ECMWF等大气数据批量下载(Python API)详细步骤
ECMWF等大气数据批量下载(Python API)
遥感方向做热红外温度反演,不可避免的要用到大气廓线数据,大气数据具有实时性,比如2018年9月1日的早上8点的影像,为了提高反演精度就需要用到时间上与其相差尽可能接近的大气数据,用于消除大气的影响,如果数据量较少我们可以查看影像的时间和空间范围进行下载,但是如果处理某个较大区域时可能涉及到大量的影像,如果一景一景对应查找去下载会很麻烦,因此针对大量数据的自动批量下载很有必要。本文根据 https://cds.climate.copernicus.eu/#!/home 官网提供API接口封装了自动下载的方法以供使用。
1.到官网注册账号并申请key
到官网 https://cds.climate.copernicus.eu/#!/home 或 https://ads.atmosphere.copernicus.eu/user/register 注册账户;
然后获取API key:
CDS用户:https://cds.climate.copernicus.eu/api-how-to
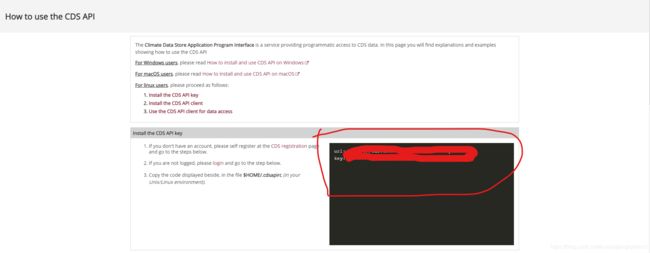
ADS用户:https://ads.atmosphere.copernicus.eu/api-how-to
复制右边命令行中的两行(黑屏部分),打开记事本,粘贴到记事本中,另存为“.cdsapirc”文件。
注意:
如果只是自己用,将这个文件放到C盘用户目录下比如C:\Users\admin ;
如果是想给别人用,就是你的代码拿到别人的电脑上无需配置等复杂操作时进行后续操作(请查看备注1部分)。
2.开始环境搭建
首先,要安装好python和pip,并设置好环境变量:这个自行安装,这里省略。
然后,安装API(这里以CDS用户为例):
打开安装好的Python环境,
Python2.7:
命令行中输入:pip install cdsapi
Python3:
命令行中输入:pip3 install cdsapi
如果不能安装成功尝试如下命令:
pip install --user cdsapi # for Python 2.7
pip3 install --user cdsapi # for Python 3
至此环境搭建成功
3.根据api规范写Python脚本
由于此网站包含不同类型的数据,因此下载格式也不尽相同,这里以ERA5 hourly data on pressure levels from 1979 to present数据集为例:
到如下地址选择数据集
https://cds.climate.copernicus.eu/cdsapp#!/search?type=dataset
比如我要做温度反演,要用到大气廓线数据,选择ERA5 hourly data on pressure levels from 1979 to present;
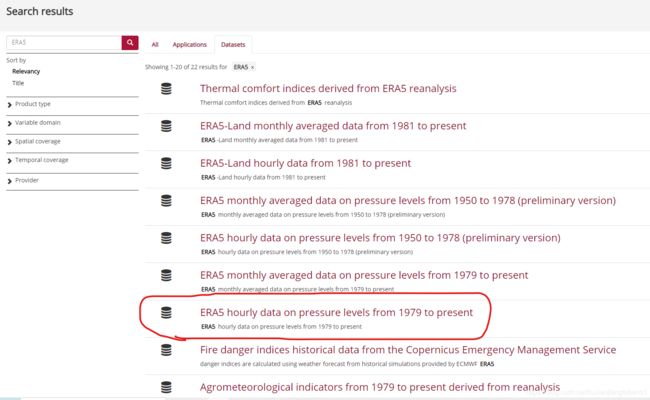
点击进入后选择Download data,根据自己要求选择数据相关属性:包括产品类型、变量、压强等级、年、月、日、时间(注意都是整点)、地理范围、格式等,然后拉到最底部,点击show api request:
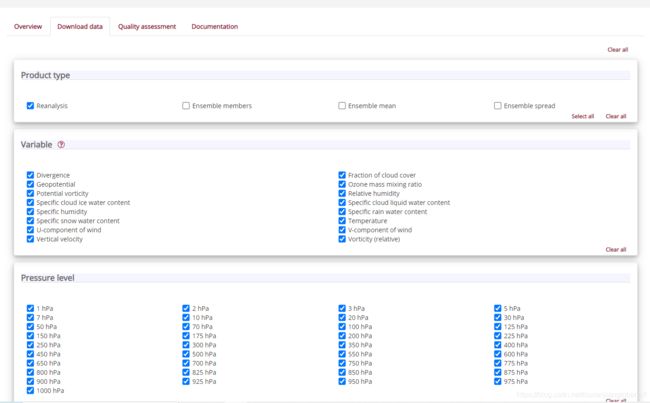
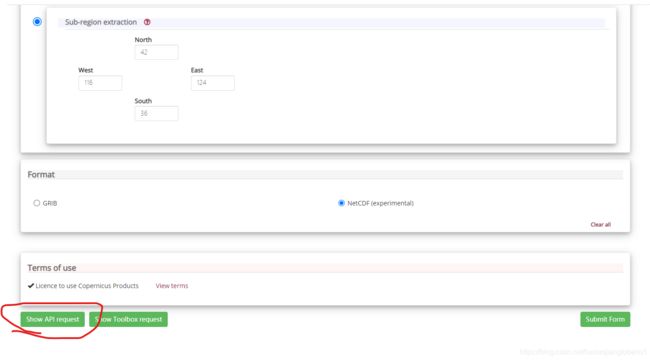
根据选择会自动生成一段请求数据的代码:
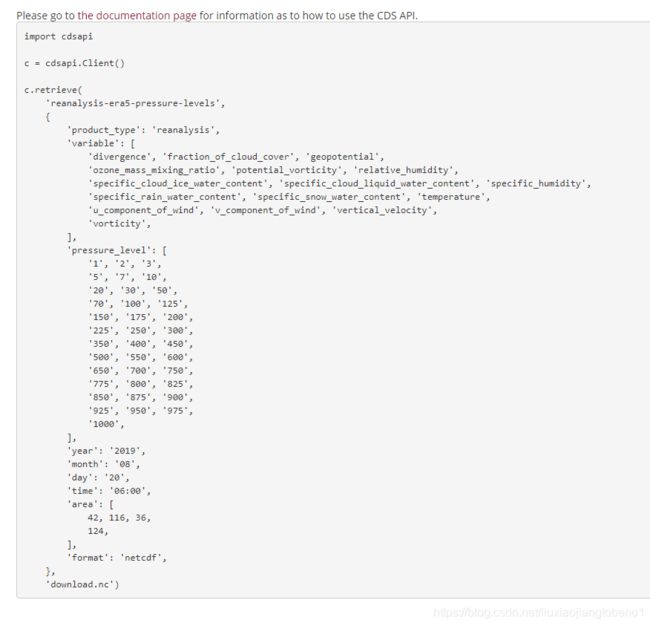
以此为模板进行下载设置,如我要做大批量的数据生产,所需数据要变的是年月日时间和地理范围以及输出路径,那我就将这几项设置为变量,通过函数传参传进来(这里注意原来的变量类型哦,还有就是时间这一项必须是整点(查看备注2),否则会下载失败),如下为封装的下载函数:
import cdsapi
import sys
#封装成一个方法,参数为年、月、日、时、上、左、下、右、输出路径(上左下右为影像的四至范围):
def downloadnc(year,month,day,time,area1,area2,area3,area4,output):
c = cdsapi.Client()
print(sys.path[0])
result=c.retrieve(
'reanalysis-era5-pressure-levels',
{
'product_type': 'reanalysis',
'variable': [
'divergence', 'fraction_of_cloud_cover', 'geopotential',
'ozone_mass_mixing_ratio', 'potential_vorticity', 'relative_humidity',
'specific_cloud_ice_water_content', 'specific_cloud_liquid_water_content', 'specific_humidity',
'specific_rain_water_content', 'specific_snow_water_content', 'temperature',
'u_component_of_wind', 'v_component_of_wind', 'vertical_velocity',
'vorticity',
],
'pressure_level': [
'1', '2', '3',
'5', '7', '10',
'20', '30', '50',
'70', '100', '125',
'150', '175', '200',
'225', '250', '300',
'350', '400', '450',
'500', '550', '600',
'650', '700', '750',
'775', '800', '825',
'850', '875', '900',
'925', '950', '975',
'1000',
],
'year': year,
'month': month,
'day': day,
'time': time,
'area': [
area1, area2, area3, area4,
],
'format': 'netcdf',
},
output)
至此通过调用该函数即可实现数据下载功能,但是这里要注意几点:
如果传入的时间不是整点,那么请求会失败,因为没有数据,这时会抛出异常:
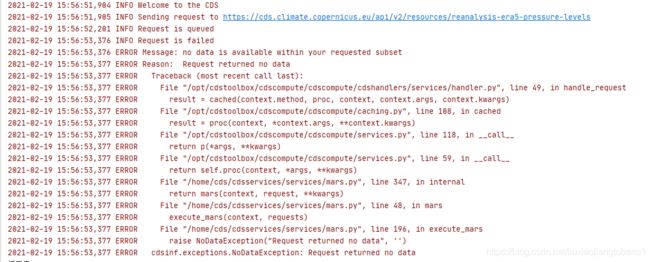
因此在这里要做一个异常处理:
def call(year,month,day,time,area1,area2,area3,area4,output):
try:
downloadnc(year,month,day,time,area1,area2,area3,area4,output)
return "successful"
except Exception as e:
return str(e)
外部通过调用call方法进行下载,下载成功返回"successful",下载失败返回失败原因。这样调用的时候就不回奔溃了。
4.根据元数据获取影像信息进行自动化下载
根据自己需求,从元数据中获取相应信息,如我的需求,需要获取影像获取时间和空间四至范围,以及下载文件的路径等,另写一个py文件获取相关信息和参数后调用上面的文件(考虑landsat8元数据格式及其他常见的xml元数据格式):
import DownloadNC
import os
import sys
from xml.dom.minidom import parse
def getInfoByTxt(metafile):
print("INFO Start read meta file ...",flush=True)
mydate = time = ""
up = down = left =right = up1 = down1 = left1 = right1 = up2 = down2 = left2 = right2 = 0
f = open(metafile)
line = f.readline()
while line:
if line.startswith(" DATE_ACQUIRED"):
a = line.index("=")
mydate = line[a + 1:]
if line.startswith(" SCENE_CENTER_TIME"):
a = line.index("=")
time = line[a + 3:]
if line.startswith(" CORNER_LR_LAT_PRODUCT"):
a = line.index("=")
down1 = line[a + 1:]
if line.startswith(" CORNER_LL_LAT_PRODUCT"):
a = line.index("=")
down2 = line[a + 1:]
if line.startswith(" CORNER_UL_LON_PRODUCT"):
a = line.index("=")
left1 = line[a + 1:]
if line.startswith(" CORNER_LL_LON_PRODUCT"):
a = line.index("=")
left2 = line[a + 1:]
if line.startswith(" CORNER_UL_LAT_PRODUCT"):
a = line.index("=")
up1 = line[a + 1:]
if line.startswith(" CORNER_UR_LAT_PRODUCT"):
a = line.index("=")
up2 = line[a + 1:]
if line.startswith(" CORNER_UR_LON_PRODUCT"):
a = line.index("=")
right1 = line[a + 1:]
if line.startswith(" CORNER_LR_LON_PRODUCT"):
a = line.index("=")
right2 = line[a + 1:]
line = f.readline()
f.close()
up = max((float)(up1), (float)(up2))
down = min((float)(down1), (float)(down2))
left = min((float)(left1), (float)(left2))
right = max((float)(right1), (float)(right2))
print("INFO Read meta data end!",flush=True)
return mydate,time,up,down,left,up,right
def getInfoByXml(metafile):
print("INFO Start read meta file...",flush=True)
mydate = time = ""
up = down = left = right = 0
domTree = parse(metafile)
# 文档根元素
rootNode = domTree.documentElement
print("INFO "+rootNode.nodeName+"",flush=True)
#获取日期时间
datetime = rootNode.getElementsByTagName("EndTime")
# 获取四至范围
TRLat = rootNode.getElementsByTagName("TopRightLatitude")
TLLat = rootNode.getElementsByTagName("TopLeftLatitude")
BRLat = rootNode.getElementsByTagName("BottomRightLatitude")
BLLat = rootNode.getElementsByTagName("BottomLeftLatitude")
TRLon = rootNode.getElementsByTagName("TopRightLongitude")
TLLon = rootNode.getElementsByTagName("TopLeftLongitude")
BRLon = rootNode.getElementsByTagName("BottomRightLongitude")
BLLon = rootNode.getElementsByTagName("BottomLeftLongitude")
try:
strdatetime = datetime[0].firstChild.data
mydate = strdatetime[:10]
time = strdatetime[11:]
strTRLat = TRLat[0].firstChild.data
strTLLat = TLLat[0].firstChild.data
strBRLat = BRLat[0].firstChild.data
strBLLat = BLLat[0].firstChild.data
strTRLon = TRLon[0].firstChild.data
strTLLon = TLLon[0].firstChild.data
strBRLon = BRLon[0].firstChild.data
strBLLon = BLLon[0].firstChild.data
up = max((float)(strTRLat), (float)(strTLLat))
down = min((float)(strBRLat), (float)(strBLLat))
left = min((float)(strTLLon), (float)(strBLLon))
right = max((float)(strTRLon), (float)(strBRLon))
print("INFO Read meta data end!", flush=True)
return mydate, time, up, down, left, up, right;
except Exception as e:
print("ERROR", flush=True)
print(e,flush=True)
return "", "", 0, 0, 0, 0, 0;
def changetimetoUTC(mydate,time):
year=0
mounth=0
day=0
#拆分年月日
x = str(mydate).split('-')
if len(x) >= 3:
year = x[0]
mounth = x[1]
day = x[2][:2]
else:
print("Error Get date false!",flush=True)
#确定月初前一天是几号
iscommanyear = 1 # 平年
if (int(year) % 4 == 0 and int(year) % 100 != 0 or int(year) % 400 == 0):
iscommanyear = 0 # 闰年
lastday = 31
if (int(mounth) == 3 and iscommanyear == 0):
lastday = 29
if (int(mounth) == 3 and iscommanyear == 1):
lastday = 28
if (int(mounth) == 5 or int(mounth) == 7 or int(mounth) == 10 or int(mounth) == 12):
lastday = 30
#拆分时间
inttime=(int)(str(time)[:2])
if(inttime<8):
sub=8-inttime
inttime=24-sub
if(day==1):
day=lastday
else:
inttime=inttime-8
#组合起来
newtime=""
if(inttime<10):
newtime="0"+str(inttime)+":00"
else:
newtime=str(inttime)+":00"
newdate=str(year)+"-"+str(mounth)+"-"+str(day)
return newdate,newtime
#查找文件
def FindFiles(input,filter,meta_list):
for i in os.listdir(input):
path2 = os.path.join(input, i) # 拼接绝对路径
if os.path.isdir(path2): # 判断如果是文件夹,调用本身
FindFiles(path2,filter,meta_list)
else:
if (i.lower().endswith(filter)):
meta_list.append(os.path.join(input, i))
def mymain(input,output,satelite,type):
print("INFO Find meta file...",flush=True)
#文件后缀
filter="xml"
if(satelite.startswith("LandSat")):
filter="txt"
#找到所有文件并过滤
meta_list=[]
FindFiles(input,filter,meta_list)
#遍历元数据文件进行下载
for m in meta_list:
print("=========================================================================================================",flush=True)
print("INFO "+m,flush=True)
mydate=time=up=down=left=up=right=""
if(filter=="xml"):
mydate,time,up,down,left,up,right=getInfoByXml(m)
else:
mydate, time, up, down, left, up, right = getInfoByTxt(m)
#获取范围
uplat = ((float)(up) + 1)
downlat = ((float)(down) - 1)
leftlon = ((float)(left) - 1)
rightlon = ((float)(right) + 1)
#指定输出
name = os.path.basename(m)
name = name[0:-8]
outputpath = output + '/' + name + '.nc'
#获取日期
newdate = mydate
x = str(newdate).split('-')
if len(x) < 3:
print("Warning Date false!",flush=True)
print("INFO Complete " + str(meta_list.index(m) + 1) + " files!", flush=True)
print("=========================================================================================================",flush=True)
continue
year = x[0]
mounth = x[1]
day = x[2][:2]
#获取时间
newtime = time
newtime = str(newtime)[:2]
time = newtime + ":00"
#开始下载
print("INFO Start download...",flush=True)
result = DownloadNC.call(year, mounth, day, time, uplat, leftlon, downlat, rightlon, outputpath, type)
if result != "successful":
print("Error Download failed!:",flush=True)
print(result,flush=True)
print("INFO Complete " + str(meta_list.index(m) + 1) + " files!", flush=True)
#下载完成打印
print("=========================================================================================================", flush=True)
if __name__ == "__main__":
print("INFO Welcome NC Download!",flush=True)
if len(sys.argv) == 5:
print("INFO Let's go!",flush=True)
intput= sys.argv[1]
output= sys.argv[2]
satelite=sys.argv[3]
type=sys.argv[4]
mymain(intput,output,satelite,type)
print("INFO Download Ends! Good bye!",flush=True)
这样可以直接调用py文件并传入相关个参数就可完成下载(元数据路径,输出路径和错误日志路径),这里把批处理也一并嵌入了。
备注
前文提到如果要给别人用且想省去配置和安装环境的情况下需做如下操作:
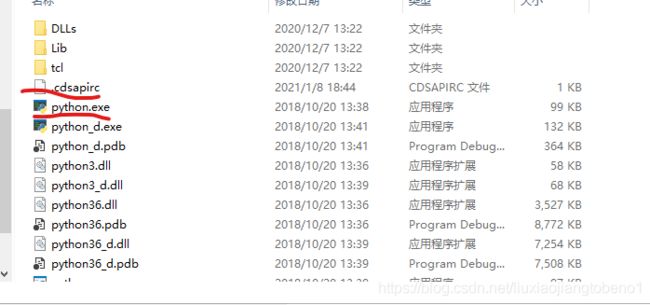
1 在Python安装目录下找到cdsapi库的api.py文件,如D:\Python3.6\Lib\site-packages\cdsapi:
2 打开api.py文件,搜索“.cdsapirc”,找到该行,大约在285行,做如下修改:(源码是到用户目录(如C:\Users\admin)下找这个文件,现在将其改为当前工作路径下):
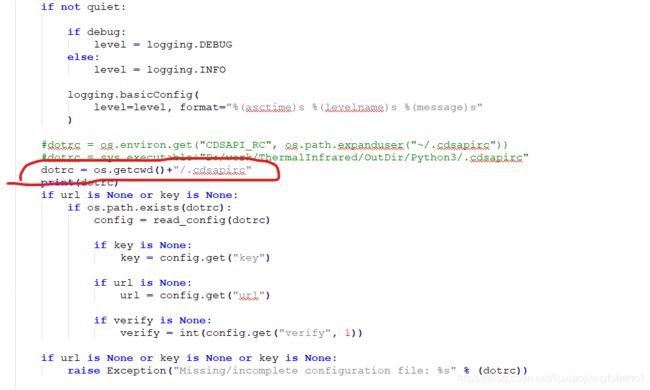
并将.cdsapirc文件放到python.exe同级目录下: