里
![]() 既然知道了图片链接在哪里,那就话不多说,直接定下小目标,先把链接拿到手
既然知道了图片链接在哪里,那就话不多说,直接定下小目标,先把链接拿到手

代码设计
首先第一步,导入基本要使用的第三方库,并把要爬取的图片种类的url设置好
import requests
from lxml import etree
if __name__ == '__main__':
url = "https://www.iituku.com/lvyou.html"
get_pic_url(url)
然后定义一个获取图片链接的方法,经过我的测试发现图片的链接所在位置如下图所示,数据存在于body里的第二个script中,决定使用正则将数据提取出来
![]()
def get_pic_url(url):
resp = requests.get(url).text
tree = etree.HTML(resp)
pic_url_string = tree.xpath('//html/body/script[2]/text()')[0]
obj = re.compile(r'var imagesarr=\"(.*?)\";')
data = obj.findall(pic_url_string)[0]
print(data)
为了下面顺利进行,我们先测试一下
![]() 可以看到最后匹配到的结果并不是我们想要的形式,我们还需要进行处理使它变为我们在前端看到的样子。暂时转为字符串格式利用replace方法替换掉
可以看到最后匹配到的结果并不是我们想要的形式,我们还需要进行处理使它变为我们在前端看到的样子。暂时转为字符串格式利用replace方法替换掉
data = str(data).replace('"','')
![]() 可以看到烦人的"已经消失了,接下来只要提取到链接就可以
可以看到烦人的"已经消失了,接下来只要提取到链接就可以
由于我们现在得到的已经是字符串格式的数据了,只能采用字符串的方法进行处理。我们可以看到返回的数据通过{}分为一个个小整体,可以通过split来切割数据,这样我们就可以获取一个列表数据
data_list = data.split('}')
获得数据如下
![]() 通过for循环与re获取图片链接,这里我发现不带/nu的链接获取的图片清晰度更高些,因此获取不带/nu的链接
通过for循环与re获取图片链接,这里我发现不带/nu的链接获取的图片清晰度更高些,因此获取不带/nu的链接
for li in data_list:
http = re.findall(r'picture:(.*?)/nu', li)
http = str(http).replace(r'\\', '')
print(http)
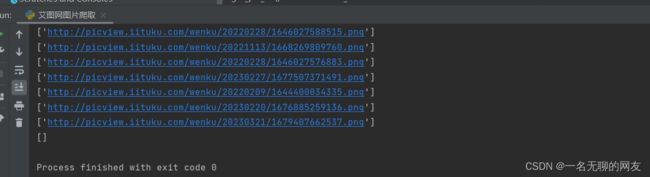 此处获取的结果如上图,一开始想用索引直接提取出字符串,结果一直报错超出索引,后来才发现有的列表获取到的是空值,因此我们还需要价格判断,不然会报错如下
此处获取的结果如上图,一开始想用索引直接提取出字符串,结果一直报错超出索引,后来才发现有的列表获取到的是空值,因此我们还需要价格判断,不然会报错如下
 对代码改动一下
对代码改动一下
for li in data_list:
http = re.findall(r'picture:(.*?)/nu', li)
if not http:
continue
else:
http_str = http[0]
http = http_str.replace('\\', '')
print(http)
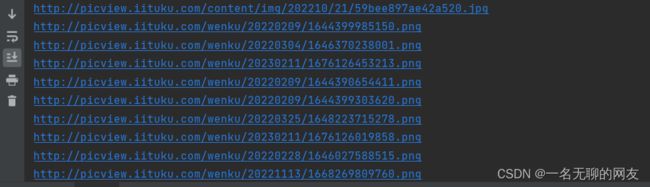
ok兄弟们看看效果,完美获取到图片链接
下载图片
获取到所有图片后就可以开始下载图片了
def download(list):
for src in list:
resp = requests.get(src)
pic_name = src.split('/')[-1]
with open('./'+pic_name, mode='wb') as f:
f.write(resp.content)
print('下载完成')
运行完成后可以看到图片已经全部下载完成

完整代码
完整代码如下:
import requests
from lxml import etree
import re
def get_pic_url(url):
resp = requests.get(url)
resp.encoding = 'utf-8'
tree = etree.HTML(resp.text)
pic_url_string = tree.xpath('//html/body/script[2]/text()')[0]
obj = re.compile(r'var imagesarr=\"(.*?)\";')
data = obj.findall(pic_url_string)[0]
data = str(data).replace('"', '')
data_list = data.split('}')
pic_url_list = []
for li in data_list:
http = re.findall(r'picture:(.*?)/nu', li)
if not http:
continue
else:
http_str = http[0]
http = http_str.replace('\\', '')
pic_url_list.append(http)
return pic_url_list
def download(list):
for src in list:
resp = requests.get(src)
pic_name = src.split('/')[-1]
with open('./'+pic_name, mode='wb') as f:
f.write(resp.content)
print('下载完成')
if __name__ == '__main__':
url = "https://www.iituku.com/lvyou.html"
pic_url_list = get_pic_url(url)
download(pic_url_list)
 打开工作目录就可以看到精美的图片已经下载完成啦
打开工作目录就可以看到精美的图片已经下载完成啦
明天接着更新多页面图片爬取以及协程和进程的方式
